Marco's Java【Redis进阶(一) 之 Redis缓存击穿及布隆过滤器实现原理】
前言
本章的内容主要围绕面试中经常碰到的Redis的问题,即什么是缓存击穿,以及缓存击穿的解决方案来展开的,希望对大家能有所帮助啦!
文章目录
- 前言
- 什么是缓存的击穿
- Bloom过滤器实现原理
- Bloom过滤器具体实现
- 分析布隆过滤器的实现
- 使用BitSet实现数据存储
- 使用Redis的BitMap实现数据存储
什么是缓存的击穿
相信大家都很清楚,Redis缓存技术大大的提高我们查询数据的效率,当我们从数据库中查询数据的时候,同时会缓存到内存当中,当下次我们再次查询相同数据的时候,则直接可以在缓存中查询,而不需要再次从数据库中提取数据。这种方式呢,当然也是存在一定 “漏洞” 的,当我们一直查询一些缓存或者说数据库中根本不存在的数据的时候,其实跟直接查询数据库的效果是一样的,根本用不上缓存。
因此一些黑客会利用这些 “漏洞” 故意查询一些在缓存内必然不存在的数据,最终导致每次数据请求都经过Redis缓存,而直接去查询数据库(比方说我们默认不会缓存null 值,导致用户访问 id = -1 这样的数据时,会一直都无法命中),当请求的流量比较大时,缓存每次都无法命中,可能会导致数据库过载而挂掉。这就是所谓的缓存击穿。
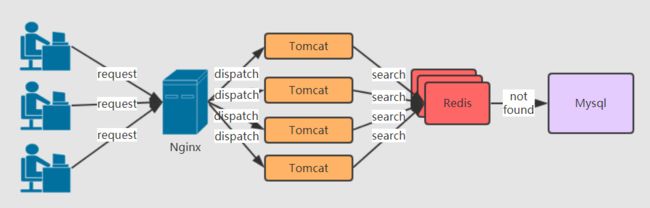
那么怎么解决缓存击穿呢?相信大家最容易想到的方案就是将null值也缓存到Redis中,比方说用户访问 id = -1 这样的数据时,数据库查出来的结果一定是null,那么我就将这个数据缓存起来,同理,其它值为null的结果也给缓存起来。那么下次我再查询的时候,就不会再从数据库提取数据了。

但是这种方案有一个巨大的缺陷,相信各位也看出来了,就是在Redis中缓存大量无用的值,从而浪费过多的内存空间。当然网上还有其它更好的解决方案,比如说使用互斥锁(即在根据key获得的value值为空时,先锁上,再从数据库加载,加载完毕,释放锁。若其他线程发现获取锁失败,则睡眠50ms后重试。至于锁的类型,单机环境用并发包的Lock类型就行,集群环境则使用分布式锁( redis的setnx))。
或者说对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
但是今天呢,着重讲解其一种最有效的方案 — Bloom过滤器
Bloom过滤器实现原理
啥是布隆过滤器呢?我们先来看看百科上怎么解释的吧。
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
说白了,布隆过滤器就基本思想和大数据中的 “去重” 差不多,因为在处理大数据时,重复的数据一般是不被允许的,也就是说布隆过滤器需要保证数据的唯一性,当我们查询一个数据的时候,他需要很快的反应并作出决断,这个数据究竟存不存在?
因为布隆过滤器中的数据通常拥有数据库中所有需要查询的数据,只不过存储的方式不一样,而且功能很简单,一般只用到添加(addElement)和判断数据是否存在(hasElement)。工作原理图如下。

