Python并发编程理论篇
Python并发编程理论篇
前言
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
其实关于Python的并发编程是比较难写的一章,因为涉及到的知识很复杂并且理论偏多,所以在这里我尽量的用一些非常简明的语言来尽可能的将它描述清楚,在学习之前首先要记住一个点: 并发编程永远的宗旨就是提高程序的运行效率,也是围绕CPU来进行优化的一种技术手段。
像我们之前学习过的网络编程中,我们只是基于 socketserver 模块让我们的Server端有了处理多任务的能力,但是我们并不了解它的底层是怎么做到的,在学习完并发编程后,尝试自己阅读一下 socketserver 源码,你将会大有收获。
并发编程很重要吗?是的,非常重要,如果你想进入 PythonWeb 领域那么著名的框架如 Django , Tornado , Flask 等等底层都是有基于本章节的知识点,如果你想进入爬虫领域那就更不用说了,非常强大的 scrapy 框架也是基于我们所学的这些东西累积起来的。
好了废话不多说,让我们开始进入并发编程的学习吧。
从任务处理角度看待操作系统发展史
这一节主要是理论知识,了解计算机任务处理方式的演变过程,能够让我们更快的理解和学习并发编程。
首先,我们先来回顾一下操作系统方面的一些知识。
操作系统的作用:管理硬件,目的就是让用户更加方便的来操控计算机底层的硬件。
可以看到操作系统对于人们操控计算机进行作业有着不可小觑的功劳,那么在早期没有操作系统的时候你能想象是什么样子吗?现在我们来看一看。
无操作系统时任务的处理方式
早期的计算机并没有操作系统 ,而是通过纸带来进行程序的编辑,它有三台设备分别是:输入机,计算机,输出机。

那个时候的程序员需要一起约定好时间,来轮流的对自己的程序进行优化,因为那个时候的计算机在同一时刻下只能由一个人去运行和掌控,我们来看一下它的计算流程:


这个时代的计算机 一次只能跑一个人的程序 ,没有其他干扰,那么它的缺点也很明显,一次只能一个人使用而后面想要使用的人必须得等待前一个人用完之后才行。其执行效率非常低下,最关键的就是 人在进行与计算机交互的时候计算机的运算器是没有任何工作的,这就造成了资源上极大的浪费 ,那么这种浪费可以理解为 I/O阻塞 。
为了解决这个问题,批处理系统横空出世了。
批处理系统的诞生
相比于前一代计算机处理任务的方式,批处系统的诞生让这一代计算机有了极大的进步,并且输入也不再使用纸带,而是采用磁带,批处理操作系统 可以将多个用户的任务同时提交(但是不能同时运行)。
假设有三个程序员需要使用这台计算机,他们将自己的程序全部交由一个程序员让其进行人机之间的交互,那么这样就 节省了三倍的时间 。但是这样的缺点也很明显, 只能等待三个人的程序全部处理完后大家才能拿到各自的结果 ,这个等待过程是十分漫长的。
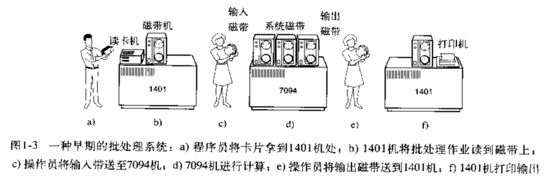
在这里,出现了一种自动化的工作方式, 计算机也就是中间的7094机器能够去区分出每个程序员自己的程序 ,那么其内部肯定是由一种代码支持它有了这种功能,那个这个就是批处理系统。
单处理的批处理系统最大的缺点依然还是拥有 I/O阻塞 ,能不能把中间的两个小人全部干掉让计算机来做他们做的事儿呢?当然可以,但是....当时的人还没那么聪明。

我们再来想一个问题,如果程序员A的程序出错了,它第一时间拿不到,返回会一直卡在那,程序员B和程序员C也不用拿了,反正都出不来。是不是很蛋疼?
