【飞桨PaddlePaddle学习心得】day5大作业详细指南【源码+教程精讲】
写在前面:
大作业不难,但是涉及到的技术稍微多一点,请对于各个函数耐心查看代码和注释,认真食用。(因为用心,所有动人)
作业内容&要求
-
第一步:爱奇艺《青春有你2》评论数据爬取(参考链接:https://www.iqiyi.com/v_19ryfkiv8w.html#curid=15068699100_9f9bab7e0d1e30c494622af777f4ba39)
爬取任意一期正片视频下评论
评论条数不少于1000条 -
第二步:词频统计并可视化展示
数据预处理:清理清洗评论中特殊字符(如:@#¥%、emoji表情符),清洗后结果存储为txt文档
中文分词:添加新增词(如:青你、奥利给、冲鸭),去除停用词(如:哦、因此、不然、也好、但是) -
第三步:统计top10高频词并展示绘制词云
统计top10高频词
可视化展示高频词
根据词频生成词云
可选项-添加背景图片,根据背景图片轮廓生成词云 -
第四步:结合PaddleHub,对评论进行内容审核
需要的配置和准备
- 中文分词需要jieba
- 词云绘制需要wordclou
- 可视化展示中需要的中文字体 (./source/simhei.ttf)
- 网上公开资源中找一个中文停用词表 (./source/stopWords.txt)
- 根据分词结果自己制作新增词表 (./source/addWords.txt)
- 准备一张词云背景图(附加项,不做要求,可用hub抠图实现)(./source/bg.jpg)图片尽量使用白色背景或者透明背景
- paddlehub配置
本次的所有资源文件和生成的文件都会放到当前路径的source包下面。
在开始之前再次将matplotlib的显示中文的坑整理一下:
1.确保系统的.font文件下面有中文字体(这里假设中文字体就是simhei.ttf)如果不懂可以忽略这一条,直接跳到2。
# Linux系统默认字体文件路径
!ls /usr/share/fonts/
#查看系统可用的ttf格式中文字体
!fc-list :lang=zh | grep ".ttf"
2.要想matplotlib显示中文需要做到两点
2.1系统的font里面有simhei.ttf
2.2matpltlib的mpl-data/fonts/ttf/下面也需要有这个字体
第一点不多说,对于第二点,可以使用如下命令
cp ./resource/simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
然后只要在调用matplotlib的时候 设置一下字体就行了,使用如下命令
# 设置显示中文
matplotlib.rcParams['font.family'] = ['SimHei']
# 解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
findfont: Font family [‘sans-serif’] not found. Falling back to Bitstream Vera Sans
可能经过上面的设置后还是会出现这样的错误。解决方法如下:
在mac系统下面:
删除系统根目录下面的matplotlib的隐藏文件(里面的缓存文件)即可
rm -r ~/.matplotlib
在windows系统下面:
删除系统根目录下的.cache/matplotlib目录
rm -r .cache/matplotlib
在aistudio平台:
同样删除.cache/matplotlib目录就行了。
如果经过上诉步骤还不行的话,可以重启服务器或者电脑。
经过上面的准备,下面将正式进去整体,请打开你的pycharm(sublime text也是可以的哟嘻嘻)
导入需要用到的python包
from __future__ import print_function
import requests
import json
import re #正则匹配
import time #时间处理模块
import jieba #中文分词
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
from PIL import Image
from wordcloud import WordCloud #绘制词云模块
import paddlehub as hub
import pandas as pd
一、评论爬取
这次的评论爬去其实就是一个对评论接口的调用。唯一的难度就在于如何找到接口的地址。
方法如下:
- 先根据前面的参考链接,打开爱奇艺青春2的视频页面。
- 下滑页面找到全部评论模块,如下图的地方
- 然后按键盘的F12或者鼠标右键检查打开控制台,找到Network选项,并选中下面的JS

- 等待页面加载一段时间(半分钟一分钟吧)等到目前页面的资源都加载完成后,将页面拉去到最下面的查看更多评论地方。此时现将控制台中的clear点击一下,因为里面加载的资源很多,我们先清空一下里面的所有内容。
 5. 然后“查看更多评论”,可以发现在控制台出现了一个名为get_comments.action的js请求。我们只要打开这个请求就可以看到评论的接口url。
5. 然后“查看更多评论”,可以发现在控制台出现了一个名为get_comments.action的js请求。我们只要打开这个请求就可以看到评论的接口url。
接口参数分析
# url = 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?' \
# 'agent_type=118' \
# '&agent_version=9.11.5' \
# '&business_type=17' \
# '&content_id=15068699100' \
# '&hot_size=10' \
# '&last_id=' \ 根据last_id来确定这一页应该从哪一个评论开始拉去
# '&page=' \
# '&page_size=10' \一次拉去的评论有多少条,最多不超过40条
# '&types=hot,time' \
# '&callback=jsonp_1587883768795_67783'
Function1:
def getComment(lastId):
'''
请求爱奇艺评论接口,返回response信息
参数 lastId: 前10条评论的最后一条的用户的id
:return: 字典格式的response信息
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url = 'http://sns-comment.iqiyi.com/v3/comment/get_comments.action?'
