数据库系统复习
文章目录
- Chapter1.数据库系统概论
- 教学内容
- 考点
- Chapter2.关系数据模型
- 教学内容
- 考点
- Chapter3.SQL
- 教学内容
- 考点
- Chapter4.事物处理与故障恢复
- 教学内容
- 考点
- Chapter5.设计合理性验证
- 教学内容
- 考点
- Chapter6.NoSQL
- 教学内容
- 考点
Chapter1.数据库系统概论
教学内容
-
数据 + 有用性 = 信息;
-
一个理念(Philosophy):关系数据模型;
-
一个语言:SQL;
-
一种专业技能:database design;
-
一种专业素质:应用程序开发:
HTML/DOM/CSS, Jscript
JDBC/ODBC, ADO;
-
一个台阶:性能优化,事务处理;
-
一种风尚:
对象关系数据库Object–Relational DBMS;
分布式数据库 Distributed DBMS;
数据仓库和数据挖掘Data warehousing and data mining;
-
教学重点:数据库的特征和特性;数据库系统的特征和特性;数据库技术要解决的五大问题;数据库系统的邦联式构成特性;
考点
-
采用数据库方式集中存储和管理数据
其目标是:提高数 据的共享性、真实性,降低数据管理成本
其前提是:数据库与用户之间的通信通道要畅通和可靠,而且费用低廉,速度快
-
数据库、数据库管理系统、数据库应用程序三者合起来构成数据库系统
-
存储数据库并运行数据库管 理系统软件的计算机叫作数据库服务器
-
数据库管理系统中的五个基本问题是:
数据正确性问题
数据处理性能问题
数据操作简单性问题
数据安全问题
数据完整性问题
-
数据模型 是数据库中最基本的概念。数据模型是指表达数 据库中数据以及数据之间的关系的基本概念。包括数据结构、数据操作、数据上的约束,其中最主要 的内容是数据结构。
-
关系数据模型 将数据保存在由行和列组成的表中,其好处是:用户查询 数据时,不需要知道其存储结构,数据操作简单,用户容 易掌握。关系数据模型 将数据保存在由行和列组成的表中,其好处是:用户查询 数据时,不需要知道其存储结构,数据操作简单,用户容 易掌握。
Chapter2.关系数据模型
教学内容
- 教学重点:掌握关系数据模型中的四大数据完整性约束,尤其是主键、外键概念。
考点
-
关系代数中的运算类型
一元运算:
选择Selection σ
投影Projection Π
二元运算:
横向联接:
Cartesian product ×
联接Join ⋈
纵向联接:
Union ∪
Difference -
Intersection ∩
Division ÷
-
关系运算:实现业务数据与数据库中的数据之间的转换
-
5个基本的运算:σ, Π, ∪, -, ×,其他运算可以由这5个基本运算代替
-
四大数据完整性约束:主键约束、外键约束(实体之间的联系)、域约束、业务规则约束
Chapter3.SQL
教学内容
- 教学重点:五大数据操作的DML语言表达;表模式的DDL语言表达;
考点
-
SQL: Structured Query Language is the standard query language for relational databases.
-
DDL&DML: SQL consists of both a Data Definition Language and a Data Manipulation Language
-
DML是对实例,对记录的增删改查统计。
-
DATE’2020-01-01’, TIME’23:59:59’ 日期型的常量要用函数来转化。
-
字符型常量的前后用单引号括起来,两个单引号表示一个单引号字符: ‘Master’‘s’.
