多台Linux虚拟机Hadoop集群的安装与部署(超详细版)
生资之高在忠信,非关机巧
学业之美在德行,不仅文章
注意事项
- 虚拟机系统均为Linux的发行版,CentOS 7
- 本次安装部署实际使用的虚拟机数量为3(实际两台及以上数量的虚拟机均可,一台为伪分布式)
- 各台虚拟机的IPv4为手动,它们的IP地址、子网掩码、网关以及DNS需要正确填写
- 本次安装部署使用的IP地址如下,后文会多次出现
| 节点 | IP地址 | 原主机名 | 即将更新后的主机名 |
|---|---|---|---|
| 主节点 | 172.16.29.94 | GPU | master |
| 从节点1 | 172.16.29.95 | CentOS | slave1 |
| 从节点2 | 172.16.29.96 | ContOS | slave2 |
准备工作
安装包
- jdk-8u151-linux-x64.tar.gz 提取码0823
- hadoop-2.7.7.tar.gz 提取码en66
注意:JDK版本尽量使用1.8
软件
- Xftp (类似的SFTP、FTP文件传输软件均可,如国产的FinalShell)
- Xshell (类似的安全终端模拟软件均可,如SecureCRT)
- Xftp以及Xshell均包含在Xmanager软件产品中 提取码7r9h
- SecureCRT 提取码fcjd
- Xshell以及SecureCRT下载一个即可,建议下载Xshell
具体步骤
注意:以下以在IP为172.16.29.94的虚拟机(主节点)上安装与部署为例,阅读过程中请注意特别说明
使用Xftp导入安装包
- 打开Xftp,点击“文件”→“新建”