params = {
'types': 'time',
'business_type': '17',
'agent_type': '118',
'agent_version': '9.11.5',
'content_id': '15068699100',
'page_size' : '10'
}
if lastId != '':#判断lastId是否为空,如果不为空就在url中拼接上lastId的值
params["last_id"] = lastId
for item in params: #将params里面的值全部拼接到url中
url = url + item + '=' + params[item] + '&'
try:
#根据前面拼接的url使用python的request模块爬去评论
response = requests.get(url, headers=headers)
print(response.status_code)
#评论返回的是json类型的字符串,这里将其使用json.loads解析为python的字典返回
return json.loads(response.text)
except Exception as e:
print(e)
Function2:
def saveCommentToFile():
#是出货lastId为空,以为第一个10条数据不需要lastId
lastId = ''
response = getComment(lastId)#调用function1的函数,获取到前10条的评论
#将获取的评论中的comments里面的内容提取出来,comments是一个列表,长度为10,也就是我们10条评论的所有内容
comment_list = response['data']['comments']
#然后开始获取第一次爬去的10条评论的最后一个用户的id,然后根据lastId去爬取新的10条评论
lastId = comment_list[-1]['id']
while len(comment_list)<2000:#总共预计爬去2000条评论
response = getComment(lastId)
try:
comments = response['data']['comments']
for i in comments:
comment_list.append(i)
lastId = comment_list[-1]['id']
print(comment_list[-1]['content'])
except Exception as e:
print(e)
#将包含2000条评论数据的数据写入到./resource/day5.json文件中
with open('./resource/day5.json', 'w', encoding='UTF-8') as f:
json.dump(comment_list, f, ensure_ascii=False)
print(len(comment_list))
return
通过调用saveCommentToFile函数,即可实现第一步的爬去爱奇艺青春2正片下的2000条评论。把day5.json打开可以发现里面的数据格式如下图所示:

二、统计词频并可视化展示
在这个环节我们需要将前面爬去的每一条评论先使用jieba进行分词,然后再进行词频的统计。要实现这个功能需要进过以下4步骤:
- 先对每条评论使用正则表达式去除特殊字符,以免影响后面的分词效果
- 给jieba添加新增词表(./source/addWord.txt)(主要包括青春109位选手的姓名和一些心得网络词汇),并使用jieba.cut()对每条评论进行分词
- 对经过2分词后的每个评论词汇根据停用词表删除常用停用词。(./source/stopWords.txt)(停用词表博主是在github随便找的一个停用词,建议自己github搜索以下就能找到。也可以下载使用博主提供的)
- 将经过上诉处理后的短语写入到文档(./source/day5.txt)
Function1
def clear_special_char(s):
'''
正则处理特殊字符
参数 s:原文本
return s: 去除特殊字符后的文本
'''
s = re.sub(r"| |\t|\r","",s)
s = re.sub(r"\n","",s)
s = re.sub(r"\*","\\*",s)
s = re.sub("[^\u4e00-\u9fa5^a-z^A-Z^0-9]","",s)
s = re.sub("[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+","", s)
s = re.sub("[a-zA-Z]","",s)
s = re.sub("^d+(\.\d+)?$","",s)
return s
Function2:
def stopwordslist():
'''
将停用词表中的所有词汇读入到内存中,即使放入到一个list变量中存储以备使用
参数 file_path:停用词文本路径
return:停用词list
'''
file_path = './source/stopWords.txt'
stopwords_list = []
with open(file_path,'r') as f:
for line in f.readlines():
stopwords_list.append(line)
return stopwords_list
Function3
def fenci(text):
'''
利用jieba进行分词 并删除停用词 一次只能处理一条评论
参数 text:需要分词的句子
return:分词结果 list
'''
jieba.load_userdict('./source/addWords.txt')#加载新增词到jieba
seg_list = jieba.cut(text, cut_all=False)
liststr = "/ ".join(seg_list) #将单词使用‘/’链接起来,以便后面再次分开
mywordlist = []
stopwords_list = stopwordslist() #调用funciton1 获取内存中的通用词list
#删除停止词
for myword in liststr.split('/'):
if (myword.strip() not in stopwords_list) and len(myword.strip()) > 1:
mywordlist.append(myword.strip())
return mywordlist
Function4
def writeToTxt():
'''
遍历一中爬取保存的json数据中的所有评论,并逐个将每一条评论进行分词操作
:return:
'''
with open('./source/day5.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
content_list = []
for contents in json_array:
try:
text = contents['content']
#移除特殊字符
text = clear_special_char(text)
#在分词的函数中 包含了对分文的分词和删除停止词操作
