街景字符编码识别项目学习笔记(二)pytorch in deep learning
内容简介
本文为针对Datacamp上的Introduction to deep learning by pytorch课程的学习总结。Datacamp(官网链接)内含许多python的专题知识讲解,以几分钟的视频教学加在线编程实操为主。笔者在下两个博客中将总结pytorch中的基本张量创建以及其在深度学习当中的一些应用,最终将实现Alexnet并完成从读取数据到训练评估的全过程。本博客先总结tensor的基本运算,而后实现基本的全连接神经网络,下个博客将介绍卷积神经网络相关操作,并实现AlexNet。
tensor创建与基本运算
创建一个tensor
tensor_1 = torch.tensor([2.,-4.])
创建一个m行n列的tensor 每一个元素为0-1随机 此随机分布为均匀分布
tensor_1=torch.rand(m,n)

创建一个m行n列的tensor 每一个元素为均值为0 方差为1的高斯分布
tensor_1=torch.randn(m,n)
对二维tansor的索引 高维也如此
print(tensor_1[1][2])
修改tensor中的数值 tensor中每一个元素的类别为 torch.tensor
tensor_1[1][2]=3
print(tensor_1[1][2])
创建一个m行n列全为1的二维tensor
tensor_1 = torch.ones(m,n)
创建一个m行n列全为0的二维tensor
tensor_1 = torch.zeros(m,n)
创建一个n1行n2列的单位tensor(n1=n2) 当n2>n1时 多出来的列会全为0
tensor_1 = torch.eye(n,n)
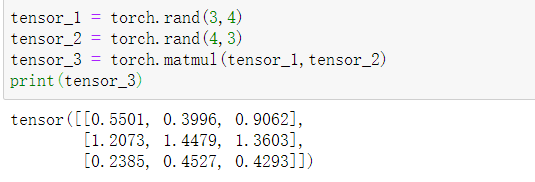
实现二维张量的点乘
tensor_3 = torch.matmul(tensor_1,tensor_2)
创建基本的神经网络 (PyTorch 风格)
当一个张量反向传播时需要求解梯度需要对张量进行如下说明
x = torch.tensor(4., requires_grad=True)
当我们希望数字4置换为上文提到的矩阵时,操作如下
tensor_1 = torch.rand(3,4)
tensor_1.requires_grad_(True)

一个简要的pytorch风格神经网络如下所示
import torch
import torch.nn as nn #torch.nn.Module 为所有模型的基类 此为继承关系
class Net(nn.Module): #继承基类
def __init__(self):
super(Net,self).__init__() #super 为调用父类的方法
self.fc1 = nn.Linear(10,20) #这里的nn.Linear 即为神经网络中的线性全连接层 10为前层神经元个数 20为后层神经元个数
self.fc2 = nn.Linear(20,20)
self.output = nn.Linear(20,4) #至此我们实现了一个10输入4输出的全连接神经网络(Fully connected neural network)
def forward(self,x) #定义张量x的反向传播
x = self.fc1(x) #张量经过了fc1层进行了更新 下同
x = self.fc2(x)
x = self.output(x)
return x
input_layer = torch.rand(10) #创建了一个1*10的tenosr 符合网络层的输入
net = Net() #实例化
result = net(input_layer) #获得网络的输出
一些常用的激活函数总结如下图

使用ReLU激活函数的例子如下所示
import torch.nn as nn
relu = nn.ReLU() #实例化ReLU激活函数
tensor_1 = torch.tensor([2.,-4.])
print(relu(tensor_1))
使用交叉熵损失函数的例子如下所示
import torch.nn as nn
logits = torch.tensor([[3.2,5.1,-1.7]]) #定义输入
ground_truth = torch.tensor([0]) #定义全局真值
criterion = nn.CrossEntropyLoss() #实例化交叉熵损失函数 实际上这是模型的评价标准的设定方法
loss = criterion(logits,ground_truth)
print(loss)
用PyTorch创建数据集
import torch
import torchvision #torchvision是独立于pytoch的一些处理图像的工具库
import torch.utils.data #用于读取数据 包括 Dataset DataLoader Sampler 三个类
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.Totensor(), #转换为tensor
transforms.Normalize((0.4914,0.48216,0.44653),
(0.24703,0.24349,0.26159))])
torchvision.transforms 是pytorch中的图像预处理包,包含了很多种对图像数据进行变换的函数,这些是将数据集转换为网络正确输入的必不可少的步骤。上述两个函数的功能为:
- transforms.Totensor() 将一张PIL图像转换为张量(convert a PIL image to tensor (HWC) in range [0,255] to a torch.Tensor(CHW) in the range [0.0,1.0])
- transforms.Normalize()用给定的均值和标准差分别对每个通道的数据进行正则化。因为一张图片一般为3通道,所以每一组三个数字分别对应的是三个通道。(Normalized an tensor image with mean and standard deviation)
标准化过程的数学表达为:
输 出 ( o u t p u t ) = 输 入 ( i n p u t ) − 均 值 ( m e a n ) 标 准 差 ( s t d ) 输出(output) = \frac{输入(input)-均值(mean)}{标准差(std)} 输出(output)=标准差(std)输入(input)−均值(mean)
以下以读取CIFAR10数据集为例说明pytorch划分数据集以及测试集的方式
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform) #这里实际上是从网络上自动下载CIFAR10数据集到根目录下 下同
testset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=32,shuffle=True,num_workers=0)
testloader = torch.utils.data.DataLoader(testset,batchsize=32,shuffle=False,num_workers=0)
对loader的定义中,batchsize定义同训练时的batchsize定义。shuffle为是否将数据集乱序,num_workers为训练过程当中的线程数目。因为Windows中只支持单线程,所以在win10等系统中num_workers为0,在Linux系统下按需设置。
对dataloader进行可视化
print(testloader,dataset.test_data.shape,trainloader.dataset.train_data.shape)
print(testloader.batch_size)
print(trainloader.sampler)
Training by PyTorch
定义神经网络基本架构,其中包含两层全连接层 输入为32*32的三通道图像
import torch
import torch.nn
import torch.nn.functional as F #取pytorch当中已经定义好的函数
#定义神经网络的基本架构
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(32*32*3,500)
self.fc2 = nn.Linear(500,10)
def forward(self,x):
x = F.relu(self.fc1(x))
return self.fc2(x)
net = Net() #实例化神经网络
criterion = nn.CrossEntropyLoss() #采用交叉熵函数作为输出与ground truth的衡量标准
optimizer = optim.Adam(net.parameters(),lr=3e-4) #这里定义优化器 采用Adam作为梯度下降算法 同时加上权重的二范数正则化项 正则化项的系数为lr变量
for eopch in range(10): #定义训练进行的epoch数目
for i,data in enmerate(trainloader,0):
inputs,label = data
inputs = inputs.view(-1,32*32*3) #view方法是对张量的行列进行重新排列 此处转换为1行32*32*3的张量
optimizer.zero_grad() #将梯度全部初始化为0
outputs = net(inputs)
loss = criterion(output,labels)
loss.backward() #建立梯度的反向传播过程 反向传播求解梯度
optimizer.step() #将模型当中的所有参数针对梯度进行更新
Using net to get predicts by PyTorch
承接上一节的代码
correct.total = 0,0 #定义正确的数目和全部的数目
predictions = []
net.eval()
for i,data in enumerate(testloader,0):
inputs,labels = data
outputs = net(inputs)
~,predicted = torch.max(outputs.data,1)
predictions.append(outputs)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('The acc is: %d %%'%(100*correct/total))