- 填写“名称”、“主机”、“用户名”和“密码”,“主机”填写IP地址,名称尽量填写IP地址,“用户名”和“密码”为登录该虚拟机的用户名和密码
- “协议”更改为“SFTP”
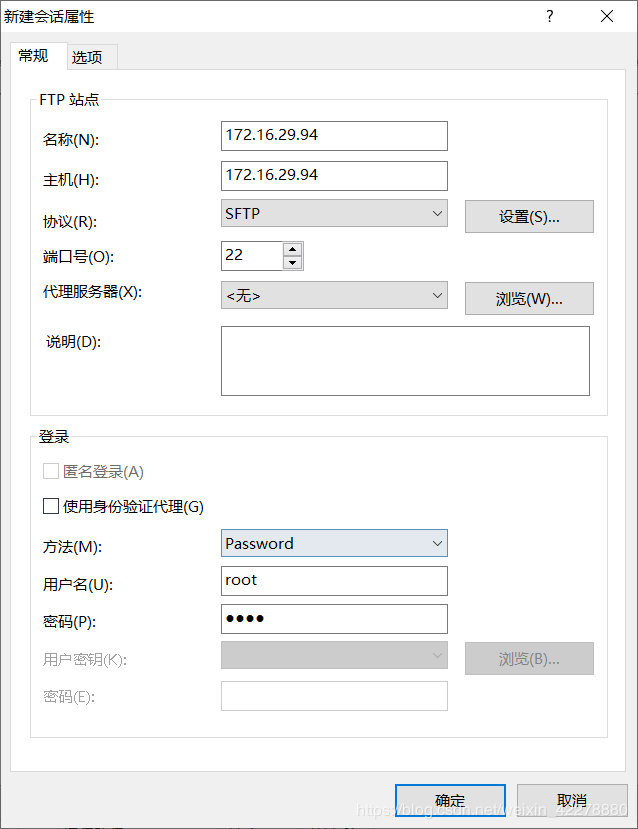
- 点击“选项”,勾选“使用UTF-8”编码,点击“确定”,否则连接时虚拟机中的文件名称会产生乱码
- 选择名称为“172.16.29.94”的会话,点击“连接”
- 将本地的两个安装包文件拖拽到虚拟机上
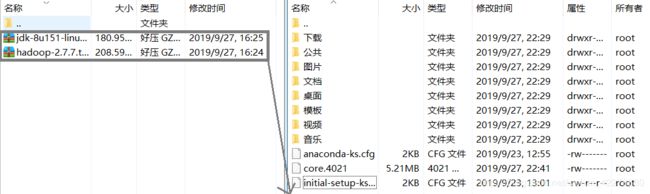 传输完成后如下
传输完成后如下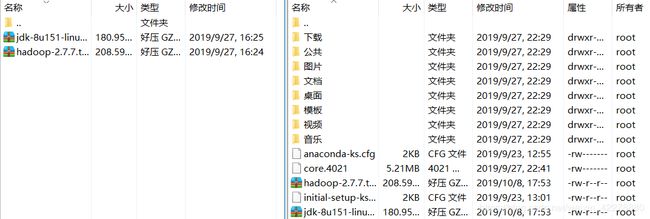
使用Xshell进行安装与部署
使用Xshell连接虚拟机
- 点击“文件”→“新建”
- 填写“名称”和“主机”,“主机”为IP地址,“名称”尽量填写IP地址,点击“确定”
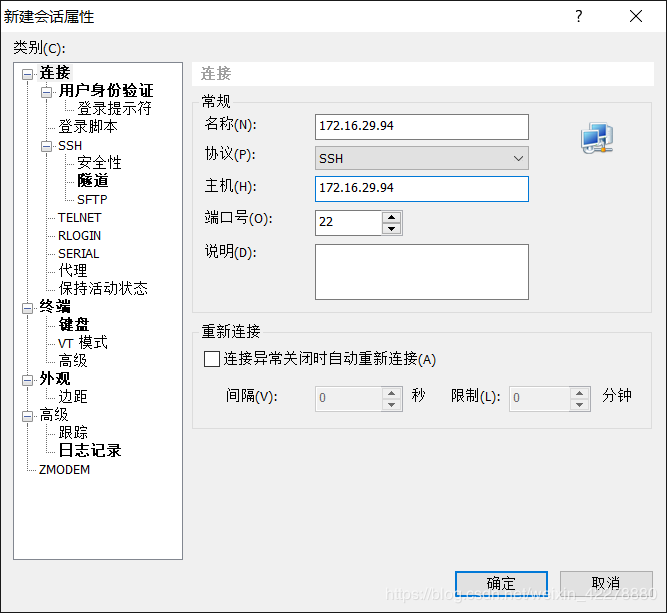
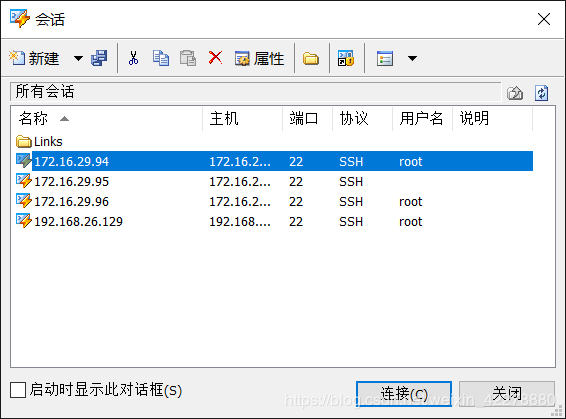
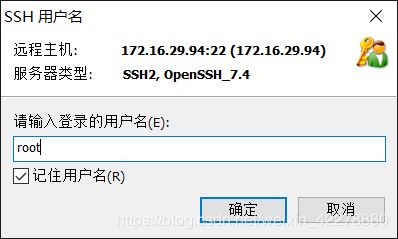
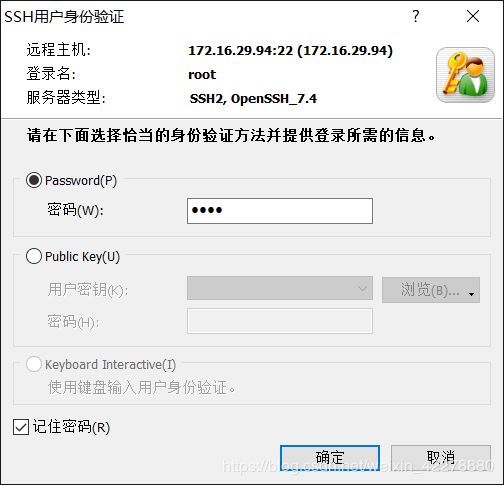
- 在会话中选择“172.16.29.94”,点击“连接”,依次输入“用户名”和“密码”,“用户名”和“密码”为登录该虚拟机的用户名和密码,最后点击“确定”
 在Xshell显示界面显示如下信息即为连接成功
在Xshell显示界面显示如下信息即为连接成功
Connecting to 172.16.29.94:22…
Connection established.
