Linux内核——进程管理与调度
原文地址:
调度:https
文章目录
- 1.进程管理
- 1.1 进程描述符及任务结构
- 1.1.1 task_struct 重要成员说明
- 1.1.2 thread_info 与 内核栈
- 1.1.2.1 内核栈
- 1.1.2.2 thread_info
- 1.2 0号进程
- 1.3 init进程:1号进程
- 1.4 kthread进程:2号进程
- 1.5 进程创建
- 1.5.1 fork特性:写时复制
- 1.6 同一进程用户态和内核态切换
- 1.7 进程终止
- 1.8 孤儿进程问题
- 1.9 僵尸进程
- 2. 进程调度
- 2.1 进程的分类
- 2.2 不同进程采用不同的调度策略
- 2.3 linux调度器的演变
- 2.4 Linux的调度器分类
- 2.5 6种调度策略
- 2.6 5个调度器类
- 2.7 3个调度实体 与 调度器类的就绪队列
- 2.8 调度器整体框架与schedule函数
- 2.8.1 schedule函数
- 2.9 进程调度的时机和上下文切换
- 2.9.1 **进程调度的时机:**
- 2.9.2 **进程上下文切换**
- 2.10 睡眠
- 附录
- 附录一:task_struct结构(linux 2.6)
1.进程管理
1.1 进程描述符及任务结构
进程存放在叫做任务队列(tasklist)的双向循环链表中。链表中的每一项包括一个详细进程的全部信息,类型为task_struct,称为进程描写叙述符(process descriptor),该结构定义在
Linux通过slab分配器分配task_struct结构,这样能达到对象复用和缓存着色(cache coloring)的目的 。还有一方面,为了避免使用额外的寄存器存储专门记录,让像x86这样寄存器较少的硬件体系结构仅仅要通过栈指针就能计算出task_struct的位置,该结构为thread_info,在文件
Linux中能够用ps命令查看全部进程的信息。
1.1.1 task_struct 重要成员说明
(1)基本信息
- volatile long state :进程的运行状态;如running,stopped,dead,waking,interruptible, uninterruptile;
- pid_t pid : 进程的唯一标识。注意,一个task_struct代表一个进程。但是一个进程可能拥有多个pid号(建立了不同的命名空间的化,但是一个命名空间下,所有的pid唯一。在不同的命令空间下,同一个task_struct D的pid 之间建立了相关映射)
- id_t tgid : 线程组的领头线程的pid成员的值
- unsigned int flags :进程标识,标识进程的某一特殊状态。如flags=0x00000002 表示进程正在被创建; 0x00000800 表示在分配内存中;0x00010000 :被系统冻结;
(2)进程之间的亲属关系
- struct task_struct *real_parent : 指向其父进程,fork它出来的那个进程;
- struct task_struct *parent :指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与 real_parent相同。当read_parent dead后,进程托管到init进程,则parent指向init。另外,当进程被ptrace时,parent 是跟踪(trace)自己的进程;
- struct list_head children :表示链表的头部,链表中的所有元素都是它的子进程(进程的子进程链表)。
- struct list_head sibling : 用于把当前进程插入到兄弟链表中(进程的兄弟链表)。
- struct task_struct *group_leader :指向其所在进程组的领头进程。
(3)进程调度信息
| 成员类型与成员变量 | 描述 |
|---|---|
| int prio | prio用于保存动态优先级 ; |
| int normal_prio | 取决于静态优先级和调度策略(进程的调度策略有:先来先服务,短作业优先、时间片轮转、高响应比优先等等的调度算法) |
| int static_prio | 用于保存静态优先级,可以通过nice系统调用来进行修改; int static_prio:用于保存静态优先级,可以通过nice系统调用来进行修改; |
| const struct sched_class *sched_class | 该进程所属的调度类 |
| struct sched_entity se | 调度器不限于调度进程,还可以处理更大的实体,这可以实现"组调度",可用的CPU时间可以首先在一般的进程组(例如所有进程可以按所有者分组)之间分配,接下来分配的时间在组内再次分配。这种一般性要求调度器不直接操作进程,而是处理"可调度实体",一个实体有sched_entity的一个实例标识。在最简单的情况下,调度在各个进程上执行,由于调度器设计为处理可调度的实体,在调度器看来各个进程也必须也像这样的实体,因此se在task_struct中内嵌了一个sched_entity实例,调度器可据此操作各个task_struct |
