数据结构和算法:Big-Data-Structure 大话数据结构 算法复杂度 线性表 非线性表 查找 排序
Big-Data-Structure 大话数据结构
博文末尾支持二维码赞赏哦 _
本文github
我们学习数据结构和算法,并不是为了死记硬背几个知识点。我们的目的是建立时间复杂度、空间复杂度意识,写出高质量的代码,能够设计基础架构,提升编程技能,训练逻辑思维,积攒人生经验,以此获得工作回报,实现你的价值,完善你的人生。
所以,不管你是业务开发工程师,还是基础架构工程师;不管你是初入职场的初级工程师,还是工作多年的资深架构师,又或者是想转人工智能、区块链这些热门领域的程序员,数据结构与算法作为计算机的基础知识、核心知识,都是必须要掌握的。
掌握了数据结构与算法,你看待问题的深度,解决问题的角度就会完全不一样。因为这样的你,就像是站在巨人的肩膀上,拿着生存利器行走世界。数据结构与算法,会为你的编程之路,甚至人生之路打开一扇通往新世界的大门。
1. 数据结构绪论
数据结构起源
数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及它们之间的关系和操作等相关问题的科学。
巧妇难为无米之炊。米----就是数据。
基本概念和术语
- 数据: 数据是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机的符号集合。
- 数据元素: 是组成数据的、有一定意义的基本单位,在计算机中通常作为整体处理,也被称为记录。
- 数据项: 一个数据元素由若干个数据项组成,数据项是数据不可分割的最小单位。
- 数据对象: 是性质相同的数据元素的集合,是数据的子集。
- 数据结构: 是相互之间存在一种或多种特定关系的数据元素的集合。
逻辑结构与物理结构
逻辑结构
是指数据对象中 数据元素之间 的 相互关系。 类似人与人之间的关系
- 集合结构: 集合结构中的数据元素除了同属于一个集合外,它们之间没有其他关系。
- 线性结构: 线性结构中的数据元素之间是一对一的关系。
- 树形结构: 树形结构中的数据元素之间存在一种一对多的层次关系。
- 图形结构: 图形结构的数据元素是多对多的关系。
物理结构
是指数据的逻辑结构在 计算机中的 存储形式
- 顺序存储结构: 是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致
排队占位–占坑–排队摇号买房—
- 链式存储结构: 是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的。
排队系统–先取号-等待时爱在哪在哪–等号到了—就上–
类似—特工–间谍–单线暗号联系–不知所踪–无间道电影—链式关系–
抽象数据类型
-
数据类型: 是指一组性质相同的值得集合及定义在此集合上的一些操作的总称。
- 原子类型: 是不可以再分解的基本类型,包括整型、实型、字符型等。
- 结构类型: 由若干个类型组合而成,可以是再分解的。例如:整形数组是由若干整形数据组成的。
抽象 是指抽取出事物具有的普遍性的本质。概括能力–破云见雾的能力–
-
抽象数据类型(Abstract Data Type, ADT): 是指一个数学模型及定义在该模型上的一组操作。
抽象数据类型的标准格式
ADT 抽象数据类型名
Data
数据元素之间逻辑关系的定义
Operation
操作1
初始条件
操作结果描述
操作2
……
操作n
……
endADT
总结回顾
- 数据结构概念
- 数据结构分类
2.算法
算法定义
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
算法的特性
- 输入输出: 算法具有零个或多个输入
- 有穷性: 指算法在执行有限的步骤之后,自动结束而不会出现无限循环,并且每一个步骤在可接受的时间内完成。
- 确定性: 算法的每一个步骤都具有确定的含义,不会出现二义性。
- 可行性: 算法的每一步都必须是可行的,也就是说每一步都能够通过执行有限的次数完成。
算法设计的要求
-
正确性: 算法的正确性是指算法至少应该具有输入、输出和加工处理无歧义性、能正确反映问题的需求、能够得到问题的正确答案。
-
- 算法程序没有语法错误
-
- 算法程序对于合法的输入能够产生满足要求的输出结果
-
- 算法程序对于非法的输入数据能够得出满足规格说明的结果。
-
- 算法程序对于精心选择的,甚至刁难的测试数据都有满足要求的输出结果。
-
可读性: 算法设计的另一目的是为了便于阅读、理解和交流。
-
健壮性: 当输入数据不合法时,算法也能做出相关处理,而不是产生异常或莫名其妙的结果。
-
时间效率高和存储量低: 设计算法应该尽量满足时间效率高和存储量低的需求。
算法效率的度量方法
是骡子是马,拉出来溜溜
- 事后统计方法: 这种方法主要是通过设计好的测试程序和数据,利用计算机计时器对不同算法编制的程序运行时间进行比较,从而确定算法效率的高低。
- 事前分析估算方法: 在计算机程序编制前,依据统计方法对算法进行估算。
函数的渐进增长
给定两个函数 f(n) 和 g(n), 如果存在一个整数 N,使得对于所有的 n > N, f(n) 总是比 g(n) 大,那么我们说f(n)的增长渐进快于 g(n)。
算法的时间复杂度
算法时间复杂度的定义
在进行算法分析时,语句总的执行次数 T(n) 是关于问题规模 n 的函数,进而分析 T(n) 随 n 的变化情况并确定 T(n)的数量级。算法的时间复杂度,也就是算法的时间量度,记作:T(n)=O(f(n))。它表示随问题规模的增大,算法执行时间的增长率和 f(n) 的增长率相同,乘坐算法的渐进时间复杂度,简称为时间复杂度。其中 f(n) 是问题规模 n 的某个函数。
推导大O阶方法
-
- 用常数 1 取代运行时间中的所有加法常数。
-
- 在修改后的运行次数函数中,只保留最高阶项。
-
- 如果最高阶项存在且不是 1,则去除与这个项相乘的常数。得到的结果就是大 O 阶
常数阶
int sum =0, n=100;
sum = (1+n)*n/2;
printf("%d", sum);
-
- 算法运行次数函数为 f(n) = 3;
-
- 用常数 1 取代运行时间中的所有加法常数,得到 f(n) = 1。
-
- 由于没有最高阶项,所以此算法的时间复杂度为 O(1)。
线性阶
int i;
for(i=0; i<n; i++) {
/* 时间复杂度为 O(1) 的程序步骤序列 */
}
-
- 算法运行次数的函数为 f(n) = n;
-
- 没有加法常数取代, f(n) = n;
-
- 只保留最高阶项,f(n) = n;
-
- 最高阶项存在但是1,所以该算法时间复杂度为 O(n)
对数阶
int count = 1;
while(count < n) {
count = count * 2;
/* 时间复杂度为 O(1) 的程序步骤序列 */
}
-
- 有多少个 2 相乘后大于 n,则会退出循环,由 2^x = n, 得到算法运行次数函数 f(n) = log2n。
-
- 没有加法常数取代, f(n) = log2n。
-
- 至保留最高阶项,f(n) = log2n。
-
- 最高阶项存在且不是1,去除与这个项相乘的系数,所以该算法时间复杂度为 O(logn)
-
如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了。而且,O(nlogn) 也是一种非常常见的算法时间复杂度。比如,归并排序、快速排序的时间复杂度都是 O(nlogn)。
平方阶
int i, j;
for(i=0; i<n; i++) {
for(j=0; j<n; j++) {
/* 时间复杂度为 O(1) 的程序步骤序列 */
}
}
-
- 算法运行次数函数 f(n) = n^2。
-
- 没有常数,f(n) = n^2。
-
- 只保留最高阶项,f(n) = n^2。
-
- 最高阶项存在但系数为1,所以该算法时间复杂度为 O(n^2)