To escape to local shell, press ‘Ctrl+Alt+]’.
Last login: Tue Oct 8 16:55:55 2019 from 172.28.54.186
[root@GPU ~]#
其中[root@GPU~]中的GPU为该虚拟机的主机名,即hostname,每台虚拟机可能会不一样
特别说明:所有虚拟机均执行“使用Xshell连接虚拟机”操作
安装JDK
- 在Xshell中输入命令
ll,得到如下结果
([root@GPU ~]# ll)
从中可以看到 hadoop-2.7.7.tar.gz 和 jdk-8u151-linux-x64.tar.gz 两个文件
-rw-------. 1 root root 2094 9月 23 12:55 anaconda-ks.cfg
-rw-------. 1 root root 5468160 9月 27 22:41 core.4021
-rw-r–r-- 1 root root 218720521 10月 8 17:53 hadoop-2.7.7.tar.gz
-rw-r–r--. 1 root root 2142 9月 23 13:01 initial-setup-ks.cfg
-rw-r–r-- 1 root root 189736377 10月 8 17:53 jdk-8u151-linux-x64.tar.gz
drwxr-xr-x. 2 root root 6 9月 27 22:29 tsclient
drwxr-xr-x. 2 root root 6 9月 27 22:29 公共
drwxr-xr-x. 2 root root 6 9月 27 22:29 模板
drwxr-xr-x. 2 root root 6 9月 27 22:29 视频
drwxr-xr-x. 2 root root 6 9月 27 22:29 图片
drwxr-xr-x. 2 root root 6 9月 27 22:29 文档
drwxr-xr-x. 2 root root 6 9月 27 22:29 下载
drwxr-xr-x. 2 root root 6 9月 27 22:29 音乐
drwxr-xr-x. 2 root root 6 9月 27 22:29 桌面
- 输入创建目录命令
mkdir /usr/local/java
([root@GPU ~]# mkdir /usr/local/java) - 将JDK安装到该目录,输入命令
tar -C /usr/local/java -zxvf jdk-8u151-linux-x64.tar.gz,点击回车
([root@GPU ~]# tar -C /usr/local/java -zxvf jdk-8u151-linux-x64.tar.gz) - 输入命令
vi /etc/profile,修改profile配置文件
([root@GPU ~]# vi /etc/profile)
点击i进入输入模式,在文件的末尾添上如下代码
添加完成后,点击Esc按键,输入:wq保存并退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export classpath=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
- 输入
source /etc/profile或者. /etc/profile,使配置文件生效
([root@GPU ~]# source /etc/profile) - 输入
java命令,显示如下信息
([root@GPU ~]# java)
用法: java [-options] class [args…]
(执行类)
或 java [-options] -jar jarfile [args…]
(执行 jar 文件)
其中选项包括:
-d32 使用 32 位数据模型 (如果可用)
-d64 使用 64 位数据模型 (如果可用)
(省略)
-javaagent:[=<选项>]
加载 Java 编程语言代理, 请参阅 java.lang.instrument
-splash:
使用指定的图像显示启动屏幕
有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
- 输入
javac命令,显示如下信息
([root@GPU ~]# javac)
用法: javac
其中, 可能的选项包括:
-g 生成所有调试信息
-g:none 不生成任何调试信息
-g:{lines,vars,source} 只生成某些调试信息
(省略)
-J<标记> 直接将 <标记> 传递给运行时系统
-Werror 出现警告时终止编译
@<文件名> 从文件读取选项和文件名
- 输入
java和javac命令均无异常并不能说明安装成功,输入命令java -version,若出现以下信息,则非安装成功,需要进行补充操作
([root@GPU ~]# java -version)
openjdk version “1.8.0_161”
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
- 输入命令
rpm -qa | grep java,若显示如下信息,则需要将虚拟机自带的OpenJDK卸载
([root@GPU ~]# rpm -qa | grep java)
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.e17.x86_64
java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.e17.x86_64