| unsigned int rt_priority | 用于保存实时优先级 |
| struct sched_rt_entity rt | 用于实时进程的调用实体 |
| unsigned int policy | 表示进程的调度策略,目前主要有以下五种:按照优先级进行调度(SCHED_NORMAL)、先进先出的调度算法( SCHED_FIFO)、时间片轮转的调度算法(SCHED_RR)、用于非交互的处理机消耗型的进程(sched_batch)、系统负载很低时的调度算法(sched_idle) |
(4) 信号
| 成员类型与成员变量 | 描述 |
|---|---|
| struct signal_struct *signal | 指向进程信号描述符 |
| struct sighand_struct *sighand | 指向进程信号处理程序描述符 |
| sigset_t saved_sigmask | 当set_restore_sigmask被调用时,用于恢复之前的值 |
| struct sigpending pending | 进程上还需要处理的信号 |
| unsigned long sas_ss_sp | 信号处理程序备用堆栈的地址 |
| size_t sas_ss_size | 信号处理程序的堆栈的地址 |
(5)文件、内存
| 成员类型与成员变量 | 描述 |
|---|---|
| struct fs_struct *fs | 文件系统的信息的指针 |
| struct files_struct *files | 打开文件的信息指针 |
| struct mm_struct *mm | 进程内存管理信息 |
| struct mm_struct *active_mm | active_mm指向进程运行时所使用的内存描述符。对于普通进程而言,这两个指针变量的值相同。但是,内核线程不拥有任何内存描述符,所以它们的mm成员总是为NULL。当内核线程得以运行时,它的active_mm成员被初始化为前一个运行进程的active_mm值 |
(6)其他
| 成员类型与成员变量 | 描述 |
|---|---|
| mm_segment_t addr_limit | 进程地址空间,内核进程与普通进程在内存存放的位置不同 |
| struct task_struct *next_task, *prev_task | 于将系统中所有的进程连成一个双向循环链表, 其根是init_task |
| struct list_head thread_group | 线程链表 |
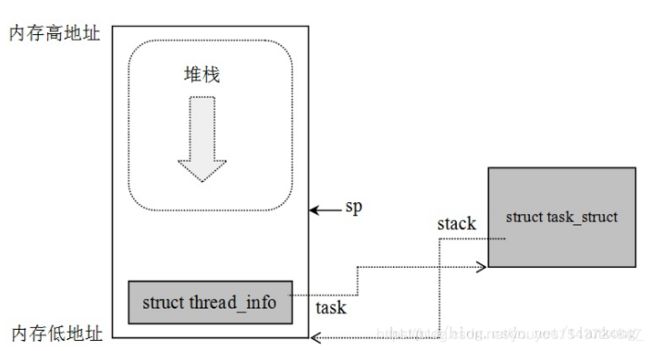
| void *stack | 进程内核栈,进程通过alloc_thread_info函数分配它的内核栈,通过free_thread_info函数释放所分配的内核栈 |
| struct nsproxy *nsproxy | 命名空间 |
1.1.2 thread_info 与 内核栈
1.1.2.1 内核栈
进程在内核态运行时需要自己的堆栈信息, 因此linux内核为每个进程都提供了一个内核栈kernel stack。
内核态的进程访问处于内核数据段的栈,这个栈不同于用户态的进程所用的栈。
用户态进程所用的栈,是在进程线性地址空间中
而内核栈是当进程从用户空间进入内核空间时,特权级发生变化,需要切换堆栈,那么内核空间中使用的就是这个内核栈。因为内核控制路径使用很少的栈空间,所以只需要几千个字节的内核态堆栈。
1.1.2.2 thread_info
内核还需要存储每个进程的PCB信息, linux内核是支持不同体系的的, 但是不同的体系结构可能进程需要存储的信息不尽相同, 这就需要我们实现一种通用的方式, 我们将体系结构相关的部分和无关的部门进行分离
用一种通用的方式来描述进程, 这就是struct task_struct, 而thread_info就保存了特定体系结构的汇编代码段需要访问的那部分进程的数据,我们在thread_info中嵌入指向task_struct的指针, 则我们可以很方便的通过thread_info来查找task_struct
linux将内核栈和进程控制块thread_info融合在一起, 组成一个联合体thread_union
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
task_struct数据结构中的stack成员(void* 类型,通过类型转化访问)指向thread_union结构(Linux内核通过thread_union联合体来表示进程的内核栈)
struct thread_info {
struct pcb_struct pcb; /* palcode state */
