java多线程同步笔记——阻塞队列
一、阻塞队列
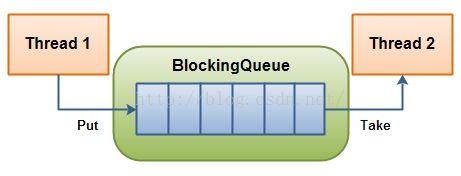
阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞。试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列,同时,阻塞队列里面的put、take方法是被加:synchronized 同步限制,下图展示了如何通过阻塞队列来合作:
二、几种常见阻塞队列
1、BlockingQueue (常用)
获取元素的时候等待队列里有元素,否则阻塞
保存元素的时候等待队列里有空间,否则阻塞
用来简化生产者消费者在多线程环境下的开发
2、ArrayBlockingQueue (数组阻塞队列)
FIFO、数组实现
有界阻塞队列,一旦指定了队列的长度,则队列的大小不能被改变
在生产者消费者例子中,如果生产者生产实体放入队列超过了队列的长度,则在offer(或者put,add)的时候会被阻塞,直到队列的实体数量< 队列的
初始size为止。不过可以设置超时时间,超时后队列还未空出位置,则offer失败。
如果消费者发现队列里没有可被消费的实体时也会被阻塞,直到有实体被生产出来放入队列位置,不过可以设置等待的超时时间,超过时间后会返
回null
3、DelayQueue (延迟队列)
有界阻塞延时队列,当队列里的元素延时期未到是,通过take方法不能获取,会被阻塞,直到有元素延时到期为止
如:
1.obj 5s 延时到期
2.obj 6s 延时到期
3.obj 9s 延时到期
那么在take的时候,需要等待5秒钟才能获取第一个obj,再过1s后可以获取第二个obj,再过3s后可以获得第三个obj
这个队列可以用来处理session过期失效的场景,比如session在创建的时候设置延时到期时间为30分钟,放入延时队列里,然后通过一个线程来获 取这个队列元素,只要能被获取到的,表示已经是过期的session,被获取的session可以肯定超过30分钟了,这时对session进行失效。
4、LinkedBlockingQueue (链表阻塞队列)
FIFO、Node链表结构
可以通过构造方法设置capacity来使得阻塞队列是有界的,也可以不设置,则为无界队列
其他功能类似ArrayBlockingQueue
5、PriorityBlockingQueue (优先级阻塞队列)
无界限队列,相当于PriorityQueue + BlockingQueue
插入的对象必须是可比较的,或者通过构造方法实现插入对象的比较器Comparator
队列里的元素按Comparator comparator比较结果排序,PriorityBlockingQueue可以用来处理一些有优先级的事物。比如短信发送优先 级队列,队列里已经有某企业的100000条短信,这时候又来了一个100条紧急短信,优先级别比较高,可以通过PriorityBlockingQueue来轻松实现 这样的功能。这样这个100条可以被优先发送
6、SynchronousQueue (同步队列)
无内部容量的阻塞队列,put必须等待take,同样take必须等待put。比较适合两个线程间的数据传递。异步转同步的场景不太适用,因为对于异步
线程来说在处理完事务后进行put,但是必须等待put的值被取走。
三、示例(ArrayBlockingQueue)-----多线程快速搜索文件
/**
* 主线程
* @author David
*
*/
public class MainThread implements Strategy{
public int mSum = 0;
public static ExecutorService mThreadPool = Executors.newCachedThreadPool();
public static void main(String[] args) {
// TODO Auto-generated method stub
MainThread thread = new MainThread();
Scanner in = new Scanner(System.in);
String directory;
String keyword;
File file;
do {
System.out.println("Enter a base directory (e.g C:\\user\\malingyi)");
directory = in.nextLine();
file = new File(directory);
System.out.println("Enter keyword (e.g. malingyi)");
keyword = in.nextLine();
} while (!file.isDirectory() || !file.exists());
final int FILE_QUEUE_SIZE = 16; //阻塞队列长度
final int SEARCH_THREADS = 100; // 最大线程数
BlockingQueue queue = new ArrayBlockingQueue<>(FILE_QUEUE_SIZE);
FileEnumerationTask enumerator = new FileEnumerationTask(queue, file);
List> Results = new ArrayList<>(10); //装填搜索任务的数组
new Thread(enumerator).start();
for(int i = 0 ; i <= 10; i++){
Integer integer = new Integer(0);
SearchTask searchTask = new SearchTask(thread,queue, keyword);
}
} public interface Strategy {
/**
* 每当一个线程计算完毕之后,调用该接口,计算包含关键字的文件数量
* @param num 某一个线程工作结束之后传来的统计文件数量
* @return 返回当前的总数,并不是完全的总数。因为有可能还有其他线程正在计算
*/