当布隆过滤器中没有我们查询的数据时,会直接返回空值给客户端。
当布隆过滤器发现我们查询的数据存在时,则会交给Redis去查询,当然了,数据库中有的数据,缓存不一定会有,因此,当Redis查到数据的话,会返回给客户端,如果没有查到,依然会去数据库去查询,只不过此时数据经手了布隆过滤器,因此可以保证数据库中一定有该数据,不会产生无用请求。
Bloom过滤器具体实现
知道了Bloom过滤器过滤数据的原理,那么接下来就要考虑怎么去实现了?刚才我们也提到了Bloom过滤器实质上就是对数据的去重和储存,说到去重,大家是不是首当其冲的会想到HashSet?
没错,不得不承认HashSet天然去重的优势很吸引人,但是当数据量很大时,它的内存占用会非常非常大,查询速度也会很慢。当然还有一个候选者TreeSet,但是TreeSet的查询速度是(logN),因此当数据量越来越大时,它的查询速度也会相对变慢。
说了这么半天,都是废话… 那么到底该使用什么来作为Bloom过滤器的存储数据的容器呢?答案就是BitSet。
分析布隆过滤器的实现
可能有很多朋友都没有听说过BitSet,也就是专门存储bit比特的集合… (还有这种骚操作是吧…)
大多数的集合都是用来存储基本数据类型或者对象的,一般来说存储的一个数据最少得4个字节吧?比方说int的长度就是4个字节,一个字节有8位,也就是说,我光存储一个int就要花32位来存储。
而BitSet就可以做到位存储,也就是说我们可以将数据经过特定计算之后,转化为比特进行存储,而这种计算的方式就是我们熟知的Hash算法。
那么结合Hash算法,如何使用BitSet来存储数据呢?我们假设现在BitSet有无限长,现在需要查询一个key=marco,那么通过hash算法可以获取marco的hash值,然后将得到的hash值和BitSet的长度进行按位与计算,假设得到的值为56589,那么我就将BitSet的索引为56589的值涂黑(设为true),不同数据的则使用相同的hash算法进行计算,并存储。当判断是否有这个数据时,按照相同的算法计算,然后判断BitSet上这个位置的值是否被 “涂黑” ,进而判断数据是否存在。

但是,通过这中方式进行存储,难免会遇到hash碰撞的问题,特别是当容量很小,存储数据很多时,hash最容易碰撞,因此我们可以通过增加hash函数的个数来减少碰撞(每次hash函数计算后的结果要保证不一样,后面具体实现BloomFilter的时候会讲到),比如说将数据marco通过计算获得5个不一样的数值56589、85698、12368、87854、12569。
使用这种方式,虽然无法百分之百避免hash碰撞,但可以保证碰撞的几率基本为0。

使用BitSet实现数据存储
好啦,终于到了模拟实现BloomFilter的阶段。首先咱们自定义个哈希函数,用于计算我们查询或者存放的key,存放在比特集合BitSet上的位置。
package com.marco;
/**
* 自定义哈希函数
* @author Marco
*
*/
public class HashFun {
private int prime;
public HashFun(int prime) {
this.prime = prime;
}
public int hash(String key) {
int h = 0;
char[] value = key.toCharArray();
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = this.prime * h + val[i];
}
}
return h;
}
}
接下来就是BloomFilter的实现代码,本质上就是使用上面的算法,传入不同的质数,对被传入的key值进行处理,并得到该数据映射在位集合上的位置bitIndex,我这里分别传入5个不同的质数,也就是说同一个key经过5次计算之后获得5个不同的bitIndex,并记录到同一个bitSet上,并将bitIndex位置 “涂黑” (此处的值设置为true)。

package com.marco;
import java.util.BitSet;
public class BloomFilter {
// 初始化集合长度
public static int length = Integer.MAX_VALUE;
// 声明比特集合
public static BitSet bitSet = new BitSet(length);
// 准备hash计算次数
public static int hash_length = 5;
/**
* 准备自定义哈希算法需要用到的质数,因为一条数据需要hash计算5次 且5次的结果要不一样
*/
public static int[] primeNums = new int[] { 17, 19, 29, 31, 37 };
// 自定hash函数(算法)
public static HashFun[] funs = new HashFun[hash_length];
/**
* 初始化funs
*/
static {
for (int i = 0; i < hash_length; i++) {
funs[i] = new HashFun(primeNums[i]);
}
}
/**
* 添加元素到bitSet中
* @param key
*/
public static void addElement(String key) {
for (HashFun fun : funs) {
int hashcode = fun.hash(key);
int bitIndex = hashcode & (length - 1);
System.out.println("映射位置有:"+ bitIndex);
bitSet.set(bitIndex, true);
}
}
/**
* 判断bitSet中是否有被查询的的key(经过hash处理之后的)
* @param key
* @return
*/
public static boolean hasElement(String key) {
for (HashFun fun : funs) {
// 计算hashcode
int hashcode = fun.hash(key);
// 计算映射在位集合上的位置
int bitIndex = hashcode & (length - 1);
// 只要有一个位置对应不上,则返回false
if(!bitSet.get(bitIndex)) {
return false;
}
}
return true;
}
}
其实实现起来真的非常简单啦,接下来咱们测试下吧!
public static void main(String[] args) {
addElement("xidada");
System.out.println("----------------");
addElement("chuanpu");
if(hasElement("xidada")) {
System.out.println("ok");
}else {
System.out.println("error");
}
if(hasElement("chuanpu")) {
System.out.println("ok");
}
}
测试之后的结果如下

