实验设计与分析 (总结8)
1.1 实验设计
我们将设计一系列实验来验证渐次全局裁剪框架的运算效率和有效性。首先,我们将要验证在不同应用场景下,不同神经元筛选策略的性能差别。在通常的应用场景中,我们训练了一个用于CIFAR-10图片分类的栈式神经网络。在迁移学习的场景下,我们使用VGG-16在ImageNet上的预训练权重作为迁移学习的模型,以Kaggle数据竞赛猫狗大战为学习目标。
其次,我们在栈式神经网络上比较了所提出的渐次裁剪框架与全局等比例裁剪的性能。我们以模型在验证集上的准确率作为模型性能的衡量指标。最后,我们选取一种冗余神经元筛选方法,在给定性能指标的情况下进行自动化裁剪,展示了渐次全局裁剪框架具有能够自动发现网络在给定性能指标下的近似最优结构的能力,并通过参数量与运算速度的比较检查网络裁剪的实际效果。
https://www.kaggle.com/c/dogs-vs-cats
1.2 网络模型与数据集
我们训练了一个栈式网络用于CIFAR-10图片分类。CIFAR-10是深度学习领域经常使用的基准数据集,由50000张10个类别的小图片和10000张各个类别的验证集构成,每张图片均为32x32的彩色图片。CIFAR-10数据集的类别和部分图片展示如图5-1。我们搭建了一个栈式卷积神经网络进行CIFAR-10图片分类训练,所使用的网络结构与前面介绍的VGG-16网络类似,但在每个卷积层和全连接层后都增加了BN层。同时,相对于VGG-16网络,我们在卷积层后仅设置了两个全连接层,且首个全连接层的隐层神经元由原来的2048降为512。由于使用了BN层加速收敛,我们没有使用Dropout。我们记该模型为模型1。经过200轮训练,我们在CIFAR-10验证集上取得87.32%的正确率。 在迁移学习应用场景下, 我们以VGG-16的预训练权重为蓝本,在Kaggle猫狗识别问题上进行迁移学习。

由于猫、 狗本身就是ImageNet竞赛中包含的两类, 两项任务高度重合, 因此我们在迁移学习时保留了VGG-16的几乎全部结构,仅仅将最后一层由1000分类变为2分类,并重新进行训练。Kaggle猫狗竞赛包含25000张有标记的图片,我们随机选取20000张进行训练,以剩余5000张图片作为验证集。我们记该模型为模型2。模型2在验证集上取得了98.24%的正确率,其输入图像大小为224x224x3。图片内容复杂性较高,属于比较贴近实际应用场景的数据集。部分图片展示如下。

1.3 评估神经元选择方案的性能
一般引用场景下,即从头开始训练的神经网络更适合使用数据无关的冗余神经元筛选方法,因为在网络训练的参数由训练集确定,本身已经包含了训练集的信息。相反,在迁移学习场景下,网络的参数与原先的训练集有关,而与迁移学习的目标数据集关系不大,因此我们认为数据相关的神经元筛选方法适合迁移学习场景。
1.4 一般应用场景下的全局网络裁剪
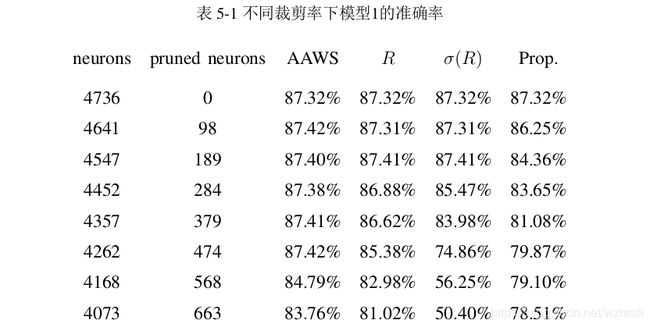
我们首先估计了一般应用场景下的全局裁剪,即从随机初始化的权重训练得到的网络。我们从0开始,逐渐提高神经元的裁减比例,在不进行微调的情况下观察网络在验证集上的准确率。在三种不同的冗余神经元选择策略上,我们得到的结果如表5-1。值得注意的是,在我们所提出的框架中,每一步被裁剪掉的神经元均为较小比例,因此在这里我们展示的是裁减率从0开始,以2%为步长增长的7步裁剪结果。
注意到在小比例的裁减下,AAWS方法与R方法有近似相同的性能,AAWS方法略有优势。而σ(R))方法的性能明显落后于其余两种。这是因为σ(R)评估的是神经元在数据集上响应的稳定性,对全连接网络而言,稳定响应的神经元可在裁减时通过连接权将其平均响应作为偏置叠加在后序神经元上,从而大大减少该神经元裁剪所带来的性能损失。而对卷积神经网络而言,无法执行类似的“响应转
移” ,因此σ(R)的性能在这里表现最差。
我们取5%为裁剪步长,对模型1执行渐次全局裁剪,得到如图5-3的结果,该结果与我们上面的分析大致相同。

