深度神经网络算法分析
深度神经网络算法分析
人工智能的分类
- 弱人工智能:特定任务与人类智力或者效率持平
- 通用人工智能:具有人类智力水平,解决通用问题
- 超人工智能:超过人类智力水平,可以在创造力上超过常人
机器学习的类型
- 监督学习:通过标签的训练数据集(人脸识别)
- 无监督学习:通过无标签数据集自动发掘模式(文本自聚类)
- 增强学习:通过反馈或者奖惩机制学习(游戏)
人工智能,机器学习,深度学习的关系
- 人工智能:它是研究,开发用于模拟,延伸和扩展人的智能的理论,方法,技术和应用系统的一门技术科学
- 机器学习:如果一个程序可以在任务T上,随着经验E的增加,效果P也可以随之增加,则称这个程序可以在经验中学习
- 深度学习:基于深度人工神经网络,自动地将简单的特征组合成更加复杂的特征,并使用这些组合特征解决问题。
人工智能是个大范围,包括了机器学习,机器学习包括了深度学习
深度学习的应用
- 语音识别
- 计算机视觉
- 自然语言处理
深度学习与传统机器学习的差别
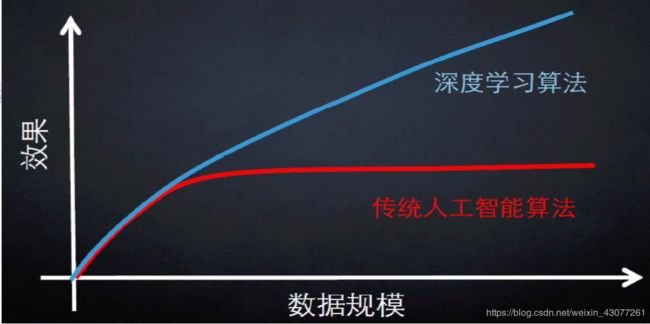
深度学习的三个基础算法
- DNN(deep neural networks)
- CNN (convolutional neural networks)
- RNN (recurrent neuron network)
深度学习与人工神经网络
一句话来说就是深度学习的基础就是人工神经网络,而人工神经网络是由生物神经网络的启发得来的。

人工神经网路的最小单元称为感知机,但是现在常常称为神经元。
神经元的内部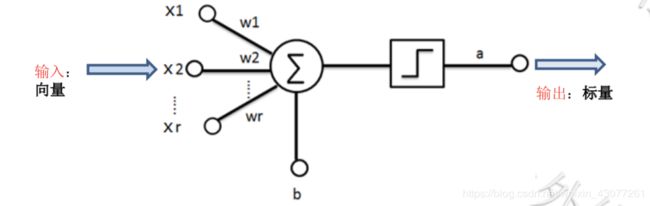
神经元是是人工神经网络的最小单元
在上图中
- 输入:一个向量
- 输出:一个标量
- 在中间部分,一个大圆,一个正方形,代表运算
- 线性变换(加权求和)
- 非线性变化(非线性函数)
输出就是由线性变换和非线性变换得到的
其实每个神经元可以看作一个复合函数,整个神经网络就是一个大的复合函数
于是,神经元内部的运算,就可以分开看成下面两个函数,其中w,b分别为权重和偏秩,一开始可以人为取值,随着机器的不断学习,w和b会不断的更新。
z = ∑ i = 1 k f ( x i ) = x 1 w 1 + x 2 w 2 + x 3 w 3 + . . . . . + x k w k + b a = g ( z ) z=\sum_{i=1}^{k}f(x_i)=x_1w_1+x_2w_2+x_3w_3+.....+x_kw_k+b\\ a=g(z) z=i=1∑kf(xi)=x1w1+x2w2+x3w3+.....+xkwk+ba=g(z)
可以看出, a = f ∘ g ( x 1 , x 2 , x 3 . . . . . , x k ) a=f\circ g(x_1,x_2,x_3.....,x_k) a=f∘g(x1,x2,x3.....,xk)的复合函数形式。
also:
通过人为设置得到的参数称为超参数。
系统输入与输出
深度学习模型本质上也是一个运算过程

以房价预测为例:
样本(特征值):面积,楼层,户型。。。。
标签:价格
那么通过采集得到的数据集应该是下面这样:

多层感知机
神经网络又被称为多层感知机模型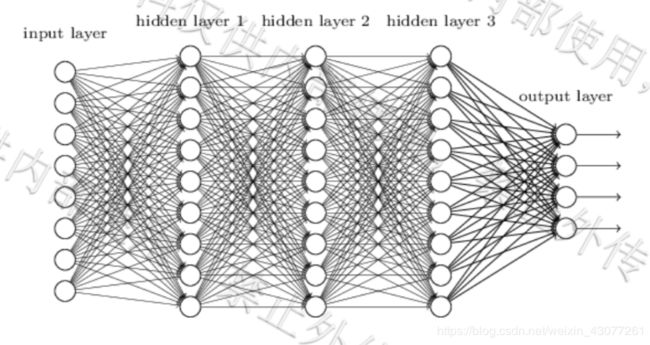
上图中一共有四层神经模型,不算入input层,只有参与运算过程的层数才能算进去,包括output层
FC(全连接):每个神经元都和下一层的所有神经元相连
训练过程三部曲
1. 正向传播(从input到output,计算预测值)
- 参数( w , b w,b w,b)
- 常见的激活函数
2. 反向传播(从output到input)
- 常见的损失函数
- BP算法
3. 梯度下降
- 参数的更新过程
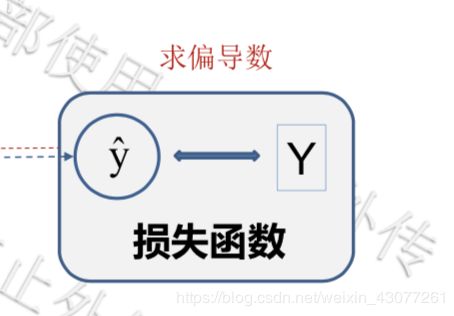
通过预测值和真实值之间的损失函数不断的求偏导数,更新w,b的值。
w = w − ∂ d w w=w-\partial dw w=w−∂dw
b = b − ∂ d b b=b-\partial db b=b−∂db
- 学习率
- 梯度下降的三种方式
激活函数
在上面提到的 a = g ( z ) a=g(z) a=g(z),其中g就是激活函数,存在于非线性变换里面。通过引入激活函数,使得模型具有非线性的划分能力。将每个线性组合送入激活函数,将输出结果送入下一层神经元的输入。
常见的激活函数:
sigmoid函数:(logistic函数)
早期流行的激活函数,RNN-LSTM网络还会用到。
f ( z ) = 1 1 + e − z f(z)=\displaystyle\frac1{1+e^{-z}} f(z)=1+e−z1
特点是:
- 将一个是实数映射到(0,1)之间
- 在特征相差不大的时候效果比较好
用法:
通常用来做二分类
缺点:
- 激活函数计算量大
- 容易出现梯度消失:当数据分布在曲线平滑位置的时候很容易出现梯度消失,梯度容易饱和。
图像(python 绘制):

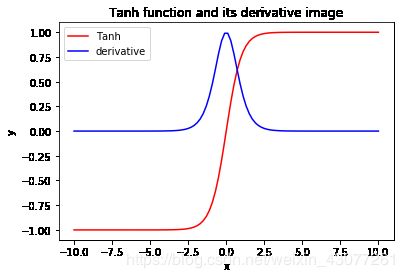
Tanh 函数(双切正切函数)
f ( x ) = e x − e − x e x + e − x \displaystyle f(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} f(x)=ex+e−xex−e−x
特点:
- 取值范围为[-1,1]
- 输出以0为中心
- 可以看成是一个放大版本的sigmoid函数
用法:
- tanh函数比sigmoid函数更加的常用
- 循环神经网络会用
- 二分类问题
- 靠近输出值位置
缺点:
- 梯度容易消失
- 在曲线水平的区域学习非常的慢
图像:
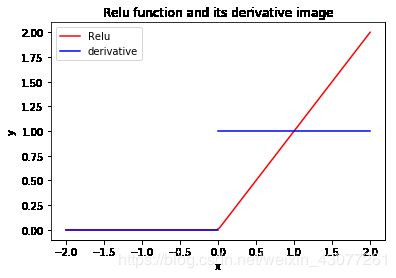
Relu 函数(激活函数的重要发明)
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
特点:
- relu函数对与梯度收敛有巨大加速作用
- 只需要一个阀值就可以得到激活值节省计算量
用法:
深层网络中隐藏层常用
缺点:
过于生猛,一言不合就会使得数据变为0,从此结点后的相关信息全部丢失。
图像:
其实还有一种函数leaky-ReLU 函数,就是在其负区间弄一定斜率的函数,解决RELU函数的0区间带来的影响,一般为 m a x ( k x , 0 ) max(kx,0) max(kx,0),k就是leak常数,一般为0.01或0.02,或通过学习得到。
also:
图像绘制可以看sigmoid Relu and tanh函数图像绘制
特殊的激活函数
- SoftMax函数
- 线性激活函数
y = x y=x y=x,仅仅用于线性回归