-
小数:DECIMAL(4,1)
-
往表中添加一行记录:
INSERT INTO 表名 (字段1, 字段2) VALUES (数据1, 数据2);
INSERT INTO 表名 VALUES (数据1,数据2,数据3, 数据4, 数据5, 数据6, 数据7); -
对一个表,选定行,修改其列的值:
UPDATE staff SET salary = salary*1.10; UPDATE staff SET salary = salary*1.2 WHERE BranchNo = 'B01'; UPDATE staff SET salary = salary + 500 WHERE staffNo = '2004213';修改一行时,WHERE条件中一定要指定主键字段。
-
对一个表,选定行,将其删除:
DELETE FROM staff; DELETE FROM staff WHERE salary > 9000; DELETE FROM staff WHERE staffNo = '2004213'; DELETE FROM student WHERE s_no LIKE '2012%';删除特定的一行时,WHERE条件中一定要指定主键字段。
-
对一个表,查询记录:
SELECT FROM WHERE
等值查询:null,确定值;
SELECT name FROM staff WHERE position = 'secretary'; SELECT name FROM student WHERE d_no IS NULL;范围查询:连续型,离散型;
WHERE salary < 10000 AND salary >= 1500; WHERE rank IN ('教授','研究员','高级工程师'); WHERE birthday >= DATE('1980/01/01');模糊查询:LIKE ,两个特意符号,%,_, 转意符
WHERE name LIKE '张%'; WHERE name LIKE '张 ==_ _=='; WHERE email LIKE 'rj#_**%**@hnu.edu.cn’ ESCAPE #;去重、排序:
SELECT DISTINCT sex, birthday FROM student WHERE d_no = '590' ORDER BY class_no, s_no DES;ASC为升序,DES为降序,默认为升序。
-
统计Statistics
COUNT, SUM, AVG, MIN, MAX
COUNT, MAX, MIN 可对任一类型的字段, 而SUM and AVG 只对数值型字段.
SUM, AVG, MIN, MAX 要求查询结果只有一列.
先查询,再对查询结果进行统计;
除了 COUNT() , 其它函数都忽略null值;
统计结果是单一的值;从表概念来说,只一行数据;
-
分组统计GRUOP BY
先对查询结果,选定某一字段或者某些字段(叫分组字段)进 行分组:对查询结果的行,将分组字段的值相同的行放在一起 构成一个组。于是,可能会形成多个组。再对每个小组分别进 行统计
-
分组统计执行顺序
先执行查询, WHERE 语句;
然后执行分组, GROUP BY 语句
执行统计,聚集函数
再执行筛选, HAVING进行过滤
最后执行排序,ORDER BY 对结果排序
-
笛卡尔乘积运算,自然联接运算
笛卡尔乘积运算
SELECT b.*, s.* FROM Branch AS b , staff AS s;自然联接运算
SELECT b.*, s.name,staffNo, position FROM Branch AS b , staff AS s WHERE b.deptNo = s.d_no; -
在数据库中创建表
CREATE TABLE Student ( sno CHAR(10) NOT NULL, sname CHAR(10) NOT NULL, sex VARCHAR(6) CHECK (rank IN (‘男’,‘女’)), native VARCHAR(8), birthday DATE, classno CHAR(2), addr VARCHAR(48), phone VARCHAR(12), dno VARCHAR(8), PRIMARY KEY (sno), FOREIGN KEY (dno) REFERENCES Department(dno) ); -
视图