tzdata-java-2018c-1.e17.noarch
java-1.7.0-openjdk-1.7.0.171-2.6.13.2.e17.x86_64
java-1.8.0-openjdk-1.8.0.161-2.b14.e17.x86_64
javapackages-tools-3.4.1-11.e17.noarch
- 输入命令
yum -y remove java-1.8.0-openjdk-headless-1.8.0.161-2.b14.e17.x86_64,点击回车进行卸载
([root@GPU ~]# yum -y remove java-1.8.0-openjdk-headless-1.8.0.161-2.b14.e17.x86_64) - 输入命令
yum -y remove java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.e17.x86_64,点击回车进行卸载
([root@GPU ~]# yum -y remove java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.e17.x86_64) - 输入命令
rpm -qa | grep java,出现如下信息即可,即不包含已卸载的JDK
([root@GPU ~]# rpm -qa | grep java)
tzdata-java-2018c-1.e17.noarch
python-javapackages-3.4.1-11.e17.noarch
javapackages-tools-3.4.1-11.e17.noarch
- 输入
source /etc/profile或者. /etc/profile,使配置文件生效
([root@GPU ~]# source /etc/profile) - 输入
java -version,显示如下信息即为安装成功
([root@GPU ~]# java -version)
java version “1.8.0_151”
Java™ SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot™ 64-Bit Server VM (build 25.151-b12, mixed mode)
- 输入命令
rm -f jdk-8u151-linux-x64.tar.gz,删除JDK安装包
([root@GPU ~]# rm -f jdk-8u151-linux-x64.tar.gz)
特别说明:所有虚拟机均执行“安装JDK”操作
安装Hadoop
- 输入命令
mkdir /hadoop,创建目录
([root@GPU~]# mkdir /hadoop) - 输入命令
tar -C /hadoop/ -zxvf hadoop-2.7.7.tar.gz,在上述目录中安装Hadoop
([root@GPU~]# tar -C /hadoop/ -zxvf hadoop-2.7.7.tar.gz) - 输入命令
cd /hadoop/hadoop-2.7.7,进入 hadoop-2.7.7目录中
([root@GPU~]# cd /hadoop/hadoop-2.7.7) - 输入命令
ll,若显示如下信息,则Hadoop安装成功
([root@GPU hadoop-2.7.7]# ll)
总用量 112
drwxr-xr-x 2 user ftp 194 7月 19 2018 bin
drwxr-xr-x 3 user ftp 20 7月 19 2018 etc
drwxr-xr-x 2 user ftp 106 7月 19 2018 include
drwxr-xr-x 3 user ftp 20 7月 19 2018 lib
drwxr-xr-x 2 user ftp 239 7月 19 2018 libexec
-rw-r–r-- 1 user ftp 86424 7月 19 2018 LICENSE.txt
drwxr-xr-x 3 root root 22 9月 29 19:14 logs
-rw-r–r-- 1 user ftp 14978 7月 19 2018 NOTICE.txt
-rw-r–r-- 1 user ftp 1366 7月 19 2018 README.txt
drwxr-xr-x 2 user ftp 4096 7月 19 2018 sbin
drwxr-xr-x 4 user ftp 31 7月 19 2018 share
- 输入命令
rm -f hadoop-2.7.7.tar.gz,删除Hadoop安装包
([root@GPU ~]# rm -f hadoop-2.7.7.tar.gz)
特别说明:所有虚拟机均执行“安装Hadoop”操作
关闭防火墙
- 输入命令
systemctl stop firewalld并执行
([root@GPU hadoop-2.7.7]# systemctl stop firewalld) - 输入命令
systemctl disable firewalld并执行
([root@GPU hadoop-2.7.7]# systemctl disable firewalld)
特别说明:所有虚拟机均执行“关闭防火墙”操作
关闭Selinux
- 输入命令
vi /etc/sysconfig/selinux进入selinux文件进行编辑
([root@GPU hadoop-2.7.7]# vi /etc/sysconfig/selinux) - 点击
i进入输入模式,找到代码段SELINUX=enforcing,将其改为SELINUX=disabled,点击Esc按键,输入:wq保存并退出
特别说明:所有虚拟机均执行“关闭Selinux”操作