struct task_struct *task; /* main task structure */ /*这里很重要,task指针指向的是所创建的进程的struct task_struct
unsigned int flags; /* low level flags */
unsigned int ieee_state; /* see fpu.h */
struct exec_domain *exec_domain; /* execution domain */ /*表了当前进程是属于哪一种规范的可执行程序,
//不同的系统产生的可执行文件的差异存放在变量exec_domain中
mm_segment_t addr_limit; /* thread address space */
unsigned cpu; /* current CPU */
int preempt_count; /* 0 => preemptable, <0 => BUG */
int bpt_nsaved;
unsigned long bpt_addr[2]; /* breakpoint handling */
unsigned int bpt_insn[2];
struct restart_block restart_block;
};
1.2 0号进程
所有进程的祖先叫做进程0
在系统初始化阶段由start_kernel()函数从无到有手工创建的一个内核线程。0号进程一直处于皇宫“内核态”,没有出过宫“到用户态”,所谓贵族终身。
0号进程(idle进程,也称为init_task,因为其task_struct类型变量名字叫做init_task)是唯一一个没有通过fork或者kernel_thread产生的进程。
该进程的构建方式如下:
struct task_struct init_task = INIT_TASK(init_task);
Linux在无进程概念的情况下将一直从初始化部分的代码执行到start_kernel(它试图将从最早的汇编代码一直到start_kernel的执行都纳入到 0 号进程)。然后调用rest_init。
从rest_init开始,Linux开始产生进程。在rest_init函数中,内核将通过下面的代码产生第一个真正的进程(pid=1)
static noinline void __init_refok rest_init(void)
{
...
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
...
cpu_idle();
}
idle进程的工作(运行逻辑):
- 设置执行环境;
- 执行start_kernel()完成Linux内核的初始化工作,包括初始化页表,初始化中断向量表,初始化系统时间等。执行start_kernel()完成Linux内核的初始化工作,包括初始化页表,初始化中断向量表,初始化系统时间等。
- 调用kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND),创建init 进程;
- 调用 cpu_idle() 演变成了idle进程。
1.3 init进程:1号进程
进程1又称为init进程,是所有用户进程的祖先
由进程0在start_kernel调用rest_init,然后在rest_init中调用kernel_thread函数创建。init进程PID为1,当调度程序选择到init进程时,init进程开始执行kernel_init ()函数
init是个普通的用户态进程,它是Unix系统内核初始化与用户态初始化的接合点,它是所有用户进程的祖宗。在运行init以前是内核态初始化,该过程(内核初始化)的最后一个动作就是运行/sbin/init可执行文件。
** init 进程的工作(运行逻辑):**
- 被idle父进程创建起来后,开始执行kernel_init函数,继续系统初始化工作,如挂载根文件系统,根据/etc/inittab文件初始化相关程序;
- 调用kernel_execve,开始执行/sbin/init程序(这里会从内核态程序切换成用户态特权等级),变为守护进程监视系统其他进程
1.4 kthread进程:2号进程
kthreadd进程由idle通过kernel_thread创建,并始终运行在内核空间,负责所有内核进程的调度和管理。
它的任务就是管理和调度其他内核线程kernel_thread, 会循环执行一个kthread的函数,该函数的作用就是运行kthread_create_list全局链表中维护的kthread, 当我们调用kernel_thread创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程 。
1.5 进程创建
在Linux系统中,全部的进程都是PID为1的init进程的后代。内核在系统启动的最后阶段启动init进程。该进程读取系统的初始化脚本(initscript)并运行其它的相关程序,终于完毕系统启动的整个进程。
Linux提供两个函数去处理进程的创建和运行:fork()和exec()。首先,fork()通过拷贝当前进程创建一个子进程。子进程与父进程的差别只在于PID(每一个进程唯一),PPID(父进程的PID)和某些资源和统计量(比如挂起的信号)。exec()函数负责读取可运行文件并将其加载地址空间開始运行。
1.5.1 fork特性:写时复制
内核在fork进程时不复制整个进程地址空间,让父进程和子进程共享同一个拷贝,当须要写入时,数据才会被复制,使各进程拥有自己的拷贝。在页根本不会被写入的情况下(fork()后马上exec()),fork的实际开销仅仅有复制父进程的页表以及给子进程创建唯一的task_struct。
1.6 同一进程用户态和内核态切换
每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间(可通过task_struct 中的stack变量访问)。当进程在用户空间运行时,CPU堆栈指针寄存器里面的内容是用户堆栈地址;当进程在内核空间时,CPU堆栈指针寄存器里的内容是内核栈空间地址,使用内核栈。
当进程通过系统调用、或是发生中断异常陷入内核态时,进程使用的堆栈也要从用户栈转到内核栈。进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;
当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
== 在进程从用户态转到内核态的时候,进程的内核栈总是空的==。这是因为,当进程在用户态运行时,使用的是用户栈。当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以。
1.7 进程终止
进程在执行结束,或接受到它既不能处理也不能忽略的信号,或异常时,都会被终结。此时,依靠do_exit()(在kernel/exit.c文件里)把与进程相关联的全部资源都被释放掉(如果进程是这些资源的唯一使用者)。至此,与进程相关的全部资源都被释放掉了。进程不可执行(实际上也没有地址空间让它执行)并处于TASK_ZOMBIE状态。它占用的全部资源就是内核栈、thread_info和task_struct。此时进程存在的唯一目的就是想它的父进程提供信息。在父进程获得已终结的子进程的信息后,或者通知内核它并不关注那些信息后,子进程持有的task_struct等剩余内存才被释放。
1.8 孤儿进程问题
假设父进程在子进程之前退出,必须有机制保证子进程能找到一个新的父类,否则的话这些成为孤儿的进程就会在退出时永远处于僵死状态,白白的耗费内存。解决方法是给子进程在当前线程组内找一个线程作为父亲,假设不行,就让init做它们的父进程。
1.9 僵尸进程
一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
2. 进程调度
内存中保存了对每个进程的唯一描述, 并通过若干结构与其他进程连接起来.
调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉。调度任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换
内核必须提供一种方法, 在各个进程之间尽可能公平地共享CPU时间, 而同时又要考虑不同的任务优先级.
调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。调度器还需要面对一些互相冲突的目标,例如既要为关键实时任务最小化响应时间, 又要最大限度地提高 CPU 的总体利用率.
调度器的一般原理是, 按所需分配的计算能力, 向系统中每个进程提供最大的公正性, 或者从另外一个角度上说, 他试图确保没有进程被亏待.
2.1 进程的分类
linux把进程区分为实时进程和非实时进程, 其中非实时进程进一步划分为交互式进程和批处理进程
| 类型 | 描述 | 示例 |
|---|---|---|
| 交互式进程(interactive process) | 此类进程经常与用户进行交互, 因此需要花费很多时间等待键盘和鼠标操作. 当接受了用户的输入后, 进程必须很快被唤醒, 否则用户会感觉系统反应迟钝 | shell, 文本编辑程序和图形应用程序 |
| 批处理进程(batch process) | 此类进程不必与用户交互, 因此经常在后台运行. 因为这样的进程不必很快相应, 因此常受到调度程序的怠慢 | 程序语言的编译程序, 数据库搜索引擎以及科学计算 |
| 实时进程(real-time process) | 这些进程由很强的调度需要, 这样的进程绝不会被低优先级的进程阻塞. 并且他们的响应时间要尽可能的短 | 视频音频应用程序, 机器人控制程序以及从物理传感器上收集数据的程序 |
在linux中, 调度算法可以明确的确认所有实时进程的身份, 但是没办法区分交互式程序和批处理程序, linux2.6的调度程序实现了基于进程过去行为的启发式算法, 以确定进程应该被当做交互式进程还是批处理进程. 当然与批处理进程相比, 调度程序有偏爱交互式进程的倾向
2.2 不同进程采用不同的调度策略
根据进程的不同分类Linux采用不同的调度策略.
