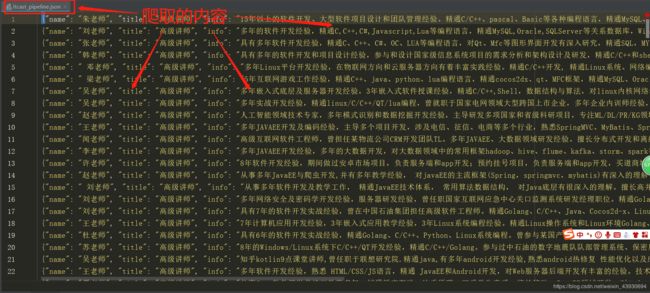
python3 pycharm+scrapy框架 爬虫项目实例(一)
博客链接!
requests 讲解
BeatifulSoup 讲解
python3 基于requests+beatifulsoup爬虫实战
python3 pycharm+scrapy框架 爬虫项目实例(一)
历经挫折,在度娘以及csdn大佬帮助下成功安装scrapy框架
一、项目简介
1.内容:爬取传智播客C/C++讲师的姓名、职称以及个人简介
2.目标网址:http://www.itcast.cn/channel/teacher.shtml
3.软件: 已经成功 安装好scrapy框架 的pycharm软件 (专业版、社区版都可以)
4.python3.7
5.使用scrapy框架实现爬虫 运用xpath解析方式
二、步骤
1. 新建scrapy项目工程:
在pycharm界面中打开 View --> Tool Windows --> Terminal
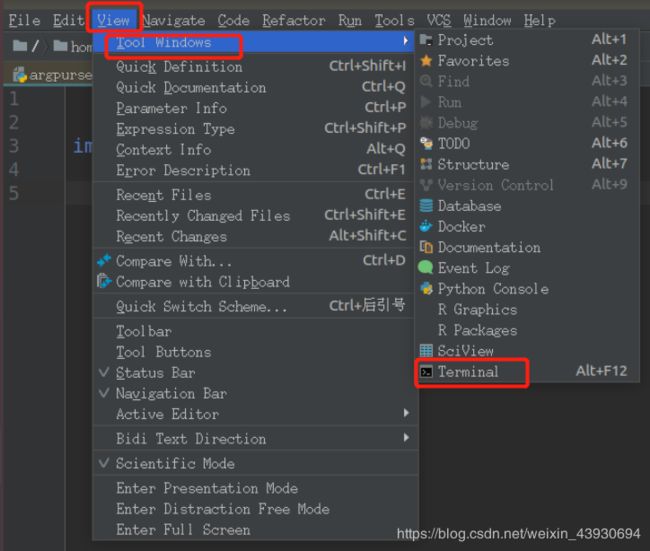
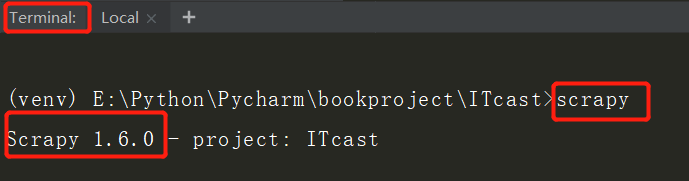
(1)验证scrapy是否成功安装:在Terminal中输入 scrapy 看看是否显示scrapy信息
(2)创建scrapy项目工程
在Terminal中输入:
# scrapy startproject + 自定义的项目名称
scrapy startproject ITcast成功创建项目的目录为:
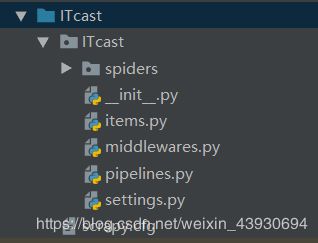
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines.py 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
(3)创建写爬虫的文件
# scrapy genspider +名称 + '网站'
#建立爬虫文件
scrapy genspider itcast "itcast.cn"结果为:
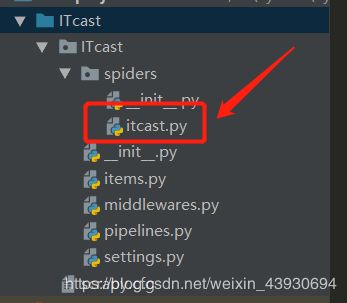
打开文件,初始代码为:
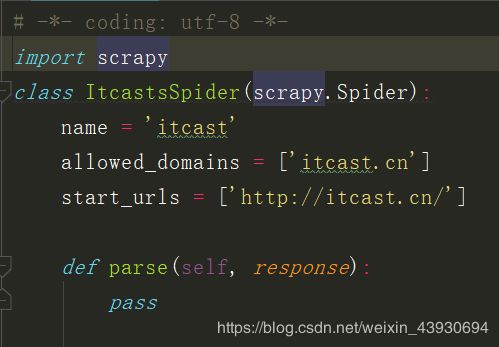
到此新建项目完成!!!
2. 分析、解析网页
观察网页,通过浏览器得出他们是这样子的结构,并且我们运用强大的xpath解析方式解析:

3.编写代码
需要编写四个相关联的文件: itcast.py items.py settings.py pipelines.py (管道文件)
(1) itcast.py
# -*- coding: utf-8 -*-
import scrapy
#导入容器
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
# 爬虫名 启动爬虫时需要的参数*必需
name = 'itcast'
# 爬取域范围 允许爬虫在这个域名下进行爬取(可选) 可以不写
allowed_domains = ['itcast.cn']
#起始url列表 爬虫的第一批请求,将求这个列表里获取
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
# .extract() 将xpath对象转换围殴Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#返回提取到的每一个item数据 给管道文件处理,同时还会回来继续执行后面的代码
yield item
(2)items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ItcastItem(scrapy.Item):
# define the fields for your item here like:
# 与itcast.py 定义的一一对应
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
#pass(3)settings.py
'''
找到这个字段,将字段不要注释!!!
'''
ITEM_PIPELINES = {
'ITcast.pipelines.ItcastPipeline': 100, #值越小优先级越高
}(4) pipelines.py (管道文件)
import json
class ItcastPipeline(object):
def __init__(self):
#python3保存文件 必须需要'wb' 保存为json格式
self.f = open("itcast_pipeline.json",'wb')
def process_item(self, item, spider):
#读取item中的数据 并换行处理
content = json.dumps(dict(item),ensure_ascii=False) + ',\n'
self.f.write(content.encode('utf=8'))
return item
def close_spider(self,spider):
#关闭文件
self.f.close()
4.结果展示
执行文命令行: scrapy crawl + 爬虫文件的名称
在Terminal中输入 scrapy crawl itcast 执行scrapy项目,生成json文件:
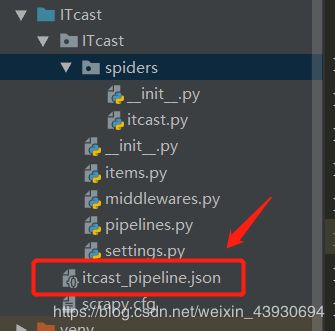
打开json文件为: