基于3D关节点的人体动作识别综述
文基于3D关节点的人体动作识别综述
原文:2016,Pattern Recognition:
3D skeleton-based human action classification: A survey
摘要
近年来,基于深度序列的人体动作分类的研究越来越多,出现了基于不同数据源:深度图或RGB视频的3D人体关节的人体动作分类的方法以及特征表示方法。
本文着眼于人体动作识别领域的进展及挑战,总结了基于3D骨架的动作分类的技术和方法。本文侧重于数据预处理、公开可用的基准和常用的精度度量等方面。此外,本文根据所采用的特征,对基于3D骨骼的人体动作分类的最新研究进行了分类。
本文旨在为希望从事三维动作分类研究工作的研究人员提供一个起点,并收集面对这一新兴领域面对的主要挑战的见解。
1. 引言
在监控[1-4],人机交互[5],辅助技术[6],手语[7-9],计算行为科学[10,11]和消费者行为分析[12],对人体动作行为的监测、识别和分析都有着广泛的需求,进而激励了从事CV的研究人员针对动作建模、识别进行研究。因此有大量的文献,包括有趣的调查[13-19],人体姿态估计[20-24]和活动/行动分类[25-30]。
正如机器视觉领域常发生的,心理学研究推动了当前人体动作识别的发展。Johansson的移动光斑的运动感知实验[31]是最早引起人们关注的,该实验是在二十世纪七十年代进行的,实验通过2D模型研究3D的人体运动感知。该实验的研究目标是分析典型运动模式的视觉信息,当模式的图形形式已知时,为了达到这些目的,在实验中使用了分布在人体上的几个亮点(见图1)。实验表明,光点的数量及其在人体上的分布可能会影响运动感知。尤其是,越来越多的光点可以减少运动理解中的模糊性。Johansson的研究表明,人类视觉不仅能检测运动方向,还能检测不同类型的肢体运动模式,包括识别活动和不同运动模式的速度。正如文献[31]所描述的那样,“人体运动模式的几何结构是由骨骼的构造决定的。从机械的角度来看,人体的关节是骨骼的终点,且长度恒定。

图1 Four frames of the video (see footnote 1) showing Johansson’s moving light-spots experiment: two persons cross each other
这项研究引发了很多研究人员对人体姿态的估计和动作的识别进行研究[32-34]。特别是,通过一张图像对人体的姿态进行估计[35]。使用部件检测器[36,37]或图形结构(PS)模型[38-40]来模拟身体部位的外观并基于身体部位之间的约束来推断Pose;一般来说,这种约束是为了代表实际的人体关节。
人体姿态估计的主要困难在于人体具有很大的姿态范围,这也是难以模拟或说明的。运动捕捉(Mo-Cap)等技术已被用于收集准确的数据和相应的事实。 由于难以可靠地估计Pose,所以有几种方法尝试使用Pose的整体表示。诸如[27,41,42]等方法已证明在跳过Pose推断步骤并采用与Pose相关的特征来同时进行简单的动作识别是成功的。最新的研究趋势是“野外”的行动认同[43-48]和行动“本土化”[49-53]。
随着技术的快速发展,便宜的深度相机被广泛使用。Shotton等人[56]的开创性工作:根据深度图估计人体的关节位置,刺激了基于关节点的人体动作识别的研究。事实证明,使用深度图是一个简单快速估计人体数据的方法。如[31]首先介绍的那样,计算机视觉社区将骨架定义为人体躯干、头部和四肢位置的示意模型。这样,骨架的相关参数和运动参数可以被用作手势/动作的表示,并且Pose可以通过骨架中的关节的相对位置来定义。图2显示了可能的骨架的图形表示(通过方法[56,57]估计),其中红点表示估计的人体关节。

图2 Graphical representation of skeletal data with 20 and 15 joints. (a) Skeleton of 20 joints (MSRA-3Ddataset [54]) and (b) skeleton of 15 joints (UCF Kinect dataset [55]). (For interpretation of the references to color in this figure caption, the reader is referred to the web version of this paper.)
受益于这些技术的发展,游戏和人机交互等应用蓬勃发展。这些年,针对基于深度图或其他骨架序列的3D关节的动作分类出现了很多[58-60]。这些研究表明,即使可靠的估计了人体的骨架信息,基于3D骨架的动作分类也并非如此简单。从这个意义上说,“使用基于姿态的特征面临的最大挑战之一就是语义相似的动作可能不一定在数值上相似”[61]。此外,运动是不明确的,动作类别之间可以分享运动[62]。3D动作识别中的大部分工作都试图从3D骨骼数据中引入新的身体姿态表示来进行动作识别[55,34,58],目的是捕捉不同时间身体关节之间的相关性。其他作品[63,64]试图挖掘每个类别最有代表性的关节或一组关节。有前途的研究[65,62]涉及人体关节三维轨迹的动力学。在所有这些研究中,各种不同的分类框架已经被应用于分类行为。
与最近的survey[66,67]相比,这些survey侧重于在多个应用领域使用深度相机,或者针对深度图的动作识别的文献进行回顾。在本文中,我们主要关注骨骼的行动分类数据。为此,我们概述了用于获取深度图的技术(参见第2节),并在第3节回顾了用于估计骨骼/身体姿势的现有技术中最常用的方法。第4节致力于介绍基于生物统计差异的数据预处理以及各种处理不同时序长度的分类技术。第5节,我们介绍了一个基于骨架的姿态描述符的动作分类方法。我们区分基于联合的描述符、基于挖掘的联合描述符和基于运动模型的描述符。在基于联合的描述符中,着重于提取关节的相似性的特征。基于挖掘的联合描述符着重于挖掘人体关节的子集。基于动力学的描述符将人体骨架视为一组时序,并调节时序动力学模型的参数来去区分动作。在第6节中,我们简要地描述了多模态方法,对来自RGB传感器或深度图中进一步提取的描述符和惯性传感获取的数据进行融合,进而表示人体的骨骼。在7节中,我们介绍了大多数研究人员在进行基于3D关节进行动作分类时常用的公开可用的基准和验证协议。在第8节中,我们介绍了最常用的数据集的最新性能评估方法。 我们还讨论动作识别中的性能测量和延迟。最后,在第9节中,给出了我们分析的结论,并概述了潜在的未来研究方向。
2. Depth maps and related technologies
距离图像或深度图是在每个像素中存储场景中相应点的到相机的距离的图像。距离图像已被研究和使用了很长时间,特别是在机器人应用[68-70]和场景/对象重建[71-73]。虽然已经设计了几种技术来估计场景的深度图,但是在过去的几年里,深度成像技术已经大大地提高,随着Kinect的发布达到了消费者的价格点[74]。
与传统的传感器相比,深度相机有许多优点,如提供校准的尺度估计,测量的颜色和纹理是不变的,能解决姿势中的轮廓模糊问题,并且简化了背景去除的任务[56]。
我们简要介绍一下用于估算深度图的三种最流行的技术。技术细节超出了这项工作的范围,我们位感兴趣的读者提供了相应的文献:
多目相机包括一套经过校准的相机(至少两个),已经为其估算了一个通用的3D参考系统。深度图是基于立体三角测量的[75]。即使有多个研究让我们在这方面取得了相当大的进步,但是多目相机估计的深度仍然是不可靠的,特别是在强度/色彩均匀的场景中;
3D飞行时间(ToF)摄像机用调制光源照亮场景,观察反射光。一些照相机测量照亮场景的光脉冲的飞行时间,这意味着反射光经历的延迟。 经过的时间,即反射光的延迟或者简单的“飞行时间”,与场景中物体的距离相关。其他相机测量发射和接收信号之间的相位差异。 在空间分辨率较低的情况下,由于辐射,几何和光照变化,运动模糊,背景光以及多次反射所导致的误差,估计的距离可能是不可靠的[78]。Kinect传感器(版本2)属于这种类型的相机;
结构光3D扫描仪将红外结构光图案投射到现场。当将图案投影到三维形状的表面上时,观察到的图案几何扭曲[79]。通过比较预期的投影模式(如果场景中没有物体)和变形的观察模式,可以恢复表面形状的精确几何重建。可以将各种图案投射到场景上,例如光条纹或任意的条纹。深度估计可能是不可靠的,特别是在反射或透明表面的情况下。Kinect传感器(版本1)属于这种类型的相机。
3.Body pose estimation
在本节中,我们将简要回顾从各种数据(强度或深度图)估算骨架的最常用技术,然后介绍一些可用于数据集的现成解决方案。
3.1 Methods for skeleton estimation
文献[35,80,21,81]尝试从RGB来估计人体部位,文献[56,82]从深度图来估计人体部位。我们将注意力集中在获取人体骨架的方法和技术上。
动作捕捉:动作捕捉(Mo-Cap)传感器允许记录人体的动作。有几种Mo-Cap技术。光学系统使用立体视觉来对对象的3D位置进行三角测量。数据采集利用附加在物体上的特殊标记。有些系统使用逆向反射材料。摄像机的阈值可以调整,以忽略皮肤和墙等,只有具有标记的物体会发光。其他系统利用一个或多个LED通过软件来它们识别它们的相对位置 [13]。这种技术主要是为了收集强度数据,进行精确处理;
强度数据:从图像和RGB视频的姿态估计仍然是一个开放和非常具有挑战性的问题。 主要困难是由于人类视觉外观的变异性,受试者间的生物特征差异,缺乏深度信息和部分自遮挡[35]。尽管如此,文献中已经提出了非常有趣和有希望的方法。由于姿态估计不是本次调查的主要议题,因此我们给读者推荐我们认为是计算机视觉科学家必备的论文[83-86]。
近年来,最常采用的姿势模型可能是图像结构(PS)[38]。这个模型把整个身体的外表分解成局部的身体部位,每个部位都有自己的空间位置和方位。对身体部位描述为具备强制约束的骨骼一致性表示的身体关节。
这个模型的进一步发展侧重于通过更强的检测器[36,80]或混合模板[21]对部件外观进行建模。其他方法通过在身体部分之间引入进一步的限制来增强模型[86,87]。虽然原始的PS确实使用树模型[38,21],它允许对身体姿态的精确推断,但其他方法采用非树模型。在这些情况下,计算复杂度增加很多,一般采用修剪策略[24,39,88]或近似推理[87,89]。通常使用判别式学习方法,如条件随机场[40]和最大边缘学习[90,21,89]来学习基于部位的模型参数。
深度图:从深度图像中估计骨骼的最有名的方法可能是[56]中的最近的工作,对从Kinect传感器采集的深度图像逐帧进行处理,并推断由20个关节组成的骨架。[56]中提出将单个输入深度图像分割成覆盖整个身体的密集的具有不同概率和标签的身体部位。分割的身体部分被用于估计3D身体关节点,而不需要利用时间序列或者运动学的约束。
简而言之,从输入的单张深度图像,通过分类推断每个像素的身体部位分布。像素分类由深度随机决策森林执行。森林是决策树的集合体,每个决策树都由分裂节点和叶节点组成。每个分割节点基于特征和阈值(即分类器的参数)来划分训练样本。叶节点存储类条件分布(其中类指示正文部分)。为了对深度图像中的像素进行分类,根据存储在分离节点中的特征和阈值的比较结果,将每一棵树向左或向右分支遍历。一旦到达叶节点,像素被分配存储在叶节点中的类-条件分布。估计的分布在森林中的所有树上取平均值。每像素信息汇集在像素中以生成关于3D骨骼关节位置的建议。为此,采用加权高斯内核的均值漂移。
其中最显着的一点是训练数据的大小和组成。大量逼真的合成深度图像以及各种形状和大小的人体图像以及大量的运动捕捉数据库和Kinect传感器获取的深度图像被用来训练像素分类器。所采用的训练集的大尺寸允许避免过度拟合并考虑到不同的人体姿势。
OpenNI库[91]提供了另一种广泛使用的骨架估计方法。该方法[57]通过局部描述符来估计15个身体关节的骨架,所述的局部描述符表示深度图的连通域的空间仓中的统计量。局部描述符提供在围绕连通域的中心点放射状排列的一组仓中的深度连通域的深度边缘计数。通过边缘检测器(例如Canny边缘检测器)从深度图中提取深度边缘。在贴片的每个径向切片中,统计每个容器中被分类为边缘像素的像素的数量,边缘的方向,每个容器中的平均或中值方向,平均值或中值深度值,深度被计算和存储。仓值可以被加权并归一化以补偿仓区域的差异。
然后使用近似最近邻居(ANN)算法将连通域描述符搜索到描述符数据库中。 该数据库存储在人形的已知位置处提取的描述符,并且与身体关节的位置相关联。 因此,在将测试连通域与数据库中的连通域匹配(例如借助于欧几里得距离)之后,可以计算测试深度图中的关节的估计位置。在比较所有的测试片之后,在加权投票过程中使用从匹配的连通域的估计的联合位置的集合来一个接一个地恢复骨架中的关节的位置。该方法还应用归一化和尺度估计来使得骨架重建不受被摄体到相机的距离的影响,并且考虑到生物统计差异。
3.2 Off-the-shelf solutions
术语“被动立体视觉”是指在不同位置使用两个(或更多)校准相机以确定两个图像中的哪些点对应于相同的3D景物点的系统。相反,主动立体视觉是指例如通过将已知图案投影到对象上来控制场景照明的方法。
表1总结了目前可用于数据获取的一些解决方案。这份清单并不详尽,还有许多其他可靠的解决方案。

Table1 Hardware and software technologies for skeletal/depth data collection
表中的第一部分介绍了被动立体视觉技术,而表格的第二部分报告了主动立体视觉系统。对于每个产品,我们都会介绍名称,简短说明和制造商网站的链接。 我们注意到,大多数技术(例如Kinect传感器,英特尔实感3D摄像头和Mo-Cap解决方案)都带有自己的软件开发工具包(SDK)和/或专有软件应用程序,用于记录骨骼数据。
4. Pre-processing of skeletal data
骨骼数据的预处理通常用于处理对象之间的生物测量差异,以及可能由于动作的不同速度和主体间风格变化而持续变化的时间序列。
特别是,考虑到生物统计差异可能需要将每个骨架转换成规范化姿态。这个问题与运动重定向密切相关[92,93],当需要将运动从一个姿态改变到另一个姿态时,这在计算机图形学领域中是个问题。运动重定目标通过满足关于结果姿态的约束(例如关节角度的特定配置[94]或所生成的运动的特定属性[95,96])来生成目标角色的运动参数。在3D动作表示的领域中,这样的技术在将每个骨架序列的运动转换为通用参考姿态时可能是有用的,从而导致对生物统计差异不变的骨架序列。从这个意义上说,在4.1节中应用于文献和回顾的技术与更广泛的运动重定位问题有关。
动作序列长度的变化可能会限制某些分类框架的适用性。例如,广泛使用的SVM分类器要求样本具有相同大小的特征表示。正如4.2节中详细解释的那样,文献中的大部分工作试图从整个序列中提取直方图,或者应用一些金字塔方法,或者采用DTW来将每个序列与参考序列对齐。
4.1 Data normalization and biometric differences
在基于3D骨骼的动作分类中,动作被描述为骨架中关节的3D位置(即3D轨迹)的时间序列的集合。然而,这种表示取决于在每个记录环境中不同的参考坐标系的选择以及生物统计差异。为了解决这些问题,使用各种坐标系变化。像[64]这样的工作,考虑任何两个连接的肢体之间的关节角度,并将动作表示为时间序列的关节角度。在[97]中,通过对齐躯干和肩膀来使人体姿势正常化。在[34]中,数据最初被注册到一个共同的坐标系统中,使关节坐标相互可比。在[98,99]中,通过将髋关节中心(见图2)放置在原点处,所有的三维关节坐标都从世界坐标系转换到以人为中心的坐标系。在[63]中,骨骼根据头部位置对齐。接下来,骨架中的所有其他坐标都由头部长度归一化。在[100]中,3D关节的坐标被标准化,以便在序列中的所有维度上[0,1]范围内。在[101]中,使用5乘1的高斯滤波器(σ= 1)对归一化姿态矢量的每个坐标进行平滑。姿势被归一化以补偿生物统计差异。从训练数据中学习参考骨架。参考骨架中的骨骼肢体的长度被调整为单位标准。测试和训练数据中的所有骨架被转换,以便在保持方向矢量的同时施加与参考骨架中相同的肢体段长度。类似的规范化也适用于[102],其中帧间线性插值也被应用于解决骨架数据中的缺失值。
4.2 Dealing with varying temporal durations
动作分类中的一个主要问题是序列可能有不同的长度。动作序列的长度可能取决于执行动作的速度和风格。一般来说,可能存在影响动作序列的时间翘曲,或者在重复动作的情况下,重复次数不同。
为了解决这个问题,[58,63]等工作采用整体序列的全局特征表示来牺牲一般序列的时间结构信息。最常见的方法是词袋模式(bag-of-word schema),它表示字典中的码字序列。该表示可以包括采用金字塔形方法的时间信息[103,100,102]。
为了说明时间翘曲并确保序列的长度相等,在文献[34]中将序列与标称曲线对齐。在三维关节的轨迹之间采用一些距离的方法,如[104],应用动态时间规整(DTW)和K近邻。在[105]中,使用了一个基于动态规划的弹性距离。在[97]中,序列被重新采样以便获得可比长度的表示。
在[64]中用于获得相同长度的表示的另一种方法是将序列划分为前缀数量的时间片段。然而,在所有的类和序列中找到最适合的段的数量并不是微不足道的。
因此,[64,62]建议将动作序列分成不同数量的时间段,每个时间段都有相同的时间段。具体而言,[62]采用滑动窗口方法,其中时间片段全部部分重叠。滑动窗口方法使得该方法对序列的时间翘曲更稳健。这种表示方式不允许采用标准支持向量机[62],而是采用一套用代表性方法训练的隐马尔可夫模型。另外[101]采用滑动窗口的表示。每个时间窗口的特征表示通过K-NN进行分类。整个序列通过基于针对每个时间窗预测的标签的投票模式来分类。在[102]中,采用了一个池化策略来在几个时间窗口中构建骨架序列的表示,从而将所有序列缩减为具有相同的长度表示。
像[99,65]这样的方法通过假定线性动态系统的所有动作类别的顺序相同并且执行系统识别来计算模型的参数来克服序列长度的问题。
5. Action representation and classification
如图3所示,我们将三维动作表示的方法分为三类:基于关节的联合描述符,基于挖掘的联合描述符和基于动力学的描述符。基于关节的表示方法从骨架中提取特征,以获取人体关节的相关性。基于挖掘的联合描述符通过了解身体部位的参与情况来对行动进行区分。基于动力学的描述符将人体骨架系列视为时间序列的动力学模型。基于联合的描述符可以被分为空间描述符,几何描述符和基于关键姿态的描述符。

图3 Graphical representation of our categorization of the methods for 3D action representation
5.1 Joint-based representation
属于这个类别的方法试图捕获相关的身体关节位置。接下来,我们回顾属于这一类的现有技术的研究,并通过区分三个子类别:空间描述符,几何描述符和基于关键姿态的描述符来组织讨论。第一个子类别包括试图通过测量所有可能的成对距离(在给定时间或跨时间)或其协方差矩阵来关联3D身体关节的研究。 第二类,即几何描述符,包括尝试估计移动骨架所需的几何变换序列的方法,或者表示关节子集的相对几何。在后一类,即基于关键姿态的描述符中,计算一组关键姿态,并且用最接近的关键姿势表示骨架序列。
5.1.1 Spatial descriptors:空间描述符
关联身体关节位置的最简单的尝试可能是考虑3D关节的所有成对距离。这种表示缺乏任何时间信息,可能导致对动作序列的模糊描述。因此,在[55]中,身体姿势是通过连接当前帧中所有可能的关节对之间的距离,当前帧中的关节之间的距离和前一帧中的关节之间的距离,当前帧和中性姿势(通过平均所有动作序列的初始骨架计算)。每个单独的特征值通过Kmeans聚类为5个组中的一个,并用二进制向量代替以表示每个聚类索引。每个动作的典型姿态描述符通过逻辑回归框架内的多实例学习方法被发现。
以类似的方式,[59]采用同一骨架中的关节的三维位置差异(而不是距离),当前帧和前一帧中的三维关节之间以及当前帧和初始帧之间的关节。主成分分析(PCA)被应用于降维以提供被称为Eigenjoints的描述符。朴素贝叶斯最近邻分类器Naive-Bayes-nearest-neighbor用于动作分类。
在[102]中,骨架被解释为其边缘权重是基于成对距离计算的图形。包括更多的边缘以链接时间上连续的骨架的关节。因此,整个骨架序列被表示为时空图。基于谱图小波变换(SGWT)[106]的金字塔表示被用来捕捉关于在不同尺度(在空间和时间上)的关节轨迹的信息。为了处理高维表示,应用PCA,然后进行l2归一化(l2-normalization)。分类由标准的SVM(standard SVM)执行。
捕获骨架中关节之间的关系的另一个尝试是通过其协方差矩阵表示骨架序列。在这个意义上,在[100]中,在一个固定长度的时间窗口中的一系列骨架用一个协方差矩阵表示,该协方差矩阵编码关于该组随机变量的联合概率分布形状的信息。为了考虑3D关节的时间依赖性,采用分层表示:根节点表示整个骨架序列的协方差矩阵,下层表示在长度递减的重叠固定长度时间窗口中的协方差矩阵。描述符的计算可以通过动态编程来完成,而动作分类是通过线性SVM执行的。
我们在这部分还包括通过卷积神经网络来捕捉关节位置之间相关性的方法。在[98]中,HMM被用来模拟一个动作。每个动作都以与[59]中类似的方式表示。这种方法与采用HMM的其他方法之间的主要区别在于,在[98]中,发射概率被包含许多特征层的深度神经网络代替。在[107]中,只有对应于右手,左手和骨盆的关节才被用来提取与动作相关的特征。卷积神经网络分类器由卷积和子采样层交替序列组成,然后是神经网络,用于分类。
5.1.2Geometrical descriptors:几何描述符
这一类的方法试图通过不同身体部位之间的几何关系来表示一个骨架。在[108]中提出的几何特征由一组布尔特征组成,每个布尔特征与一个四联关节相关联。给定一组四点,其中三个被用来确定一个平面;如果第四个点位于平面的前方,则对应于给定四元组的布尔特征采用值1,否则其值为0。这种特征允许表示关节集合之间的几何关系,并且对于空间变化,全局方向骨架的变化和大小。在[108]中,只有31个布尔特征被手动识别并用于基于内容的运动检索。
同样在[109]中,人体关节被认为是四部分的。在这种情况下,四元组中的四个关节中的两个被用来设置其中一个点被用作原点的坐标系,而四元中最远的点被用新坐标系表示为[1,1,1]。所得到的相似变换应用于其余两个形成骨架四边形的关节。骨架然后被表示为一组骨架四边形。对于每个类,高斯混合模型是通过期望最大化来训练的。然后使用模型的参数来提取Fisher分数(Fisher scores)[110]。级联分数用于训练多类线性支持向量机并执行动作分类。
更复杂的是在[34]中引入的表示,其中不同身体部位之间的相对3D几何被明确地估计。给定两个刚体部分,它们的相对几何形状可以通过考虑刚体变换(旋转和平移)来描述,以将一个身体部分与另一个身体部分对齐。这种刚体几何变换在矩阵李群SE(3)[111]中。骨架表示是SE(3)中的一组点,其中每个点表示一对身体部分之间的相对几何变换。一组骨架是李群SE(3)×…×SE(3)中的曲线,它是一个曲线流形。为了分类的目的,将每个动作曲线从SE(3)×…×SE(3)映射到它的李代数,它是该组标识元素的切空间。为了说明动作序列的持续时间和时间翘曲,使用动态时间规整(DTW)来将每个序列与标称曲线对齐。然后通过[112]中提出的傅里叶时间金字塔(FTP)来表示变形曲线,即通过去除高频系数。动作分类是使用FTP和线性一对一SVM分类器来执行的。
诸如[105,113]的方法试图考虑骨架序列之间的几何关系而不是同一骨架中的身体部位。在[105,114]中,每个动作由关节的时空运动轨迹表示。轨迹是开放曲线形状空间的黎曼流形中的曲线,并且使用基于动态编程的弹性距离来比较它们。分类是由黎曼流形上的KNN完成的。
文献[113]中的工作提出了一类积分不变量来描述运动轨迹,并实现了有效和稳健的运动轨迹匹配。该表示通过计算沿运动轨迹的多个尺度上的一类核函数的线积分来计算。积分不变量具有平滑效果,因此不需要预处理运动轨迹就对噪声不敏感。当且仅当存在将一个轨迹映射到另一轨迹的组变换时,两个运动轨迹被认为是等价的。动态时间规整和最近的邻居用于分类目的。
5.1.3 Key-poses based descriptors:关键姿态描述符
这个类别包括学习关键姿势的字典/密码本并用这些关键姿势表示动作序列的方法。
运动词的直方图已被用作[64]中的基线方法,其中连接的三维关节位置(或其相应的特征)通过使用Kmeans聚类成K个不同的姿势(即运动词)。每个动作序列通过对检测到的动作字数进行计数来表示。通过将每个骨架表示分配给其最接近的独特姿态来检测运动单词。得到的直方图然后通过其l1范数标准化(l1-norm)。
基于Hausdorff距离,[115]中详述的方法都将姿势组合成一组聚类。这些簇中的每一个都是由一个代表性元素定义的,这个元素是骨架簇的中间元素。然后通过序列中代表性元素集合的累积频率出现(积分直方图)表示骨架序列。由于积分直方图缺乏关于姿势的时间信息,通过考虑姿势的所有可能的子串,动作被分解为时间排序的子动作。给定两个动作序列,通过找出产生最小分数的最佳子动作分解来比较两个序列。分解通过动态编程找到,每个子动作由相应的积分直方图表示。该方法使用Bhattacharyya距离来比较不同的直方图。
[116]中的方法将身体分为四个空间区域:右臂,右腿,左臂和左腿。每个身体区域由21个维度的特征向量表示,包括身体关节与6个线与面之间的线与线之间的角度。通过标准的Kmeans聚类算法得到身体姿态的字典。训练层次模型以将复杂活动表示为简单动作的混合。
另外,[117]中的方法采用了使用关键姿势来表示动作的想法。具体而言,采用与[118]中提出的类似的骨架数据的描述符以获得对方向变化鲁棒的表示。该表示由对应于头部,肘部和膝部的相对于躯干的关节的球形坐标组成。通过考虑这些身体部分相对于所连接的关节的旋转来代表诸如手和脚的肢体。然后,使用多类SVM检测关键姿态,而决策森林允许从关键姿势序列中识别人的姿势。
我们在这个类别中还包括[58]中的工作,其中计算了11个手动选择的三维骨骼关节的位置的直方图以获得紧凑的身体姿势表示,该姿势表示对于使用左右肢体是不变的(3D关节的直方图 - HOJ3D)。线性判别分析(LDA)用于投影直方图并计算HMM分类器的K个离散状态。这些K个离散状态可以被认为是关键词词典的元素。
5.2 Mined joint-based descriptors
即使每个人都可能以不同的风格执行相同的动作,但是通常所需的动作涉及类似的关节子集。检测关节的激活子集可以帮助区分不同的动作类别。诸如[64,63,97]等方法专注于挖掘大多数判别性关节的子集或考虑关节子集的相关性。
在[103]中的方法通过其在球坐标系中的位置和速度对每个关节进行建模,并且通过作为正交向量表示的位置和速度之间的相关性来针对关节位置和速度来建模。一个动作被建模为一组直方图,每个直方图在特定的特征和关节上的序列上计算。时间金字塔被用来捕捉动作的时间结构。偏最小二乘法(PLS)[119]用于加权关节的重要性和核心 - PLS SVM [120]被用于分类。
[121]中的方法采用遗传算法来选择关节来表示一个动作类别。在文献[64]中,通过利用基于它们的熵的所有关节角度的相关信息来找到时间窗口中信息最丰富的关节。在高斯随机变量的假设下,熵与方差的对数成正比。假定关节角度数据是一维高斯的独立同分布(i.i.d.)样本,则角度变化方差最高的关节可以定义为信息最丰富的关节。因此,完整的骨骼运动中最有信息的关节(SMIJ)的有序序列隐式地编码运动的时间动态,并被用于表示动作。
在[63]中的工作将估计的关节分成五个身体部位。采用空间域中的对比挖掘算法[122]来检测身体部位的独特的同现空间和/或时间配置(姿势)。这样的同时发生的身体部位(part-sets)形成一个字典。通过采用词袋模型(bag-of-words)方法,动作序列被表示为检测到的部分集的直方图,并且采用1对1交叉核SVM(1-vs-1 intersection kernel SVMs)来对序列进行分类。
与之前的研究相比,在有趣的部分挖掘作为一个步骤集成到特征表示,在[97]挖掘最丰富的身体部位是通过采用多核学习(MKL)[123]方法。身体部位被表示为3D关节之间的差异向量的轨迹。在实践中,对于每个3D关节,考虑到剩余关节的所有差异向量。应用Symlet小波变换,只保留第一个V小波系数。应用小波变换的效果是数据噪声和降维。为了说明动作序列的不同持续时间,时间序列被内插以获得128个采样。最终描述符由骨架中所有3D关节时间序列的前V个系数的连接组成。
文献[124]中的方法采用了身体的多部分建模。每个关节的坐标表示在一个局部参考系统中,这个参考系统是在链中前一个关节处定义的。身体子部分分开对齐,并且修改的最近邻居分类器被用来通过学习最丰富的身体部位来执行动作分类。
5.3 Dynamics-based descriptors
在这个类别中,基于三维骨架动作识别的方法着重于对骨架中的任何子集或所有关节的动力学进行建模。这可以通过考虑线性动力系统(LDS)[99,65]或隐马尔可夫模型(HMM)或混合方法[62]来实现。
从骨骼关节轨迹的LDS建模获得的参数可能描述单个关节的位置和速度。在[99]中,骨骼被分成多个身体部位,代表全身,上身,下身,左/右臂,左/右腿等关节子集。这些身体部分,通过考虑在每个身体部分中的分段上被子采样的一组等距点的方向来计算形状上下文特征表示。这个方向的直方图然后归一化。骨架序列被表示为一组时间序列(每个身体部位一个),如位置,切线和形状上下文特征。时间序列被进一步分成几个时间尺度,从特定序列中的整个时间序列数据开始到更小和更小的相同尺寸的时间部分。每个单独的特征时间序列使用LDS建模,并且该方法通过执行系统识别来学习相应的系统参数。估计的参数被用来表示动作序列。多核学习(MKL)[123]用于学习每个零件配置和时间范围的一组最佳权重。
文献[65]中的LTBSVM将一个动作描述为关节三维位置时间序列的集合。每个动作序列被表示为已经产生三维关节轨迹的线性动力学系统。具体而言,采用自回归移动平均模型来表示序列。ARMA模型在动作序列中捕获的动力学可以通过嵌入模型参数的可观测性矩阵来表示。因此,可以用两个ARMA模型的有限可观性矩阵进行比较。这个有限可观性矩阵的列跨越的子空间对应于格拉斯曼流形上的一个点。通过考虑子空间间的主角,可以在Grassmann流形上进行不同模型的比较。然后,学习表示每个班的平均值的控制正切(CT)空间。将每个观测序列投影到所有CT上形成局部切线束(LTB)表示,并采用线性SVM进行分类。
在[62,125]中,自回归模型用于表示三维关节轨迹,但与[65]相反,没有系统识别来恢复AR模型的参数。相反,3D关节的一组轨迹由Hankelet [126]表示,嵌入了线性时不变系统(LTI)的可观测矩阵。用于比较汉克尔矩阵的子空间距离通过不相似性得分近似[127]。通过滑动窗口的方法,一个动作被表示为一系列Hankelet。一个HMM允许建模从一个LTI系统到另一个LTI系统的转换,产生一个转换动态系统的模型。作为一个Hankelet不变仿射变换[126],不需要预处理数据。
另一个相关的工作是动态森林模型(DFM)[128],其中使用了一组自回归树[129]。自回归树是时间序列数据的概率自回归树,其中每个叶节点存储具有固定协方差矩阵的多变量正态分布,并且预测滤波分布依赖于树上的访问节点,表示每个叶节点过去的观察。每个自回归树都使用套袋分别进行训练。用森林估计的高斯后验集合来计算森林后验,这可以表示为高斯混合的多模态混合。
我们在这一节还包括分层Dirichlet过程隐马尔可夫模型(HDP-HMM)方法[130]。这是HMM的非参数变体,其中每个状态具有状态特定的转换概率,并且该模型具有无限数量的状态。该模型是训练有素的方式,并允许行动课分享训练的例子。
另一个相关的表现形式是[101]中提出的表现形式,其中身体姿势被视为随着时间的推移身体关节位置的连续和可微函数。在这个假设下,可以在当前时间步的周围的一个窗口中通过其二阶泰勒近似在局部逼近这个身体姿态函数。这样,就可以通过当前的关节位置和人体关节的速度和加速度等微分特性来完全表征局部三维人体姿态。信息描述符是通过将标准化的三维姿态,在5帧的时间窗口中估计的一阶和二阶导数连接而获得的。这里,速度描述3D关节的方向和速度,而加速度捕捉速度随时间的变化。采用基于K近邻(KNN)和投票方案的非参数动作分类方案。
6. Fusing skeletal data with other sensors׳ data
文献[54,112,131]中的其他几种方法融合了从多个流提取的信息:骨架数据,RGB视频和深度图。在这里,我们简要地描述这些方法,因为它们不能直接与仅使用骨架数据的方法相比较。
一般而言,仅使用深度图的作品倾向于基于估计深度的统计来描述人体表面。李等人[54]建议使用一个动作图,其中每个节点是编码人体姿势的一组3D点。王等人将3D动作序列视为4D形状,并提取随机占有模式(ROP)特征。稀疏编码仅用于对包含对分类有用的信息的特征进行编码。在[133]中,空间和时间轴被划分为单元格,计算空间时间占用模式来表示深度序列。Oreifej等人[60]根据深度和空间坐标将深度序列描述为在4D体积中捕获的定向表面法线(HON4D)的直方图。
Rahmani等人[134]建议使用定向主成分(HOPC)的直方图通过将PCA应用于每个点周围的数据量来捕获深度图中每个点周围的局部几何特征。HOPC是通过将投影的特征向量按其特征值的降序连接而形成的。修剪过程只允许保留最高质量的关键点。分类由直方图相交核SVM执行。
还有一种重新解释方法的趋势,这种方法被证明是成功的,可以从RGB视频中识别动作,并且可能被证明对深度数据有用。例如,在文献[135]中,采用了基于修正的方向梯度直方图(HOG)的深度图的时空特征。骨骼数据用于检测深度图中的身体部位并提取局部直方图描述符。将基于HOG的描述符与关节角度相似度(JAS)相结合,其测量关节角度沿手势的成对相似度。在[136]中,提出了一种从深度视频(DSTIPs)中提取时空兴趣点的算法。在每个DSTIP周围提取局部3D深度立方相似度特征(DCSF)。这种描述符通过测量构成3D立方体的子块的相似性来编码3D立方体的时空形状。
其他作品使用骨架数据来检测身体部位,并从深度图或RGB视频中提取局部特征。在[112]中,使用深度数据和估计的三维关节位置来计算局部占据模式(LOP)特征,即在骨架关节周围的深度统计。傅立叶时间金字塔被用来捕捉动作的时间结构。为骨架计算的一组特征称为actionlet。数据挖掘技术被用来发现最有鉴别力的小动作。最后,使用多核学习方法来对动作小节进行加权。Sung等人结合RGB,深度和手位置,从骨骼关节提取的身体姿势和运动特征。 HOG用于描述RGB和深度图像。然后,采用两层最大熵马尔可夫模型进行分类。在[137]中,作者提出将随机森林融合骨架信息和基于STIPS的特征[138]。随机森林训练完成特征融合,选择和行动分类。
在文献[104]中,基于骨架和轮廓的特征被结合起来考虑到人体姿态估计误差。通过考虑轮廓本身的边界,通过背景抑制和其形状来获得轮廓。然后,通过采用以剪影为中心的径向模式来计算形状的直方图。最后的描述符是通过结合这两个特征获得的。采用一包字的方式来表示关键姿态码本的人体姿态。动态时间规整和最近邻分类器被用于分类目的。
文献[139]中的方法着重于RGB-D数据序列中的人类活动识别。该方法融合了形状和运动信息。形状特征用于描述三维轮廓结构,并使用球面谐波表示从深度图中提取。运动特征用于描述人体的运动,并从估计的三维关节位置提取。特别是,该方法仅使用人体的四个远端肢体段来描述运动:左右下臂部分和左右小腿部分。每个远端肢体段由相对于初始框架的定向和平移距离来描述。然后使用多核学习(MKL)技术在SVM分类框架内产生最佳核矩阵。
在[140]中,通过最大裕度时间扭曲(MMTW)一起解决动作对齐和分类,该最大裕度时间扭曲(MMTW)学习了用于最大边缘分类的时间动作对齐。这个问题被公式化为一个潜在的支持向量机器,其中用于表示动作类的幻影动作模板被学习。多个特征用于表示一个动作:骨架数据如[112]中所示,深度数据如[60]中所示,而RGB数据由HOG和HOF表示。所有的描述符被连接在一起。
最后,我们考虑通过融合从深度/骨架数据提取的特征和来自可穿戴式惯性传感器的加速度计测量来试图获得可靠的动作/活动识别的研究。在[141]中的方法采用从深度图和加速度统计中提取的运动描述符(类似于[142]中的运动历史图像),所述深度图和加速度统计例如在时间窗口上的均值,方差,标准偏差和均方根。Dempster-Shafer理论用于将两个分类器的分类结果进行组合,每个分类器对应一个传感器类型。在[143]中,惯性传感器和深度摄像机被用来监测食物的摄入手势(如细切,装食物,并将食物送到嘴里)。根据深度数据估算身体部位(手腕,肘部和肩部)的位置和位移,并结合可穿戴惯性传感器测量的加速度。以类似的方式,来自加速度计和骨架数据的[144,145]测量被连接在一起并用于对各种活动进行分类。特别是在[144]中,连接的特征被用作二进制神经网络分类器集合的输入;在[145]中,隐式马尔科夫模型(HMM)分类器观察到的连接特征被用于手势识别。
骨骼数据和加速计测量的联合使用可能对辅助和/或健康监测技术非常有用。然而,即使原则上采用惯性传感器的方法也可以提高动作分类中的准确度值,但是可穿戴传感器在其他领域中可能不可用或不可靠。我们注意到,在第7节描述的所有数据集中,只有伯克利多模式人类行为数据库(MHAD)[148]提供了加速度计测量。
7. Datasets and validation protocol
表2总结了基于骨架动作分类中最常用数据集的主要特征。表格介绍的内容:引用数据集的文章,动作类别的数量,数据集中序列的数量,执行动作的主题的数量,RGB的存在(N =否和Y =是),深度和骨架数据,建议的验证协议。验证协议在表3中有描述。骨架列中的数字表示骨架中的关节数量。这些基准是为分段行动分类而设计的,一般来说,每个行动都以中性姿态开始和结束。在下面,我们简要描述每个这些数据集。由于本survey是关于基于三维骨架的行为分类,我们主要关注提供骨架数据的数据集。因此,该表不包含数据集,如仅提供深度数据的Hollywood 3D [146],或提供令人印象深刻的数据的Human3.6M [147],其主要目标是测试人体姿态估计方法。这些数据不是为了测试行动分类方法。
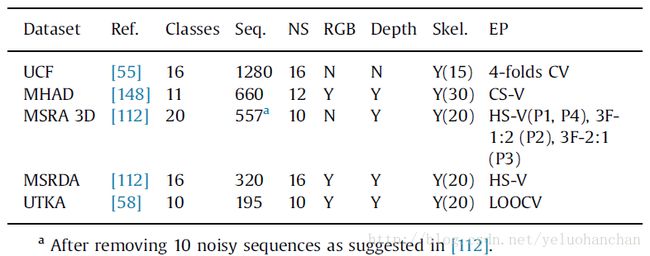
Table2 The most commonly used datasets for skeleton-based action recognition
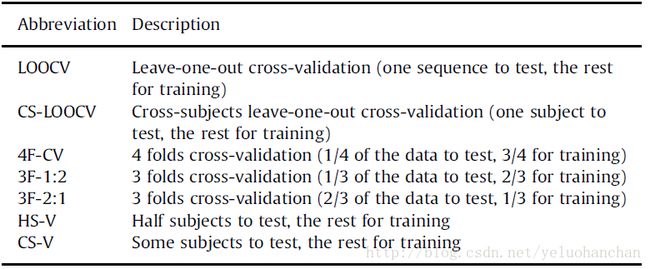
Table3 The most commonly adopted valid ation protocols
如表2所示,数据集在行动次数,数据收集主体数量和序列数量方面存在巨大差异。一些数据集可能不适合需要学习复杂模型参数的方法,因为可用样本数量很少。
7.1 UCF
UCF数据集[55]仅提供骨架数据。它提供了由16个人(13名男性和3名女性,全部在20-35岁之间)进行的16次动作的骨架(15个关节)数据。行动样本共有1280个,时间范围为[27,229],平均长度为66±34个。在这个数据集中的行为是:balance, climbladder, climbup, duck, hop, kick, leap, punch, run, stepback, stepfront, stepleft, stepright, twistleft, twistright, and vault。 在[55]中建议的验证协议基于4倍交叉验证(4F-CV),其中1/4是用于测试的序列,剩下的用于训练。 但是,文献中已经采用了其他协议。
7.2 MHAD
伯克利多模式人体行为数据库(MHAD)[4] 包含来自运动捕捉系统,立体相机,深度传感器,加速度计和麦克风的数据。 它提供了12个演员5次执行的11个动作的约660个动作序列。 这些行动是:jumping inplace, jumping jacks, bending, punching, waving twohands, waving righthand, clapping throwing ball, sit downandstandup, sit down, and stand up。受试者被指示要作行动;然而没有具体的细节给出应该如何执行的行动(即表演风格或速度)。Mo-Cap数据包括43个LED标记的3D位置,经过处理得到30个关节的骨骼数据。在[148]中,采用了跨科目验证(CS-V),其中前7名受试者的动作序列被用于训练,最后5名受试者的序列被用于测试。
7.3 MSRA3D
MSRA3D数据集[5]提供了骨架和深度数据。特别是,数据集提供了由10位受试者执行2-3次20次动作的骨架(20个关节)。它提供了3D世界坐标和屏幕坐标以及检测到的骨骼关节的深度。该数据集包含以下动作的骨架序列:high arm wave, horizontal arm wave, hammer, hand catch, forward punch, high throw, draw x, draw tick, draw circle, hand clap, two hand wave, side-boxing, bend, forward kick, side kick, jogging, tennis swing, tennis serve, golf swing, pickup and throw。被摄体面向相机,动作包括手臂,腿,躯干及其组合的各种动作。如果采取单臂或双腿行动,则建议受试者使用右手臂或腿。
567个可用序列的长度范围在[13,76],平均值为39.6±10。这个数据集有几个验证协议。在协议1中,对整个类别集合进行交叉主题验证。由于数据集中的类别数量很大,这是一种有趣的评估方法,但由于训练的可用序列数量较少以及受试者之间的差异性较大,因此存在一些挑战。在作者的网站上描述了验证协议:由于骨架上的过度噪声,已经过滤了10个序列;训练和测试集中数据的主题分割如下:训练的主题1,3,5,7和9,其他测试(HS-V协议)。
第二种验证协议将动作分成3个重叠的8个类别的子集。第一个动作组(AS1)包括水平手臂波,锤子,前冲,高抛,手拍,弯曲,网球发球,接球投篮等动作。第二个动作组(AS2)包括高手臂,手抓,平局x,平局,平局,双手,前锋,侧边拳。第三套动作包括高抛,前踢,侧踢,慢跑,网球挥杆,网球发球,高尔夫挥杆,接球和投掷。 AS1和AS2组需要相似动作的组,而AS3组则需要更复杂的动作。这些子集的测试是通过不同类型的数据分割完成的。在协议2中,采用3倍交叉验证,其中1/3用于测试模型,2/3用于训练目的(3F-1:2)。协议3采用3倍交叉验证,其中2/3用于测试模型,1/3用于训练模型(3F-2:1)。在“协议4”中,最广泛采用的是跨科目验证,其中第1,3,5,7和9科目用于训练,其余的用于测试(HS-V协议)。
这个数据集的主要挑战是数据损坏。一些序列是非常嘈杂的,在一些论文[100]中,已经从数据集中去除了损坏的序列。在其他作品中[64,99],有些数据完全被忽视。一些研究,如[102,65],采取了不同的主题分裂。由于所有这些不同的权宜之计,对这个数据集进行比较是困难的,可能会令人困惑。我们参考[149]进一步讨论这些问题。
7.4 UTKA
UTKA数据集[6]提供RGB,深度和骨架数据。该数据集提供了十个主题两次执行的10个动作的骨架(20个关节)。行动是:walk, sit down, stand up, pick up, carry, throw, push, pull, wave and clap hands。数据集包含195个序列。骨架序列的长度范围在[5,170],平均值为30.5±20帧。在手动选择的关节头,L / R肘,L / R指针,L / R膝关节,L / R脚,髋关节中心的一个子集上进行的[58]中的实验是在一次性交叉验证和L / R髋关节。在这个数据集中,一个主题是左撇子,同一个动作的不同实现之间存在显着差异:一些演员用一只手拾取物体,而另一些则用双手拾取物体。个人可以用右臂或左臂来抛掷物体,产生不同的轨迹。最后,从不同的角度采取行动,因此,身体的方向变化。
7.5 MSR daily activity 3D
MSR日常活动3D数据集[7]包括16个活动:drink, eat, read book, call cellphone, write on a paper, use laptop, use vacuum cleaner, cheer up, sit still, toss paper, play game, lie down on sofa, walk, play guitar, stand up, and sit down。 动作由10个不同的主题进行两次:一次是站立的,一次是坐着的。 数据集提供了320个手势样本的深度图,骨架关节位置(20个关节)和RGB视频。在一些情况下,在每个帧中检测到多于一个骨架。[112]的作者建议使用第一个检测到的骨架。 联合位置用真实世界坐标和标准化屏幕坐标加深度表示。建议的方案是跨科目验证(HS-V),其中受试者1,3,5,7和9被用于训练,其他受试者被测试。
7.6 Further benchmarks
在文献中有时使用的其他数据集是康奈尔活动数据集(CAD)-120数据集和康奈尔活动数据集(CAD)-60数据集,它们由非常有限的序列组成。
康奈尔活动数据集(CAD)-120数据集[150] 8提供了120个日常活动的RGB-D视频:making cereal, taking medicine, stacking objects, unstacking objects, microwaving food, picking objects, cleaning objects, taking food, arranging objects, and having a meal。每个活动可以由10个不同的(标记的)子活动组成:reaching, moving, pouring, eating, drinking, opening, placing, closing, scrubbing, and null。这些活动已经由4名学员完成(一名左撇子)。只给予对象高层次的描述,并被要求多次用不同的对象进行活动。他们通过一系列长期的子活动来进行活动,这些子活动在子活动的长度,子活动的顺序以及执行任务的方式上都有很大的不同。
摄像机被安装成可以看到被摄对象(虽然被摄对象可能不会面对摄像机),但是通常会有明显的身体部位遮挡。
Cornell活动数据集(CAD)-60数据集[150](参见脚注8)包含60个RGB-D视频,代表12个活动,rinsing mouth, brushing teeth, wearing contact lens, talking on the phone, drinking water, opening pill container, cooking (chopping), cooking (stirring), talking on couch, relaxing on couch, writing on whiteboard, and working on computer。活动由5个不同的环境中的4个不同的主题进行:office, kitchen, bedroom, bathroom, and living room。其中一个问题是左撇子。在收集数据时,受试者被告知如何进行这项活动。
验证方案包括交叉主题分析(即一次主题交叉验证)和二次交叉验证,其中一半数据用于训练,另一半用于独立测试活动主体。数据已被镜像来训练左右手对象的动作模型。
另一个公开可用的数据集是可组合的活动数据集[116],这个数据集由由14名演员执行的16个类的活动的693个视频组成。数据集中的每个活动都由许多原子操作组成。视频中的动作总数是26,每个动作中的动作数量在3到11之间。到目前为止,我们没有发现采用这个数据集的其他作品。
为了完整起见,我们还报告了Microsoft Research Cambridge-12(MSRC-12)Kinect手势[151]数据集。这个数据集只提供了由30个人执行的12个不同动作的骨架(20个关节)。这些动作是基于不同的指令集(描述性文本,图像和视频或其组合)执行的。594个序列中的每一个包含多个相同手势的重复,总共6243个样本。
手势可以分为两类:标志性的手势,其中插入手势和参考之间的对应关系,和隐喻手势,这是一个抽象的概念。数据集中的六个标志性手势是duck (crouch/hide), goggles (put on night vision goggles), shoot, throw, change weapon, and kick。在这个数据集中的六个隐喻手势是:lift outstretched arms (start system/music/raise volume), push right (navigate to next menu/move arm right), wind it up, bow (take a bow to end music session), had enough (protest the music), beat both (move up the tempo of the song/beat both arms)。
该数据集被设想为在视频中的动作本地化,而不是分段的动作分类。因此,注释由可以检测到动作的时间戳组成,但是没有提供关于动作持续时间的信息。然而,在[100]中,为分类目的进一步注释(分段操作)被提供并公开可用。[11]基于这种注释,每个序列的长度范围在[14,493],平均长度为85±31帧。在[151]验证协议是留一个跨学科验证(CS-LOOCV),50%主题分裂(HS-V),3倍交叉验证(1/3测试和2/3训练,还有2/3要测试,1/3要训练)。我们认为,与数据集一起提供的注释可能已经以不同的方式用于侧重于分割的动作数据集的作品,并且不清楚这些论文的性能是否可比。
8. Comparison of methods at the state of the art
在本节中,我们将讨论基于三维骨架的动作分类中已使用的方法的性能。首先,我们明确了每种方法的性能如何评估;之后,我们将重点放在第7部分中所介绍的大多数采用的数据集上的实验结果的报告方法。我们从第5部分介绍的分类的角度比较和讨论了文献中报告的结果。我们还强调了分类框架与所提议的行动表示一起使用以理解描述符的信息性。最后,我们讨论[55]中介绍的动作识别的延迟。
8.1 Performance evaluation – accuracy in classification
测量分类方法性能的最常用的方法是平均准确度值,其定义为在要分类的序列总数上正确分类的序列的数量。这个准确度值在多次运行中取平均值,特别是在交叉验证或随机初始化模型参数的多次运行的情况下。在平衡数据集的情况下,平均准确度值等于平均每类准确度值,即在每个类中给出相同数量样本的数据集中。可以通过平均每班准确度值来衡量一个类中正确分类的顺序的比例,从而收集到一些见解。通常的做法是提出一个混淆矩阵,它记录了沿着主对角线的每类精度值,以及在超对角线元素中错误分类序列的每类比例。在这里,除非有不同的规定,否则我们只报告每种方法在平均验证协议上获得的平均准确度值。
8.2 Datasets included in the comparison
现有技术中的大多数方法在不超过2个数据集上报告准确度值。最常用的基准是UTKA,UCF,MSRA-3D,MHAD和MSRDA数据集。在所有这些基准中,我们注意到MHAD是唯一提供Mo-Cap数据的,而UCF提供了从深度图估计的15个关节的骨架。其余的数据集提供了从深度图估计的20个关节的骨架(关于每个数据集的主要特征的细节参见表2)。
我们不报告CAD-60和CAD-120的结果,与其他数据集相比,它们的序列数量较少,并且不太常用。我们也不会在MSRC-12数据集上报告结果。实际上,在MSRC-12数据集上进行测试时,已经应用了不同的验证协议,但不清楚这些精度值的可比性。
我们也注意到在MSRA-3D数据集上测试时使用了不同的验证协议。已知验证协议的选择会影响MSRA-3D数据集上呈现的精度值[149]。因此,在介绍这个数据集的准确性值时,我们强调了是否采用了不同于[54]作者提出的验证协议。
8.3 Discussion
我们在表4中收集了在UCF,MHAD,MSRDA,UTKA和MSRA-3D上现有技术的方法所报告的准确度值。 在该表中,MSRA-3D数据集的结果通过应用协议P1获得,也就是说,在实验中使用所有的动作类别。 在表5和表6中,我们报告了在使用第7.3节所述的操作类的不同子集(协议P2,P3和P4)中的协议时,MSRA-3D数据集的精度值。
表格的结构反映了我们在第5节中提出的分类。特别是,每个表的第一列指出了该方法所属的类别:空间描述符(S),几何描述符(G),基于关键姿势描述符(K),基于关节的描述符(M),最后是基于动态的描述符(D)。

Table4 Average accuracy value reported for skeleton-based action recognition. (S) indicates that the performance refers to skeletal data adoption but the cited work reports also performance on hybrid representation.
一些方法如[137,112,104]建议使用混合特征,其中从深度图和/或RGB视频提取的骨架数据和信息被共同用于分类动作序列。只要可用,我们在仅采用骨架数据时介绍这些方法的性能。我们通过在第二栏的参考文献附近添加(S)来突出这个可能性。在第三栏中,我们指出了通过的分类框架。
在本次调查中报告的工作中,MHAD数据集的准确度值最高([99]达到100%)。我们认为这是由于基于Mo-Cap的骨架序列比从深度图估计的并且与其他数据集一起提供的噪声少的事实。
报告最高准确度值的第二个数据集是UCF数据集(由[114]提高到99.2%),这为训练模型提供了更多的序列,并且只是适度地损坏了骨架序列。
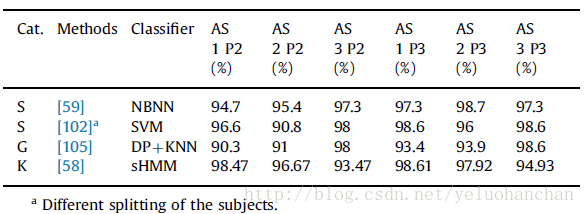
Table5 Performance on the MSRA3D using protocols P2 and P3.

Table6 Performance on the MSRA3D using protocol P4. (S) indicates that the performance refers to skeletal data adoption but the cited work reports also performance onhybrid representation.
在MSRA-3D数据集上,大部分报告结果的表现是可比的([103]高达91.5%)。表5和表6中结果的比较突出了验证协议如何影响报告的性能。此外,P4是一个交叉主体验证协议,这是对手头问题的最适合的验证。
我们注意到MSRA-3D和MSRDA数据集的骨架序列损坏最严重。图4显示MSRA-3D数据集中一些损坏的骨架的例子。该图像旨在提供关于骨骼数据腐败程度的概念。由于骨架跟踪算法的失败,在类拾取和抛出的一些序列中,骨架丢失(或者减少到一个点),如图4的最后图像所示。

图4 Some samples from the MSRA-3D dataset where the skeleton is corrupted
在MSRDA数据集中也存在类似的失败/损坏的数据,其中最佳准确度值约为73.1%,由[103]实现。过多的噪声可能导致MSRDA数据集中基于骨架的动作描述符实现的准确度较低。我们也注意到MSRDA中的动作比其他数据集中的动作更复杂,并且通常需要与场景中的对象进行交互。这种相互作用很难从骨架数据建模/检测。
不幸的是,在实验中使用不同的基准和协议使得说明哪种方法是最好的。所有评审作品中使用的数据集也具有不同的特征,因此每种方法在处理数据集中的具体挑战方面都有其自身的优点,而不是在其他方面。考虑方法的类别,在采用空间描述符(S)的作品中,最具竞争力的似乎是[102]中的工作,其中骨架序列被表示为时空图,并且基于小波的特征允许考虑针对不同的时空尺度。即使该方法在UCF数据集上采用空间描述符的工作中取得了最高的准确度值,但对MSRA-3D数据集的实验已经用不同的验证协议进行了实验,因此该比较仍不清楚。
在表4中采用几何描述符的方法中,UTKA数据集的最佳准确度值为97.08%,已被[34]报道(这也是UTKA数据集一般获得的最准确的值)。我们从第五节的讨论中回想到,在[34]中,不同身体部位之间的相对三维几何体是明确估计的,骨架序列是李群流形中的一条曲线。曲线进一步由傅立叶时间金字塔(FTP)表示。这表明该方法可能具有较高的计算复杂度。
我们相信,一般来说,几何描述符看起来非常有希望,即使需要在其他基准上进行更多验证来证实这种直觉。
大多数基于采样的描述符已经在MSRDA数据集上进行了测试。这可能是由于数据集中序列的性质:通过学习与动作更相关的关节子集,可能更容易区分与场景中的对象的不同交互。在这些作品中,最有前途的可能是[103],其中一个动作被建模为一组直方图,每个直方图在特定特征和身体关节上的序列上计算;偏最小二乘用来衡量关节的重要性。
至于基于动态的描述符,所有评估的方法都具有可比较的性能。这些方法看起来很有前途,因为它们与不同数据集中其他类别的方法非常具有竞争性。而且,即使仅在身体关节的三维轨迹上进行测试,所有这些方法都是通用的,并且可以应用于更复杂的三维动作表示,诸如骨架序列的几何描述符。
8.4 Action classification framework
如表4-6所示,现有技术中的大多数方法采用诸如SVM或一些变体的辨别方法来解决基于三维骨架的动作分类[34,103,99]。只有很少的方法采用生成模型,如[116,58]。特别是标准的隐马尔可夫模型(sHMM)在[58,98]中被应用。
生成模型的判别式学习在[130](层次Dirichlet过程隐马尔科夫模型-HDP-HMM)和[62](判别式HMM - dHMM)中被提出。 Logistic回归在[55]中应用,而在[137]中使用随机森林。
其他几种方法采用非参数方法,如最近邻(NN)[104],K-NN [105]或简单的变体来提高分类精度值[101,124,59]。
动态时间规整(DTW)在[34,104]中被采用,而基于动态规划(DP)的距离在[105]中被应用。
总的来说,这些表格似乎证实,在这种数据以及基于三维骨架的行为分类问题上,代表性方法优于生成性方法。
此外,我们注意到,与上述大多数引用的作品相比,[97]处理的是另一个原始问题,即同时检测到的行为。
8.5 Latency in action recognition
最后,我们注意到[55]提出了一个基于识别延迟的基于骨架的动作分类的替代评估协议。该验证协议试图测量识别动作需要多少帧,并且在部分观察到的动作序列可用时测量分类的准确性。具体而言,考虑到持续时间增加的时间窗来测量准确度值。
其他一些作品[135,114,65]也采用了这个其他的验证协议。表7报告并比较了这些论文在UCF数据集中进行的分析。在表中,列表示观察到的时间窗口的长度。我们注意到目前还不清楚这个评估是否可以跨数据集进行比较,原因如下:(1)动作序列的长度可能会有很大的变化,特别是在不同类别之间。因此,某些类中的序列在N个帧之后可能是完全可观察的,而其余类中的序列则不是;(2)目前还不清楚数据采集的帧率如何影响不同基准的这种分析。第一个问题的解决方案可能是考虑观察帧的百分比,而不是观察帧的数量的绝对值。我们进一步注意到,这种评价可能会对[102,99,103,100]这样的作品提出一些挑战,这些作品采用了金字塔式的方法,需要看到整个序列来识别行为。

Table7 Latency-based analys is on the UCF dataset (average classification accuracy value in %). The number on each column indicates the number of observed frames
9. Conclusions and future directions
在过去的几年里,由于廉价的深度相机的广泛使用和基于深度图的骨架估计和跟踪方面的成功,使得基于骨架序列的人类行为识别的研究激增。本文总结了建立三维骨架动作分类系统所需的主要技术(硬件和软件),以解决基于获取的时序的三维关节进行动作分类的问题。从大部分相关文献的分析中,我们着重强调了数据归一化,以消除不同相机参数和生物学差异带来的识别问题。我们还指出了一些框架的规范化方法以及如何与运动重定向技术相结合。
在本文中,我们调查了几个公开可用的3D动作分类基准。根据我们的分析,我们注意到,大多数采用骨架动作分类的数据集是UCF,MHAD,MSRDA,UTKA和MSRA-3D数据集。这样的基准不仅在数据采集技术(即,Mo-Cap与深度相机)方面显示出非常不同的特征,而且在所采集的数据的种类方面(例如,骨架中不同数量的身体关节,深度/ RGB数据等)和动作类别(即动作的复杂度和类别的数量)。我们还观察到,骨架数据被数据集中不同级别的噪声破坏,我们显示了损坏的骨架的例子。
根据我们的分析,总的印象是文献中的大多数基准对于复杂模型的适当训练来说太小,并且这方面可能影响文献综述的结果。我们认为,尽管有大量公开的数据集,但在采用合适的评估协议方面仍缺乏统一的基准和最佳实践,并且还缺少一个更详尽和更广泛的用于动作分类的3D骨架数据集。实际上,我们所调研的大多数数据集都是用简单的操作来处理的,唯一的例外是MSRDA数据集。考虑到更自然的动作识别以及基于骨骼数据的自发行为识别可能是一个有趣的未来方向。考虑到三维动作分类的目的,我们认为最适合的验证协议应该基于交叉主体验证,特别是当使用非参数方法如KNN时。这将允许测试一个动作描述符对于主体间变化的强大程度。
本文还根据从骨架序列中提取的信息种类提出了基于骨架的动作表示技术的分类。在我们的分类中,现有技术中的方法被分类为:基于关节的表示方法,基于挖掘的联合描述符和基于动力学的描述符。基于关节的表示方法从骨架中提取特征,以获取人体关节的相关性。基于挖掘的联合描述符通过了解身体部位的参与情况来对行动进行区分。基于动力学的描述符将人体骨架系列视为时间序列的动力学模型。进一步的我们将基于联合的描述符分为三类:空间描述符、几何描述符和基于关键姿势的描述符。空间描述符试图通过测量所有可能的成对距离(在给定时间或跨时间)或其协方差矩阵来关联3D身体关节;几何描述符尝试估计移动骨架所需的几何变换序列的方法,或者表示关节子集的相对几何。基于关键姿态的描述符,计算一组关键姿态,并且用最接近的关键姿势表示骨架序列。
通过对已审查工作的分析,我们发现在测试方法时使用了非常不同的(有时甚至是任意的)验证协议,这使得比较不同的方法变得更加困难。尽管如此,所采用的协议,基准和分类框架的变化使得不同方法之间的比较变得困难,总的印象是,最方便的和信息丰富的方法落在几何和基于动力学模型的描述符的类别中。因此,混合这两种方法的方法可能有助于在将来的作品中获得更高的分类准确度值。
尽管在基于骨架的行动分类方面做出了巨大的努力和进展,但仍然有一些问题在一般情况下还没有完全解决。例如,许多方法没有明确说明动作之间的共同点和行动分享。将动作看作是一系列可能在动作之间共享的子动作是很自然的。例如,在MSRA-3D数据集中,身体弯曲主要是动作拾取和抛出的子动作。这个例子也反映出,与活动(可能被定义为行动构成)相比,缺乏普遍接受的行动定义。
另一个似乎被大多数评论方法所忽略的问题,特别是使用金字塔方法和整体描述的方法,是可以用不同数量的子运动重复来执行。例如,在挥手的动作中,手可以挥动数次;如果考虑到动作表示中的这个问题,可能利用此来解决问题。
另一个研究方向可能是对[97]中提出的并行行为的认识,这可能有助于人们在协作任务中理解行为。这里的问题不仅在于认识到一组主体执行哪些行动,而且还认识到哪些行动是社会相关的,通过认识社会参与主体的小组。
最后,在本文中,我们只关注分段行为分类。但是,在线动作识别和行动检测框架中可能采用哪些经过审核的行为表述还不清楚。例如,当采取动作本地化框架时,涉及小波分解,金字塔方法或整体描述的方法可能会导致更高的计算复杂度。
总之,我们认为,对骨架数据的推理提供了一个非常方便的机会来研究成熟的框架,并扩大我们对人类行为识别的理解。这种研究可以大大提高游戏应用和人机交互[152]。从这个意义上说,在线学习或基于先验模型的学习可能对改善特定的人机交互非常有帮助。
[1]: S. Kwak, B. Han, J. Han, Scenario-based video event recognition by constraint flow, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Colorado Springs, 2011, pp. 3345–3352, http://dx.doi.org/10.1109/CVPR.2011.5995435.
[2]: U. Gaur, Y. Zhu, B. Song, A. Roy-Chowdhury, A string of feature graphs model for recognition of complex activities in natural videos, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Barcelona, Spain, 2011, pp. 2595–2602, http://dx.doi.org/10.1109/ICCV.2011.6126548.
[3]: S. Park, J. Aggarwal, Recognition of two-person interactions using a hierarchical Bayesian network, in: First ACM SIGMM International Workshop on Video surveillance, ACM, Berkeley, California, 2003, pp. 65–76, http://dx.doi.org/10.1145/982452.982461.
[4]: I. Junejo, E. Dexter, I. Laptev, P. Pérez. View-independent action recognition from temporal self-similarities. IEEE Trans. Pattern Anal. Mach. Intell., 33 (1) (2011), pp. 172-185, 10.1109/TPAMI.2010.68.
[5]: Z. Duric, W. Gray, R. Heishman, F. Li, A. Rosenfeld, M. Schoelles, C. Schunn, H. Wechsler. Integrating perceptual and cognitive modeling for adaptive and intelligent human–computer interaction Proc. IEEE, 90 (2002), pp. 1272-1289, 10.1109/JPROC.2002.801449.
[6]: Y.-J. Chang, S.-F. Chen, J.-D. Huang. A Kinect-based system for physical rehabilitation: a pilot study for young adults with motor disabilities. Res. Dev. Disabil., 32 (6) (2011), pp. 2566-2570, 10.1016/j.ridd.2011.07.002.
[7]: A. Thangali, J.P. Nash, S. Sclaroff, C. Neidle, Exploiting phonological constraints for handshape inference in ASL video, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Colorado Springs, 2011, pp. 521–528, http://dx.doi.org/10.1109/CVPR.2011.5995718.
[8]: A. Thangali Varadaraju, Exploiting phonological constraints for handshape recognition in sign language video (Ph.D. thesis), Boston University, MA, USA, 2013.
[9]: H. Cooper, R. Bowden, Large lexicon detection of sign language, in: Proceedings of International Workshop on Human–Computer Interaction (HCI), Springer, Berlin, Heidelberg, Beijing, P.R. China, 2007, pp. 88–97.
[10]: J.M. Rehg, G.D. Abowd, A. Rozga, M. Romero, M.A. Clements, S. Sclaroff, I. Essa, O.Y. Ousley, Y. Li, C. Kim, et al., Decoding children׳s social behavior, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Portland, Oregon, 2013, pp. 3414–3421, http://dx.doi.org/10.1109/CVPR.2013.438.
[11]: L. Lo Presti, S. Sclaroff, A. Rozga, Joint alignment and modeling of correlated behavior streams, in: Proceedings of International Conference on Computer Vision-Workshops (ICCVW), Sydney, Australia, 2013, pp. 730–737, http://dx.doi.org/10.1109/ICCVW.2013.100.
[12]: H. Moon, R. Sharma, N. Jung, Method and system for measuring shopper response to products based on behavior and facial expression, US Patent 8,219,438, July 10, 2012 〈http://www.google.com/patents/US8219438〉.
[13]: T.B. Moeslund, E. Granum. A survey of computer vision-based human motion capture. Comput. Vis. Image Underst., 81 (3) (2001), pp. 231-268, 10.1006/cviu.2000.0897.
[14]: S. Mitra, T. Acharya. Gesture recognition, a survey. IEEE Trans. Syst. Man Cybern. Part C: Appl. Rev., 37 (3) (2007), pp. 311-324,10.1109/TSMCC.2007.893280.
[15]: R. Poppe. A survey on vision-based human action recognition. Image Vis. Comput., 28 (6) (2010), pp. 976-990, 10.1016/j.imavis.2009.11.014
[16]: D. Weinland, R. Ronfard, E. Boyer. A survey of vision-based methods for action representation, segmentation and recognition. Comput. Vis. Image Underst., 115 (2) (2011), pp. 224-241, 10.1016/j.cviu.2010.10.002
[17]: M. Ziaeefar, R. Bergevin. Semantic human activity recognition: a literature review. Pattern Recognit. 8 (48) (2015), pp. 2329-2345, 10.1016/j.patcog.2015.03.006
[18]: G. Guo, A. Lai. A survey on still image based human action recognition. Pattern Recognit., 47 (10) (2014), pp. 3343-3361, 10.1016/j.patcog.2014.04.018
[19]: C.H. Lim, E. Vats, C.S. Chan. Fuzzy human motion analysis: a review. Pattern Recognit. 48 (5) (2015), pp. 1773-1796, 10.1016/j.patcog.2014.11.016
[20]: M. Andriluka, S. Roth, B. Schiele, Pictorial structures revisited: people detection and articulated pose estimation, in: Proceedings of Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Miami Beach, Florida, 2009, pp. 1014–1021, http://dx.doi.org/10.1109/CVPRW.2009.5206754.
[21]: Y. Yang, D. Ramanan, Articulated pose estimation with flexible mixtures-of-parts, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Colorado Springs, 2011, pp. 1385–1392, http://dx.doi.org/10.1109/CVPR.2011.5995741.
[22]: D. Ramanan, D.A. Forsyth, A. Zisserman, Strike a pose: tracking people by finding stylized poses, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, IEEE, San Diego, CA, USA, 2005, pp. 271–278, http://dx.doi.org/10.1109/CVPR.2005.335.
[23]: L. Bourdev, J. Malik, Poselets: body part detectors trained using 3D human pose annotations, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Kyoto, Japan, 2009, pp. 1365–1372, http://dx.doi.org/10.1109/ICCV.2009.5459303.
[24]: D. Tran, D. Forsyth, Improved human parsing with a full relational model, in: Proceedings of European Conference on Computer Vision (ECCV), Springer, Crete, Greece, 2010, pp. 227–240.
[25]: N. Ikizler, D. Forsyth, Searching video for complex activities with finite state models, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Minneapolis, Minnesota, 2007, pp. 1–8, http://dx.doi.org/10.1109/CVPR.2007.383168.
[26]: F. Lv, R. Nevatia, Single view human action recognition using key pose matching and Viterbi path searching, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Minneapolis, Minnesota, 2007, pp. 1–8.
[27]: N. Ikizler, P. Duygulu, Human action recognition using distribution of oriented rectangular patches, in: Proceedings of Workshop on Human Motion Understanding, Modeling, Capture and Animation, Springer, Rio de Janeiro, Brazil, 2007, pp. 271–284.
[28]: M. Brand, N. Oliver, A. Pentland, Coupled hidden Markov models for complex action recognition, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, San Juan, Puerto Rico, 1997, pp. 994–999.
[29]: H. Wang, A. Kläser, C. Schmid, C.-L. Liu. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis., 103 (1) (2013), pp. 60-79, 10.1007/s11263-012-0594-8
[30]: J.C. Niebles, H. Wang, L. Fei-Fei. Unsupervised learning of human action categories using spatial–temporal words. Int. J. Comput. Vis., 79 (3) (2008), pp. 299-318, 10.1007/s11263-007-0122-4.
[31]: G. Johansson. Visual perception of biological motion and a model for its analysis. Percept. Psychophys., 14 (2) (1973), pp. 201-211
[32]: S. Sadanand, J.J. Corso, Action bank: a high-level representation of activity in video, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Providence, Rhode Island, 2012, pp. 1234–1241, http://dx.doi.org/10.1109/CVPR.2012.6247806.
[33]: A. Ciptadi, M.S. Goodwin, J.M. Rehg, Movement pattern histogram for action recognition and retrieval, in: Proceedings of European Conference on Computer Vision (ECCV), Springer, Zurich, 2014, pp. 695–710, http://dx.doi.org/10.1007/978-3-319-10605-2_45.
[34]: R. Vemulapalli, F. Arrate, R. Chellappa, Human action recognition by representing 3D skeletons as points in a Lie Group, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Columbus, Ohio. 2014, pp. 588–595, http://dx.doi.org/10.1109/CVPR.2014.82.
[35]: L. Sigal. Human pose estimation. Comput. Vis.: A Ref. Guide (2014), pp. 362-370
[36]: K. Mikolajczyk, B. Leibe, B. Schiele, Multiple object class detection with a generative model, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, IEEE, New York, 2006, pp. 26–36.
[37]: P. Viola, M.J. Jones, D. Snow, Detecting pedestrians using patterns of motion and appearance, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Nice, France, 2003, pp. 734–741.
[38]: P.F. Felzenszwalb, D.P. Huttenlocher. Pictorial structures for object recognition. Int. J. Comput. Vis., 61 (1) (2005), pp. 55-79, 10.1023/B:VISI.0000042934.15159.49
[39]: V. Ferrari, M. Marin-Jimenez, A. Zisserman, Progressive search space reduction for human pose estimation, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Anchorage, Alaska, 2008, pp. 1–8, http://dx.doi.org/10.1109/CVPR.2008.4587468.
[40]: D. Ramanan, Learning to parse images of articulated objects, in: Advances in Neural Information Processing Systems 134 (2006).
[41]: A. Klaser, M. Marszałek, C. Schmid, A spatio-temporal descriptor based on 3d-gradients, in: Proceedings of British Machine Vision Conference (BMVC), BMVA Press, Leeds, UK. 2008, p. 275:1.
[42]: L. Wang, Y. Wang, T. Jiang, D. Zhao, W. Gao. Learning discriminative features for fast frame-based action recognition. Pattern Recognit., 46 (7) (2013), pp. 1832-1840, 10.1016/j.patcog.2012.08.016
[43]: A. Gilbert, J. Illingworth, R. Bowden, Fast realistic multi-action recognition using mined dense spatio-temporal features, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Kyoto, Japan, 2009, pp. 925–931, http://dx.doi.org/10.1109/ICCV.2009.5459335.
[44]: J. Liu, J. Luo, M. Shah, Recognizing realistic actions from videos in the wild, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Miami Beach, Florida, 2009, pp. 1996–2003.
[45]: K. Soomro, A.R. Zamir, M. Shah, Ucf101: a dataset of 101 human actions classes from videos in the wild, arXiv preprint arXiv:1212.0402.
[46]: K.K. Reddy, M. Shah. Recognizing 50 human action categories of web videos. Mach. Vis. Appl., 24 (5) (2013), pp. 971-981
[47]: J. Cho, M. Lee, H.J. Chang, S. Oh. Robust action recognition using local motion and group sparsity. Pattern Recognit., 47 (5) (2014), pp. 1813-1825, 10.1016/j.patcog.2013.12.004
[48]: L. Liu, L. Shao, F. Zheng, X. Li. Realistic action recognition via sparsely-constructed gaussian processes. Pattern Recognit., 47 (12) (2014), pp. 3819-3827, 10.1016/j.patcog.2014.07.006
[49]: M. Hoai, Z.-Z. Lan, F. De la Torre, Joint segmentation and classification of human actions in video, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Colorado Springs, 2011, pp. 3265–3272, http://dx.doi.org/10.1109/CVPR.2011.5995470.
[50]: C.-Y. Chen, K. Grauman, Efficient activity detection with max-subgraph search, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Providence, Rhode Island, 2012, pp. 1274–1281, http://dx.doi.org/10.1109/CVPR.2012.6247811.
[51]: A. Gaidon, Z. Harchaoui, C. Schmid. Temporal localization of actions with actoms. IEEE Trans. Pattern Anal. Mach. Intell., 35 (11) (2013), pp. 2782-2795, 10.1109/TPAMI.2013.65
[52]: D. Gong, G. Medioni, X. Zhao. Structured time series analysis for human action segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell., 36 (7) (2014), pp. 1414-1427, 10.1109/TPAMI.2013.244
[53]: K.N. Tran, I.A. Kakadiaris, S.K. Shah. Part-based motion descriptor image for human action recognition. Pattern Recognit., 45 (7) (2012), pp. 2562-2572, 10.1016/j.patcog.2011.12.028
[54]: W. Li, Z. Zhang, Z. Liu, Action recognition based on a bag of 3D points, in: Proceedings of Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, San Francisco, CA, USA, 2010, pp. 9–14, http://dx.doi.org/10.1109/CVPRW.2010.5543273.
[55]: S.Z. Masood, C. Ellis, M.F. Tappen, J.J. LaViola, R. Sukthankar. Exploring the trade-off between accuracy and observational latency in action recognition. Int. J. Comput. Vis., 101 (3) (2013), pp. 420-436, 10.1007/s11263-012-0550-7
[56]: J. Shotton, T. Sharp, A. Kipman, A. Fitzgibbon, M. Finocchio, A. Blake, M. Cook, R. Moore. Real-time human pose recognition in parts from single depth images. Commun. ACM, 56 (1) (2013), pp. 116-124, 10.1145/2398356.2398381
[57]: S. Litvak, Learning-based pose estimation from depth maps, US Patent 8,582,867, November 12, 2013.
[58]: L. Xia, C.-C. Chen, J. Aggarwal, View invariant human action recognition using histograms of 3D joints, in: Proceedings of Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Providence, Rhode Island, 2012, pp. 20–27, http://dx.doi.org/10.1109/CVPRW.2012.6239233.
[59]: X. Yang, Y. Tian, Eigenjoints-based action recognition using Naive-Bayes-Nearest-Neighbor, in: Proceedings of Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Providence, Rhode Island, 2012, pp. 14–19, http://dx.doi.org/10.1109/CVPRW.2012.6239232.
[60]: O. Oreifej, Z. Liu, W. Redmond, HON4D: histogram of oriented 4D normals for activity recognition from depth sequences, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), Portland, Oregon, 2013, pp. 716–723, http://dx.doi.org/10.1109/CVPR.2013.98.
[61]: A. Yao, J. Gall, G. Fanelli, L.J. Van Gool, Does human action recognition benefit from pose estimation? in: Proceedings of the British Machine Vision Conference (BMVC), vol. 3, BMVA Press, Dundee, UK, 2011, pp. 67.1–67.11, http://dx.doi.org/10.5244/C.25.67.
[62]: L. Lo Presti, M. La Cascia, S. Sclaroff, O. Camps, Gesture modeling by Hanklet-based hidden Markov model, in: D. Cremers, I. Reid, H. Saito, M.-H. Yang (Eds.), Proceedings of Asian Conference on Computer Vision (ACCV 2014), Lecture Notes in Computer Science, Springer International Publishing, Singapore, 2015, pp. 529–546, http://dx.doi.org/10.1007/978-3-319-16811-1_35.
[63]: C. Wang, Y. Wang, A.L. Yuille, An approach to pose-based action recognition, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Portland, Oregon, 2013, pp. 915–922, http://dx.doi.org/10.1109/CVPR.2013.123.
[64]: F. Ofli, R. Chaudhry, G. Kurillo, R. Vidal, R. Bajcsy. Sequence of the most informative joints (SMIJ): a new representation for human skeletal action recognition. J. Vis. Commun. Image Represent., 25 (1) (2014), pp. 24-38, 10.1016/j.jvcir.2013.04.007
[65]: R. Slama, H. Wannous, M. Daoudi, A. Srivastava. Accurate 3D action recognition using learning on the Grassmann manifold. Pattern Recognit., 48 (2) (2015), pp. 556-567, 10.1016/j.patcog.2014.08.011
[66]: L. Chen, H. Wei, J. Ferryman. A survey of human motion analysis using depth imagery. Pattern Recognit. Lett., 34 (15) (2013), pp. 1995-2006, 10.1016/j.patrec.2013.02.006
[67]: J. Aggarwal, L. Xia. Human activity recognition from 3D data: a review
Pattern Recognit. Lett., 48 (2014), pp. 70-80, 10.1016/j.patrec.2014.04.011
[68]: D. Murray, J.J. Little. Using real-time stereo vision for mobile robot navigation. Auton. Robots, 8 (2) (2000), pp. 161-171
[69]: I. Infantino, A. Chella, H. Dindo, I. Macaluso, Visual control of a robotic hand, in: Proceedings of International Conference on Intelligent Robots and Systems (IROS), vol. 2, IEEE, Las Vegas, CA, USA, 2003, pp. 1266–1271, http://dx.doi.org/10.1109/IROS.2003.1248819.
[70]: A. Chella, H. Dindo, I. Infantino, I. Macaluso. A posture sequence learning system for an anthropomorphic robotic hand. Robot. Auton. Syst., 47 (2) (2004), pp. 143-152, 10.1016/j.robot.2004.03.008
[71]: P. Henry, M. Krainin, E. Herbst, X. Ren, D. Fox, RGB-D mapping: using depth cameras for dense 3D modeling of indoor environments, in: Experimental Robotics, Springer Tracts in Advanced Robotics, vol. 79, Citeseer, Springer, Berlin, Heidelberg, 2014, pp. 477–491, http://dx.doi.org/10.1007/978-3-642-28572-1_33.
[72]: J.C. Carr, R.K. Beatson, J.B. Cherrie, T.J. Mitchell, W.R. Fright, B.C. McCallum, T.R. Evans, Reconstruction and representation of 3D objects with radial basis functions, in: Proceedings of Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), ACM, Los Angeles, CA, USA, 2001, pp. 67–76, http://dx.doi.org/10.1145/383259.383266.
[73]: V. Kolmogorov, R. Zabih, Multi-camera scene reconstruction via graph cuts, in: Proceedings of European Conference on Computer Vision (ECCV), Springer, Copenhagen, Denmark, 2002, pp. 82–96.
[74]: Microsoft kinect sensor 〈http://www.microsoft.com/en-us/kinectforwindows/〉.
[75]: E. Trucco, A. Verri, Introductory Techniques for 3-D Computer Vision, vol. 201, Prentice Hall, Englewood Cliffs, 1998.
[76]: D. Scharstein, R. Szeliski. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis., 74 (1–3) (2002), pp. 7-42
[77]: P. Fua. A parallel stereo algorithm that produces dense depth maps and preserves image features. Mach. Vis. Appl., 6 (1) (1993), pp. 35-49, 10.1007/BF01212430
[78]: S. Foix, G. Alenya, C. Torras. Lock-in time-of-flight (tof) cameras: a survey. IEEE Sens. J., 11 (9) (2011), pp. 1917-1926
[79]: D. Scharstein, R. Szeliski, High-accuracy stereo depth maps using structured light, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, IEEE, Madison, Wisconsin, 2003, p. I-195.
[80]: P. Felzenszwalb, D. McAllester, D. Ramanan, A discriminatively trained, multiscale, deformable part model, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Anchorage, Alaska, 2008, pp. 1–8, http://dx.doi.org/10.1109/CVPR.2008.4587597.
[81]: J. Shen, W. Yang, Q. Liao. Part template: 3D representation for multiview human pose estimation. Pattern Recognit., 46 (7) (2013), pp. 1920-1932, 10.1016/j.patcog.2013.01.001
[82]: M. Ye, X. Wang, R. Yang, L. Ren, M. Pollefeys, Accurate 3d pose estimation from a single depth image, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Barcelona, Spain, 2011, pp. 731–738.
[83]: M.A. Fischler, R.A. Elschlager. The representation and matching of pictorial structures. IEEE Trans. Comput., 22 (1) (1973), pp. 67-92, 10.1109/T-C.1973.223602
[84]: M. W. Lee, I. Cohen, Proposal maps driven MCMC for estimating human body pose in static images, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, IEEE, Washington, DC, 2004, p. II-334.
[85]: G. Mori, X. Ren, A.A. Efros, J. Malik, Recovering human body configurations: combining segmentation and recognition, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, IEEE, Washington, DC, 2004, p. II-326.
[86]: X. Ren, A. C. Berg, J. Malik, Recovering human body configurations using pairwise constraints between parts, in: Proceedings of International Conference on Computer Vision (ICCV), vol. 1, IEEE, Beijing, P.R. China, 2005, pp. 824–831.
[87]: T.-P. Tian, S. Sclaroff, Fast globally optimal 2d human detection with loopy graph models, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, San Francisco, CA, USA, 2010, pp. 81–88.
[88]: B. Sapp, A. Toshev, B. Taskar, Cascaded models for articulated pose estimation, in: Proceedings of European Conference on Computer Vision (ECCV), Springer, Crete, Greece, 2010, pp. 406–420.
[89]: Y. Wang, D. Tran, Z. Liao, Learning hierarchical poselets for human parsing, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Colorado Springs, 2011, pp. 1705–1712.
[90]: M.P. Kumar, A. Zisserman, P.H. Torr, Efficient discriminative learning of parts-based models, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Kyoto, Japan, 2009, pp. 552–559.
[91]: S.S. SDK, Openni 2, openNI 2 SDK Binaries 〈http://structure.io/openni〉, 2014.
[92]: M. Gleicher, Retargetting motion to new characters, in: Proceedings of Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), ACM, Orlando, Florida, USA, 1998, pp. 33–42, http://dx.doi.org/10.1145/280814.280820.
[93]: C. Hecker, B. Raabe, R.W. Enslow, J. DeWeese, J. Maynard, K. van Prooijen. Real-time motion retargeting to highly varied user-created morphologies. ACM Trans. Graph., 27 (3) (2008), p. 27, 10.1145/1399504.1360626
[94]: M. Gleicher. Comparing constraint-based motion editing methods
Graph. Models, 63 (2) (2001), pp. 107-134, 10.1006/gmod.2001.0549
[95]: R. Kulpa, F. Multon, B. Arnaldi. Morphology-independent representation of motions for interactive human-like animation. Comput. Graph. Forum, 24 (3) (2005), pp. 343-351, 10.1111/j.1467-8659.2005.00859.x
[96]: P. Baerlocher, R. Boulic. An inverse kinematics architecture enforcing an arbitrary number of strict priority levels. Vis. Comput., 20 (6) (2004), pp. 402-417, 10.1007/s00371-004-0244-4
[97]: P. Wei, N. Zheng, Y. Zhao, S.-C. Zhu, Concurrent action detection with structural prediction, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Sydney, Australia, 2013, pp. 3136–3143.
[98]: D. Wu, L. Shao, Leveraging hierarchical parametric networks for skeletal joints based action segmentation and recognition, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Columbus, Ohio. 2014, pp. 724–731.
[99]: R. Chaudhry, F. Ofli, G. Kurillo, R. Bajcsy, R. Vidal, Bio-inspired dynamic 3D discriminative skeletal features for human action recognition, in: Proceedings of Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), IEEE, Portland, Oregon, 2013, pp. 471–478, http://dx.doi.org/10.1109/CVPRW.2013.153.
[100]: M.E. Hussein, M. Torki, M.A. Gowayyed, M. El-Saban, Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations, in: Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), AAAI Press, Beijing, P.R. China, 2013, pp. 2466–2472.
[101]: M. Zanfir, M. Leordeanu, C. Sminchisescu, The moving pose: an efficient 3d kinematics descriptor for low-latency action recognition and detection, in: Proceedings of International Conference on Computer Vision (ICCV), IEEE, Sydney, Australia, 2013, pp. 2752–2759.