(1)实时进程
采用FIFO或者Round Robin的调度策略.
(2)普通进程
需要区分交互式和批处理式的不同。传统Linux调度器提高交互式应用的优先级,使得它们能更快地被调度。而CFS和RSDL等新的调度器的核心思想是”完全公平”。这个设计理念不仅大大简化了调度器的代码复杂度,还对各种调度需求的提供了更完美的支持.
注意Linux通过将进程和线程调度视为一个,同时包含二者。进程可以看做是单个线程,但是进程可以包含共享一定资源(代码和/或数据)的多个线程。因此进程调度也包含了线程调度的功能.
目前非实时进程的调度策略比较简单, 因为实时进程值只要求尽可能快的被响应, 基于优先级, 每个进程根据它重要程度的不同被赋予不同的优先级,调度器在每次调度时, 总选择优先级最高的进程开始执行. 低优先级不可能抢占高优先级, 因此FIFO或者Round Robin的调度策略即可满足实时进程调度的需求.
但是普通进程的调度策略就比较麻烦了, 因为普通进程不能简单的只看优先级, 必须公平的占有CPU, 否则很容易出现进程饥饿, 这种情况下用户会感觉操作系统很卡, 响应总是很慢,因此在linux调度器的发展历程中经过了多次重大变动, linux总是希望寻找一个最接近于完美的调度策略来公平快速的调度进程.
2.3 linux调度器的演变
一开始的调度器是复杂度为O(n)O(n)的始调度算法(实际上每次会遍历所有任务,所以复杂度为O(n)), 这个算法的缺点是当内核中有很多任务时,调度器本身就会耗费不少时间,所以,从linux2.5开始引入赫赫有名的O(1)O(1)调度器
然而,linux是集全球很多程序员的聪明才智而发展起来的超级内核,没有最好,只有更好,在O(1)O(1)调度器风光了没几天就又被另一个更优秀的调度器取代了,它就是CFS调度器Completely Fair Scheduler.
这个也是在2.6内核中引入的,具体为2.6.23,即从此版本开始,内核使用CFS作为它的默认调度器,O(1)O(1)调度器被抛弃了, 其实CFS的发展也是经历了很多阶段,最早期的楼梯算法(SD), 后来逐步对SD算法进行改进出RSDL(Rotating Staircase Deadline Scheduler), 这个算法已经是”完全公平”的雏形了, 直至CFS是最终被内核采纳的调度器, 它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越
2.4 Linux的调度器分类
可以用两种方法来激活调度
- 一种是直接的, 比如进程打算睡眠或出于其他原因放弃CPU
- 另一种是通过周期性的机制, 以固定的频率运行, 不时的检测是否有必要
因此当前linux的调度程序由两个调度器组成:主调度器,周期性调度器(两者又统称为通用调度器(generic scheduler)或核心调度器(core scheduler))
并且每个调度器包括两个内容:调度框架(其实质就是两个函数框架)及调度器类
2.5 6种调度策略
linux内核目前实现了6中调度策略(即调度算法), 用于对不同类型的进程进行调度, 或者支持某些特殊的功能
比如SCHED_NORMAL和SCHED_BATCH调度普通的非实时进程, SCHED_FIFO和SCHED_RR和SCHED_DEADLINE则采用不同的调度策略调度实时进程, SCHED_IDLE则在系统空闲时调用idle进程
关于idle进程:目前的版本中idle并不在运行队列中参与调度,而是在cpu全局运行队列rq中含idle指针,指向idle进程, 在调度器发现运行队列为空的时候运行, 调入运行。
2.6 5个调度器类
依据其调度策略的不同实现了5个调度器类, 一个调度器类可以用一种种或者多种调度策略调度某一类进程, 也可以用于特殊情况或者调度特殊功能的进程.
