其他更多java基础文章:
java基础学习(目录)
学习资料
ArrayList集合实现RandomAccess接口有何作用?
概述
ArrayList是可以动态增长和缩减的索引序列,它是基于数组实现的List类。
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
- ArrayList 继承了AbstractList抽象类
为什么要先继承AbstractList,而让AbstractList先实现List?而不是让ArrayList直接实现List ?这里是有一个思想,接口中全都是抽象的方法,而抽象类中可以有抽象方法,还可以有具体的实现方法,正是利用了这一点,让AbstractList是实现接口中一些通用的方法,而具体的类,如ArrayList就继承这个AbstractList类,拿到一些通用的方法,然后自己在实现一些自己特有的方法,这样一来,让代码更简洁,就继承结构最底层的类中通用的方法都抽取出来,先一起实现了,减少重复代码。所以一般看到一个类上面还有一个抽象类,应该就是这个作用。 - ArrayList 实现了List
接口
这里有个题外话。明明父类AbstractList也实现了List接口,那为什么子类ArrayList还是去实现一遍呢?我在stackOverFlow中找到了答案,这里其实很有趣。 Why does LinkedHashSet extend HashSet and implement Set 。开发这个collection 的作者Josh说:这其实是一个mistake,因为他写这代码的时候觉得这个以后会有用处,但是其实并没什么用,而且又因为没什么影响,JDK维护人员并不认为这是值得以后放弃的,就一直留到了现在。 - ArrayList 实现了RandomAccess接口
这个是一个标记性接口,RandomAccess接口这个空架子的存在,是为了能够更好地判断集合选择更优的遍历方式,提高性能!实现了该接口的话,那么使用普通的for循环来遍历,性能更高,例如arrayList。而没有实现该接口的话,使用Iterator来迭代,这样性能更高,例如linkedList。所以这个标记性只是为了让我们知道我们用什么样的方式去获取数据性能更好。ArrayList集合实现RandomAccess接口有何作用? - ArrayList 实现了Cloneable接口:
实现了该接口,就可以使用Object.Clone()方法了。 - ArrayList 实现了Serializable接口
实现该序列化接口,表明该类可以被序列化。
存储结构
ArrayList的底层数据结构是一个Object数组:
transient Object[] elementData;
说明:底层的数据结构就是数组,数组元素类型为Object类型,即可以存放所有类型数据。我们对ArrayList类的实例的所有的操作底层都是基于数组的。
基础字段
// 序列化时使用的版本号
private static final long serialVersionUID = 8683452581122892189L;
// 缺省容量
private static final int DEFAULT_CAPACITY = 10;
// 空对象数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 缺省空对象数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 元素数组
transient Object[] elementData;
//elementData中已存放的元素的个数,注意:不是elementData的容量
private int size;
// 最大数组容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
上面的elementData属性采用了transient来修饰,表明其不使用Java默认的序列化机制来实例化,但是该属性是ArrayList的底层数据结构,在网络传输中一定需要将其序列化,之后使用的时候还需要反序列化,那不采用Java默认的序列化机制,我们怎么序列化它呢? 那就是使用writeObject和readObject方法。
这属于序列化的知识,简单说一下,如果目标类中没有定义私有的writeObject或readObject方法,那么序列化和反序列化的时候将调用默认的方法来根据目标类中的属性来进行序列化和反序列化,而如果目标类中定义了私有的writeObject或readObject方法,那么序列化和反序列化的时候将调用目标类指定的writeObject或readObject方法来实现。
方法细节
构造方法
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
//EMPTY_ELEMENTDATA:是个空的Object[], 将elementData初始化,
//空的Object[]会给默认大小10,会在add的时候赋值
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//根据传入的容量创建ArrayList
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//创建一个ArrayList,数据为Collection的数据
public ArrayList(Collection c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
add方法
add方法是ArrayList的重点方法之一
public boolean add(E e) {
//确定内部容量是否够了,size是数组中数据的个数,因为要添加一个元素,所以size+1,
//先判断size+1的个数,这个数组能否放得下
ensureCapacityInternal(size + 1); // Increments modCount!!
//在数据中正确的位置上放上元素e,并且size++
elementData[size++] = e;
return true;
}
//插入具体某个位置
public void add(int index, E element) {
rangeCheckForAdd(index);//检查index也就是插入的位置是否合理。
//跟上面的分析一样,具体看上面
ensureCapacityInternal(size + 1); // Increments modCount!!
