【赫夫曼编码】实现文件中数据的加解密与压缩
目录
(一)第一步就是思路整理
(二)函数模块
(三)主要数据类型与变量
1、定义哈夫曼树的结构
2、动态分配数组存储赫夫曼编码表
3、存储数据扫描统计结果
4、主要变量
(四)代码测试
1、方案
建三个文件
2、运行结果
压缩文件
解压文件
输出文件
比较文件
(五)源码部分

背景知识:二叉树的应用、赫夫曼树。
目的要求:掌握赫夫曼树和赫夫曼编码的基本思想和算法的程序实现。
实验内容:实现文件中数据的加解密与压缩:将硬盘上的一个文本文件进行加密,比较加密文件和原始文件的大小差别;对加密文件进行解密,比较原始文件和解码文件的内容是否一致。
实验说明:
1.输入和输出:
(1)输入:硬盘上给定的原始文件及文件路径。
(2)输出:
- 硬盘上的加密文件及文件路径;
- 硬盘上的解码文件及文件路径;
- 原始文件和解码文件的比对结果。
2.实验要求:
- 提取原始文件中的数据(包括中文、英文或其他字符),根据数据出现的频率为权重,构建Huffman编码表;
- 根据Huffman编码表对原始文件进行加密,得到加密文件并保存到硬盘上;
- 将加密文件进行解密,得到解码文件并保存点硬盘上;
- 比对原始文件和解码文件的一致性,得出是否一致的结论。
3.参考类型定义 //双亲孩子表示法
typedef struct {
unsigned int weight;
unsigned int parent, lchild, rchild;
} HTNode, *HuffmanTree; //动态分配数组存储赫夫曼树
- typedef char * * HuffmanCode; //动态分配数组存储赫夫曼编码表
(*≧︶≦))( ̄▽ ̄* )ゞ小唠叨

这是我们的数据结构实验二,作为拖延症患者的我ddl从来都是第一生产力,于是,熬了两个晚上终于把思路给理出来了。8过代码还是借鉴啦大佬的博客
https://blog.csdn.net/qq_43492703/article/details/99769317?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-4&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-4
(一)第一步就是思路整理

这个实验难在它对我来说有一些抽象,一开始对文件的压缩和解压的概念很模糊,后来找到了B站上的一个视频(https://www.bilibili.com/video/BV1Yt411Y76w?from=search&seid=11711631498115172127),把这个本来对我来说比较抽象的概念具体化了:假设文件中的内容是“abcdabccccca”12个字符,一个ascii码对应一个字节,那么就是12个字节。但是如果用少于1个字节的几个位来表示各个字符,列如a:10,c:11,b:01,c:00,那么算下来只需要不到12个字节(5-6个字节)就可以搞定。而每个字符的编码可以由哈夫曼编码得到,每个字符的权值就是它出现的频率。

实验中比较重要的两个步骤就是压缩和解压缩:
①压缩:先打开要压缩的文件,分析每个字符的总次数,然后将次数传给哈夫曼树,构建一颗哈夫曼树,然后获取到每个字符的哈夫曼编码,将编码写入文件
②解压缩:打开要解压缩的文件,读出储存的哈夫曼字典(结构体),然后根据字典逐个的翻译编码得到字符,写入文件。
| 哈夫曼编码的思路(来自上述链接中大佬的博客): |
||||
|
(二)函数模块
void table();/*欢迎界面*/
void ReadFile(vector& f);/*读取文件到vector容器中*/
void InitList(TNode& N);/*初始化TNode结构*/
int Find(TNode N, char ch);/*查看TNode中是否有ch;有:返回true;无:返回false*/
void WriteTNode(vector v, TNode& N);/*核心:将vector中的数据存入TNode结构体中*/
void Select(HuffmanTree& HT, int n, int& min1, int& min2);/*查找HT中未被使用的权值最小的两个点的下标*/
void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC, TNode N);/*建树函数,附带完成每一个字符对应的编码*/
void ZipFile(HuffmanCode HC, vector v, TNode N);/*压缩文件*/
