Java IO 底层原理
引言
一提到 IO,就绕不开对 page cache(页缓存)的讨论,页缓存是操作系统为了提升磁盘读写性能在应用进程与磁盘之间加设的提供预读和异步刷盘机制的内核缓冲区。java 的 IO 操作是建立在操作系统的 IO 之上的,从最基础的 read/write 系统调用,到具有零拷贝特性的 sendfile、mmap,在 java 中都能看到它们的身影。本文的主要目的是纵观全局,鸟瞰 java IO 体系,并指出每种 IO 方式的特点与使用场景。整篇文章会围绕下图作分步讲解,为了简单起见,这里主要以写操作为例。
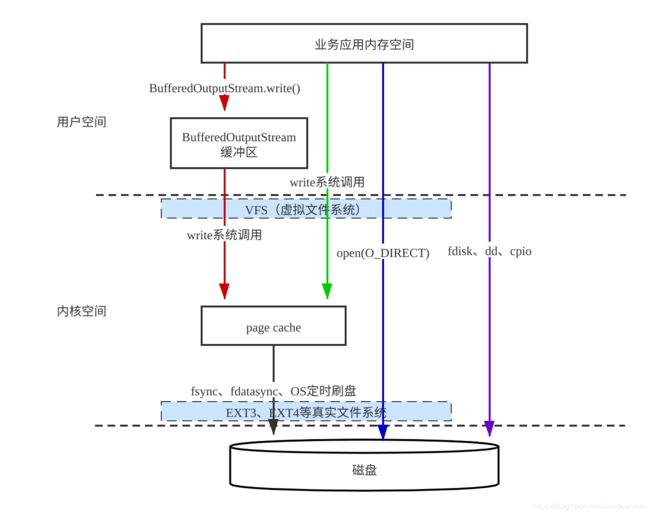
一、普通 IO
看绿色箭头指示的数据流向,每次写操作都会调用 write 系统调用,将数据写入到内核空间页缓存中然后返回,注意这时候数据还没有被写入到磁盘,操作系统中会有个定时任务负责将符合条件的数据写入到磁盘(这一过程简称刷盘),应用进程无需关心。下面是普通 IO 示例代码:
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author debo
* @date 2020-06-25
*/
public class FileOutputStreamTest {
private static final long COUNT = 1000_0000L;
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream("/home/debo/tmp.txt");
String msg = "你好,world!";
long start = System.currentTimeMillis();
for (int i = 0; i < COUNT; i++) {
// 每次都会产生write系统调用
fos.write(msg.getBytes());
}
fos.close();
System.out.println(String.format("耗时:%d毫秒", System.currentTimeMillis() - start));
}
}
这个程序循环一千万次写操作,也就是产生一千万次的 write 系统调用,程序执行完耗时 14 秒左右。
二、带缓冲区的 IO
红色箭头表示了另一种 IO 方式,在程序进行写操作的时候,并不是每次都会产生 write 系统调用,而是会在用户空间开辟一个缓冲区,先将数据暂存在这个缓冲区,等缓冲区满或者手动 flush() 的时候,才会调用 write 系统调用将数据写到 page cache,代码如下:
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author debo
* @date 2020-06-25
*/
public class BufferedOutputStreamTest {
private static final long COUNT = 1000_0000L;
public static void main(String[] args) throws IOException {
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("/home/debo/tmp.txt"));
String msg = "你好,world!";
long start = System.currentTimeMillis();
for (int i = 0; i < COUNT; i++) {
// 先写到缓冲区,等缓冲区满才会产生write系统调用将数据写入page cache
bos.write(msg.getBytes());
}
bos.close();
System.out.println(String.format("耗时:%d毫秒", System.currentTimeMillis() - start));
}
}
这个程序执行完耗时 0.9 秒,与不带缓冲区的 IO 相比性能提升 15 倍!如果执行一亿次循环,性能提升会更明显。