CREATE VIEW specified_student(id, name, class) AS SELECT sno, sname, classno FROM student AS s, teacher AS t, course AS c, enroll AS e WHERE t.tname='杨大侠' AND c.cname='数据库系统' AND e.semester='2010/01' AND s.sno=e.sno AND t.tno=e.tno AND c.cno=e.cno;用户:
SELECT * FROM specified_student; -
储存过程Stored procedure
提升视图的适应性,使其通用化:上课点名清单
CREATE PROCEDURE my_students(@semesterV IN VARCHAR, @courserV IN VARCHAR, @teacherV IN VARCHAR)AS BEGIN SELECT studentNo, name, class FROM student AS S, enroll AS E, course AS C, teacher AS T WHERE S.studentNo = E.studentNo AND C.courseNo = E.courseNo AND T.teacherNo = E.teacherNo AND C.name = @courseV AND E.semester = @semesterV AND T.name=@teacherV; END;用户:
CALL my_students( '2014/01','数据库系统', '杨大侠'); -
存储过程带来的好处
应用程序或者用户见到的是存储过程,视图,而不是表;
用户不用学SQL语言了;
因为带变量,有很强的适应性,通用性;
能够将业务规则约束,放在存储过程中加以实现;
还有函数,可以带上返回值; -
DDL删除或者修改一个对象
• DROP TABLE emp; • ALTER TABLE emp ………;
• DROP VIEW staff; • ALTER VIEW staff ………;
• DROP PROCEDURE add_enroll; • ALTER PROCEDURE add_enroll;
• DROP TRIGGER staff_insert; • ALTER TRIGGER staff_insert;创建:CREATE
删除:DROP
修改:ALTER
-
使用触发器实现每个房间的预订不重叠冲突
CREATE TRIGGER trigger_insertBooking BEFORE INSERT ON booking REFERENCING NEW ROW AS new FOR EACH ROW BEGIN WHERE ( EXIST SELECT hotelNo, roomNo FROM booking WHERE hotelNo = newrow.hotelNo AND roomNo = @new.roomNo AND dateTo >= @new.dateFrom AND dateFrom <= @new.dateTo) raise_application_error(20000, '这个预定与已有预订有重叠'); END; -
给用户分派角色 ,给用户(角色)授权,收回权限
GRANT student TO chen_song; GRANT SELECT ON dept TO PUBLIC; GRANT SELECT, UPDATE(salary) ON Emp TO Manager,Director; GRANT ALL PRIVILEGES ON Proj TO Director WITH GRANT OPTION; REVOKE SELECT ON dept FROM PUBLIC; REVOKE ALL PRIVILEGES ON Emp FROM Joe;
Chapter4.事物处理与故障恢复
教学内容
- 教学重点:事务的概念,故障类型,故障恢复方法。
考点
-
事务的ACID属性:
原子性(Atomicity): 一个事务中的操作要求要么全部执 行,要么全部不执行.
一致性(Consistency): 在外部看来,数据库中的数据总 是正确的.
隔离性(Isolation): 尽管多个事务在并发执行,但从外 部看来,具有多个事务串行执行的效果.
持久性(Durability):一个事务一旦提交了,即使随后发 生故障,其结果在数据库中不会丢失.
-
故障恢复方法一:分页方法
对每个事务:
-
把要访问的数据页读入内存;
-