void RZipFile(HuffmanCode HC, TNode N);/*解压文件*/
void OutPutFile(vector& f);/*输出文件到屏幕*/
void CompareFile(vector& f, vector& v);/*对比两个文件*/ (三)主要数据类型与变量
1、定义哈夫曼树的结构
typedef struct
{
unsigned int weight;/*权值*/
unsigned int parent, lchild, rchild;/*父节点 左节点 右节点*/
}HTNode, * HuffmanTree;/*动态分配数组存储赫夫曼树*/2、动态分配数组存储赫夫曼编码表
typedef char** HuffmanCode;3、存储数据扫描统计结果
typedef struct {
char* data;/*表示文件中的字符(相当于哈夫曼树的结点)*/
int* cou;/*同一个字符在文件中出现的次数*/
int length;/*文件的字符总长度*/
}TNode;4、主要变量
//HT:哈夫曼树;
//HC:哈夫曼编码
vector V;/*vector声明*/ (四)代码测试
1、方案
-
建三个文件
路径分别是:
- E:\\Amusement\\Test.txt 原始文件 填写好内容
- E:\\Amusement\\ZipFile.txt 压缩后的文件 初始为空
- E:\\Amusement\\RZipFile.txt 解压后的文件 初始为空
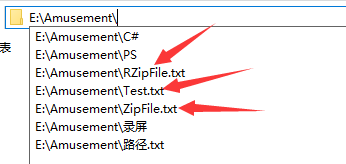
- 测试文件Test 包含文字和字母以及符号

2、运行结果
-
压缩文件
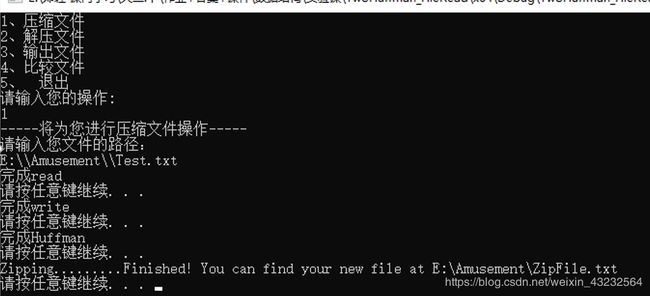
- ZipFile中储存压缩后的内容
-
解压文件
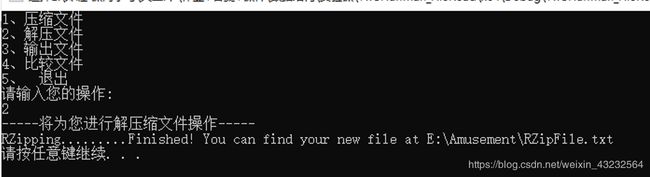

-
输出文件

-
比较文件
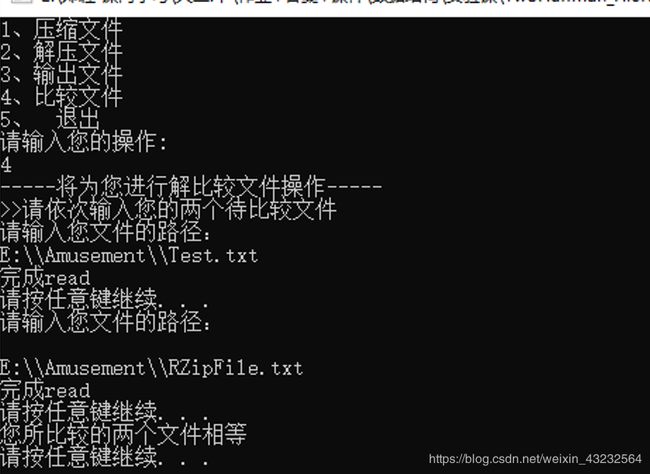
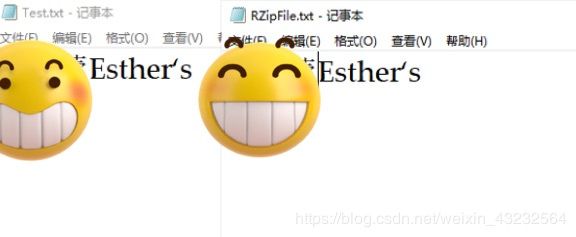
(五)源码部分
好啦废话不多说啦直接上源码

#include
#include
#include
#include
#include
#include
#include
using namespace std;
/*-----主要数据类型与变量------*/
typedef struct/*定义哈夫曼树的结构*/
{
unsigned int weight;/*权值*/
unsigned int parent, lchild, rchild;/*父节点 左节点 右节点*/
}HTNode, * HuffmanTree;/*动态分配数组存储赫夫曼树*/
typedef char** HuffmanCode;/*动态分配数组存储赫夫曼编码表*/
typedef struct {/*存储数据扫描统计结果*/
char* data;/*表示文件中的字符(相当于哈夫曼树的结点)*/
int* cou;/*同一个字符在文件中出现的次数*/
int length;/*文件的字符总长度*/
}TNode;
void table() {
cout << "1、压缩文件" << endl;
cout << "2、解压文件" << endl;
cout << "3、输出文件" << endl;
cout << "4、比较文件" << endl;
cout << "5、 退出 " << endl;
}
void ReadFile(vector& f) {/*读取文件*/
char path[500];/*文件路径*/
char ch;
cout << "请输入您文件的路径:" << endl;
cin >> path;/*从键盘输入路径*/
/*定义一个来自于文件path的输入copy流,
用ios::in方式 打开,in方式表示要读取文件,
文件不存在的话,不建立文件,而是得到一个空的ifstream对像*/
ifstream infile(path, ios::in);
if (!infile) {/*文件不存在*/
cout << "wrong open!!" << endl;
exit(1);/*退出当前运行的程序,并将参数1返回给主调进程*/
}
while (infile.peek() != EOF) {/*读操作,返回下一个字符但是不读取它*/
infile.get(ch);/*读取字符赋值给ch*/
f.push_back(ch);/*把字符ch推入vector*/
}
infile.close();/*关闭文件*/
