前言:
在之前的文章中,简单的利用python爬取了代理ip的数据,在这篇文章中讲述一下利用之前用到的爬虫技术爬取赶集网二手货物的相关数据.
思路简介:
通过分析赶集网的商品信息,首先爬取二手商品分类的链接,然后再分别爬取二手商品的具体链接并将其放入数据库中,再通过查询数据库中的链接来完成对商品的具体信息的爬取.
工具:
IDE:Pycharm
环境:Python3.6
数据库:MongoDB
数据库的创建:
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji_data']
url_list = ganji['url_list']
item_info = ganji['item_info']
代理ip的获取:
def get_ips(url):
ips_data = requests.get(url,headers=headers)
soup_ips = BeautifulSoup(ips_data.text,'lxml')
time.sleep(0.5)
ips = soup_ips.select('table#ip_list > tr > td')
i = 1
j = 2
k = 5
ips_list = []
data = {}
while(i < len(ips)):
if ips[i]:
data['ip'] = ips[i].text
if ips[j]:
data['port'] = ips[j].text
if ips[k].text is not 'sock4/5':
data['http_info'] = ips[k].text
i = i + 8
j = j + 8
k = k + 8
if data['http_info'] != 'socks4/5':
ips_list.append(data['http_info'].lower()+"://"+data['ip']+":"+data['port'])
return ips_list
代理ip的处理函数:
由于协议类型不同,所以面对不同的ip类型,应该分别做不同处理,代码如下
def proxys():
url = "http://www.xicidaili.com/"
ips_list = get_ips(url)
proxy_ip = random.choice(ips_list)
if proxy_ip.startswith('http'):
proxies = {'http':proxy_ip}
elif proxy_ip.startswith('https'):
proxies = {'https':proxy_ip}
return proxies
商品分类链接的爬取:
url_host = 'http://lz.ganji.com'
start_url = 'http://lz.ganji.com/wu/'
channel_list = []
def get_channel(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text,'lxml')
links = soup.select('dl > dd > a')
for link in links:
page_url = url_host + link.get('href')
channel_list.append(page_url)
通过打印channel_list列表,我们可以看到的部分信息如下:
http://lz.ganji.com/shuangrenchuang/
http://lz.ganji.com/dianfengshan/
http://lz.ganji.com/tongche/
http://lz.ganji.com/qunzi/
http://lz.ganji.com/fangshaishuang/
http://lz.ganji.com/iphone/
http://lz.ganji.com/nokia/
http://lz.ganji.com/htc/
http://lz.ganji.com/sanxingshouji/
http://lz.ganji.com/motorola/
http://lz.ganji.com/suoniailixin/
定义商品详细信息链接的爬取函数:
links = []
def get_link_from(channel,pages):
#http://lz.ganji.com//o3/
pages_url = '{}o{}/'.format(channel,str(pages))
wb_data = requests.get(url=pages_url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
for link in soup.select('td.t > a'):
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url':item_link})
links.append(item_link)
return links
定义爬取商品详细信息的函数:
定义爬取商品详细信息的函数如下所示:
def get_item_info(url):
info_data = requests.get(url,headers=headers,proxies=proxys())
if info_data.status_code == 404:
pass
#保证爬取页面为.shtml,防止错误页面跳出.
elif url.endswith(".shtml"):
soup = BeautifulSoup(info_data.text, 'lxml')
data = {
'title': soup.select('body > div.content > div > div.box_left > div.info_lubotu > div.box_left_top > h1')[
0].text,
'price': soup.select(
'body > div.content > div > div.box_left > div.info_lubotu > div.info_massege > div.price_li > span > i')[
0].text.strip(),
'area': soup.select(
'body > div.content > div > div.box_left > div.info_lubotu.clearfix > div.info_massege.left > div.palce_li > span > i')[
0].text.strip(),
'detail': soup.select(
'body > div.content > div > div.box_left > div.info_baby > div.baby_talk > div.baby_kuang > p')[
0].text.strip('\n')
}
item_info.insert_one(data)
else:
pass
爬取所有二手商品前一百页的商品链接:
为了保证爬虫的连续运行,防止错误页面跳出,需要加入异常处理.
def get_all_links(channel):
for i in range(1,100):
try:
get_link_from(channel,i)
except Exception:
continue
爬取商品的详细链接:
for url in url_list.find():
try:
get_item_info(url['url'])
except Exception:
continue
在爬虫的运行过程中,我们需要保证url_list表中的数据不能为空,所以,先执行get_all_links()函数.该函数运行完之后,再执行爬取详细页面信息的函数.
最后:
爬取详细商品链接在主函数里分别如下:
if __name__ == '__main__':
#商品详细信息页面链接的处理
pool = Pool(processes=6)
pool.map(get_all_links,channel_list)
pool.close()
pool.join()
#商品详细信息的处理
for url in url_list.find():
try:
get_item_info(url['url'])
except Exception:
continue
注意:
在爬取ip代理的过程中,为了防止频繁的爬取造成网站被block,所以应该加入延时处理.
最后,爬取的结果如下:

url_list.PNG
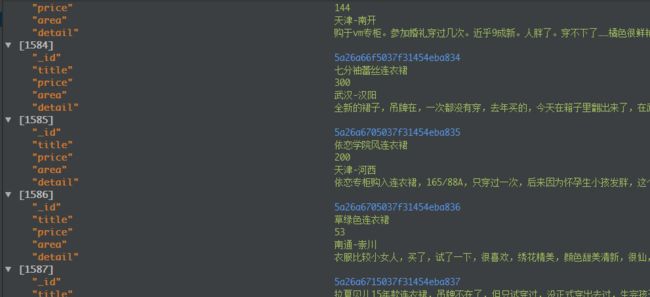
details.png
完整的代码链接