索引(index)_普通索引、唯一索引和复合索引.索引查询
索引对于优化数据库查询效率方面有着非常巨大的作用,下面是一个简单索引查询效率示例,希望能帮到一些朋友。
前提:范例表user_info,通过存储过程插入6万条数据。
表结构:

存储过程:
BEGIN
DECLARE i INT;
SET i =1;
WHILE i <= 60000 DO
INSERT INTO user_info VALUES(i,CONCAT("赵钱",i),CONCAT("passw",i),26);
SET i = i + 1;
END WHILE;
END建立索引前:
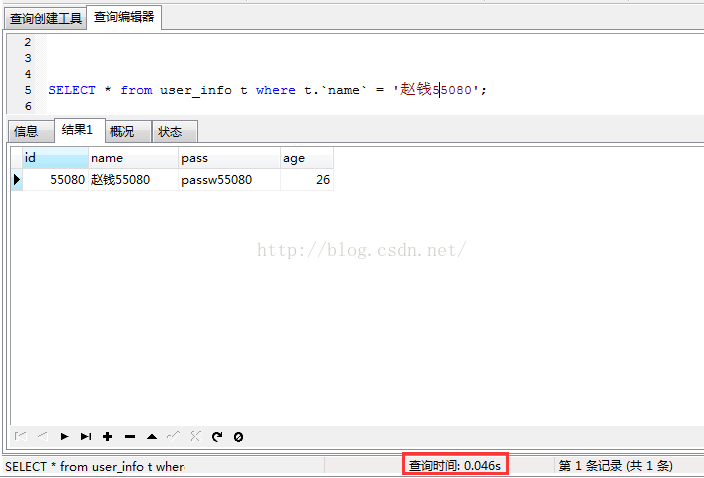
从上执行结果看出,根据name查询时,耗时0.046s;
然后根据id查询,执行结果如下:
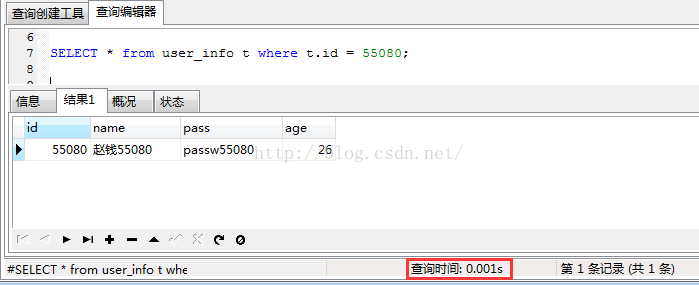
从上可以很明显的看出,根据主键id查询时间短的多得多!
这是因为:创建主键的时候自动给主键添加了索引,且该索引为唯一性索引。
即主键一定是唯一性索引。
但是一张表中可以有多个唯一性索引,所以唯一性索引不一定是主键。
******************************************普通索引和唯一性索引的区别 START***************************************************************
在这里不得不讲一下普通索引和唯一性索引的区别:
1、普通索引
普通索引的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column = )或排序条件(ORDER BY column)中
的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
2、唯一索引
普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个“员工个人资料”数据表里可能出现两次或更多次。
如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好处:一是简化了MySQL对这个索引的管理工作,这个索引也因此而变得更有效率;二是MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
