推荐算法实战(二)算法分类
一、常用推荐算法分类
分类标准
1. 实时与离线
2. 是否个性化,还是基于统计
3. 基于模型去推荐,随机规则
二、基于人口统计学的推荐与用户画像
1. 原理
若用户 a 与 用户 b 相似,则推荐 a 用户喜欢的物品给用户 b
基于人口统计学的推荐机制是最容易实现的推荐方法,只是简单地根据基本信息发现用户的相关程度
对于没有明确含义的用户信息(登录时间,地域等sangxi)可以通过聚类等手段,给用户打上分类标签
对于特定标签的用户,又可以根据预设的规则(知识)或者模型,推荐出对应的物品
用户信息标签化的过程被称为 用户画像(User Profiling)
用户画像
公司通过收集与分析消费者的社会属性、生活习惯、消费行为等主要信息的数据后,抽象出一个用户的商业全貌作是企业应用大数据技术的基本方式
用户画像为公司提供足够的信息基础,帮助企业快速的找到精确的用户群体
三、基于内容的推荐与特征工程
Content-based Recommendations(CB) 根据内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品
重点是抽取物品的特征值,实现相似计算
例如:电影有导演,评论,用户标签,时长,风格等
相似度计算
相似度计算用向量终点的距离或向量的距离计算即可
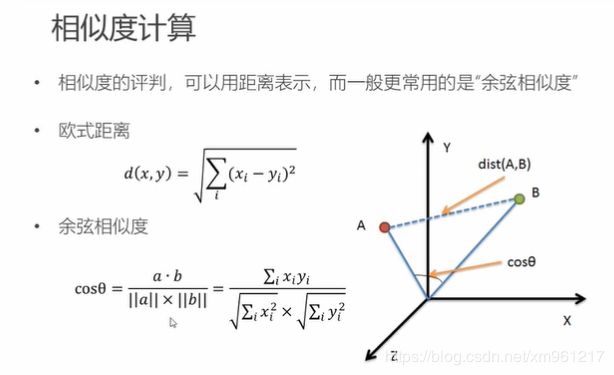
为什么用余弦相似度来作为标准,个人认为是单单用距离无法很好的标签某些向量之间的区别,可能会出现很多重复的属性特征
还有一些专业名词也稍微过一下
专家标签(PGC) 用户自定义标签(UGC) 降维分析数据、提取隐语义标签(LFM)
文本信息提取:分词、语义处理和情感分析(NLP) 潜在语义分析(LSA)
内容推荐的高层次结构
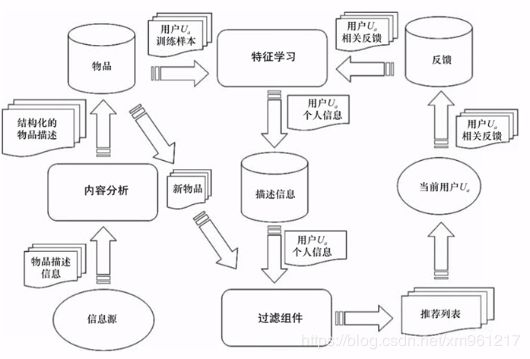
购物推荐系统常用的数据
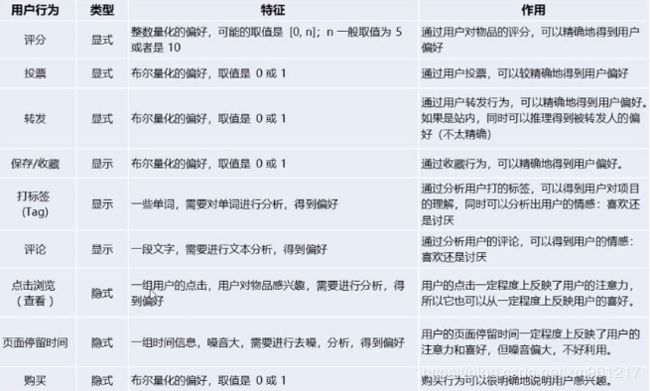
基于 UGC 的推荐
用户用标签来描述物品的看法,所以用户生成标签(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源
一个用户标签行为的数据集一般由一个三元组(用户,物品,标签)的集合表示,其中一条记录(u,i,b)表示用户u给物品 i 打上标签 b
简单地计算方法
① 统计每个用户最常用的标签
② 对于每个标签,统计被打过这个标签次数最多的物品
③ 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门的物品,推荐给他、
④ 所以用户 u 对物品 i 的兴趣公式为
![]()
其中第一个 n 为用户 u 打过标签 b 的次数,第二个是物品 i 被打过标签 b 的次数
单对 NLP 有一定了解的同学应该知道,标签的数量有时可能只是因为这个词太过于常见,才导致经常看见他
在 NLP 里有 TF-IDF 来进行处理,那这里不也可以使用 TF-IDF 的方法来减少通用词汇的影响吗?
TF-IDF
词频-逆文档频率(Term Frequency-Inverse Document Frequency , TF-IDF)是一种用于资讯检索与文本挖掘的常用加权技术
TF-IDF 是用于评估一个词对于包含这个词的文章的重要程度分析,一个词的重要程度会随着在文章中出现的次数增加,但如果在别的文章中也经常出现,那这个词的重要程度就会下降。
TFIDF = TF * IDF
TF
词频(Term Frequency,TF),该词在文章中出现的频率
对词数进行归一化,防止长文章的影响。文章中词数 除以 总词数
IDF
逆向文件频率(Inverse Document Frequency,IDF)
总文档数目除以包含该词语的文档数目,再将得到的商取对数
![]()
TF-IDF 对基于 UGC 推荐的改进
为了避免所有用户的首页都被热门所占领,我们需要对热门物品进行惩罚
借鉴 TF-IDF ,以一个物品的所有标签作为 文章,标签作为 词,从而计算 TF-IDF
但在 TF 计算时,词数除以总词数,但在物品推荐这里,总词数应该没有影响,所以我们可以略过
所以 物品的所有标签 和 标签总数 都可以除去,直接加入对热门标签和热门物品的惩罚项
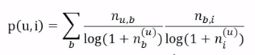
![]()
四、基于协同过滤的推荐
抽空再做笔记