这个带缓冲区的 BufferedOutputStream 性能提升的法宝就是:每次调用 write() 方法并不会产生实际的 write 系统调用,而是会先将数据存放于 BufferedOutputStream 实例内部的缓冲区中(缓冲区默认大小 8 KB),等缓冲区满、或者手动调用 BufferedOutputStream.flush() 或 close() 方法时,才会真正调用 write 系统调用将缓冲区数据写入 page cache,这样就比不带缓冲区的 IO 少了很多次的系统调用,性能自然就大大提升了。
三、page cache 刷盘策略
既然数据都在 page cache 中,那么什么时候会被写入磁盘呢?其实操作系统有一个定时任务会定时查看是否满足刷盘条件(比如 page cache 占用内存空间超过设定值等),如果满足,就会将数据写入磁盘。此外,操作系统也提供了手动刷盘的系统调用,当应用进程调用 fsync 或 fdatasync 系统调用时,就会将 page cache 数据同步写入磁盘直到成功返回。所以很多支持持久化的中间件(比如 redis)都会提供以下几种刷盘策略:
- 依赖操作系统的自动刷盘机制
- 每次写完数据后都调用 fsync 强制刷盘
- 折衷方案,以固定的时间间隔调用 fsync 强制刷盘,比如 1 秒刷一次
java 中是如何控制手动刷盘的呢?如果用的是流式 IO(OutputStream 的子类),是没有提供相应 API 的,但可以调用以下实例的方法来完成手动刷盘:
- 使用 RandomAccessFile 读写文件时,在
RandomAccessFile.write()后使用RandomAccessFile.getFD().sync()方法手动刷盘 - 使用 FileChannel 读写文件时,在
FileChannel.write()后使用FileChannel.force()方法手动刷盘 - 使用 MappedByteBuffer 读写文件时,在
MappedByteBuffer.put()后使用MappedByteBuffer.force()方法手动刷盘
关于 RandomAccessFile 、FileChannel 以及 MappedByteBuffer 的详细使用,请参考 这篇文章。
四、绕过 page cache 的 IO
每次数据都写入页缓存在某些场合下会存在问题,试想一下,在还没来得及刷盘的情况下,突然断电了,那么在 page cache 中的数据就丢失了,这对于一些要求数据强一致性和完整性的服务是无法接受的,比如 MySQL 数据库等。通常情况下,这类应用会绕过 page cache,将数据直接写入磁盘,如图中蓝色路径所示。应用进程在调用 open 系统调用创建文件描述符的时候,只要设置 flag 参数为 O_DIRECT,那么接下来的读写操作都将绕过 page cache 而直接写入磁盘。不过 java 中并没有提供此类操作的API,要想在 java 中实现同样的功能,可以使用 JNI 技术调用封装了该功能的 C 语言代码。
五、直接操纵磁盘
open(O_DIRECT) 系统调用虽然绕过了 page cache,但是是在操作系统的文件系统规范下完成的。在以 EXT3 为文件系统的操作系统中写入一批数据到磁盘,然后将磁盘卸载,装载到另一个以 EXT3 为文件系统的操作系统中时,之前写的那批数据在新操作系统中是可以被识别的。而使用 dd 等 Linux 系统自带的软件,可以绕过文件系统,直接向磁盘中写入最纯粹(RAW)的数据,如图中紫色箭头所示。通过这种方式写入的数据,操作系统是无法识别的,如果将磁盘卸载后装载到另一台电脑中,磁盘数据是不会被读出来的。
六、mmap 系统调用
mmap 系统调用可以将文件的一个指定区域直接映射到用户进程的虚拟地址空间,这样当用户进程操作文件时,就像操作分配给自己的内存一样。更详细地说,就是以普通方式去读写文件时,会产生 read/write 系统调用,而通过 mmap 方式操作文件时,在文件读写的过程中不会产生系统调用。