常见的时间复杂度
| 执行次数函数 | 阶 | 非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n^2 + 2n +1 | O(n^2) | 平方阶 |
| 5log2n + 20 | O(logn) | 对数阶 |
| 2n + 3nlog2n + 19 | O(nlogn) | nlogn 阶 |
| 6n^3 + 2n^2 + 3n + 4 | O(n^3) | 立方阶 |
| 2^n | O(2^n) | 指数阶 |
常用时间复杂度所耗费的时间从小到大依次是:
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(n!) < O(nn)
最坏情况与平均情况
最坏情况运行时间是一种保证,那就是运行时间不会再坏了。在应用中,这是一种最重要的需求,通常,除非特别指定,我们提到的运行时间都是最坏情况的运行时间。
平均运行时间是所有情况中最有意义的,因为它是期望的运行时间。
一般没有特殊说明的情况下,时间复杂度都是指最坏时间复杂度。
算法空间复杂度
算法的空间复杂度通过计算算法所需的存储空间时间,算法空间复杂度的计算公式记作:S(n)=O(f(n)), 其中 n 为问题的规模,f(n) 为语句关于 n 所占存储空间的函数。
通常我们都使用 “时间复杂度” 来指运行时间的需求, “空间复杂度” 来指空间徐秀。当不用限定词的使用 “复杂度” 时,通常是指时间复杂度。
总结回顾
算法的定义: 算法是解决特定问题求解步骤的描述,在计算机中卫指令的有限序列,并且每条指令表示一个或多个操作。
算法的特性: 有穷性、确定性、可行性、输入、输出。
算法的设计的要求: 正确性、可读性、健壮性、高效率和低存储量需求。
算法的度量方法: 事后统计方法(不科学、不准确),事前分析估算方法。
函数的渐进增长: 给定两个函数 f(n) 和 g(n),如果存在一个整数 N, 使得对于所有的 n > N, f(n) 总是比 g(n) 大,那么我们说 f(n) 的增长渐进快于 g(n)。
推导大 O 阶:
- 用常数 1 取代运行时间中的所有加法常数
- 在修改后的运行次数函数中,只保留最高阶项
- 如果最高阶项存在且不是1,则去除与这个项相乘的常数。
得到的结果就是大 O 阶
常见时间复杂度所耗时间的大小排列: O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(n!) < O(n^n)
3.线性表
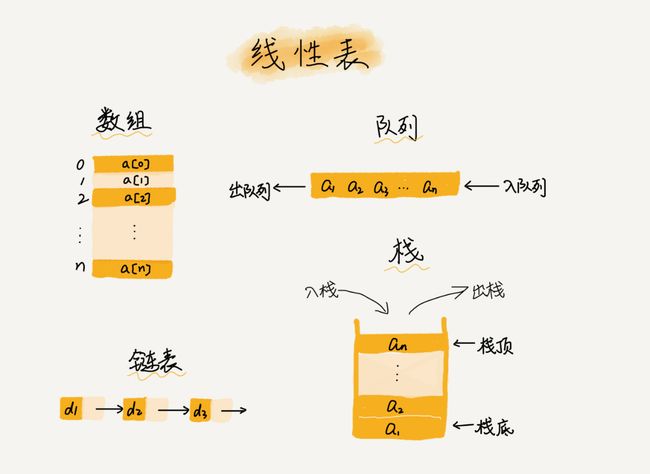
而与它相对立的概念是非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
线性表的定义
线性表:零个或多个数据元素的有限序列
若使用数学语言定义:
若将线性表记为(a1, …, ai-1, ai, ai+1, …, an)则表中ai-1领先于ai, ai 领先于ai+1,称ai-1是ai的直接前驱元素,ai+1是ai的直接后继元素。当 i=1, 2, …, n-1 时,ai有且仅有一个直接后继,当 i=2, 3, …, n时,ai有且仅有一个直接前驱
所以
线性表元素的个数 n (n≥0)定义为线性表的长度,当n=0时,称为空表
线性表的抽象数据类型
ADT 线性表(List)
Data
线性表的数据对象集合为{a1,a2,...,an}, 每个元素的类型均为 DataType。
其中除第一个元素a1外,每一个元素有且仅有一个直接前驱元素,
除了最后一个元素an外,每一个元素有且仅有一个直接后继元素。
数据元素之间的关系是一对一的关系
Operation
InitList(*L): 初始化操作,建立一个空的线性表 L。
ListIsEmpty(L): 若线性表为空,返回 true, 否则返回false。
ClearList(*L); 将线性表置空
GetElem(L,i,*e): 将线性表 L 的第 i 个元素返回给 e。
LocateElem(L, e): 在线性表 L 中查找与给定值 e 相等的元素,若查找成功,返回该元素在表中序号表示成功,否则返回0表示失败
ListInsert(*L,i,e): 在线性表 L 中第 i 个位置插入新元素 e。
ListDelete(*L,i,*e): 删除线性表中第 i 个位置的元素,并用 e 返回其值。
ListLength(L): 返回线性表 L 的元素个数
endADT
线性表的顺序存储结构
顺序存储定义: 线性表的存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素
顺序存储方式: 可以用一维数组来实现顺序存储结构
#define MAXSIZE 20 // 存储空间初始分配量
typedef int ElemType; // ElemType类型根据实际情况而定, 这里假设为 int
typedef struct {
ElemType data[MAXSIZE]; // 数组存储元素, 最大值为 MAXSIZE
int length; // 线性表当前元素
} SqList;
数组长度与线性表长度的区别: 数组长度是存放线性表的存储空间长度,线性表长度是线性表中元素的个数。
地址: 存储器中的每个存储单元都有自己编号,这个编号称为地址。
顺序存储结构的插入与删除
获得元素的操作
// 相关操作状态定义
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status; // Status 是函数的类型,其值是函数结果状态码,如 OK 等
/**
获取线性表中第 i 个元素
@param L 线性表 L, 必须已存在
@param i 要获取的编号, 需满足 i ≤ i ≤ ListLength(L)
@param e 对应元素返回
@return 操作结果 OK/ERROR
*/
Status GetSqListElem(SqList L, int i, ElemType *e) {
if (L.length==0 || i<1 || i>L.length) return ERROR;
*e = L.data[i-1];
return OK;
}
插入操作
/**
向线性表的第 i 个位置插入元素
@param L 线性表, 必须存在
@param i 位置编号, 需满足 i ≤ i ≤ ListLength(L)
@param e 要插入的元素
@return 操作结果 OK/ERROR
*/
Status SqListInsert(SqList *L, int i, ElemType e) {
// 1. 顺序线性表已满
if (L->length == MAXSIZE) return ERROR;
// 2. 插入位置i 不在线性表范围内
if (i<1 || i>L->length+1) return ERROR;
// 插入数据位置不在表尾部
if (i <= L->length) {
// 3.将要插入位置后的元素统一后移一位
for (int k=L->length-1; k>=i-1; k--) {
L->data[k+1] = L->data[k];
}
}
// 4.将要插入的元素 填入 第i个位置
L->data[i-1] = e;
// 5. 表长+1
L->length ++;
return OK;
}
删除操作
/**
删除线性表第 i 个位置的元素
@param L 线性表, 必须存在
@param i 要删除的位置编号, 需满足 i ≤ i ≤ ListLength(L)
@param e 被删除的元素返回
@return 操作结果 OK/ERROR
*/
Status SqListDelete(SqList *L, int i, ElemType *e) {
// 1. 空表
if (L->length==0) return ERROR;
// 2. 要删除的位置不正确
if (i<1 || i>L->length) return ERROR;
*e = L->data[i-1];
// 3. 若删除的不是表尾, 将删除位置 后继元素 前移
if (i<L->length) {
for (int k=i; k<L->length; k++) {
L->data[k-1] = L->data[k]; // 依次前移
}
}
// 4. 表长-1
L->length --;
return OK;
}
线性表的链式存储结构
线性表链式存储结构的定义
为了表示每个数据元素 ai 与其直接后继元素 ai+1 之间的逻辑关系,对数据元素 ai 来说,出了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息乘坐指针或链。这两部分信息组成数据元素 ai 的存储映像,称为结点(Node)。
n 个节点(ai的存储映像)链接成一个链表,即为线性表 (a1, a2, …, an) 的连式存储结构,因为此链表的每个节点中只包含一个指针域,所以叫做单链表。
链表中第一个节点的存储位置叫做头指针
有时,为了更加方便的对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点
头指针和头结点的异同
线性表链式存储结构代码描述
/**
线性表的单链表的存储结构
结点由存放数据元素的数据域和存放后继结点地址的指针域组成
*/
typedef struct Node {
ElemType data; // 数据信息
struct Node *next; // 指向信息/单线联系
} Node;
// 定义 LinkList
typedef struct Node *LinkList;
单链表的读取
/**
获取单链表第i 个位置的元素
@param L 单链表, 必须存在
@param i 要获取元素的位置标号 1 ≤ i ≤ ListLength(L)
@param e 返回元素
@return 操作是否成功 OK/ERROR
*/
Status GetLinkListElem(LinkList L, int i, ElemType *e) {
LinkList p = L->next;
int j = 1;
while (p && j<i)
{
p = p->next; // 后继
++j;
}
if (!p || j > i) {
return ERROR;
}
*e = p->data;
return OK;
}
单链表的插入与删除
单链表的插入
/**
向单链表第 i 个位置插入元素
@param L 单链表, 必须存在
@param i 要插入的位置标号, 1 ≤ i ≤ ListLength(L)
@param e 要插入的元素
@return 操作结果 OK/ERROR
*/
Status LinkListInsert(LinkList *L, int i, ElemType e) {
LinkList p = *L;
int j = 1;
while (p && j<i) {
p = p->next;
++j;
}
// 第 i 个元素不存在
if (!p || j >i) return ERROR;
// 生成一个新节点
LinkList s = (LinkList)malloc(sizeof(Node));
// 插入元素
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}
单链表的删除
/**
移除单链表的第 i 个位置的元素
@param L 单链表,必须存在
@param i 要移除元素的位置标号, 1 ≤ i ≤ ListLength(L)
@param e 要删除的元素返回
@return 操作结果 OK/ERROR
*/
Status LinkListDelete(LinkList *L, int i, ElemType *e) {
LinkList p = *L;
int j = 1;
while (p && j < i) {
p = p->next;
++j;
}
// 第 i 个节点不存在
if (!p->next || j > i) return ERROR;
LinkList q = p->next;
p->next = q->next;
*e = q->data;
free(q);
return OK;
}
单链表的整表创建
头插法
/**
随机产生 n 个元素的值, 建立带表头节点的单链线性表 L(头插法)
@param L 创建的线性表 L 返回
@param n 表元素个数
@return 操作结果 OK/ERROR
*/
Status CreateLinkListHead(LinkList *L, int n) {
srand((unsigned int)time(0));
*L = (LinkList)malloc(sizeof(Node));
(*L) -> next = NULL;
for (int i=0; i<n; i++) {
LinkList p = (LinkList)malloc(sizeof(Node));
p->data = rand() % 100 + 1;
p->next = (*L)->next;
(*L)->next = p;
}
return OK;
}
尾插法
/**
随机产生 n 个元素的值, 建立带表头节点的单链线性表 L(尾插法)
@param L 创建的线性表 L 返回
@param n 表元素个数
@return 操作结果 OK/ERROR
*/
Status CreateLinkListTail(LinkList *L, int n) {
srand((unsigned int)time(0));
(*L) = (LinkList)malloc(sizeof(Node));
LinkList r = *L;
for (int i=0; i<n; i++) {
LinkList p = (Node *)malloc(sizeof(Node));
p->data = rand()%100+1;
r->next = p;
r = p;
}
r->next = NULL;
return OK;
}
单链表的整表删除
/**
清空单链表
@param L 单链表, 必须存在
@return 操作结果 OK/ERROR
*/
Status ClearLinkList(LinkList *L) {
LinkList p = (*L)->next;
while (p) {
LinkList q = p->next;
free(p);
p=q;
}
(*L)->next = NULL;
return OK;
}
单链表结构与顺序存储结构优缺点
静态链表
…用数组描述的链表叫静态链表(游标实现法)
静态链表的定义
#define MAXSIZE_FOR_STATICLINKLIST 1000
typedef struct {
ElemType data;
int cur;
} Component, StaticLinkList[MAXSIZE_FOR_STATICLINKLIST];
静态链表的初始化
/**
初始化一个静态链表
@param space 静态链表
@return 初始化结果
*/
Status InitStaticLinkList(StaticLinkList space) {
int i;
for (i=0; i<MAXSIZE_FOR_STATICLINKLIST-1; i++) {
space[i].cur = i+1;
space[i].data = 0;
}
space[MAXSIZE_FOR_STATICLINKLIST-1].cur=0;
return OK;
}
静态链表模拟动态链表的内存分配和释放
/**
模拟动态链表存储空间的分配
@param space 静态链表
@return 若备用空间链表非空, 则返回分配的节点下标, 否则返回0
*/
int Malloc_SLL(StaticLinkList space) {
// 数组第0位,始终记录静态链表下一个可用位置
int i = space[0].cur;
if (space[0].cur) {
space[0].cur = space[i].cur;
}
return i;
}
/**
模拟动态l链表存储空间的释放
@param space 静态链表
@param k 要释放的位置
*/
void Free_SLL(StaticLinkList space, int k) {
space[k].cur = space[0].cur;
space[0].cur = k;
}
静态链表的插入
/**
静态链表的插入实现
@param space 静态链表
@param i 要插入的位置
@param e 要插入的内容
@return 插入结果
*/
Status StaticLinkListInsert(StaticLinkList space, int i, ElemType e) {
int j, k, l;
k = MAXSIZE_FOR_STATICLINKLIST-1;
if (i<1 || i>StaticLinkListLength(space)+1) return ERROR;
j = Malloc_SLL(space);
if (!j) return ERROR;
space[j].data = e;
for (l=1; l<i; l++) {
k = space[k].cur;
}
space[j].cur = space[k].cur;
space[k].cur = j;
return OK;
}
静态链表的删除
/**
静态链表的删除实现
@param space 静态链表
@param i 要删除的元素编号
@return 删除结果
*/
Status StaticLinkListDelete(StaticLinkList space, int i) {
int j, k;
if (i<1 || i> StaticLinkListLength(space)) return ERROR;
k = MAXSIZE_FOR_STATICLINKLIST-1;
for (j=1; j<i; j++) {
k = space[k].cur;
}
j = space[k].cur; // space[k] 为要删除元素的前一个
space[k].cur = space[j].cur;
Free_SLL(space, j);
return OK;
}
静态链表的长度计算
/**
获取链表长度
@param space 静态链表
@return 链表长度
*/
int StaticLinkListLength(StaticLinkList space) {
int j=0;
int i = space[MAXSIZE_FOR_STATICLINKLIST-1].cur;
while (i) {
i = space[i].cur;
j++;
}
return j;
}
静态链表的优缺点
链表代码是最考验逻辑思维能力的。因为,链表代码到处都是指针的操作、边界条件的处理,稍有不慎就容易产生 Bug。链表代码写得好坏,可以看出一个人写代码是否够细心,考虑问题是否全面,思维是否缜密。所以,这也是很多面试官喜欢让人手写链表代码的原因。所以,这一节讲到的东西,你一定要自己写代码实现一下,才有效果。
栈 stack

栈–是限定仅在表尾进行插入和删除操作的线性表
人生,就像一个很大的栈演变。出生时赤条条地来到这个世界,慢慢地长大,渐渐地变老,最终还得赤条条地离开世间。
后进先出 LIFO结构(Last In First Out) 弹夹 网页后退功能
栈顶–允许插入和删除的那一端
重要–进栈出栈变化形式–不是等所有元素进栈后再出栈—可以先进栈的元素直接出栈–后面的元素再进栈出栈
抽象数据类型
ADT 栈(stack)
Data
同线性表,元素具有相同的类型,相邻元素具有前驱和后继关系
Operation
InitStack(*S):初始化操作,建立一个空栈S
DestroyStack(*S):若栈存在,则销毁它
ClearStack(*S):将栈清空
StackEmpty(S):若栈为空,返回true,否则返回false
GetTop(S,*e):若栈存在且非空,用e返回S的栈顶元素
Push(*S,e):若栈存在,插入新元素e到栈S中并成为栈顶元素
Pop(*S,*e):删除栈S中栈顶元素,并用e返回其值
StackLength(S):返回栈S的元素个数
endADT
顺序栈–栈的顺序存储结构–栈顶不变–栈顶位置变化—游标卡尺
有一种有趣的两栈共享空间,两端为栈底,两个茶杯口对口
链栈–栈的链式存储结构 不需要头结点
typedef struct StackNode{
SElemType data;
struct StackNode *next;
}StackNode,*LinkStackPtr;
typedef struct LickStack{
LinkStackPtr top;
int count;
}LinkStack;
//说明在声明变量的时候可以直接StackNode stack1,而不是struct StackNode stack1,不写第一个StackNode也可以
//说明此结构体类的结构体指针为LinkStackPtr
如果栈中的元素变化不可预料,时大时小,用链栈
如果在可控范围内的变化,用顺序栈
迭代–常规for循环
递归–调用自己的函数称为递归函数
菲波那切数列兔子问题–前面相邻两项之和,一年后144只兔子
栈的应用:
1. 逆波兰表示法: 定义后缀表达式,计算四则运算 9+(3-1)*3+10/2 --> 9 3 1-3*+10 2/+
2. 后缀表达式运算规则:
从左到右遍历表达式的每个数字和符号,遇到是数字就进栈,遇到是符号,
就将处于栈顶两个数字出栈,进行运算,运算后的结果再进栈,一直到获得结果
3. 中缀表达式转后缀表达式规则:
从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;
若是符号,则判断其与栈顶符号的优先级,是右符号或优先级低于栈顶符号(*/优先+-),
则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止
队列 queue
参考2
队列–是只允许在一端进行插入操作,而在另一端进行删除操作的线性表
是一种先进先出的线性表(First In First Out)简称FIFO 线程池等有限资源池 阻塞队列和并发队列
允许插入的一端称为队尾,允许删除的一端称为队头
ADT 队列(Queue)
Data
同线性表.元素具有相同的类型,相邻元素具有前驱和后继关系
Operation
InitQueue(*Q):初始化操作,建立一个空队列Q
DestroyQueue(*Q):若队列Q存在,则销毁它
ClearQueue(*Q):将队列Q清空
QueueEmpty(Q):若队列Q为空,返回true,否则返回false
GetHead(Q,*e):若队列Q存在且非空,用e返回队列Q的队头元素
EnQueue(*Q,e):若队列Q存在,插入新元素e到队列Q中并成为队尾元素
DeQueue(*Q,*e):删除队列Q中队头元素,并用e返回其值
QueueLength(Q)返回队列Q的元素个数
endADT
循环队列的顺序存储结构
typedef int QElemType;
typedef struct{
QElemType data[MAXSIZE];
int front; //头指针
int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出,简称为链队列
串–专门存储字符的字符数组字符序列?
串–是由零个或多个字符组成的有限序列,又名字符串
空格串: 只包含空格的串
子串: 串中任意个数的连续字符组成的子序列
主串: 包含子串的串
ADT 串(string)
Data
串中元素仅由一个字符组成,相邻元素具有前驱和后继关系
Operation
StrAssign(T,*chars) 生成一个其值等于字符串常量chars的串T
StrCopy(T,S) 串S存在,由串S复制得到串T
ClearString(S) 串S存在,将串清空
StringEmpty(S) 若串S为空,返回true,否则返回false
StrLength(S) 返回串S的元素个数,即串的长度
StrCompare(S,T) 若S>T,返回值大于0,若S=T,返回0,若S<T,返回值<0
Concat(T,S1,S2) 用T返回由S1和S2联接而成的新串
SubString(Sub,S,index,len) 串S存在,1<=index<=StrLength(S),且0<=index<=StrLength(S)-index+1,用Sub返回串S的第index个字符起长度为len的子串
Index(S,T,index) 串S和T存在,T是非空串,1<=index<=StrLength(S),若主串S中存在串T值相同的子串,则返回它在主串S中第index个字符之后第一次出现的位置,否则返回0
Replace(S,T,V) 串S,T,V存在,T是非空串.用V替换主串S中出现的所有与T相等的不重叠的子串
StrInsert(S,index,T) 串S和T存在,1<=index<=StrLength(S)+1,在串S的第index个字符之前插入串T
StrDelete(S,index,len) 串S存在,1<=index<=StrLength(S)-len+1,从串S中删除第index个字符起长度为len的子串
endADT
朴素模式匹配算法: 子串的定位操作 挨个遍历
KMP模式匹配算法:大大避免重复遍历的情况 克努特-莫里斯-普拉特算法 KMP算法
把T串各个位置的j值得变化定义为一个数组next,next的长度就是T串的长度
next[j] = 0 (当j=1时)
= k ("P1...P(k-1)" = "P(j-k+1)...P(j-1)")
= 1 (其他情况)
j 123456
T abcdex
next[j] 011111
j 123456
T abcabx
next[j] 011123
j 123456789
T ababaaaba
next[j] 011234223
优化KMP模式匹配算法:
在计算next值时,判断T[next]的值与当前位置T[j]的值是否相等,如果相等,
nextval[j]的值就等于nextval[next]的值
j 123456789
T ababaaaba
next[j] 011234223
nextval[j] 010104210
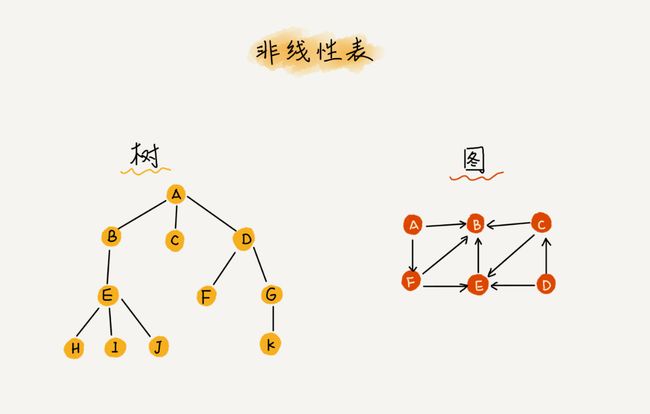
4. 非线性表
线性表
非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
树 tree
参考

树–是n个节点的有限集.n=0时为空树
在任意一棵非空树中:
1>有且仅有一个特定的称为根(root)的结点
2>当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2...Tm,
其中每一个集合本身又是一棵树,并且称为根的子树
结点拥有的子树数称为结点的度,
度为0的结点称为 叶结点 或 终端结点,
度不为0的称为非终端结点或分支结点,
除根结点外,也称为内部结点
结点的层次从根开始定义起,
根为第一层,
树中结点的最大层次称为树的深度或高度
如果将树中结点的各子树看成从左至右有次序的,
不能互换的,
则称该树为有序树
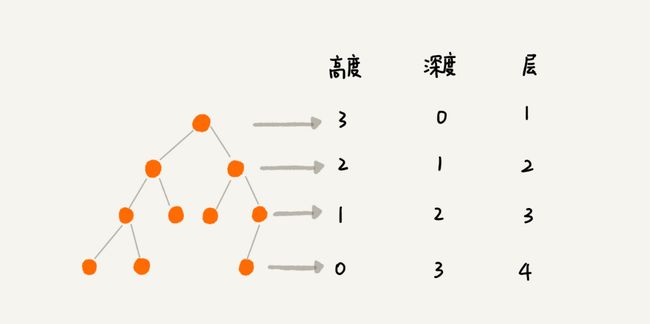
“高度”这个概念,其实就是从下往上度量,比如我们要度量第 10 层楼的高度、第 13 层楼的高度,起点都是地面。所以,树这种数据结构的高度也是一样,从最底层开始计数,并且计数的起点是 0。
“深度”这个概念在生活中是从上往下度量的,比如水中鱼的深度,是从水平面开始度量的。所以,树这种数据结构的深度也是类似的,从根结点开始度量,并且计数起点也是 0。
“层数”跟深度的计算类似,不过,计数起点是 1,也就是说根节点的位于第 1 层。
抽象数据类型
ADT 树(tree)
Data
树由一个根结点和若干棵子树构成,树中结点具有相同数据类型及层次关系
Operation
InitTree(*T) 构造空树T
DestroyTree(*T) 销毁树T
CreateTree(*T,definition) 按definition中给出的树的定义来构造树
ClearTree(*T) 若树T存在,则将树T清为空树
TreeDepth(T) 返回T的深度
Root(T) 返回T的根结点
Value(T,cur_e) cur_e是树T中一个结点,返回此结点的值
Assign(T,cur_e,value) 给树T中结点cur_e赋值为value
Parent(T,cur_e) 若cur_e是树T的非根结点,则返回它的双亲,否则返回空
LeftChild(T,cur_e) 若cur_e是树T的非根结点,则返回它的最左孩子,否则返回空
RightSibling(T,cur_e) 若cur_e有右兄弟,则返回它的右兄弟,否则返回空
InsertChild(*T,*p,i,c) 其中p指向树T的某个结点,i为所指结点p的度加上1,
非空树c与T不相交,操作结果为插入c为树T中p指结点的第i棵子树
DeleteChild(*T,*p,i) 其中p指向树T的某个结点,i为所指结点p的度,
操作结果为删除T中所指节点的第i棵子树
endADT
树的存储结构:
1 双亲表示法:
#define MAX_TREE_SIZE 100
typedef int TElemType; //树结点的数据类型
typedef struct PTNode{ //结点结构
TElemType data; //结点数据
int parent; //双亲位置
}PTNode;
typedef struct{ //树结构
PTNode nodes[MAX_TREE_SIZE]; //结点数组
int r,n; //根的位置和结点数
}PTree;
可以扩展域,增加双亲域,长子域,兄弟域
2 孩子表示法:
多重链表,每个结点有多个指针域,每个指针指向一棵子树的根节点
2.1 每个结点指针域的个数等于树的度 牺牲空间
2.2 每个结点指针域的个数等于该结点的度 牺牲时间
2.3 每个结点的孩子结点排列起来,以单链表作存储结构,
则n个结点有n个孩子链表,然后n个头指针又组成一个线性表,
顺序存储结构,存放进一个一维数组中
#define MAX_TREE_SIZE 100
typedef struct CTNode{ //孩子结点
int child;
struct CTNode *next;
}*ChildPtr;
typedef struct{ //表头结构
TElemType data;
ChildPtr firstchild;
}CTBox;
typedef struct{ //树结构
CTBox nodes[MAX_TREE_SIZE]; //结点数组
int r,n; //根的位置和结点数
}CTree;
3.孩子兄弟表示法
typedef struct CSNode{
TElemType data;
struct CSNode *firstChild,*rightSib;
}CSNode,*CSTree;

二叉树–
参考
是n(n>=0)个结点的有限集合,
该集合或者为空集(称为空二叉树),
或者由一个根结点和两棵互不相交的,
分别称为根结点的左子树和右子树的二叉树组成
每个结点最多有两棵子树,左子树和右子树是有顺序的,
即使只有一棵子树,也要区分左还是右,且次序不能颠倒
线性表结构可以理解为是树的一种极其特殊的表现形式
左斜树,右斜树,满二叉树,完全二叉树(按层序顺序编号)
二叉树性质:
1.在二叉树的第i层上至多有2^(i-1)个结点
2.深度为k的二叉树至多有2^k -1个结点
3.对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0 = n2 + 1
4.具有n个结点的完全二叉树的深度为[log2^n]+1
5.寻找双亲为i/2等
二叉树的顺序存储结构
适用于完全二叉树,按顺序存入数组中 ABCDEFGHI
二叉链表
二叉树每个结点最多有两个孩子,即一个数据域和两个指针域
typedef struct BiTNode{ //结点结构
TElemType data; //结点数据
struct BiTNode *lChild,*rChild; //左右孩子指针
}BiTNode,*BiTree;
二叉树的遍历,是指从根结点出发,
按照某种次序依次访问二叉树中所有结点,
使得每个结点被访问一次且仅被访问一次
1>前序遍历
先访问根节点,然后前序遍历左子树,再前序遍历右子树 ABDGHCEIF
void PreOrderTraverse(BiTree T){
if(T==NULL){
return;
}
printf("%c",T->data);
PreOrderTraverse(T->lCHild);//先遍历左子树
PreOrderTraverse(T->rChild);//然后遍历右子树
}
2>中序遍历
从根结点开始,中序遍历根结点的左子树,然后访问根结点,最后中序遍历右子树 GDHBAEICF
void PreOrderTraverse(BiTree T){
if(T==NULL){
return;
}
PreOrderTraverse(T->lCHild);//先遍历左子树
printf("%c",T->data);
PreOrderTraverse(T->rChild);//然后遍历右子树
}
3>后序遍历
从左到右先叶子后结点遍历左右子树,最后访问根结点 GHDBIEFCA
void PreOrderTraverse(BiTree T){
if(T==NULL){
return;
}
PreOrderTraverse(T->lCHild);//先遍历左子树
PreOrderTraverse(T->rChild);//然后遍历右子树
printf("%c",T->data);
}
4>层序遍历
从根结点开始访问,从上而下逐层遍历,在同一层中,从左到右对结点逐个访问 ABCDEFGHI
建立二叉树:
将二叉树中每个结点的空指针引出一个虚结点,其值为"#",称为扩展二叉树 AB#D##C##
线索二叉树:
把空余的指针域指向前驱后继元素,指向前驱和后继的指针称为线索,
加上线索的二叉链表称为线索链表,相应的二叉树就称为线索二叉树
并且除了两个左右指针域,再增加两个标识BOOL值,lTag与rTag,lTag为0时指向左孩子,
为1时指向前驱,rTag为0时指向右孩子,为1时指向后继
typedef enum(Link,Thread) PointerTag; //Link==0表示指向左右孩子指针 Thread==1表示指向前驱或后继的线索
typedef struct BiTNode{ //结点结构
TElemType data; //结点数据
struct BiTNode *lChild,*rChild; //左右孩子指针
PointerTag lTag; //左标识
PointerTag rTag; //右标识
}BiTNode,*BiTree;
树转换为二叉树:
1.加线.在所有兄弟结点之间加一条连线
2.去线.每个结点只保留与第一个孩子结点的连线,删除它与其他孩子结点之间的连线
3.第一个孩子是二叉树结点的左孩子,兄弟转换过来的孩子是结点的右孩子
森林转换为二叉树:
1.把每个树转换为二叉树
2.把后一棵二叉树的根结点作为前一棵二叉树的根结点的右孩子
二叉树转换为树:
1.加线.将子级与孙子级的右孩子结点都作为此结点的孩子连接
2.去线.删除所有结点与其右孩子结点的连线
二叉树转换为森林:
1.把所有右孩子分离出来
2.把分离出来的二叉树转换为树
森林的前序遍历和二叉树的前序遍历结果相同,森林的后序遍历和二叉树的中序遍历结果相同
赫夫曼树
是压缩文件时用的最基本的压缩编码方法
树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称为路径长度
结点的带权路径长度为从该结点到树根之间的路径长度与结点上权(值比例)的乘积
带权路径长度WPL最小的二叉树称作赫夫曼树.最优二叉树.
构造方法:
1.把各结点按照权值从小到大排列
2.取最小权值的两个结点作为新结点N1的两个子结点,新结点N1的权值为两个叶子权值得和
3.将N1替换两个结点重新排列
4.重复以上三步
传递时,构造好赫夫曼树,双方约定好赫夫曼编码规则,按照路径寻找数据
一般规定赫夫曼树的左分支代表0,右分支代表1,从根结点到叶子结点经过的路径分支组成的0和1的序列便为该结点对应字符的编码,这就是赫夫曼编码
图 社交网络 如何存储微博、微信等这些社交网络的好友关系?
参考
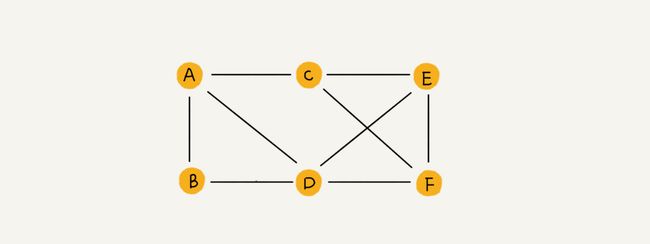
是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),
其中,G表示一个图,V是图G中顶点的集合,E是图G中边集合
顶点(元素)之间的边没有方向,则称这条边为无向边(),全是无向边的图称为无向图
G(V,{E}) V={A,B,C,D} E={(A,D),(B,A),(C,A),(B,C)}
有方向则为有向边<>,也称为弧,弧头,弧尾,有向图
G(V,{E}) V={A,B,C,D} E={
简单图:无重复边与指向自身的边
稀疏图,稠密图,连通图,子图,
权:与图的边或弧相关的数
网:带权的图
无向完全图:任意两个顶点之间都存在边 n(n-1)/2条边
有向完全图:任意两个顶点之间都存在方向互为相反的两条弧 n(n-1)条边
无向图的度,有向图的入度,出度
ADT 图
Data
顶点的有穷非空集合和边的集合
Operation
CreateGraph(*G,V,VR) 按照顶点集V和边弧VR的定义构造图G
DestroyGraph(*G) 图G存在则销毁
LocateVex(G,u) 若图G中存在顶点u,则返回图中的位置
GetVex(G,v) 返回图G中顶点v的值
PutVex(G,v,value) 将图G中顶点v赋值value
FirstAdjVex(G,*v) 返回顶点v的一个邻接顶点,若顶点在G中无邻接顶点返回空
NextAdjVex(G,v,*w) 返回顶点v相对于顶点w的下一个邻接顶点,若w是v的最后一个邻接点则返回空
InsertVex(*G,v) 在图G中增添新顶点v
DeleteVex(*G,v) 删除图G中顶点v及其相关的弧
InsertArc(*G,v,w) 在图G中增添弧<v,w>,若G是无向图,还需添加对称弧<w,v>
DeleteArc(*G,v,w) 在图G中删除弧<v,w>,若G是无向图,还需删除对称弧<w,v>
DFSTraverse(G) 对图G中进行深度优先遍历,在遍历过程对每个顶点调用
HFSTraverse(G) 对图G中进行广度优先遍历,在遍历过程对每个顶点调用
endADT
存储方式
1.邻接矩阵
用两个数组,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息
无向图的边数组是一个对称矩阵
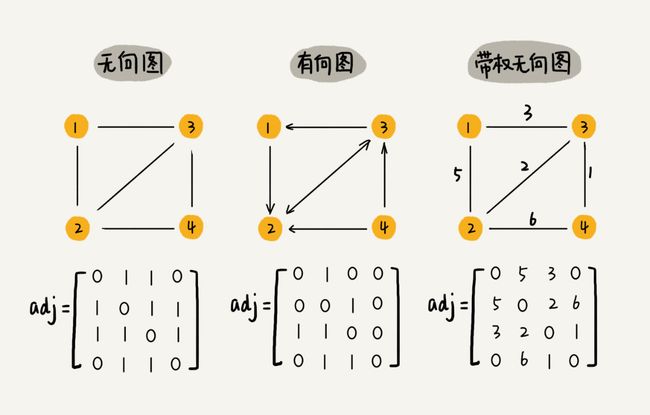
2.邻接表—链表数组–
针对有向图,用数组与链表结合,一个一维数组存储图中顶点信息,每个顶点的所有邻接点构成一个线性表(入度)
逆邻接表(出度)

3.十字链表
把邻接表和逆邻接表整合在了一起
4.邻接多重表
针对无向图,根据十字链表设计
5.边集数组
由两个一维数组构成,一个存储顶点的信息,另一个存储边的信息,这个边数组每个数据元素包括起点下标,终点下标,权
最短路径
深度和广度优先搜索:如何找出社交网络中的三度好友关系?
还有 A*、D*、IDA* 等启发式图上搜索算法。
// java
public class Graph { // 无向图
private int v; // 顶点的个数
private LinkedList<Integer> adj[]; // 邻接表 链表数组
public Graph(int v) {
this.v = v;
adj = new LinkedList[v]; // 链表数组
for (int i=0; i<v; ++i) {
adj[i] = new LinkedList<>();//单个链表
}
}
public void addEdge(int s, int t) { // 无向图一条边存两次
adj[s].add(t);
adj[t].add(s);
}
}
1.深度优先遍历 DFS
广度优先搜索(Breadth-First-Search),我们平常都把简称为 BFS。直观地讲,它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。
// 其中 s 表示起始顶点,t 表示终止顶点。我们搜索一条从 s 到 t 的路径。
// 实际上,这样求得的路径就是从 s 到 t 的最短路径。
public void bfs(int s, int t) {
if (s == t) return;
boolean[] visited = new boolean[v];
visited[s]=true;
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
while (queue.size() != 0) {
int w = queue.poll();
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
if (q == t) {
print(prev, s, t);
return;
}
visited[q] = true;
queue.add(q);
}
}
}
}
private void print(int[] prev, int s, int t) { // 递归打印 s->t 的路径
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
visited是用来记录已经被访问的顶点,用来避免顶点被重复访问。如果顶点 q 被访问,那相应的 visited[q] 会被设置为 true。
queue是一个队列,用来存储已经被访问、但相连的顶点还没有被访问的顶点。因为广度优先搜索是逐层访问的,也就是说,我们只有把第 k 层的顶点都访问完成之后,才能访问第 k+1 层的顶点。当我们访问到第 k 层的顶点的时候,我们需要把第 k 层的顶点记录下来,稍后才能通过第 k 层的顶点来找第 k+1 层的顶点。所以,我们用这个队列来实现记录的功能。
prev用来记录搜索路径。当我们从顶点 s 开始,广度优先搜索到顶点 t 后,prev 数组中存储的就是搜索的路径。不过,这个路径是反向存储的。prev[w] 存储的是,顶点 w 是从哪个前驱顶点遍历过来的。比如,我们通过顶点 2 的邻接表访问到顶点 3,那 prev[3] 就等于 2。为了正向打印出路径,我们需要递归地来打印,你可以看下 print() 函数的实现方式。
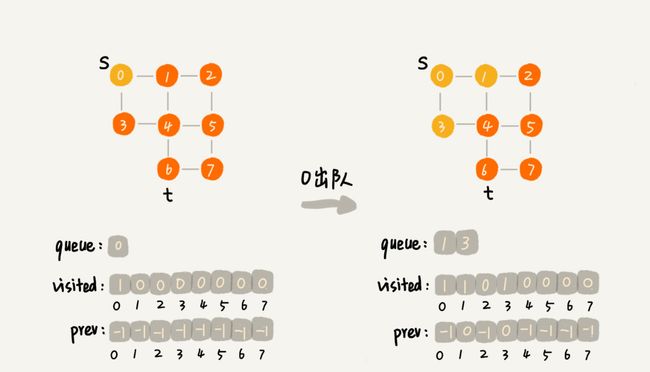
2.广度优先遍历 BFS
深度优先搜索(Depth-First-Search),简称 DFS。最直观的例子就是“走迷宫”。
假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是一种深度优先搜索策略。
走迷宫的例子很容易能看懂,我们现在再来看下,如何在图中应用深度优先搜索,来找某个顶点到另一个顶点的路径。
你可以看我画的这幅图。搜索的起始顶点是 s,终止顶点是 t,我们希望在图中寻找一条从顶点 s 到顶点 t 的路径。如果映射到迷宫那个例子,s 就是你起始所在的位置,t 就是出口。
我用深度递归算法,把整个搜索的路径标记出来了。这里面实线箭头表示遍历,虚线箭头表示回退。从图中我们可以看出,深度优先搜索找出来的路径,并不是顶点 s 到顶点 t 的最短路径。
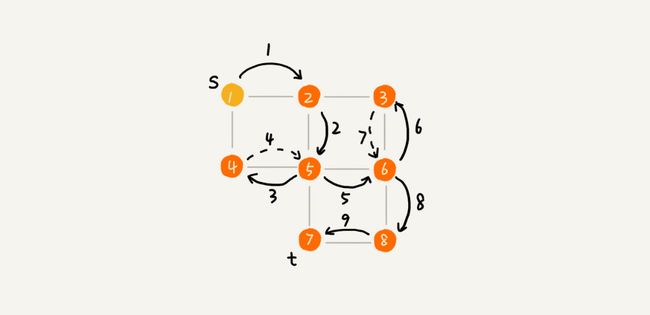
实际上,深度优先搜索用的是一种比较著名的算法思想,回溯思想。这种思想解决问题的过程,非常适合用递归来实现。
我们发现,深度优先搜索代码实现也用到了 prev、visited 变量以及 print() 函数,它们跟广度优先搜索代码实现里的作用是一样的。不过,深度优先搜索代码实现里,有个比较特殊的变量 found,它的作用是,当我们已经找到终止顶点 t 之后,我们就不再递归地继续查找了。
boolean found = false; // 全局变量或者类成员变量
public void dfs(int s, int t) {
found = false;
boolean[] visited = new boolean[v];
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
recurDfs(s, t, visited, prev);
print(prev, s, t);
}
private void recurDfs(int w, int t, boolean[] visited, int[] prev) {
if (found == true) return;
visited[w] = true;
if (w == t) {
found = true;
return;
}
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
recurDfs(q, t, visited, prev);
}
}
}
广度优先搜索,通俗的理解就是,地毯式层层推进,从起始顶点开始,依次往外遍历。
广度优先搜索需要借助队列来实现,遍历得到的路径就是,起始顶点到终止顶点的最短路径。
深度优先搜索用的是回溯思想,非常适合用递归实现。换种说法,深度优先搜索是借助栈来实现的。
在执行效率方面,深度优先和广度优先搜索的时间复杂度都是 O(E),空间复杂度是 O(V)。
深度和广度搜索各有优缺点,就像人生在追求卓越时,着重深度还是广度是很难说得清楚的。
一个连通图的生成树是一个极小的连通子图,它含有图中全部的顶点,但只有足以构成一棵树的n-1条边.
最小生成树–构造连通网的最小代价生成树
普里姆算法
假设N=(P,{E})是连通网,TE是N上最小生成树中边的集合.算法从U={u0}(u0属于V),TE={}开始.
在所有u属于U,v属于V-U的边(u,v)属于E中,找出一条代价最小的边(u0,v0)并入集合TE,同时v0并入U,直至U=V为止.此时TE中必有n-1条边,则T=(V,{TE})为N的最小生成树.
时间复杂度为O(n²)
针对顶点展开,边数多的情况下更好一些
克鲁斯卡尔算法
假设N=(V,{E})是连通网,则令最小生成树的初始状态为只有n个顶点而无边的非连通图T={V,{}},图中每个顶点自成一个连通分量.在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边选择下一条代价最小的边.直至T中所有的顶点都在同一连通分量上为止
时间复杂度为O(eloge)
针对边来展开,边数少时效率会非常高
最短路径
非网图指的是两顶点之间经过的边数最少的路径,
网图指的是两顶点之间经过的边上权值之和最少的路径
迪杰斯特拉算法
按路径长度递增的次序产生最短路径的算法
时间复杂度为O(n²)
弗洛伊德算法
列出两个矩阵,一个是顶点到顶点的最短路径权值和的矩阵,一个是对应顶点的最小路径的前驱矩阵(初始化为P[i][j]=j存储路径)
通过修改初始矩阵的值,最终得到可以找出最短路径的矩阵
时间复杂度为O(n³)
拓扑排序
针对表示工程的有向图,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,称为AOV网
设G=(V,E)是一个具有n个顶点的有向图,V中的顶点序列v1,v2…vn,满足若从顶点vi到vj有一条路径,顶点vi必在vj之前,该顶点序列为一个拓扑序列
拓扑排序,对有向图构造拓扑序列的过程,解决一个工程能否顺序进行的问题
从AOV网中选择入度为0的顶点入栈,选择栈顶的顶点输出,然后删去此顶点,并删除此顶点为尾的弧,出现了入度为0的顶点就继续入栈,直到输出全部顶点或者AOV网中不存在入度为0的顶点,这个顺序就是拓扑排序方案
关键路径
在一个表示工程的带权有向图中,用顶点表示事件,用有向边表示活动,用边上的权值表示活动的持续时间,称为AOE网
其实就是从起点到终点找最长路径
查找
静态查找表:只做查找操作的查找表
动态查找表:在查找过程中有增删操作的
顺序查找:从第一个查找到最后一个,直到查找到为止
有序表查找
- 折半查找:
参考
二分查找,线性表中的数据必须是有序的,采用顺序存储.取中间数据作为比较对象,若小于中间数据,再左半区继续查找,若大于中间数据,在右半区继续查找.
查找思想有点类似分治思想。
即每次都通过跟区间中的中间元素对比,将待查找的区间缩小为一半,直到找到要查找的元素,或者区间被缩小为 0。但是二分查找的代码实现比较容易写错。你需要着重掌握它的三个容易出错的地方:循环退出条件、mid 的取值,low 和 high 的更新。
下标mid = low + 1/2 * (high-low)
凡是用二分查找能解决的,绝大部分我们更倾向于用散列表或者二叉查找树。
即便是二分查找在内存使用上更节省,但是毕竟内存如此紧缺的情况并不多。
- 插值查找:
根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法
mid = (key-a[low]) / (a[high]-a[low]) * (high-low)
表长较大,关键字分布较均匀的表,平均性能比折半查找好得多
- 斐波那契查找:
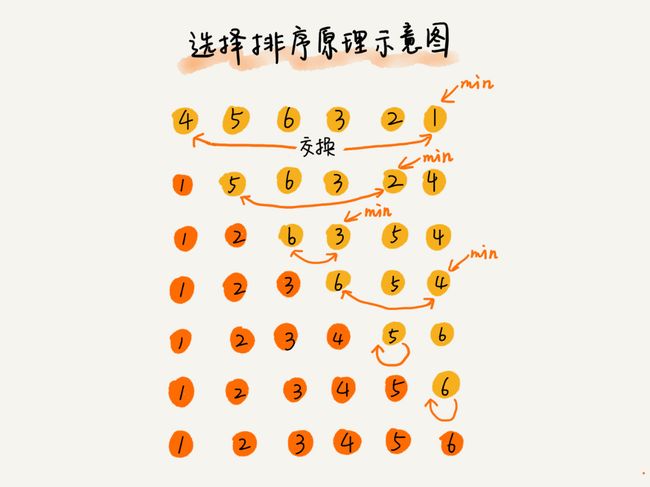
根据要查找表的长度n处于斐波那契数列F={0,1,1,2,3,5,8,13,21…}中位置, key key>a[mid]时,新范围是mid+1到high,个数为F[k-2]-1个 mid = low + F[k-1] - 1 索引: 线性索引: 稠密索引: 分块索引: 倒排索引: 二叉排序树: 平衡二叉树 AVL树: 多路查找树 B树: 2-3树 3阶B树: 2-3-4树 4阶B树: B树: B+树: 散列表(哈希表)查找: 参考 设计哈希表: 排序算法太多了,有很多可能你连名字都没听说过,比如猴子排序、睡眠排序、面条排序等。 最经典的、最常用的:冒泡排序、插入排序、选择排序、归并排序、快速排序、计数排序、基数排序、桶排序。 插入排序和冒泡排序的时间复杂度相同,都是 O(n2),在实际的软件开发里,为什么我们更倾向于使用插入排序算法而不是冒泡排序算法呢? 冒泡排序: 插入排序 选择排序 归并排序 快速排序 归并排序 & 快速排序
计算出k值(n=10,F[6]加快查找速度设计的一种数据结构,把一个关键字与它对应的数据相关联的过程
分为线性索引,树形索引,多级索引
索引表,将索引项集合组织为线性结构
分为稠密索引,分块索引,倒排索引
在线性索引中将数据集中的每个记录对应一个索引项
索引表索引项是按照关键码有序的排列
索引项有序,在查找关键字时,可以使用有序查找算法
对数据进行分段,每个分块有序,每一个块建立一个索引项,减少索引项的个数,块内无序,块间有序
一个分块索引表分为三部分,最大key值,块长,块首指针
记录号表存储具有相同次关键字的所有记录的记录号
又称二叉查找树,左子树的值<根结点的值<右子树的值
中序查找时,就如同顺序查找了
一种二叉排序树,每一个节点的左子树和右子树的 高度差 至多为1
看起来是对称的,可以提供比较高效的查找效率
每个结点的孩子数可以多于两个,每个结点处可以存储多个元素
对数据的处理不断从硬盘等存储设备中调入或调出内存页面
每个结点都有两个孩子或三个孩子
一个2结点包含一个元素和两个孩子
一个3结点包含一大一小两个元素和三个孩子
一个4结点包含小中大三个元素和四个孩子
平衡的多路查找树,2-3树和2-3-4树都是B树的特例,结点最大的孩子数目称为B树的阶
为内外存的数据交互准备的
调整B树结点的元素与硬盘存储页面大小相匹配,把根结点持久地保留在内存中,
在这棵树上,寻找某一个关键字至多需要两次硬盘的读取
由于B树每个结点的元素比二叉树多得多,减少了必须访问结点和数据块的数量,从而提高了性能
出现在分支结点中的元素,会在叶子结点中再次列出,每一个结点都会保存一个指向后一叶子结点的指针
应文件系统所需而出
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)
f称为散列函数,哈希函数
关键字对应的记录存储位置称为散列地址
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表
是面向查找的存储结构,散列技术的数据之间不存在什么逻辑关系,只与关键字有关
解决查找与给定值相等的记录
直接定址法,数字分析法,平方取中法,折叠法,除留余数法,随机数法
关键在于解决key冲突
开放地址法,
排序----购物网站商品排序—