1.5 应用在迁移学习的网络裁剪
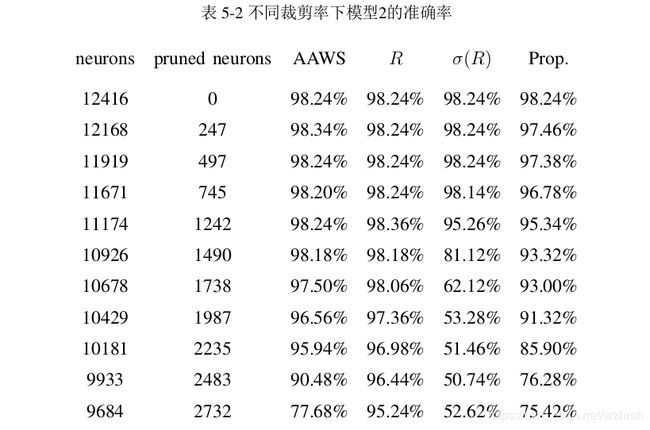
在迁移学习的场景下,我们做了相同的实验,其结果如表5-2。从结果中可以看出,首先,在迁移学习的场景下,数据相关的评价方法R相比较数据无关的学习方法具有了优势,σ(R)评价方法依然由于无法进行“响应转移”而表现出巨大劣势。其次,VGG-16网络由于体积庞大,同时也表现出巨大的冗余性。
1.6 渐次全局裁剪与等比例裁剪
等比例裁剪是在各个层等比例的选择部分神经元作为冗余神经元,其基本假设是网络的冗余神经元均匀的分布在各个层中。我们分别在模型1和模型2上选择性能最好的冗余神经元筛选办法,并对比全局筛选与等比例选择的网络性能,我们将不加微调的评估结果附在表5-1与5-2的最后一列。注意,表5-1的最后一列采用的是AAWS评价方法,而表5-2的最后一列采用的是R评价方法。可以看到,所提出的全局神经元筛选方法要明显优于等比例筛选方法。渐次全局裁剪与等比例裁剪在模型1上的性能对比如图5-4。
1.7 渐次全局裁剪与逐层裁剪
逐层裁剪难以避免的问题是,在给定的模型性能下,如何确定每一层被裁剪掉的神经元比例。由于缺乏理论指导,在逐层裁剪中往往只能通过试错来逐渐确定合适的裁减比例,这将导致网络裁剪所需的微调次数大幅度增加。为了保证我们的全局裁剪与逐层裁剪在计算量上的可比性,在逐层裁剪的实验中,我们以全局裁剪得到的整体裁剪比例作为每一层的裁减比例。具体而言,每层将30.11%的神经元被剪除。与等比例裁减不同的是,在逐层裁剪中,每一层的参数被剪除后,整个网络即微调一次。在这种条件下,逐层裁剪所需要的微调次数与网络层数相同。经过14轮裁剪后,逐层裁剪得到的网络性能为86.48%,而全局裁剪在经过7轮裁剪得到的网络准确率为86.92%。