后来慢慢的经过时间的积累与技术的成熟,针对这一代的批处理系统的缺点,又出现了新一代操作系统。
多道程序设计与分时操作系统的诞生
在这一代操作系统中最先出现了一种技术,名叫 SPOOLING 技术,这个技术的出现让上图的两个小人下岗了。 SPOOLING 技术的出现极大的减少了 I/O阻塞 的时间,除此之外,该代操作系统还提出了一个非常重要的思想,即 多道程序设计 的思想,这个技术思想目前在我们的进程中依然存在,它的主要功能就是解决了顺序执行(串行)的问题。
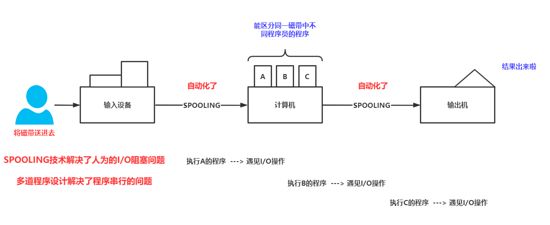
尽管这样做的确让程序效率提高了,但是我们还有一个问题。计算机中依然是批处理系统,还是要等A,B,C的叅櫊程序同时出结果才能拿到最终结果,这个时间太长了,就想上面说的如果程序员A的程序出错了卡住了程序员B和C的正常程序也取不出来。
有的人开始怀念最早的无操作系统时代的计算机了,太怀念了,我一个人的程序十分钟我就出来了,三个人的我要等三十分钟,如果有一个出错了我的等在久也出不来,我太难了...
为了解决这种问题,出现了极为牛逼的 分时操作系统 。
分时很形象的一个比喻就是一台电脑给A,B,C每个程序员一个键盘鼠标和显示器,大家共有一个主机各玩各的互不影响,都认为自己的程序是独享的并且马上就能看到自己程序的运行结果,你说牛不牛逼?大家都很开心,但是实际上大家还是共用的同一个CPU...( 多用户多任务 )。
分时操作系统到现在依然存在,并且还十分常见,比如许多人去操作同一台服务器。
这时候大家就在考虑,你丫键盘鼠标显示器啥都给我了,为啥不再给我一个主机呢?这其实还是受限于当时的成本条件,但是到了如今计算机的成本以及体积都下来后,这些都不是问题了。
个人操作系统的诞生
现在咱们大家都是用的个人操作系统,已经挺熟练了吧,这个玩意儿每个人都在玩,但是虽然大家不共有一个CPU了,其实在系统内部依然存在着切换,它就是进程或者线程之间的切换。
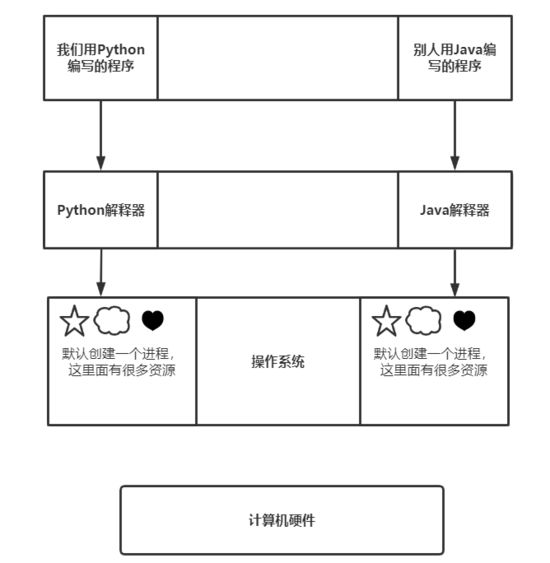
应用程序与系统之间的关系
现在咱们聊一聊应用程序与系统之间的关系,其实对于开发者而已,我们与操作系统之间是隔了很多层的。如图所示:
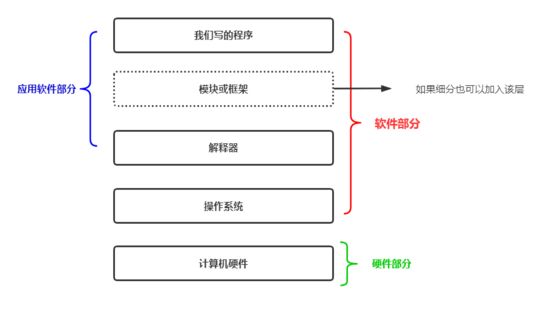
所以,我们自己写的程序要想运行,必须从上至下的依次经过这些关卡。
为什么要聊这个,因为聊完这个之后我们才能接着往下看。
并发并行阻塞非阻塞同步异步
这几个概念将贯穿接下来的所有学习。
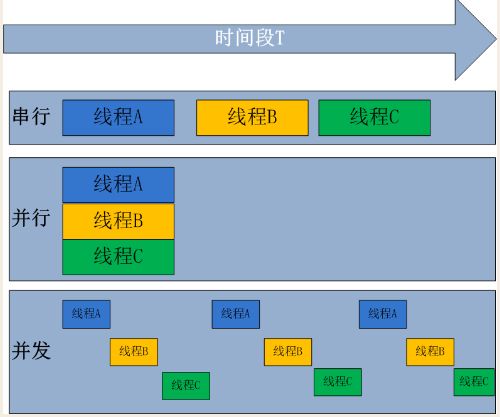
并发和并行是指操作系统处理任务的能力:( 一个一个处理?一次处理多个? )
并发:操作系统具有处理多个任务的能力。
并行:操作系统具有 同时 处理多个任务的能力。
PS:并发包含并行。这里再提一个伪并行,就是看起来像是同时处理,但是实际上并不是同时处理。
同步和异步是指任务的提交方式:( 任务提交完后等你结果我再进行下一步操作?或者不等你的结果我接着干我的其他事? )
同步:任务提交之后,原地等待任务的返回结果,等待的过程中不做任何事。(干等),程序上面表现出来的感觉就是卡住了。
异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情,等待任务的返回结果自动提交给调用者。