| 调度器类 | 描述 | 对应调度策略 |
|---|---|---|
| stop_sched_class | 优先级最高的线程,会中断所有其他线程,且不会被其他任务打断。作用:1.发生在cpu_stop_cpu_callback 进行cpu之间任务migration;2.HOTPLUG_CPU的情况下关闭任务 | 无, 不需要调度普通进程 |
| dl_sched_class | 采用EDF最早截至时间优先算法调度实时进程 | SCHED_DEADLINE |
| rt_sched_class | 采用提供 Roound-Robin算法或者FIFO算法调度实时进程 | |
| 具体调度策略由进程的task_struct->policy指定 | SCHED_FIFO, SCHED_RR | |
| fair_sched_clas | 采用CFS算法调度普通的非实时进程 | SCHED_NORMAL, SCHED_BATCH |
| idle_sched_class | 采用CFS算法调度idle进程, 每个cup的第一个pid=0线程:swapper,是一个静态线程。调度类属于:idel_sched_class,所以在ps里面是看不到的。一般运行在开机过程和cpu异常的时候做dump | SCHED_IDLE |
2.7 3个调度实体 与 调度器类的就绪队列
调度器不限于调度进程, 还可以调度更大的实体, 比如实现组调度: 可用的CPUI时间首先在一半的进程组(比如, 所有进程按照所有者分组)之间分配, 接下来分配的时间再在组内进行二次分配.
这种一般性要求调度器不直接操作进程, 而是处理可调度实体, 因此需要一个通用的数据结构描述这个调度实体,即seched_entity结构, 其实际上就代表了一个调度对象,可以为一个进程,也可以为一个进程组.
linux中针对当前可调度的实时和非实时进程, 定义了类型为seched_entity的3个调度实体
| 调度实体 | 名称 | 描述 | 对应调度器类 |
|---|---|---|---|
| sched_dl_entity | DEADLINE调度实体 | 采用EDF算法调度的实时调度实体 | dl_sched_class |
| sched_rt_entity | RT调度实体 | 采用Roound-Robin或者FIFO算法调度的实时调度实体 | rt_sched_class |
| sched_entity | CFS调度实体 | 采用CFS算法调度的普通非实时进程的调度实体 | fair_sched_class |
另外,对于调度框架及调度器类,它们都有自己管理的运行队列,调度框架只识别rq(其实它也不能算是运行队列):
- cfs调度器类:它的运行队列则是cfs_rq(内部使用红黑树组织调度实体)
- 实时rt:运行队列则为rt_rq(内部使用优先级bitmap+双向链表组织调度实体)。
- 内核对新增的dl实时调度策略也提供了运行队列dl_rq。
注意:各个活动进程只出现在一个就绪队列中
2.8 调度器整体框架与schedule函数
本质上, 通用调度器(核心调度器)的一般过程过程:
-
判断接下来运行哪个进程.
内核支持不同的调度策略(完全公平调度, 实时调度, 在无事可做的时候调度空闲进程,即0号进程也叫swapper进程,idle进程), 调度类使得能够以模块化的方法实现这些侧露额, 即一个类的代码不需要与其他类的代码交互
当调度器被调用时, 他会查询调度器类, 得知接下来运行哪个进程 -
在选中将要运行的进程之后, 必须执行底层的任务切换.
这需要与CPU的紧密交互. 每个进程刚好属于某一调度类, 各个调度类负责管理所属的进程. 通用调度器自身不涉及进程管理, 其工作都委托给调度器类.