值得注意的是,尽管经过多次实验,全局裁剪相对于逐层裁剪的有稳定的优势,但性能上的微弱优势并非是全局裁剪的主要优点。事实上,我们相信经过仔细试错的逐层裁剪能够达到比所提出的渐次全局裁剪更好的性能。我们强调,渐次全局裁剪的优势体现在计算复杂度低,以及不需要确定各层裁减比例两个方面。全局裁剪的方法将网络裁剪所需要的微调轮数从网络层数转移到网络裁剪步长上,使得对更深层的网络而言,网络裁剪的效率更高。
1.8 经过裁剪后的网络结构
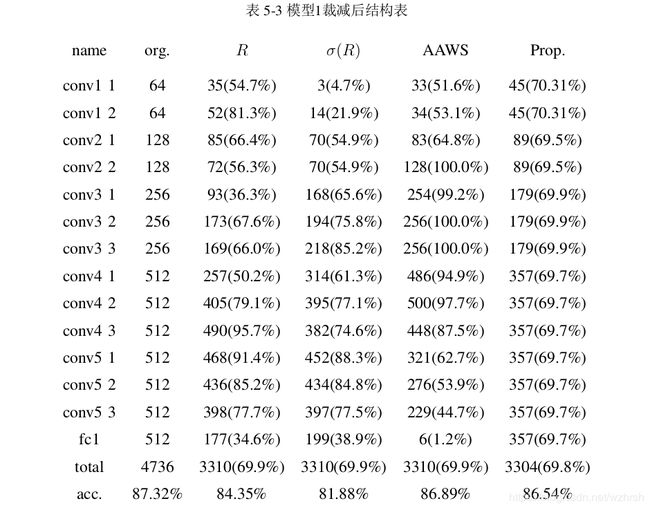
渐次全局裁剪的主要优点之一是,在给定网络性能指标下,裁减过程能够自动发现网络的近似最优结构。经过裁减后的网络结构也能从另一方面反应各种裁减方案的裁剪倾向,括号内为每层保留的神经元占比。表5-3展示了模型1在不同的冗余神经元筛选方法上经过7步裁剪后各个层的神经元数目。这里我们设定原模型的准确率下降1%,即模型1的准确率不低于86.32%为网络性能下限,为了便于对比,在AAWS筛选方法下取得该下限性能后,我们在其他的筛选方法上执行相同轮数的裁剪,保证经过裁减后的网络具有同样的神经元个数。

从结果可以看到,对模型1而言,R和σ(R)对网络的裁剪比较均匀,各个网络层均有一定比例的裁剪,但σ(R)对低层网络裁剪力度更大。这种现象的主要原因是,网络的低层提取的是图像的底层特征,无论是什么样的图片,或多或少总能找到类似的底层特征,因此底层网络响应的方差较小,容易被优先裁剪。AAWS对底层和高层,特别对于全连阶层具有非常大的裁剪力度,而对中间层几乎很少裁剪。
类似的,我们对迁移学习场景下的网络以1%的准确率下降进行裁剪,为加速裁减过程,我们使用AAWS方法进行神经元筛选,并在首轮裁剪中进行多轮次微调,以保证AAWS的可靠性,随着裁剪的进行,AAWS的方法与R方法的差别将逐渐减少。我们所得到的网络结构如表5-4。
小结:网络层对输入信号的响应强度具有层次性特点,网络层所处的位置越高,对输入信号的响应强度就越大。响应的波动情况也具有类似的特点。其次,网络的冗余神经元大量存在于全连接层中,而不是等比例的分布在各个层里。在裁剪的过程中我们观察到,全连接层的裁剪对模型性能影响较小,而卷积层内的裁剪对模型性能影响较大。对全连接层的裁剪不但能够有效降低模型大小,而且能够最大限度的保持模型精度。此外,数据无关的冗余神经元筛选标准更适合于一般的应用场景,而在迁移学习场景下,数据相关的冗余神经元筛选标准更为适合,但经过几轮的裁剪后,由于微调过程对权重的调整,使得数据无关的评价准则也逐渐变得可用。这些结论有益于加深对神经网络的理解,也有利于开发新的网络压缩方法。