Ps: 对于异步来说,那么我们提交任务后的返回结果如何获取?
提交任务后的返回结果会有一个异步回调机制自动处理,可以理解为当该任务有结果就会自动返回回来。给你打电话告诉你一声我这边完成了,你别忙了,看我一眼。
阻塞和非阻塞是指程序的运行状态:( 程序现在卡住了吗?卡住了就是阻塞,没卡就是非阻塞 )
阻塞:是指调用某个函数的时候被卡住不动了,比如 input() 函数会导致阻塞
非阻塞:是指调用某个函数的时候不会卡住,而是立即返回的一种形式
进程理论
进程的定义
大白话版本:
进程你可以把它当做一件屋子,里面放了很多物件(资源), 所以进程就是最小的资源单位。 另外我们要注意一点,程序只有在运行状态时才会产生进程,而不运行的时候就是一堆死代码。
程序是一堆躺在硬盘上的代码,是"死"的
进程则是表示程序正在执行的过程,是"活的"
所以说,进程这玩意儿就是在程序执行过程中产生的,它会有一些资源状态放在这个屋子里。
并且一定要注意,进程这玩意儿是一个系统级别的概念,进程是由操作系统创建出来的。程序执行的时候我们就会有一个进程,当然一个程序运行中也可以产生多个进程。
专业版本
详细定义:
进程就是一个程序在一个数据集上的一次动态执行过程。
进程一般由程序、数据集、进程控制块三部分组成。
我们编写的程序用来描述进程要完成哪些功能以及如何完成;
数据集则是程序在执行过程中所需要使用的资源;
进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
数据集提供所有程序运行时需要的资源,进程控制块用来记录程序的状态,比如说挂起被切换状态还是运行状态等等...
进程间的数据交互
进程之间按理说是不应该允许彼此之间数据交互的, 因为每个进程都是一间独立的小房子,每个小房子的资源都是自己独享的。 但是我们之前学过 socket 模块,这玩意儿最早就是用来解决进程间数据交互(进程间通信)问题的。
所以,进程之间虽然默认不支持数据交互,但是我们可以使用某些特殊手段让两个进程之间支持数据交互,但是这不是很容易就能完成的,需要付出一些代价。
进程切换
一个CPU核心同一时刻最多只能运行一个进程,而多个CPU核心同一时刻可以运行多个进程,这个就是并发的体现。 我们说过,多道技术的产生解决了程序串行的问题,那么就必然涉及到进程切换。 进程切换实际上是由操作系统说了算,除了我们的I/O操作切换外,它还有以下控制进程切换的手段,PS:进程的切换代价也是比较巨大的,因为一旦切换就要保证当前进程中的资源数据,而切换回来时又要将进程的状态复原 :
1.先来先服务算法
谁先开辟了一个小屋子,那么就先运行你。这个说白了对一个存活时间很短的进程是相当不利的,如果一个存活时间很长的进程占用了一个CPU核心,那么恰巧这个CPU又是单核的,其他存活时间短的进程永远也得不到CPU的眷顾了。所以单一的这种策略不行。
2.短作业优先调度算法
谁的进程作业时间短(即存活时间短)就先运行谁,显然,单一的这种算法会让长作业进程得不到CPU眷顾,故也不能一直采取这种策略。
3.时间片轮转(时间轮询)
什么意思呢?就是说假如有多个进程,我每个进程让你运行个三五秒就切换到另一个进程运行,如此来回切换就是时间片轮转。即将时间切成一段。