数据处理;
-
把修改了的数据页作为一个新页写回磁盘,注意不要覆盖旧页;
-
完成第3步操作后,在磁盘上删除过时了的旧页;
优点:简单
故障恢复方法:如果因故障导致第3步没有完成,那么原数据 页还在,就当该事物没有发生看待,保证了事物的原子性;
缺点: 效率不高
原因是:磁头要在磁盘盘面上到处来回移动。因为磁头一会要 读事物要处理的数据页,一会要去磁盘上的哪个地方找一个空 闲页来写修改后的数据,还要回过头来删除旧页。
-
-
方法二:日志方法(广泛采用)
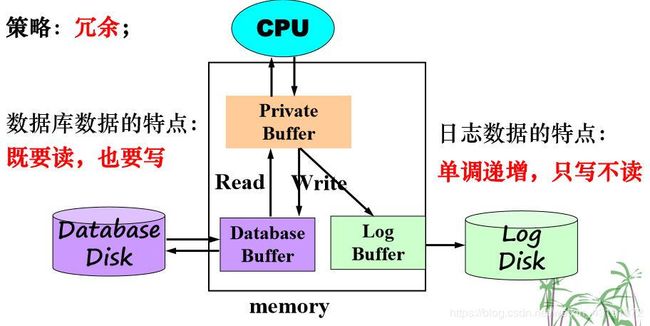
有两种同步约束:
1)当数据库缓冲区中的某个内容要输出到数据库磁盘时,必 须先把与其相关的日志缓冲区内容输出到日志磁盘(WAL ) ;
– 数据库缓冲区中数据要输出到磁盘,是因为当要从磁盘 中读数据到内存空间来进行处理时,必须先为其先腾出 空间来;
2)当事务 Ti 完成,遇到< Ti commit >记录时,要把日志缓 冲区的内容输出到日志磁盘,以便保证事物的四个属性;恢复方法:执行回卷(Rollback)操作:当事物 T i 要撤销 时,反向扫描日志内容,对 T i 的每项数据操作记录, 执行undo(Ti) 操作,使用旧值恢复数据项的原有值, 即撤销事务所做的数据操作;直至遇到 < T i start >
记录为止,然后放弃 T i ;系统崩溃故障的恢复方法:
① 重启数据库管理系统;
② 从日志磁盘读取日志文件;
③ 反向扫描日志,即从日志文件的结束位置开始后向扫描。对 于在日志记录中没有< Ti commit > 记录的事物,执行回卷操 作(Rollback),使用旧值恢复数据项,做撤销处理:
④ 然后从日志文件的开始位置前向扫描。 对日志记录中含有 < Ti commit >的事务 , 执行redo( T i) 操作,使用新值赋值数据 库中的数据项,确保事物的生效性;检查点:
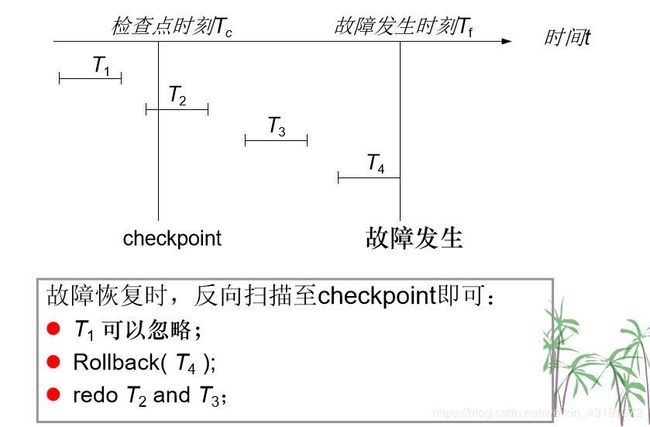
备份(Dump)操作-应对数据库磁盘故障:周期性地执行备份(dump) 操作,对磁盘数据库进行磁盘备份:
① 不再接收客户事务请求,让当前所有活动事务执行完毕;
② 输出日志缓冲区中的日志记录到日志磁盘中;
③ 输出数据库缓冲区中的缓冲数据到数据库磁盘中;
④ 把数据库磁盘中的数据库文件拷贝到另一个磁盘上;⑤ 往日志磁盘中写入一条 < dump > 日志记录;
⑥ 接收客户事物请求,恢复正常处理;
数据库磁盘故障的恢复方法:
① 用最近备份的数据库磁盘替换掉失效的数据库磁盘;
② 重启数据库管理系统;
③ 读日志文件,从文件末尾反向扫描直至< dump >记录;
④ 再顺向扫描日志记录,对有< Ti commit >记录的事务 做redo(Ti)操作;
日志磁盘故障的恢复方法:
① 不再接收客户事务请求,让当前的所有活动事务执行完毕;
② 输出数据库缓冲区中的缓冲数据到数据库磁盘中;
③ 执行备份(Dump)操作,把磁盘中的数据库文件拷贝到另一个磁盘上;
④ 用一个好的磁盘更换日志磁盘;
⑤ 恢复正常处理;
日志磁盘和数据库磁盘同时故障:
无法修复,小概率事件
-
容灾-远程备份
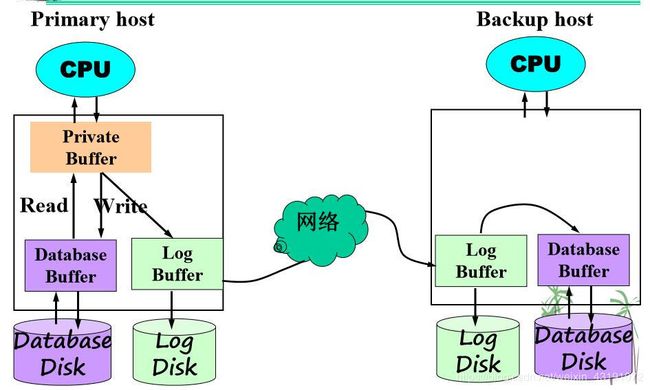
Chapter5.设计合理性验证
教学内容
- 数据库设计不合理时存在问题的表现形式,一个属性集是否是候选键的判定方法,五个范式;
考点
-
函数依赖的含义函数: Y = f(X): 给定变量X的一个值,那么就有唯一的一个y值 与其对应。记为:X→Y,X决定Y,或者说,Y依赖于X。
-
对于一个关系中的属性,函数依赖( functional dependency (FD))描述属性之间的关系(relationship);
-
X表示属性的集合,Y表示一个属性。记作: X → Y,其含义是X决 定Y,或者说,Y依赖于X。
-
对于函数依赖A → B,如果从A中去掉任一个属性,依赖关 系不再成立,那么 A → B是一个完全函数依赖。 也说,B完全函数依赖于A; 如果从A中去掉任一个属性,依赖关系依然成立,那么就说 B部分 函数依赖于A;
-
X的闭包应用一
当要判定一个函数依赖 X → Y 是否成立时,就只要计算 X+ ,如 果Y X+,那么函数依赖 X → Y就成立。
例如: R = (A,B,C,D,E,G), F = {A → B,C ; C → D; D → G} 判断C,D → G 是否成立 ? 解:计算 {C,D}+ = {C,D,G}, 它包含G ,因此C,D → G 成立.