cout << "完成read" << endl;
system("pause");
}
void InitList(TNode& N) {/*初始化TNode定义的结点*/
N.data = new char[256];
N.cou = new int[256];
if (!N.data || !N.cou) exit(1);
N.length = 0;
}
int Find(TNode N, char ch) {/*查看TNode中是否有ch;有:返回true;无:返回false*/
for (int i = 0; i < N.length; i++)
if (ch == N.data[i]) return true;/*ch在TNode存在*/
return false;/*ch在TNode中不存在*/
}
/*核心:将vector中的数据存入TNode结构体中*/
void WriteTNode(vector v, TNode& N) {
char ch;/*存储临时字符*/
int len = v.size(), j = 0;
for (int i = 0; i < len; i++) {/*遍历vector容器 寻找相同的字符*/
ch = v[i];/*相同的字符暂时存入v这个容器中*/
if (!Find(N, ch)) {
/*如果大vector中不再有没有读入v的相同的字符
那么就将v中当前字符ch的数据存入TNode N中*/
N.data[j] = ch;/*当前字符*/
N.cou[j] = count(v.begin(), v.end(), ch);/*此字符出现了多少次*/
j++;
N.length++;
}
}
cout << "完成write" << endl;
system("pause");
}
/*查找HT中未被使用的权值最小的两个点的下标*/
void Select(HuffmanTree& HT, int n, int& min1, int& min2) {
/*min1, min2最小值和次小值对应的下标*/
min1 = min2 = 0;/*初始化*/
for (int i = 1; i < n; i++) {
if (HT[i].parent != 0) continue;/*略过已经加入的结点*/
if (min1 == 0) min1 = min2 = i;/*赋初值*/
else if (HT[i].weight <= HT[min1].weight) {/*min1是最小值*/
min2 = min1; min1 = i;
}
else if (HT[i].weight < HT[min2].weight) {/*min2是次小值*/
min2 = i;
}
else if (HT[i].weight > HT[min2].weight) {/*防止两个值相等*/
if (min1 == min2) min2 = i;
}
}
}
/*建树函数,附带完成每一个字符对应的编码*/
void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC, TNode N) {
int m, start, n = N.length;
char* cd;
unsigned int c, f;
if (n <= 1) return;
m = 2 * n - 1;/*实际需要的存储空间为m*/
HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode));/*0号单元未用 从1开始*/
for (int i = 1; i <= n; i++) {/*利用TNode将叶节点初始化*/
HT[i].parent = 0;
HT[i].lchild = HT[i].rchild = 0;
HT[i].weight = N.cou[i - 1];/*TNode从0开始存储 HT从1开始存储*/
}
for (int i = n + 1; i <= m; i++) {/*初始化非叶节点*/
HT[i].parent = HT[i].weight = 0;
HT[i].lchild = HT[i].rchild = 0;
}
for (int i = n + 1; i <= m; i++) {/*构建赫夫曼树*/
int min1, min2;/*选出最小的两个结点合并*/
Select(HT, i, min1, min2);
HT[i].weight = HT[min1].weight + HT[min2].weight;
HT[i].lchild = min1;