[102]: T. Kerola, N. Inoue, K. Shinoda, Spectral graph skeletons for 3D action recognition, in: Proceedings of Asian Conference on Computer Vision (ACCV), Springer, Singapore, 2014, pp. 1–16.
[103]: A. Eweiwi, M.S. Cheema, C. Bauckhage, J. Gall, Efficient pose-based action recognition, in: Proceedings of Asian Conference on Computer Vision (ACCV), Springer, Singapore, 2014, pp. 1–16.
[104]: A.A. Chaaraoui, J.R. Padilla-López, F. Flórez-Revuelta, Fusion of skeletal and silhouette-based features for human action recognition with RGB-D devices, in: Proceedings of International Conference on Computer Vision Workshops (ICCVW), IEEE, Sydney, Australia, 2013, pp. 91–97, http://dx.doi.org/10.1109/ICCVW.2013.19.
[105]: M. Devanne, H. Wannous, S. Berretti, P. Pala, M. Daoudi, A. Del Bimbo, Space–time pose representation for 3D human action recognition, in: Proceedings of the International Conference on Image Analysis and Processing (ICIAP), Springer, Naples, Italy, 2013, pp. 456–464, http://dx.doi.org/10.1007/978-3-642-41190-849.
[106]: D.K. Hammond, P. Vandergheynst, R. Gribonval. Wavelets on graphs via spectral graph theory. Appl. Comput. Harmon. Anal., 30 (2) (2011), pp. 129-150
[107]: E.P. Ijjina, C.K. Mohan, Human action recognition based on MOCAP information using convolution neural networks, in: Proceedings of International Conference on Machine Learning and Applications (ICMLA), IEEE, Detroit Michigan, 2014, pp. 159–164, http://dx.doi.org/10.1109/ICMLA.2014.30.
[108]: M. Müller, T. Röder, M. Clausen. Efficient content-based retrieval of motion capture data. ACM Trans. Graph., 24 (3) (2005), pp. 677-685, 10.1145/1186822.1073247
[109]: G. Evangelidis, G. Singh, R. Horaud, et al., Skeletal quads: human action recognition using joint quadruples, in: Proceedings of International Conference on Pattern Recognition (ICPR), IEEE, Stockholm, Sweden, 2014, pp. 4513–4518, http://dx.doi.org/10.1109/ICPR.2014.772.
[110]: T. Jaakkola, D. Haussler, et al., Exploiting generative models in discriminative classifiers, in: Advances in Neural Information Processing Systems, 1999, pp. 487–493.
[111]: J.E. Humphreys, Introduction to Lie Algebras and Representation Theory, vol. 9, Springer Science & Business Media, New York, 1972.
[112]: J. Wang, Z. Liu, Y. Wu, J. Yuan, Mining actionlet ensemble for action recognition with depth cameras, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Providence, Rhode Island, 2012, pp. 1290–1297, http://dx.doi.org/10.1109/CVPR.2012.6247813.
[113]: Z. Shao, Y. Li. Integral invariants for space motion trajectory matching and recognition. Pattern Recognit., 48 (8) (2015), pp. 2418-2432, 10.1016/j.patcog.2015.02.029
[114]: M. Devanne, H. Wannous, S. Berretti, P. Pala, M. Daoudi, A. Del Bimbo
3-D human action recognition by shape analysis of motion trajectories on Riemannian manifold. IEEE Trans. Cybern., 45 (7) (2015), pp. 1340-1352
[115]: M. Barnachon, S. Bouakaz, B. Boufama, E. Guillou. Ongoing human action recognition with motion capture. Pattern Recognit., 47 (1) (2014), pp. 238-247, 10.1016/j.patcog.2013.06.020
[116]: I. Lillo, A. Soto, J.C. Niebles, Discriminative hierarchical modeling of spatio-temporally composable human activities, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Columbus, Ohio. 2014, pp. 812–819.
[117]: L. Miranda, T. Vieira, D. Martínez, T. Lewiner, A.W. Vieira, M.F. Campos
Online gesture recognition from pose kernel learning and decision forests
Pattern Recognit. Lett., 39 (2014), pp. 65-73
[118]: M. Raptis, D. Kirovski, H. Hoppe, Real-time classification of dance gestures from skeleton animation, in: Proceedings of the 2011 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, ACM, Hong Kong, 2011, pp. 147–156.
[119]: M. Barker, W. Rayens. Partial least squares for discrimination. J. Chemom., 17 (3) (2003), pp. 166-173
[120]: R. Rosipal, L.J. Trejo. Kernel partial least squares regression in reproducing kernel Hilbert space. J. Mach. Learn. Res., 2 (2002), pp. 97-123
[121]: P. Climent-Pérez, A.A. Chaaraoui, J.R. Padilla-López, F. Flórez-Revuelta, Optimal joint selection for skeletal data from rgb-d devices using a genetic algorithm, in: Advances in Computational Intelligence, Springer, Tenerife - Puerto de la Cruz, Spain, 2013, pp. 163–174, http://dx.doi.org/10.1007/978-3-642-37798-3_15.
[122]: G. Dong, J. Li, Efficient mining of emerging patterns: discovering trends and differences, in: Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, San Diego, CA, USA, 1999, pp. 43–52.
[123]: F.R. Bach, G.R. Lanckriet, M.I. Jordan, Multiple kernel learning, conic duality, and the SMO algorithm, in: Proceedings of International Conference on Machine Learning (ICML), ACM, Alberta, Canada, 2004, p. 6.
[124]: L. Seidenari, V. Varano, S. Berretti, A. Del Bimbo, P. Pala, Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses, in: Proceedings of Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Portland, Oregon, 2013, pp. 479–485.
[125]: L. Lo Presti, M. La Cascia, S. Sclaroff, O. Camps, Hankelet-based dynamical systems modeling for 3D action recognition, in: Image and Vision Computing, Elsevier, 44 (2015), 29–43, http://dx.doi.org/10.1016/j.imavis.2015.09.007 〈http://www.sciencedirect.com/science/article/pii/S02628%85615001134〉.
[126]: B. Li, O.I. Camps, M. Sznaier, Cross-view activity recognition using Hankelets, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Providence, Rhode Island, 2012, pp. 1362–1369, http://dx.doi.org/10.1109/CVPR.2012.6247822.
[127]: B. Li, M. Ayazoglu, T. Mao, O.I. Camps, M. Sznaier, Activity recognition using dynamic subspace angles, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Colorado Springs, 2011, pp. 3193–3200, http://dx.doi.org/10.1109/CVPR.2011.5995672.
[128]: A.M. Lehrmann, P.V. Gehler, S. Nowozin, Efficient nonlinear Markov models for human motion, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Columbus, Ohio. 2014, pp. 1314–1321.
[129]: C. Meek, D.M. Chickering, D. Heckerman, Autoregressive tree models for time-series analysis, in: Proceedings of the Second International SIAM Conference on Data Mining, SIAM, Toronto, Canada, 2002, pp. 229–244.
[130]: N. Raman, S.J. Maybank, Action classification using a discriminative multilevel HDP-HMM, Neurocomputing 154 (2015): 149-161
[131]: J. Sung, C. Ponce, B. Selman, A. Saxena, Unstructured human activity detection from RGBD images, in: Proceedings of International Conference on Robotics and Automation (ICRA), IEEE, St. Paul, Minnesota, 2012, pp. 842–849, http://dx.doi.org/10.1109/ICRA.2012.6224591.
[132]: J. Wang, Z. Liu, J. Chorowski, Z. Chen, Y. Wu, Robust 3D action recognition with Random Occupancy Patterns, in: Proceedings of European Conference on Computer Vision (ECCV), Springer, Florence, Italy, 2012, pp. 872–885, http://dx.doi.org/10.1007/978-3-642-33709-362.
[133]: A.W. Vieira, E.R. Nascimento, G.L. Oliveira, Z. Liu, M.F. Campos, STOP: space–time occupancy patterns for 3D action recognition from depth map sequences, Prog. Pattern Recognit. Image Anal. Comput. Vis. Appl. (2012) 252–259, http://dx.doi.org/10.1007/978-3-642-33275-331.
[134]: H. Rahmani, A. Mahmood, D.Q. Huynh, A. Mian, Hopc: histogram of oriented principal components of 3d pointclouds for action recognition, in: Proceedings of European Conference on Computer Vision (ECCV), Springer, Zurich, 2014, pp. 742–757.
[135]: E. Ohn-Bar, M.M. Trivedi, Joint angles similarities and HOG2 for action recognition, in: Proceedings of Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Portland, Oregon, 2013, pp. 465–470, http://dx.doi.org/10.1109/CVPRW.2013.76.
[136]: L. Xia, J. Aggarwal, Spatio-temporal depth cuboid similarity feature for activity recognition using depth camera, in: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Portland, Oregon, 2013, pp. 2834–2841.
[137]: Y. Zhu, W. Chen, G. Guo, Fusing spatiotemporal features and joints for 3D action recognition, in: Proceedings of Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Portland, Oregon, 2013, pp. 486–491, http://dx.doi.org/10.1109/CVPRW.2013.78.
[138]: I. Laptev. On space–time interest points. Int. J. Comput. Vis., 64 (2) (2005), pp. 107-123, 10.1007/s11263-005-1838-7
[139]: S. Althloothi, M.H. Mahoor, X. Zhang, R.M. Voyles. Human activity recognition using multi-features and multiple kernel learning. Pattern Recognit., 47 (5) (2014), pp. 1800-1812
[140]: J. Wang, Y. Wu, Learning maximum margin temporal warping for action recognition, in: 2013 IEEE International Conference on Computer Vision (ICCV), IEEE, Sydney, Australia, 2013, pp. 2688–2695.
[141]: C. Chen, R. Jafari, N. Kehtarnavaz. Improving human action recognition using fusion of depth camera and inertial sensors. IEEE Trans. Hum.-Mach. Syst., 45 (1) (2015), pp. 51-61, 10.1109/THMS.2014.2362520
[142]: A.F. Bobick, J.W. Davis. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell., 23 (3) (2001), pp. 257-267
[143]: H.M. Hondori, M. Khademi, C.V. Lopes, Monitoring intake gestures using sensor fusion (microsoft kinect and inertial sensors) for smart home tele-rehab setting, in: 1st Annual IEEE Healthcare Innovation Conference, IEEE, Houston, TX, 2012, pp. 1–4.
[144]: B. Delachaux, J. Rebetez, A. Perez-Uribe, H.F.S. Mejia, Indoor activity recognition by combining one-vs.-all neural network classifiers exploiting wearable and depth sensors, in: Advances in Computational Intelligence. Lecture Notes in Computer Science, Springer, Tenerife - Puerto de la Cruz, Spain, 7903 (2013), pp. 216–223.
[145]: K. Liu, C. Chen, R. Jafari, N. Kehtarnavaz. Fusion of inertial and depth sensor data for robust hand gesture recognition. IEEE Sens. J., 14 (6) (2014), pp. 1898-1903
[146]: S. Hadfield, R. Bowden, Hollywood 3d: recognizing actions in 3d natural scenes, in: 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Portland, Oregon, 2013, pp. 3398–3405.
[147]: C. Ionescu, D. Papava, V. Olaru, C. Sminchisescu. Human3. 6m: large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell., 36 (7) (2014), pp. 1325-1339
[148]: F. Ofli, R. Chaudhry, G. Kurillo, R. Vidal, R. Bajcsy, Berkeley MHAD: a comprehensive multimodal human action database, in: Proceedings of Workshop on Applications of Computer Vision (WACV), IEEE, Clearwater Beach Florida, 2013, pp. 53–60.
[149]: J.R. Padilla-López, A.A. Chaaraoui, F. Flórez-Revuelta, A discussion on the validation tests employed to compare human action recognition methods using the MSR Action 3D dataset, CoRR abs/1407.7390.arXiv:1407.7390.
[150]: J. Sung, C. Ponce, B. Selman, A. Saxena, Human activity detection from RGBD images, in: AAAI Workshops on Plan, Activity, and Intent Recognition, San Francisco, CA, USA, vol. 64, 2011, pp. 1–8.
[151]: S. Fothergill, H.M. Mentis, P. Kohli, S. Nowozin, Instructing people for training gestural interactive systems, in: J.A. Konstan, E.H. Chi, K. Höök (Eds.), Proceedings of ACM Conference on Human Factors in Computing Systems (CHI), ACM, Austin Texas, 2012, pp. 1737–1746, http://dx.doi.org/10.1145/2207676.2208303.
[152]: A. Malizia, A. Bellucci. The artificiality of natural user interfaces. Commun. ACM, 55 (3) (2012), pp. 36-38