判断B,C → E 是否成立 ? 解:计算 {B,C}+ = {B,C,D,G},不包含E, 因此B,C → E 不成立. -
X的闭包应用二:判断属性集Xk是否为R的候选键
对于关系R,它的属性集合A,函数依赖集F,对于属性集合 Xk, Xk 属于 A:
如果 Xk+ = A;然后计算Xk的所有真子集的闭包,如果它们都 不等于A;那么Xk是R的候选键,否则不是;
候选键的定义:如果Xk → A 成立,但Xk的任一真子集Xk- → A 都 不成立,那么Xk才是关系R的候选键; -
三范式
-
1NF (First Normal Form)
每一行和每一列相交的位置有且仅有一个值。
-
2NF
在第一范式的基础上,每个非主关键字属性都完全依赖于主关键字。
-
3NF
在第二范式的基础上,所有非主关键字属性都不传递依赖于主关键字。
-
Chapter6.NoSQL
教学内容
- 教学重点:NOSQL, 分布式数据库,对象-关系型数据库。
考点
-
NoSQL的四大类型:键值数据库(redis)、列族数据库、文档数据库(mongoDB)、图形数据库
-
NoSQL的CAP
C(Consistency):一致性,是指任何一个读操作总是能够读到之前 完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的, 或者说,所有节点在同一时间具有相同的数据;
A:(Availability):可用性,是指快速获取数据,可以在确定的时间 内返回操作结果,保证每个请求不管成功或者失败都有响应;
P(Tolerance of Network Partition):分区容错性,是指当出现网络 分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分
离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不 会影响系统的继续运作。一个分布式系统不可能同时满足一致性、可用性 和分区容错性这三个需求,最多只能同时满足其中两个。
-
不同产品在CAP理论下的不同设计原则
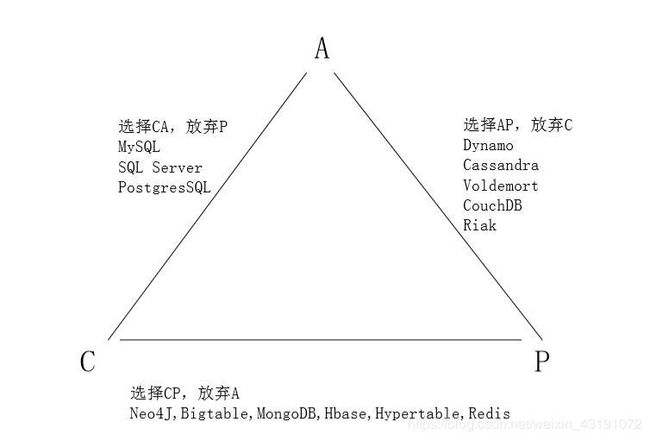
-
BASE(Basically Availble, Soft-state, Eventual consistency)
基本可用
基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其 他部分仍然可以正常使用,也就是允许分区失败的情形出现
软状态
“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一 种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,
即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同 步,具有一定的滞后性最终一致性
① 一致性的类型包括强一致性和弱一致性,二者的主要区别在于高并发的数据访 问操作下,后续操作是否能够获取最新的数据;
② 对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证
读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最
新数据,那么就是弱一致性。而最终一致性只不过是弱一致性的一种特例,允
许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必 须最终读到更新后的数据;③ 最常见的实现最终一致性的系统是DNS(域名系统)。一个域名更新操作根据 配置的形式被分发出去,并结合有过期机制的缓存;最终所有的客户端可以看 到最新的值。
本篇完。