每个进程都属于某个调度器类(由字段task_struct->sched_class标识), 由调度器类采用进程对应的调度策略调度(由task_struct->policy )进行调度, task_struct也存储了其对应的调度实体标识
2.8.1 schedule函数
schedule就是主调度器的函数。
该函数完成如下工作:
- 确定当前就绪队列, 并在保存一个指向当前(仍然)活动进程的task_struct指针
- 检查死锁, 关闭内核抢占后调用__schedule完成内核调度。
- 恢复内核抢占, 然后检查当前进程是否设置了重调度标志TLF_NEDD_RESCHED, 如果该进程被其他进程设置了TIF_NEED_RESCHED标志, 则函数重新执行进行调度
其中, __schedule的执行过程如下:
- 完成一些必要的检查, 并设置进程状态, 处理进程所在的就绪队列
- 调度全局的pick_next_task选择抢占的进程. 调度全局的pick_next_task选择抢占的进程
-
- 如果当前cpu上所有的进程都是cfs调度的普通非实时进程, 则直接用cfs调度, 如果无程序可调度则调度idle进程
-
- 否则从优先级最高的调度器类sched_class_highest(目前是stop_sched_class)开始依次遍历所有调度器类的pick_next_task函数, 选择最优的那个进程执行
- context_switch完成进程上下文切换
-
- 调用switch_mm(), 把虚拟内存从一个进程映射切换到新进程中调用switch_mm(), 把虚拟内存从一个进程映射切换到新进程中
-
- 调用switch_to(),从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存、恢复栈信息和寄存器信息
2.9 进程调度的时机和上下文切换
2.9.1 进程调度的时机:
- 中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
- 内核线程(只有内核态没有用户态的特殊进程)可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
- 用户态进程无法实现主动调度,只能被动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
2.9.2 进程上下文切换
进程上下文包含了进程执行需要的所有信息:
- 用户地址空间:包括程序代码,数据,用户堆栈等
- 控制信息:进程描述符,内核堆栈等
- 硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
该函数执行的大致过程如下:
next = pick_ next_task(rq, prev);//进程调度算法都封装这个函数内部
context_switch(rq, prev, next);//进程上下文切换
2.10 睡眠
current进程因不能获得必须的资源而要立刻被阻塞,就直接调用调度程序。在这种情况下,按下述步骤执行:
- 把current进程current插入适当的等待队列
- 把current进程的状态改为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE。
- 调用schedule()
附录
附录一:task_struct结构(linux 2.6)
struct task_struct {
volatile long state; //说明了该进程是否可以执行,还是可中断等信息
unsigned long flags; //Flage 是进程号,在调用fork()时给出
int sigpending; //进程上是否有待处理的信号
mm_segment_t addr_limit; //进程地址空间,区分内核进程与普通进程在内存存放的位置不同
//0-0xBFFFFFFF for user-thead
//0-0xFFFFFFFF for kernel-thread
//调度标志,表示该进程是否需要重新调度,若非0,则当从内核态返回到用户态,会发生调度
volatile long need_resched;
int lock_depth; //锁深度
long nice; //进程的基本时间片
//进程的调度策略,有三种,实时进程:SCHED_FIFO,SCHED_RR, 分时进程:SCHED_OTHER
unsigned long policy;
struct mm_struct *mm; //进程内存管理信息
int processor;
//若进程不在任何CPU上运行, cpus_runnable 的值是0,否则是1 这个值在运行队列被锁时更新
unsigned long cpus_runnable, cpus_allowed;
struct list_head run_list; //指向运行队列的指针
unsigned long sleep_time; //进程的睡眠时间
//用于将系统中所有的进程连成一个双向循环链表, 其根是init_task
struct task_struct *next_task, *prev_task;
struct mm_struct *active_mm;
struct list_head local_pages; //指向本地页面
unsigned int allocation_order, nr_local_pages;
struct linux_binfmt *binfmt; //进程所运行的可执行文件的格式
int exit_code, exit_signal;
int pdeath_signal; //父进程终止时向子进程发送的信号
unsigned long personality;
//Linux可以运行由其他UNIX操作系统生成的符合iBCS2标准的程序
int did_exec:1;
pid_t pid; //进程标识符,用来代表一个进程
pid_t pgrp; //进程组标识,表示进程所属的进程组