HT[i].rchild = min2;
HT[min1].parent = HT[min2].parent = i;
}
/*从叶子到根逆向求每个字符的赫夫曼编码*/
HC = (HuffmanCode)malloc((n + 1) * sizeof(char*));/*分配n个字符编码的头指针向量*/
cd = (char*)malloc(n * sizeof(char));/*分配求编码的工作空间*/
cd[n - 1] = '\0';/*编码结束符*/
for (int i = 1; i <= n; i++) {/*逐个字符求赫夫曼编码*/
start = n - 1;/*编码结束符位置*/
for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) {/*从叶子到根逆向求编码*/
if (HT[f].lchild == c)
cd[--start] = '0';
else
cd[--start] = '1';
}
HC[i] = (char*)malloc((n - start) * sizeof(char));/*为第i个字符编码分配空间*/
strcpy(HC[i], &cd[start]);/*从cd复制编码(串)到HC*/
}
free(cd);/*释放工作空间*/
cout << "完成Huffman" << endl;
system("pause");
}
void ZipFile(HuffmanCode HC, vector v, TNode N) {/*压缩文件*/
int i = 0, j = 0, k = 0;
ofstream outfile("E:\\Amusement\\ZipFile.txt", ios::out);/*文件以输出方百式打开*/
if (!outfile) {/*文件为空*/
cerr << "wrong open!!" << endl;
exit(1);/*出现错误,返回值1*/
}
for (i = 0; i < v.size(); i++) {/*遍历vector容器*/
for (j = 0; j < N.length; j++)
if (N.data[j] == v[i]) break;
for (k = 0; HC[j + 1][k] != '\0'; k++)/*借助哈夫曼编码将数据压缩*/
outfile << HC[j + 1][k];
}
outfile.close();/*关闭文件*/
cout << "Zipping..."; Sleep(200); cout << "..."; Sleep(200); cout << "...";/*让用户等得一些时间*/
cout << "Finished! You can find your new file at E:\\Amusement\\ZipFile.txt" << endl;/*提示完成压缩*/
system("pause");
}
void RZipFile(HuffmanCode HC, TNode N) {/*解压文件*/
int flag, flag2 = 0, m = 0, i, j;
char ch;
char ch2[55];
ofstream outfile("E:\\Amusement\\RZipFile.txt", ios::out);/*文件以输百出方式打开;如果没有文件,那么生成空文件*/
ifstream infile("E:\\Amusement\\ZipFile.txt", ios::in);/*如果没有文件,打开失败;不能写文件*/
if (!outfile) {/*文件打开失败*/
cerr << "wrong open!!" << endl;
exit(1);/*运行错误,返回值1*/
}
if (!infile) {
cerr << "wrong open!!" << endl;
exit(1);/*运行错误,返回值1*/
}
while (infile.peek() != EOF) {
flag = 0;
char* cd = new char[N.length];
for (i = 0;; i++) {
infile >> ch;
cd[i] = ch;
cd[i + 1] = '\0';
for (int j = 1; j <= N.length; j++) {
if (strcmp(HC[j], cd) == 0) {
if (flag2 == 1) {
ch2[m] = N.data[j - 1];
flag = 1;
m++;
delete cd;
break;
}
if (flag2 == 0) {