修改hostname
- 输入命令
hostnamectl set-hostname master
([root@GPU hadoop-2.7.7]# hostnamectl set-hostname master) - 输入命令
hostname,若出现如下信息,则主机名称更改成功
([root@GPU hadoop-2.7.7]# hostname)
master
特别说明:所有虚拟机应设置不同的主机名称,能够区分即可
我将IP为172.16.29.94的虚拟机主机名设置为master(主节点),将IP为172.16.29.95的虚拟机主机名设置为slave1(第一个从节点),将IP为172.16.29.96的虚拟机主机名设置为slave2(第二个从节点),以此类推
即IP为172.16.29.95的虚拟机应执行的命令为hostnamectl set-hostname slave1
([root@CentOS ~]# hostnamectl set-hostname slave1)
IP为172.16.29.96的虚拟机应执行的命令为hostnamectl set-hostname slave2
([root@CentOS ~]# hostnamectl set-hostname slave2)
修改host文件
- 输入命令
vi /etc/hosts,对hosts文件进行编辑
([root@GPU hadoop-2.7.7]# vi /etc/hosts) - 点击
i进入输入模式,在文件末端添加如下代码后点击Esc按键,输入:wq保存并退出
代码格式为集群中的所有虚拟机的 IP+空格+主机名称
172.16.29.94 master
172.16.29.95 slave1
172.16.29.96 slave2
特别说明:后续操作有两种选择
选择1:所有虚拟机均执行“修改host文件”操作
选择2:由主机依次执行文件复制命令scp /etc/hosts 172.16.29.95:/etc/和scp /etc/hosts 172.16.29.96:/etc/,即有多少未执行“修改host文件”的虚拟机,主机就执行多少次该操作,将hosts文件发放至各个虚拟机,但是需要输入目的虚拟机的密码
重启虚拟机
输入命令reboot,重启虚拟机
重启虚拟机后,各主机名会发生变化
如IP为172.16.29.94的虚拟机为[root@master~]#
IP为172.16.29.95的虚拟机为[root@slave1~]#
IP为172.16.29.96的虚拟机为[root@slave2~]#
特别说明:所有虚拟机均执行“重启虚拟机”操作
设置SSH无密码登录
获取公钥
- 输入命令
cd ~回到根目录 - 输入命令
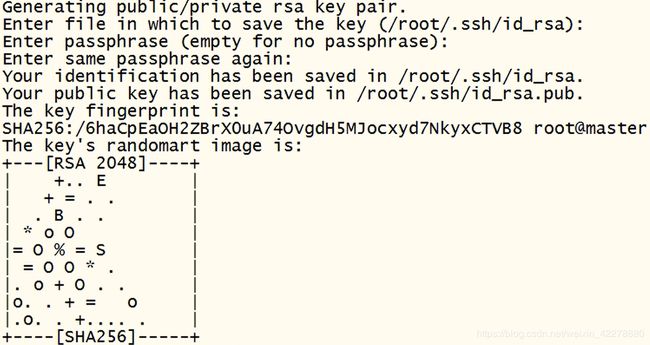
ssh-keygen,点击6次回车,出现如下信息
([root@master ~]# ssh-keygen)
- 输入命令
cd .ssh
([root@master ~]# cd .ssh) - 输入命令
cat ./id_rsa.pub >> authorized_keys
([root@master .ssh]# cat ./id_rsa.pub >> authorized_keys) - 输入命令
cat authorized_keys,将生成的公钥复制
特别说明:所有虚拟机均执行“获取公钥”操作
修改授权公钥文件
- 输入命令
vi authorized_keys,对authorized_keys文件进行编辑
([root@master .ssh]# vi authorized_keys) - IP为172.16.29.94的虚拟机(主节点)的authorized_keys文件中仅有一个结尾为
root@master的公钥,点击i进入输入模式,在后面添加IP为172.16.29.95的虚拟机在“获取公钥”操作中产生的公钥(结尾为root@slave1)和IP为172.16.29.96的虚拟机在“获取公钥”操作中产生的公钥(结尾为root@slave2),添加完成后点击Esc按键,输入:wq保存并退出

特别说明:后续操作有两种选择
选择1:所有虚拟机均执行“修改授权公钥文件”操作,即主机名为slave1的虚拟机将master和slave2虚拟机的公钥加入该文件,主机名为slave2的虚拟机将master和slave1虚拟机的公钥加入该文件
选择2:由主机依次执行文件复制命令scp ./authorized_keys slave1:/root/.ssh/和scp ./authorized_keys slave2:/root/.ssh/,即有多少未执行“修改授权公钥文件”的虚拟机,主机就执行多少次该操作,将授权公钥文件发放至各个虚拟机,但是需要输入目的虚拟机的密码
([root@master .ssh]# scp ./authorized_keys slave1:/root/.ssh/)
([root@master .ssh]# scp ./authorized_keys slave2:/root/.ssh/)
上述操作完成后,就可以进行SSH无密码登录,在master虚拟机上试验免密登录如下
[root@master ~]# ssh slave1
Last login: Tue Oct 8 21:38:59 2019 from master
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@master ~]# ssh slave2
Last login: Tue Oct 8 18:37:03 2019 from master
[root@slave2 ~]# exit
登出
Connection to slave2 closed.