text_fenci_list = fenci(text)
for text_fenci in text_fenci_list:
#将清洗好并分好词的list遍历,将其中的每个短语添加到content_list里面
content_list.append(text_fenci)
except Exception as e:
print(e)
print(len(content_list))
with open('./source/day5.txt','a') as f:
for i in content_list:
try:
f.write(i+'\n')
except Exception as e:
print(e)
通过调用writeToTxt函数就可以实现将一中的评论数据进行数据清理后进行分词了。
三、统计top10高频词并展示绘制词云
- 现将第二步中保存的day5.txt中的所有词汇读取到一个list中
- 使用pandas中的value_counts函数轻松实现词频统计
- 将top10的单词和词频绘制到直方图中
- 将根据2得到的词频生成词云图
Function1
def countwordsfre():
'''
统计day5.txt中的词频
return:每个单词和对于的词频 返回的是一个Series数据结构 类似字典可以通过键值访问
'''
fenciwordlist = []
try:
with open('./source/day5.txt','r') as f:
for line in f.readlines():
fenciwordlist.append(line.strip())
except Exception as e:
print(e)
return pd.value_counts(fenciwordlist)#使用pandas的value_counts函数统计词频
Function2
def drawcounts(counts,topN=10):
'''
绘制词频统计表 top1o
参数 counts: 词频统计结果 num:绘制topN
return:none
'''
x = list(counts.index)#得到单词列表
x= x[:topN]#截取前10个单词
y = counts.values#得到词频列表
y = y[:topN]#得到前10的词频列表
# 设置显示中文
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(5, 3))
#根据x和y画条形图
plt.bar(range(len(y)), y, color='r', tick_label=x, facecolor='#9999ff', edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45, fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''爱奇艺《青春有你2》评论Top10词频''', fontsize=24)
plt.savefig('./source/bar_result.jpg')
plt.show()
return
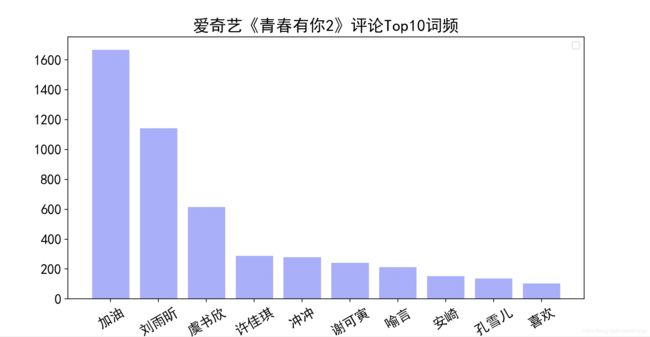
调用drawcounts函数即可生成top10词频的直方图
Top10词频直方图结果战术:
Function3
注意词云的背景图可能选择纯色背景
def drawcloud(words,img_path='./source/bg.jpg'):
'''
根据词频绘制词云图
参数 words:统计出的词频结果
return:none
'''
y = words.values
text = [i for i in y]
#get color 下面的两行代码是根据背景图片的颜色来在plt中显示图片中文字的颜色
alice_coloring = np.array(Image.open(img_path))
image_colors = ImageColorGenerator(alice_coloring)
# get mask
my_mask = np.array(Image.open(img_path))
# set wordcloud
my_wordcloud = WordCloud(
font_path='./source/simhei.ttf',
background_color="white",
max_words=100,
width=600,
height=600,
mask=my_mask,
)
# words must be dict
my_wordcloud.generate_from_frequencies(words)
my_wordcloud.to_file('./source/parrot_result.jpg')
# 显示图像
plt.imshow(my_wordcloud.recolor(color_func=image_colors), interpolation='bilinear')
# interpolation='bilinear' 表示插值方法为双线性插值
plt.axis("off") # 关掉图像的坐标
plt.show()
调用drawcloud函数即可生成词云图
词云效果对比图:
四 结合PaddleHub,对评论进行内容审核
主要是使用paddlehub预训练的senta_bilstm模型对句子进行情感分析,将其中是积极语言的置信度大于0.5的评论输出。其中唯一要注意的就是paddlehub模型对于要传入的数据必须是一个字典,字典的key为text,value为一个list。
def text_detection():
'''
使用hub对评论进行内容分析
result:分析结果
'''
#使用paddlehub加载senta_bilstm模型
senta = hub.Module(name='senta_bilstm', version='1.0.0')
#从1中得到的day5.json中获取所有评论的list
with open('./source/day5.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
content_list = []
for contents in json_array:
try:
text = contents['content']
#移除特殊字符
text = clear_special_char(text)
content_list.append(text)
except:
pass
#组建符合要求的data字典数据,然后遍历评论列表,对每条评论单独
for i in content_list:
text_list = []
text_list.append(i)
input_dict = {"text": text_list}
res = senta.sentiment_classify(data=input_dict)
if float(res[0]['positive_probs']) > 0.5:
print(i)
print(res[0]['positive_probs'])
最后调用函数即可实现对所有评论的情感分析,并输出其中的积极评论与评分。