pid_t tty_old_pgrp; //进程控制终端所在的组标识
pid_t session; //进程的会话标识
pid_t tgid;
int leader; //表示进程是否为会话主管
struct task_struct *p_opptr,*p_pptr,*p_cptr,*p_ysptr,*p_osptr;
struct list_head thread_group; //线程链表
struct task_struct *pidhash_next; //用于将进程链入HASH表
struct task_struct **pidhash_pprev;
wait_queue_head_t wait_chldexit; //供wait4()使用
struct completion *vfork_done; //供vfork() 使用
unsigned long rt_priority; //实时优先级,用它计算实时进程调度时的weight值
//it_real_value,it_real_incr用于REAL定时器,单位为jiffies, 系统根据it_real_value
//设置定时器的第一个终止时间. 在定时器到期时,向进程发送SIGALRM信号,同时根据
//it_real_incr重置终止时间,it_prof_value,it_prof_incr用于Profile定时器,单位为jiffies。
//当进程运行时,不管在何种状态下,每个tick都使it_prof_value值减一,当减到0时,向进程发送
//信号SIGPROF,并根据it_prof_incr重置时间.
//it_virt_value,it_virt_value用于Virtual定时器,单位为jiffies。当进程运行时,不管在何种
//状态下,每个tick都使it_virt_value值减一当减到0时,向进程发送信号SIGVTALRM,根据
//it_virt_incr重置初值。
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_value;
struct timer_list real_timer; //指向实时定时器的指针
struct tms times; //记录进程消耗的时间
unsigned long start_time; //进程创建的时间
//记录进程在每个CPU上所消耗的用户态时间和核心态时间
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS];
//内存缺页和交换信息:
//min_flt, maj_flt累计进程的次缺页数(Copy on Write页和匿名页)和主缺页数(从映射文件或交换
//设备读入的页面数); nswap记录进程累计换出的页面数,即写到交换设备上的页面数。
//cmin_flt, cmaj_flt, cnswap记录本进程为祖先的所有子孙进程的累计次缺页数,主缺页数和换出页面数。
//在父进程回收终止的子进程时,父进程会将子进程的这些信息累计到自己结构的这些域中
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1; //表示进程的虚拟地址空间是否允许换出
//进程认证信息
//uid,gid为运行该进程的用户的用户标识符和组标识符,通常是进程创建者的uid,gid
//euid,egid为有效uid,gid
//fsuid,fsgid为文件系统uid,gid,这两个ID号通常与有效uid,gid相等,在检查对于文件
//系统的访问权限时使用他们。
//suid,sgid为备份uid,gid
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups; //记录进程在多少个用户组中
gid_t groups[NGROUPS]; //记录进程所在的组
//进程的权能,分别是有效位集合,继承位集合,允许位集合
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
int keep_capabilities:1;
struct user_struct *user;
struct rlimit rlim[RLIM_NLIMITS]; //与进程相关的资源限制信息
unsigned short used_math; //是否使用FPU
char comm[16]; //进程正在运行的可执行文件名
//文件系统信息
int link_count, total_link_count;
//NULL if no tty 进程所在的控制终端,如果不需要控制终端,则该指针为空
struct tty_struct *tty;
unsigned int locks;
//进程间通信信息
struct sem_undo *semundo; //进程在信号灯上的所有undo操作
struct sem_queue *semsleeping; //当进程因为信号灯操作而挂起时,他在该队列中记录等待的操作
//进程的CPU状态,切换时,要保存到停止进程的task_struct中
struct thread_struct thread;
//文件系统信息
struct fs_struct *fs;
//打开文件信息
struct files_struct *files;
//信号处理函数
spinlock_t sigmask_lock;
struct signal_struct *sig; //信号处理函数
sigset_t blocked; //进程当前要阻塞的信号,每个信号对应一位
struct sigpending pending; //进程上是否有待处理的信号
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
u32 parent_exec_id;
u32 self_exec_id;
spinlock_t alloc_lock;
void *journal_info;