**********************************************************普通索引和唯一性索引的区别 END**********************************************
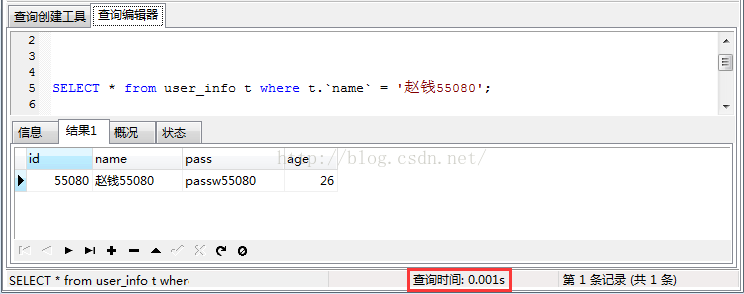
下面开始创建索引(name):
CREATE INDEX ind_user_info_name ON user_info(name);执行成功后根据name查询:
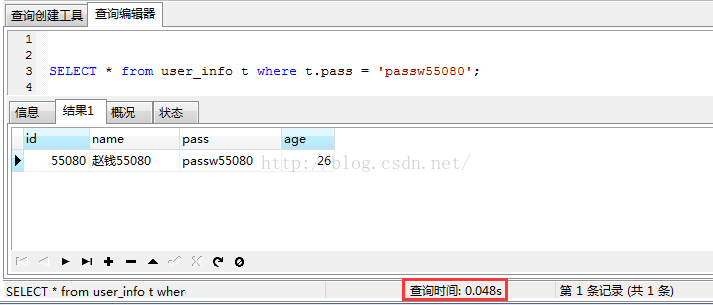
接下来是唯一索引!!用字段pass来示范:
添加索引前:
添加唯一索引:
CREATE UNIQUE INDEX uni_user_info_pass ON user_info(pass);添加索引后再查询:
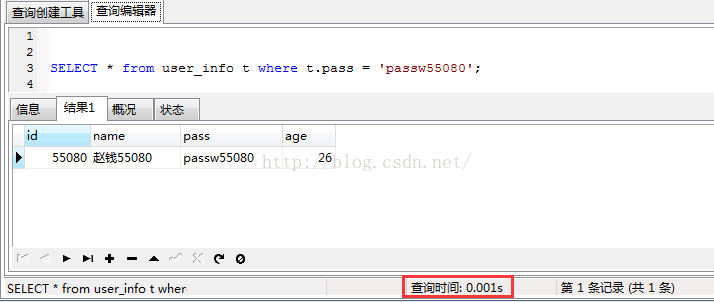
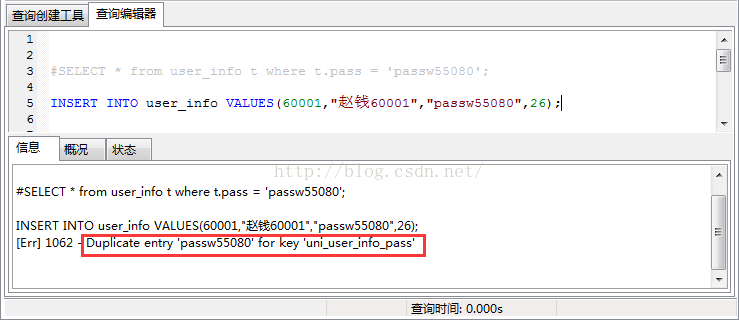
唯一性索引的另一个作用,控制该列不能有相同值!
查看表中所有的索引:

为了下面的演示,把刚创建的两个索引删除!
DROP INDEX ind_user_info_name ON user_info;
DROP INDEX uni_user_info_pass ON user_info;创建一个唯一性复合索引:
CREATE UNIQUE INDEX uni_user_info_pass ON user_info(name,pass);然后执行插入操作:
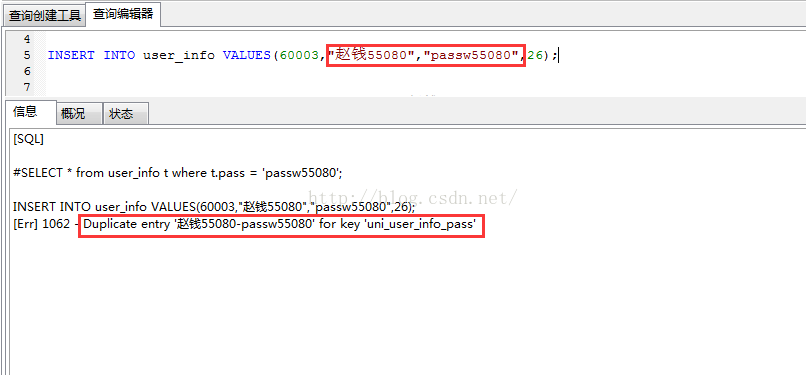
在这里因为是复合型索引,只有当任意两条数据name-pass两字段的值都对应相同时,才起到唯一约束的作用!!!!
关于普通复合索引index这里就不再详细执行截图描述,只需要注意下面这形式的索引意义就OK了!!!!
当建立复合索引index(column1,column2,column3),这就相当于建立了以下三个索引:
index(column1),
index(column1,column2)
index(column1,column2,column3) // 跟三个字段的顺序没有关系 比如:index(column3,column1,column2),它们是一样的效果
上面是创建索引,下面的语句提供查询索引(oracle中经过测试):
select * from user_indexes where table_name='表名';
select * from user_ind_columns where index_name='索引名';
以上
仅供参考,文中有考虑不全的地方,欢迎大家提出宝贵意见!!!!