4.多级反馈队列
这个其实是基于时间片轮转做的,它会将当前所有的活动进程送入一个队列中,根据存活时间来为其分配到不同的队列中,进程存活时间越久,其得到CPU眷顾的次数越低。如图:
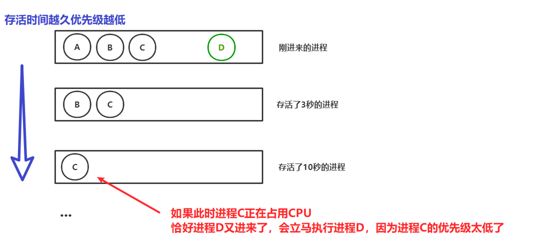
其实在Linux系统中,我们可以为一个进程分配更多的时间片与更高的优先级,这里暂且先不提。
线程理论
线程的定义
大白话版:
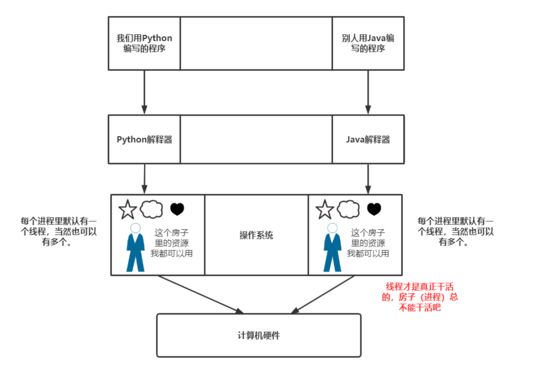
每个进程存在的时候都默认会有一个线程,如果把进程比喻做房子,那么线程就是房子里的人(可以有一个也可以有多个,默认一个)。线程才是真正干活的单位, 因此线程是最小的执行单位,线程共享进程中所有数据(进程资源集)。
进程和线程是一个包含关系:必须有进程才有线程,就像线程这个人必须住在进程的房子里。
专业版本:
线程详细定义:
1 一个程序至少有一个进程,一个进程至少有一个线程.(进程可以理解成线程的容器)
2 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
3 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
4 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位. 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈)但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源. 一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行。
线程间的数据交互
线程必须存在于进程中,我们上面说过一个进程可以有多个线程,那么想当然的该进程里的所有资源都可以被位于该进程中的线程所拿到。
而跨进程之间的线程就是属于进程间的数据交互了。
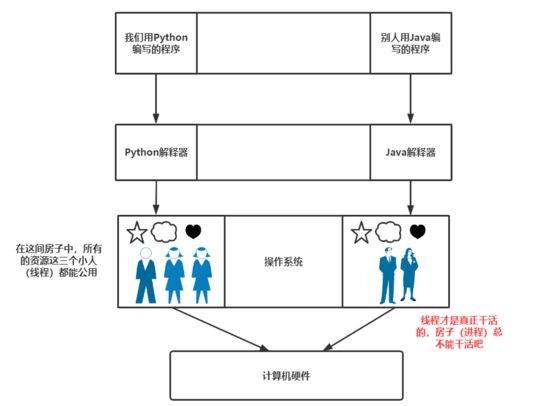
但是我们一定要注意一点,就是线程安全。这句话怎么说呢?就是这个房子里有一颗糖,被一个小人吃了,那么其他的小人也应该知道这颗糖没了才行。虽然听起来很符合逻辑,但是别忘了线程不是真正的人,它是傻的,所以当我们进行线程之间数据交互的时候一定要注意线程安全 。
线程安全的问题还是由于线程切换导致的,比如这个房间一共有10颗糖,一个小人吃了3颗糖被CPU通知歇息一会,那么他会认为还剩下7颗糖,另一个干活的小人又吃了3颗糖后去休息了,那么现在第一个休息的小人上线了,但是真正的糖果数量只剩下了4颗,他还傻乎乎的任务是7颗。
线程切换
线程切换与进程切换如出一辙,看上面的就行了。
Python中的GIL锁
终于聊到这个话题了,GIL锁被称为全局解释器锁。这玩意儿直接让Python的多线程残了,我们用图来解释这个锁是干嘛用的:
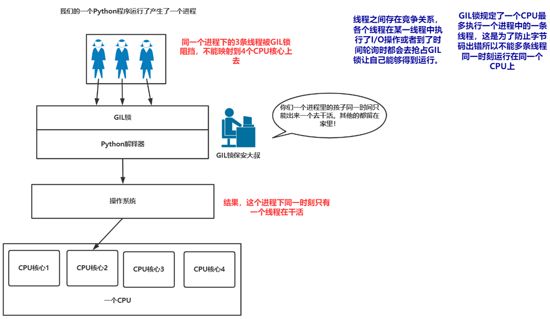
我们再来看一眼诸如C#或者Java中的多线程运行是怎么样的。

所以!Python中的多线程没有并行操作!同时处理多个事对于Python里的单进程下的多线程来说是做不到的,那么我们可以怎么办呢?
