爬取古诗词网的诗经全文
爬取古诗词网的诗经全文
- 1、基本介绍及爬取
- 2、存储
- 3、转到word
1、基本介绍及爬取
首先我们看一下古诗词网上诗经的网页是怎么样的一个布局。
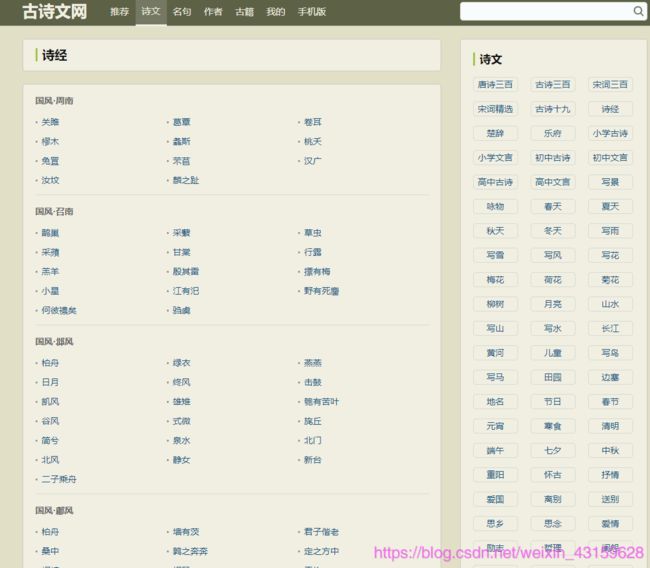
如图所示,在诗经的网页上,可以看他它的小标题排列的顺序,点进去每个标题既可以看到对应的诗经的文字,那么基本的思路就有了,我们找到现在的网页上的诗经“目录”区域的所有诗名的链接,并把这些链接放置到数组中,然后分别访问这些连接,并获取链接中的我们需要的网页内容。
下面我们分析下诗文的网页是如何布置的。

如上图所示,我们可以看到上面的第一个“框”包含了关雎这个小标题的诗文以及年代作者等信息,那么这就说明我们需要爬取的诗文的内容基本上都是在第一个“框”中的,所以我们可以F12来看一下这个框相对于其他框的不同点,然后根据代码获取第一个框的信息。这样子,我们基本上就把诗经中所有的诗文全部爬下来了。
2、存储
我们在第一节中介绍了爬取诗文的基本思路,但是,以上还都是将数据存储在我们创建的字典或者数组里面,这个时候我们需要写到电脑的文件中,在这里我本人推荐写入到.csv文件中,因为方便后期对数据做改动,毕竟诗文的各种信息,放到文本文件里面就会显得很乱。输出到文件后经过简单的整理,如下图所示。

3、转到word
在excel中做好基本的整理后,我们可以通过将其通过邮件合并或者其他方式导入到word中,然后再做一些简单的编辑,我们的诗经小本本就做好了。当然,有设计想法的人可以通过这样子将诗经设计成自己喜好的样子。

具体代码如下:
import requests
import pandas as pd
from bs4 import BeautifulSoup
import re
pname = []
u= "https://so.gushiwen.org"
url = "https://so.gushiwen.org/gushi/shijing.aspx"
url_list = []
pintroduction = []
pcontent =[]
def get_herf(url):
con = requests.get(url)
content = BeautifulSoup(con.content, "lxml")
for i in content.find_all("div", class_="typecont"):
list = i.find_all("span")
for j in range(len(list)):
herf = str(list[j])
# 通过正则表达式截取相应的字符
p = "\"/.+?\""
pattern = re.compile(p)
if len(herf) > 41:
new = pattern.findall(herf)
url_list.append(new[0].replace("\"", ""))
# 简单的方法,通过找到某个字符的前两个下标进行截取
# index = herf.find("\"")
# index1 = herf.find("\"", index+1)
# if len(herf) > 41:
# url_list.append(herf[15:41])
# print(url_list)
return url_list
def get_poems(url):
p = "[\u4e00-\u9fa5。:,?!]+"
pattern = re.compile(p)
con = requests.get(url)
content = BeautifulSoup(con.content, "lxml") # 解析html内容
c = content.find("div", class_="sons")
# print(str(c))
n = c.find("h1").string # 诗歌名称
intr = str(c.find("p", class_="source")) # 诗歌介绍数组
cont = str(c.find("div", class_="contson")) # 诗词内容数组
intro = "".join(pattern.findall(intr)) # 转换为诗歌介绍字符串
conte = "".join(pattern.findall(cont)) # 转换为诗词内容字符串
pname.append(n)
pintroduction.append(intro)
pcontent.append(conte)
# print(pname)
return pname, pintroduction, pcontent
def write_csv(list, list2, list3):
dataframe = pd.DataFrame({'name':list, 'introduction':list2, 'content':list3})
dataframe.to_csv("F://poems.csv", index=False, sep=',', encoding="utf_8_sig")
return
if __name__ == "__main__":
url_list = get_herf(url)
for i in url_list:
newu = u + str(i)
get_poems(newu)
print(newu, "已完成!")
write_csv(pname, pintroduction, pcontent)
以上。