//这个方法就是用来在插入元素之后,要将index之后的元素都往后移一位,
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//在目标位置上存放元素
elementData[index] = element;
size++;//size增加1
}
很明显,ensureCapacityInternal方法是一个判断数组的长度是否满足新增后size的方法,让我们跟进看一下:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) { //看,判断初始化的elementData是不是空的数组,也就是没有长度
//判断是否新创建数组,如果是则设为默认容量10
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//这个方法才是真正的判断elementData是否够用
ensureExplicitCapacity(minCapacity);
}
继续跟进ensureExplicitCapacity方法
private void ensureExplicitCapacity(int minCapacity) {
modCount++; //这个参数用于判断数据结构变化
//判断需要的最小容量是否比目前数组的长度length大,如果是,则扩容ArrayList数组
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
继续跟进grow方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//扩容为当前容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//这句话就是适应于elementData就空数组的时候,length=0,那么oldCapacity=0,newCapacity=0,所以这个判断成立,在这里就是真正的初始化elementData的大小了,就是为10.前面的工作都是准备工作。
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
简单看下hugeCapacity方法
//如果minCapacity都大于MAX_ARRAY_SIZE,那么就Integer.MAX_VALUE返回,反之将MAX_ARRAY_SIZE返回。因为maxCapacity是三倍的minCapacity,可能扩充的太大了,就用minCapacity来判断了。
//Integer.MAX_VALUE:2147483647 MAX_ARRAY_SIZE:2147483639 也就是说最大也就能给到第一个数值。还是超过了这个限制,就要溢出了。相当于arraylist给了两层防护。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
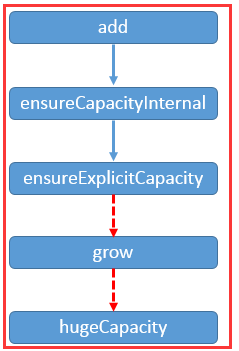
到此,就是ArrayList的add方法和扩容方法的所有流程了。也不算难。大概流程如下,虚线表示需要扩容时才会走的步骤:
remove方法
public E remove(int index) {
rangeCheck(index);//检查index的合理性
modCount++;//这个作用很多,比如用来检测快速失败的一种标志。
E oldValue = elementData(index);//通过索引直接找到该元素
int numMoved = size - index - 1;//计算要移动的位数。
if (numMoved > 0)
//这个方法也已经解释过了,就是用来移动元素的。
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将--size上的位置赋值为null,让gc(垃圾回收机制)更快的回收它。
elementData[--size] = null; // clear to let GC do its work
//返回删除的元素。
return oldValue;
}
//通过判断Object是否相同来删除
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
跟remove有关的方法中,重点讲一下batchRemove这个方法,这个方法的调用只有在removeAll()和retainAll()两个方法中。
//在removeAll中
batchRemove(c, false);
//在retainAll中
batchRemove(c, true);
private boolean batchRemove(Collection c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
//遍历所有元素,根据传入的complement不同,保存不同的结果。
//removeAll中保存elementData中删去Collection c中的元素后的数组
//retainAll中保存elementData和Collection c的交集
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
//如果contains方法使用过程报异常
//将剩下的元素都赋值给集合A,
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
关于最后if (w != size) {}代码块的逻辑,我在这里解释一下:
- 此时如果是removeAll,w表示elementData删去c后的数组长度,size为原数组长度。
- 如果删去后的数组长度与原数组长度相同,则表示没有remove元素,removeAll返回false。
- 如果删去后的数组长度与原数组长度不同,举例elementData为[1,2,3,4,5],c为[1,2]。通过上面的循环得到的新elementData为[3,4,5,4,5],所以此时就需要把size-w这段区间内的数组设为null。最后结果为[3,4,5,null,null],返回true
- 此时如果是retainAll,w表示elementData与c交集后的数组长度,size为原数组长度。
- 如果交集后的数组长度与原数组长度相同,则表示没有交集元素,retainAll返回false。
- 如果交集后的数组长度与原数组长度不同,举例elementData为[1,2,3,4,5],c为[2,3]。通过上面的循环得到的新elementData为[2,3,3,4,5],所以此时就需要把size-w这段区间内的数组设为null。最后结果为[2,3,null,null,null],返回true
总结
- arrayList可以存放null。
- arrayList本质上就是一个elementData数组。
- arrayList区别于数组的地方在于能够自动扩展大小,其中关键的方法就是gorw()方法。
- arrayList由于本质是数组,所以它在数据的查询方面(get)会很快,而在插入(add)删除(remove)这些方面,性能下降很多,要移动数组其他元素才能达到应有的效果
- arrayList实现了RandomAccess,所以在遍历它的时候推荐使用for循环。