若在其他的虚拟机上能够自由地进行SSH免密登录,则“设置SSH无密码登录”操作成功
修改Hadoop配置文件1
- 输入命令
cd ~,进入根目录 - 输入命令
cd /hadoop/hadoop-2.7.7/etc/hadoop,进入该目录
([root@master ~]# cd /hadoop/hadoop-2.7.7/etc/hadoop) - 输入命令
ll,会显示出如下文件
总用量 156
-rw-r–r-- 1 user ftp 4436 7月 19 2018 capacity-scheduler.xml
-rw-r–r-- 1 user ftp 1335 7月 19 2018 configuration.xsl
-rw-r–r-- 1 user ftp 318 7月 19 2018 container-executor.cfg
-rw-r–r-- 1 user ftp 1421 9月 29 19:33 core-site.xml
-rw-r–r-- 1 user ftp 3670 7月 19 2018 hadoop-env.cmd
-rw-r–r-- 1 user ftp 4271 9月 29 19:27 hadoop-env.sh
-rw-r–r-- 1 user ftp 2598 7月 19 2018 hadoop-metrics2.properties
-rw-r–r-- 1 user ftp 2490 7月 19 2018 hadoop-metrics.properties
-rw-r–r-- 1 user ftp 9683 7月 19 2018 hadoop-policy.xml
-rw-r–r-- 1 user ftp 1374 9月 29 19:33 hdfs-site.xml
-rw-r–r-- 1 user ftp 1449 7月 19 2018 httpfs-env.sh
-rw-r–r-- 1 user ftp 1657 7月 19 2018 httpfs-log4j.properties
-rw-r–r-- 1 user ftp 21 7月 19 2018 httpfs-signature.secret
-rw-r–r-- 1 user ftp 620 7月 19 2018 httpfs-site.xml
-rw-r–r-- 1 user ftp 3518 7月 19 2018 kms-acls.xml
-rw-r–r-- 1 user ftp 1527 7月 19 2018 kms-env.sh
-rw-r–r-- 1 user ftp 1631 7月 19 2018 kms-log4j.properties
-rw-r–r-- 1 user ftp 5540 7月 19 2018 kms-site.xml
-rw-r–r-- 1 user ftp 11801 7月 19 2018 log4j.properties
-rw-r–r-- 1 user ftp 951 7月 19 2018 mapred-env.cmd
-rw-r–r-- 1 user ftp 1383 7月 19 2018 mapred-env.sh
-rw-r–r-- 1 user ftp 4113 7月 19 2018 mapred-queues.xml.template
-rw-r–r-- 1 root root 886 9月 29 19:33 mapred-site.xml
-rw-r–r-- 1 user ftp 758 7月 19 2018 mapred-site.xml.template
-rw-r–r-- 1 user ftp 21 9月 29 19:33 slaves
-rw-r–r-- 1 user ftp 2316 7月 19 2018 ssl-client.xml.example
-rw-r–r-- 1 user ftp 2697 7月 19 2018 ssl-server.xml.example
-rw-r–r-- 1 user ftp 2250 7月 19 2018 yarn-env.cmd
-rw-r–r-- 1 user ftp 4612 9月 29 19:28 yarn-env.sh
-rw-r–r-- 1 user ftp 1699 9月 29 19:33 yarn-site.xml
- 下面要进行修改的是core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml以及slaves五个文件
这五个文件可以使用 vi+文件名 的方式在Xshell中更改(点击i进入输入模式模式,点击Esc按键,输入:wq保存并退出),也可以点击这里(提取码wsha)进行下载后,进行相应的修改,然后使用Xftp传输到相应的文件夹内进行替换