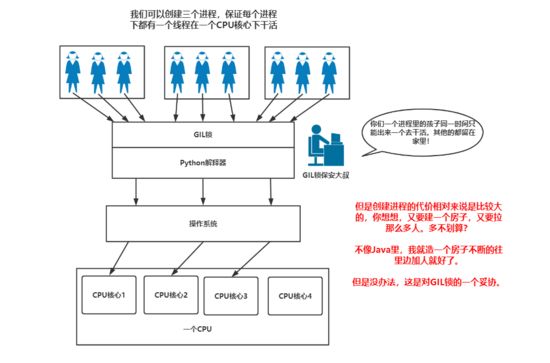
自己在学GIL锁时作的笔记:
Python中的一个线程对应于C语言中的一个线程( 基于CPython ),而 CPython前面也已经说过了。会将函数转变为可执行的字节码,而多个线程同时运行一段字节码是很有可能出错的,为了避免这个错误所以Python使用了GIL锁限制了多线程技术。 具体如下:
GIL 使得同一个时刻只能有一个线程在 CPU 上执行字节码( 一般情况下 ),无法将多个线程映射到多个CPU 上去执行。 因此 Python多线程的GIL锁 注定了其在多线程任务处理并没有太大优势
当GIL 锁死一个线程之后,并不是非要等这个线程运行完后才会释放。而是会在适当的时候就进行释放 :
1:时间轮询机制
2: I/O操作
所以Python中线程的并行操作是不被支持的(Cpython),Python并不适合做多线程的大量计算。这样的时间远不如串行来的简单,因为在线程切换之中会导致运行速度的减缓。
Python中的线程不能并行,但是进程是存在并行的。所以,Python的线程更加适用于密集型I/O操作比如网络爬虫方面,Python的GIL锁在某种程度上来说是保护了线程安全,但是更多的被人诟病。开发团队曾经尝试过去GIL锁但是发现去掉GIL锁之后实现线程并行的这种方式让运行速度更加慢了下来,具体原因是因为CPython中的大量模块第三方库在设计之初都是在有GIL锁的情况下设计的,所以一旦改版后果不能被人预料。
但是也不用悲观,Python的GIL锁只是解释器层面和语言本身并无关系,比如PYPY就是没有GIL锁的一种解释器。
扩展:进程切换与程序计数器
不同的进程之间能进行切换那么不同的线程之间也必定能进行切换,既然线程是最小的执行单位那么同一进程中的线程切换的代价必然是少于进程间的切换的。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换,这种切换是由操作系统来完成的。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存处理机上下文,包括程序计数器和其他寄存器。
2. 更新PCB信息。
3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4. 选择另一个进程执行,并更新其PCB。
5. 更新内存管理的数据结构。
6.恢复处理机上下文。
注:总而言之就是很耗资源的
程序计数器
我们都知道软件的数据是存储在硬盘上的,这个调用的过程十分缓慢,但是在内存中就会快很多。同时,一个线程或者进程的切换挂起状态如果是存放在内存中那么是肯定不行的,这个速度对于切换毫秒级别的线程或者进程来说速度依旧不够快。所以在CPU旁边有了一个程序计数器的存在,由于距离CPU比较近传输状态的时间也会相应缩短。它的大小并不是很大只有小小的 1 到 2kb ,主要功能就是存储了这些进程或者线程切换状态的数据。存储的其实都是--->内存地址