outfile << N.data[j - 1];
flag = 1;
delete cd;
break;
}
}
}
if (flag == 1)
break;
}
}
cout << "RZipping..."; Sleep(200); cout << "..."; Sleep(200); cout << "...";/*让用户等得一些时间*/
cout << "Finished! You can find your new file at E:\\Amusement\\RZipFile.txt" << endl;/*提示完成解压缩*/
}
void OutPutFile(vector& f) {
char path[200];/*文件路径*/
char ch;
cout << "请输入您所要查询的文件路径" << endl;
cin >> path;/*从键盘输入路径*/
ifstream infile(path, ios::in);
if (!infile) {/*文件不存在*/
cout << "wrong open!!" << endl;
exit(1);/*退出当前运行的程序,并将参数1返回给主调进程*/
}
while (infile.peek() != EOF) {/*读操作,返回下一个字符但是不读取它*/
infile.get(ch);/*读取字符赋值给ch*/
f.push_back(ch);/*把字符ch推入vector*/
}
infile.close();/*关闭文件*/
cout << "路径:" << path << "的文件如下" << endl;
for (int i = 0; i < f.size(); i++)
cout << f.at(i);
cout << endl;
f.clear();
system("pause");
}
void CompareFile(vector& f, vector& v) {
cout << ">>请依次输入您的两个待比较文件" << endl;
ReadFile(f);
ReadFile(v);
//if (f.size() != v.size()) {
// cout << "您所比较的两个文件不相同" << endl;
// return;
//}
/*一直在想如何逐一比较vector里面的数据,后来查了博客才知道可以直接比较*/
if (f == v)
cout << "您所比较的两个文件相等" << endl;
else
cout << "您所比较的两个文件不相等" << endl;
return;
}
int main() {
int choose;
vector V, Vf, Vs, Vr;
HuffmanTree HT;
HuffmanCode HC;
TNode N;
InitList(N);
while (1) {
system("cls");
table();
cout << "请输入您的操作:" << endl;
cin >> choose;
switch (choose) {
case 1:
cout << "-----将为您进行压缩文件操作-----" << endl;
ReadFile(V);/*打开指定文件 读取数据 存入vector容器*/
WriteTNode(V, N);/*将vector中的数据存储到NTode结构中*/
HuffmanCoding(HT, HC, N);/*将TNode中的数据存到哈夫曼树中并生成哈夫曼编码*/
ZipFile(HC, V, N);/*压缩文件*/
break;
case 2:
cout << "-----将为您进行解压缩文件操作-----" << endl;
RZipFile(HC, N);/*对文件内容进行解码*/
system("pause");
break;
case 3:
cout << "-----将为您进行输出文件操作-----" << endl;
OutPutFile(Vr);/*将文件内容借助vector输出到终端*/
break;
case 4:
cout << "-----将为您进行解比较文件操作-----" << endl;
CompareFile(Vf, Vs);
system("pause");
//cout << ">>请依次输入您的两个待比较文件" << endl;
//OutPutFile(Vf);
//OutPutFile(Vs);
/*直接将两个待比较的文件输出 肉眼进行比较*/
break;
case 5:
return 0;
default:
cout << "请输入规范的序号";
system("pause");
break;
}
}
return 0;
}