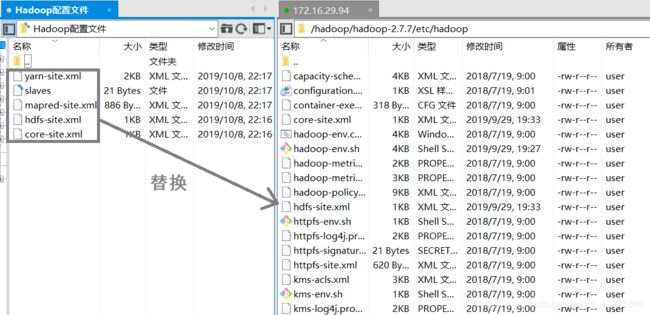
- 输入命令
vi core-site.xml(或者直接修改下载文件后上传),修改core-site.xml文件
([root@master hadoop]# vi core-site.xml)
该配置文件无需作改动
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
configuration>
- 输入命令
vi hdfs-site.xml(或者直接修改下载文件后上传),修改hdfs-site.xml文件
([root@master hadoop]# vi hdfs-site.xml)
由于 dfs.namenode.name.dir 和 dfs.datanode.data.dir 对应了两个新的目录,因此后续会进行相应的目录创建
dfs.replication 为分布式存储的副本数,默认为3
该配置文件无需作改动
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave1:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
- 输入命令
vi mapred-site.xml(或者直接修改下载文件后上传),修改mapred-site.xml文件
([root@master hadoop]# vi mapred-site.xml)
该配置文件无需作改动
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
- 输入命令
vi yarn-site.xml(或者直接修改下载文件后上传),修改yarn-site.xml文件
([root@master hadoop]# vi yarn-site.xml)
该配置文件无需作改动,其中的master可以替换为其IP地址(即172.16.29.94),但是非常不利于后续的维护(比如master节点的IP地址发生变化)
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>
- 输入命令
rm -f slaves(该文件禁止在本机修改之后上传,问题在于Windows系统的回车),删除slaves文件
([root@master hadoop]# rm -f slaves)
输入命令vi slaves,创建并编写该文件
([root@master hadoop]# vi slaves)
在文件中输入以下内容并保存
该文件为设置用作DataNode的虚拟机
通过这个设定可以发现,在这三台虚拟机中,master既作为NameNode也作为DataNode,slave1作为DataNode,slave2作为DataNode
其中的master、slave1、slave2可以替换为其IP地址,但是非常不利于后续的维护(比如某节点的IP地址发生变化)
master
slave1
slave2
特别说明:其余各虚拟机暂时无需执行“修改Hadoop配置文件1”操作,后文会有相关介绍
创建目录
在/hadoop目录下创建数据存放的文件夹temp、hdfs、hdfs/data、hdfs/name
- 输入
cd ~,进入根目录 - 输入
cd hadoop/,进入/hadoop目录
([root@master ~]# cd hadoop/) - 输入
mkdir /hadoop/tmp,创建tmp目录
([root@master hadoop]# mkdir /hadoop/tmp) - 输入
mkdir /hadoop/hdfs,创建hdfs目录
([root@master hadoop]# mkdir /hadoop/hdfs) - 输入
mkdir /hadoop/hdfs/name,创建hdfs/name目录
([root@master hadoop]# mkdir /hadoop/hdfs/name) - 输入
mkdir /hadoop/hdfs/data,创建hdfs/data目录
([root@master hadoop]# mkdir /hadoop/hdfs/data)
特别说明:其余各虚拟机暂时无需执行“创建目录”操作,后文会有相关介绍
修改Hadoop配置文件2
- 输入
cd ~,进入根目录 - 输入
cd /hadoop/hadoop-2.7.7/etc/hadoop/,进入/hadoop目录
([root@master ~]# cd /hadoop/hadoop-2.7.7/etc/hadoop/) - 输入
vi hadoop-env.sh,点击i进入输入模式,找到export JAVA_HOME=${JAVA_HOME},将其替换为JDK的安装路径,即export JAVA_HOME=/usr/local/java/jdk1.8.0_151,点击Esc按键,输入:wq保存并退出 - 输入
vi yarn-env.sh,点击i进入输入模式,在末尾添加export JAVA_HOME=/usr/local/java/jdk1.8.0_151,点击Esc按键,输入:wq保存并退出
特别说明:其余各虚拟机暂时无需执行“修改Hadoop配置文件2”操作,后文会有相关介绍
配置Hadoop环境变量
- 输入
vi /etc/profile,修改profile配置文件
点击i进入输入模式
在文件末尾添加export HADOOP_HOME=/hadoop/hadoop-2.7.7,即Hadoop安装路径
继续添加export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin - 输入命令
source /etc/profile,使配置文件生效
特别说明:所有虚拟机均执行“配置Hadoop环境变量”操作
完成其余虚拟机的相关配置
特别说明:“完成其余虚拟机的相关配置”有两种选择
选择1(推荐):将其余各虚拟机依次按照“修改Hadoop配置文件1”、“创建目录”、“修改Hadoop配置文件2”三项操作
选择2:在已经配置好的master节点中输入命令cd ~进入根目录,输入cd /hadoop/进入该目录,依次输入命令scp -r hadoop-2.7.7/ slave1:/hadoop/和scp -r hadoop-2.7.7/ slave2:/hadoop/
即([root@master hadoop]# scp -r hadoop-2.7.7/ slave1:/hadoop/)和([root@master hadoop]# scp -r hadoop-2.7.7/ slave2:/hadoop/)
该操作为将master结点hadoop目录中的hadoop-2.7.7目录中所有内容递归地复制到slave1和slave2的/hadoop目录下
不推荐的原因是在实际操作中,当hadoop-2.7.7目录中的所有内容复制到slave1和slave2时,出现了有的节点不存在master已经创建的/hadoop/hdfs/data或者/hadoop/hdfs/name
使配置文件重新生效
输入source /etc/profile,使配置文件生效
特别说明:所有虚拟机均执行“使配置文件重新生效”操作
格式化NameNode
输入命令hdfs namenode -format,进行格式化
特别说明:除主节点外其他虚拟机不需要执行“格式化NameNode”操作
启动Hadoop
输入命令start-all.sh,启动Hadoop
在主节点输入命令jps,应该显示如下6项信息
4736 ResourceManager
23249 Jps
1125 StandaloneAgent
4037 NameNode
4873 NodeManager
11881 DataNode
在slave1节点输入命令jps,应该显示如下5项信息
1109 StandaloneAgent
9366 Jps
15256 DataNode
5821 SecondaryNameNode
6189 NodeManager
在slave2节点输入命令jps,应该显示如下4项信息
16225 DataNode
1113 StandaloneAgent
23548 Jps
3853 NodeManager
注意:根据每个人的需求不同,其显示结果也不尽相同,比如我的主节点也用作了DataNode,因此会显示存在DataNode端口
打开浏览器,输入主节点虚拟机(master)的 IP地址+端口8088(如172.16.29.94:8088),点击页面左侧的Nodes,会出现集群内所有虚拟机的信息
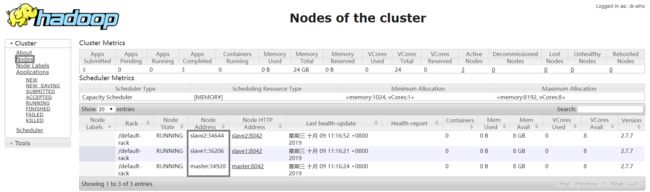
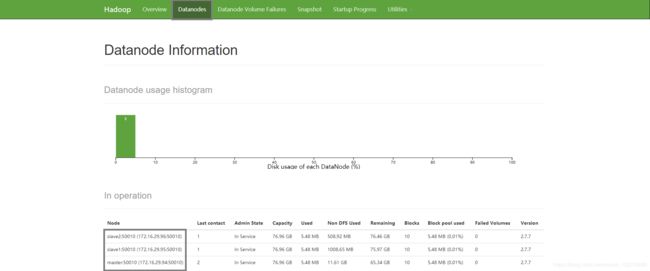
打开浏览器,输入主节点虚拟机(master)的 IP地址+端口50070(如172.16.29.94:50070),点击页面上方的Datanodes,会出现集群内所有虚拟机的信息
多台Linux虚拟机Hadoop集群的安装与部署到此就告一段落
有疑问的朋友可以在下方留言或者私信我,我尽量尽早回答
欢迎各路大神指点、交流!
求关注!求点赞!求转发!