public int countSum(int num);
}
@Override
/**
* 线程搜索工作完成后,回调该函数
*/
public int countSum(int num) {
// TODO Auto-generated method stub
mSum += num;
System.out.println("该文件夹下,包含所求关键字的文件总数为:"+mSum);
return mSum;
}
}
/**
* 文件枚举任务类
* @author David
*
*/
public class FileEnumerationTask implements Runnable {
public static File DUMMY = new File(""); //虚拟文件,作为扫描的结束标志。
private BlockingQueue mQueue; //阻塞队列
private File mStartingDirectory; //起始文件夹
/**
* 构造一个枚举文件的任务类,负责枚举(深度优先)起始目录下所有的文件个数。
* @param queue 阻塞队列,枚举出来的文件放入该队列中
* @param startingDirectory 用户希望查找的起始文件夹,枚举从该目录下开始。
*/
public FileEnumerationTask(BlockingQueue queue, File startingDirectory) {
// TODO Auto-generated constructor stub
mQueue = queue;
mStartingDirectory = startingDirectory;
}
@Override
public void run() {
// TODO Auto-generated method stub
try {
enumerate(mStartingDirectory); // 递归的遍历起始目录下以及其子目录下的所有文件
mQueue.put(DUMMY); // 遍历完毕之后,将虚拟文件夹加入队列中,便于之后搜索的结束标记确认。
} catch (InterruptedException e) {
// TODO: handle exception
}
}
/**
* 遍历检查该目录下所有的文件以及其子目录下的所有文件总数。(使用递归)
* @param directory 开始枚举的文件夹
* @throws InterruptedException
*/
protected void enumerate(File directory) throws InterruptedException{
//先确认该文件夹非空且内部含有子文件
File[] files = directory.listFiles();
if (files != null && files.length > 0) {
for (File file : files) {
if (file.isDirectory()) {
enumerate(file);
}else {
mQueue.put(file);
}
}
}
return ;
}
}
/**
* 搜索任务类,每个搜索人物类分配一定的搜索任务(大小依据何时遇到虚拟文件从而结束)
*/
public class SearchTask implements Runnable {
private BlockingQueue mBlockQueue;
private String keyword;
private int count = 0;
private boolean isfinish = false;
Strategy mStrategy ;
public SearchTask(Strategy strategy,BlockingQueue blockingQueue, String keyword) {
// TODO Auto-generated constructor stub
mStrategy = strategy;
mBlockQueue = blockingQueue;
this.keyword = keyword;
}
@Override
public void run() {
// TODO Auto-generated method stub
try {
boolean done = false;
while (!done) {
File file = mBlockQueue.take(); // 取出队列的头元素
if (file == FileEnumerationTask.DUMMY) {
mBlockQueue.put(file); //遇到虚拟文件夹,将其放入队列中,该线程搜索任务完毕
//当队列中只剩下虚拟文件夹的时候,所有线程都将退出
done = true;
}else {
if (search(file)) {
count++;
}
}
}
if (done) {
mStrategy.countSum(count);
}
} catch (FileNotFoundException e) {
// TODO: handle exception
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
protected boolean search(File file) throws FileNotFoundException{
try(Scanner in = new Scanner(file)){
int lineNumber = 0;
while (in.hasNextLine()) {
lineNumber++;
String line = in.nextLine();
if (line.contains(keyword)) {
// System.out.printf("%s:%d:%s\n",file.getPath(),lineNumber,line);
return true;
}
}
return false;
}
}
}
四、总结
使用java自带的阻塞队列包,可以很方便的进行多线程同步的控制,不用进行加锁和唤醒的处理,程序员不需要担心线程安全问题,可以更专注
于其他方面的编程。