使用Redis的BitMap实现数据存储
接下来我们稍微改造下以上的代码,因为以上数据存储仅仅只适用于单机版玩玩而已,而在分布式项目中,使用BitSet存储数据并不能保证数据的共享,那么如何解决数据共享的问题呢?
答案就是Redis的BitMap!BitMap其实就是一个Map集合,key为String,value为BitSet,因此仅需要略作改造就可以实现分布式架构下的布隆过滤器的数据存储。
首先导入jedis的jar包
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.marcogroupId>
<artifactId>bloomfilterartifactId>
<version>0.0.1-SNAPSHOTversion>
<properties>
<jedis.version>3.1.0jedis.version>
properties>
<dependencies>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>${jedis.version}version>
dependency>
dependencies>
project>
接着创建一个RedisUtil类,其效果和上面的BitSet是一样的,主要是要是用作位集合,存储数据
package com.marco.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtil {
private static final JedisPool jedisPool;
/**
* BIT_SET的名称
*/
private static String MQ_MESSAGE_BIT_SET = "mq:message:bit:1";
static {
JedisPoolConfig poolConfig = new JedisPoolConfig();
//设置最大空闲数量
poolConfig.setMaxIdle(15);
//设置最小空闲数量
poolConfig.setMinIdle(10);
//设置最大资源数量
poolConfig.setMaxTotal(20);
//设置最长等待时长
poolConfig.setMaxWaitMillis(5000);
//默认的端口号为6379
jedisPool = new JedisPool(poolConfig, "127.0.0.1");
}
/**
* 根据索引从bitmap中获取值
* @param bitIndex bitset的索引值
* @return
*/
public static boolean get(int bitIndex) {
Jedis jedis = null;
boolean flag = false;
try {
jedis = jedisPool.getResource();
flag = jedis.getbit(MQ_MESSAGE_BIT_SET, bitIndex);
} catch (Exception e) {
e.printStackTrace();
} finally {
if(null != jedis) {
jedis.close();
}
}
return flag;
}
/**
* 在bitset中设置key和value
* @param bitIndex
* @param b
*/
public static void set(int bitIndex, boolean b) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.setbit(MQ_MESSAGE_BIT_SET, bitIndex, b);
} catch (Exception e) {
e.printStackTrace();
} finally {
if(null != jedis) {
jedis.close();
}
}
}
}
接下来修改BloomFilter中以下部分的代码,将bitSet.set(bitIndex, true)替换为RedisUtil.set(bitIndex, true),将bitSet.get(bitIndex)替换成!RedisUtil.get(bitIndex)
/**
* 添加元素到bitSet中
* @param key
*/
public static void addElement(String key) {
for (HashFun fun : funs) {
int hashcode = fun.hash(key);
int bitIndex = hashcode & (length - 1);
System.out.println("映射位置有:"+ bitIndex);
RedisUtil.set(bitIndex, true);
// bitSet.set(bitIndex, true);
}
}
/**
* 判断bitSet中是否有被查询的的key(经过hash处理之后的)
* @param key
* @return
*/
public static boolean hasElement(String key) {
for (HashFun fun : funs) {
// 计算hashcode
int hashcode = fun.hash(key);
// 计算映射在位集合上的位置
int bitIndex = hashcode & (length - 1);
// 只要有一个位置对应不上,则返回false
if(!RedisUtil.get(bitIndex)) {
return false;
}
}
return true;
}
测试结果也没有问题!
检查Reids之后,发现数据也成功的存储进去了。