这么说的话,mmap 比普通方式更高效吗?其实不然。将文件映射到内存这一过程的代价是很昂贵的,如果是一个很小的文件(几十 KB),只需要很少的 read/write 操作就能将文件读取到内存或写入到磁盘,如果是用 mmap,所需的代价可能会更大。因此,mmap 在读写大文件的时候比较有优势。
以 mmap 方式读写文件时,是直接读写内核空间的 page cache,而不需要经由用户空间到内核空间的内存拷贝。既然涉及到 page cache,因此也会存在断电后数据可能丢失的情况。针对需要确保数据强一致性和完整性的场合,mmap 提供了 msync 系统调用来手动将 page cache 中的数据同步写入到磁盘。在 java 中使用 MappedByteBuffer 来表示这块内存映射区域,相应的手动刷盘 API 为 MappedByteBuffer.force()。
下面是 mmap 写操作的简单示例:
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel.MapMode;
/**
* @author debo
* @date 2020-06-25
*/
public class MappedByteBufferWriteTest {
private static final long COUNT = 1000_0000L;
public static void main(String[] args) throws IOException {
RandomAccessFile raf = new RandomAccessFile("/home/debo/tmp.txt", "rw");
String msg = "你好,world!";
// 内存映射区域总大小
long size = msg.getBytes().length * COUNT;
long start = System.currentTimeMillis();
MappedByteBuffer map = raf.getChannel().map(MapMode.READ_WRITE, 0, size);
for (int i = 0; i < COUNT; i++) {
map.put(msg.getBytes());
}
raf.close();
System.out.println(String.format("耗时:%d毫秒", System.currentTimeMillis() - start));
}
}
MappedByteBuffer 的详细使用,请参考 这篇文章。
七、使用 strace 追踪系统调用
依前面所说,mmap 读写不产生系统调用,FileOutputStream 每次读写都会产生系统调用。作为 java 程序员,无法直观地去感受这些结论,除非懂 c/c++,去探究 JVM 源码,这样的话就太大动干戈了。好在 Linux 中有很多现成的工具可以追踪这些系统调用,下面以 strace 命令为例来演示如何追踪 java 程序底层产生的系统调用。
以上面的 FileOutputStreamTest 程序为例,修改该程序,将循环次数 COUNT 改成 10 以方便演示,然后在命令行执行此程序:
javac FileOutputStreamTest.java && strace -ff -o out java FileOutputStreamTest
执行完程序后,会在当前工作目录下生成若干 out.pid 文件,如图所示
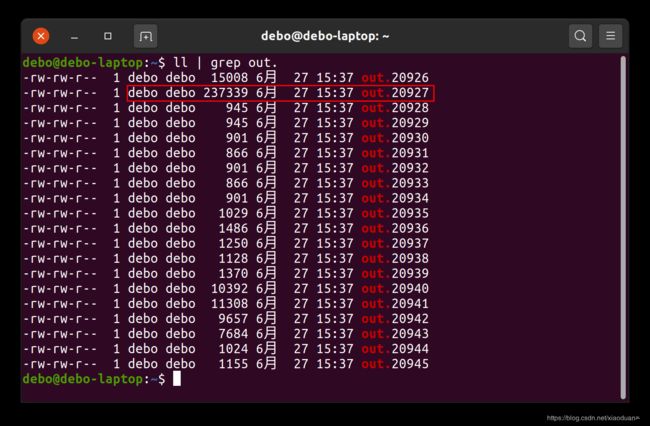
然后用以下命令查看最大的 out.pid 文件,这里是 out.20927
cat out.20927 | grep -C 20 world
输出结果如图所示:
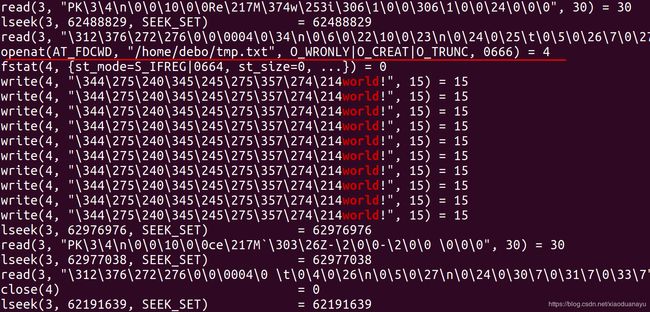
可以看到,在 openat 系统调用(作用是创建文件,同 open 系统调用)之后,共产生了 10 次 write 系统调用,这和程序中的循环次数相吻合,也印证了 FileOutputStream.write() 写操作每次都会产生系统调用这一结论。
参考资料
漫谈linux文件IO
洞悉MySQL底层架构:游走在缓冲与磁盘之间
Linux 中直接 I/O 机制的介绍
从内核文件系统看文件读写过程