Linux下的hadoop的伪分布式安装
需要注意的:
如果是配置文件都在${hadoop_home}/etc/hadoop下面
执行命令的目录都在hadoop的安装目录下
上传hadoop的压缩包
首先安装Linux自带的上传下载文件的工具
命令:
sudo yum install -y lrzsz我之前是借用工具直接将Windows系统里面的压缩包拖到Linux内的,其实都差不多,只是为了都尝试一下而已
上传
rz
下载
sz到要放置的压缩包的目录下执行rc命令,会出现如下的窗口,将我们要需要的hadoop的压缩包上传到Linux内,这里我上传的是第一个压缩包到/opt/modules内,注意我这里的版本是2.x,3.x的端口都有发生变化
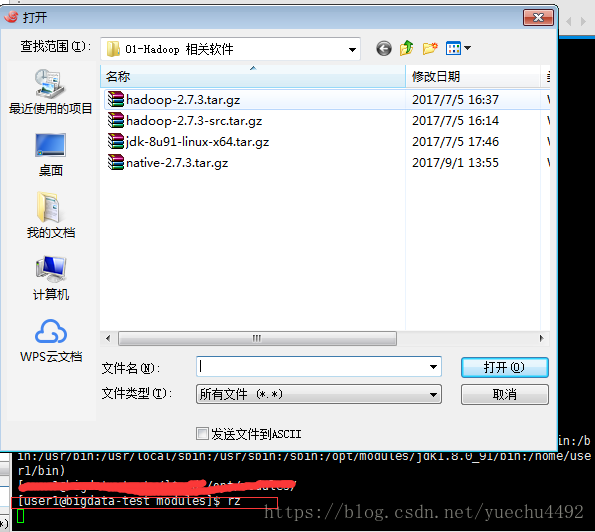
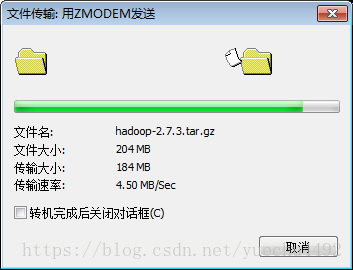
这里我出现了点小失误,因为我modules目录是安装目录,压缩包等是放在softwares里面的,这个之前的博客有说到过。其实没什么影响。
这里可以将该压缩包移动到softwares文件夹
命令:
mv hadoop-2.7.3.tar.gz /opt/softwares/
给压缩包执行的权限
命令:
chmod u+x hadoop-2.7.3.tar.gz


解压压缩包
解压压缩包到modules目录下
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/modules/解压后到modules目录下面如下图显示

配置 *-env.sh 环境变量文件
以下所有配置文件基本都在hadoop的/etc内
我是使用notepad++编辑配置文件的
hadoop-env.sh
![]()
将上面的${JAVA_HOME}改为jdk的路径
![]()
保存退出
yarn-env.sh
![]()
去掉#改为和hadoop-env.sh一样
![]()
mapred-env.sh
和yarn-env.sh一样
![]()
![]()
配置HDFS环境
core-site.xml
进入配置文件,里面上面也没有,但其实是有默认配置文件的

在里面添加如下:
fs.defaultFS
hdfs://bigdata-test.com:8020
hadoop.tmp.dir
/opt/modules/hadoop-2.7.3/data/tmpData
创建对应的文件夹
![]()

hdfs-site.xml

添加如下配置属性
dfs.replication
1

slaves
![]()
改为自己的主机名
说明: 此文件中一行表示一个主机名称,会在此主机上运行DataNode
![]()
启动HDFS服务
格式化文件系统
注意:只能格式一次
bin/hdfs namenode -format
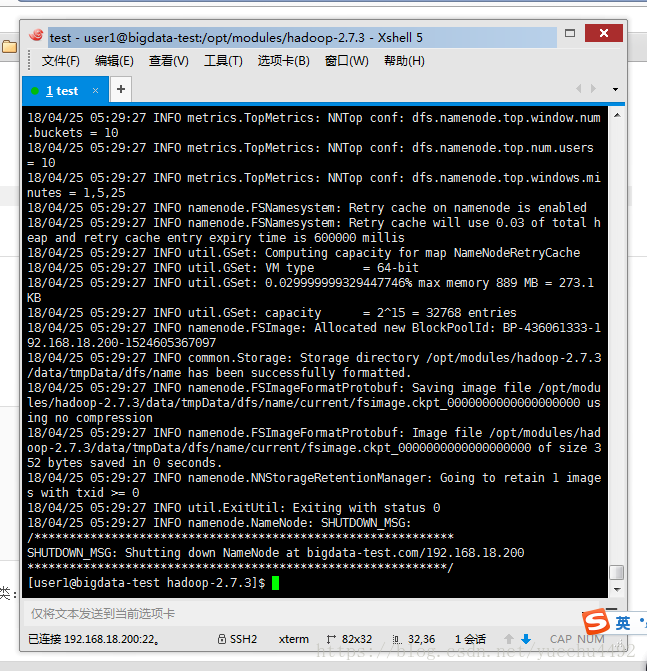
启动服务
主节点:
sbin/hadoop-daemon.sh start namenode
从节点:
sbin/hadoop-daemon.sh start datanode
验证:
方式一:
jps
方式二:
在浏览器的地址栏输入
http://bigdata-test.com:50070如果出现如下的页面则表示成功
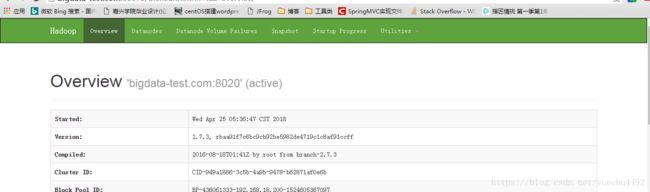
如果没有,则到C:\Windows\System32\drivers\etc目录下,修改hosts文件,在里面添加自己的ip和主机名,如下所示
192.168.18.200 bigdata-test.com测试HDFS
创建文件夹,在下图中会出现我们创建的文件夹
bin/hdfs dfs -mkdir -p /datas/tmp


上传文件
bin/hdfs dfs -put ./etc/hadoop/core-site.xml /datas/tmp到datas/tmp里面可以看到自己上传的文件

配置yarn集群
yarn-site.xml

在里面配置如下:
yarn.resourcemanager.hostname
bigdata-test.com
yarn.nodemanager.aux-services
mapreduce_shuffle

slaves文件
指定NodeManager运行的主机名称,由于NM与DN同属一台机器,前面已经配置完成。
![]()
启动yarn服务
主节点:
sbin/yarn-daemon.sh start resourcemanager
从节点:
sbin/yarn-daemon.sh start nodemanager

测试:
方法一:查看进程
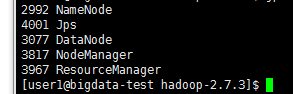
方法二:在浏览器地址栏输入主机名:8088
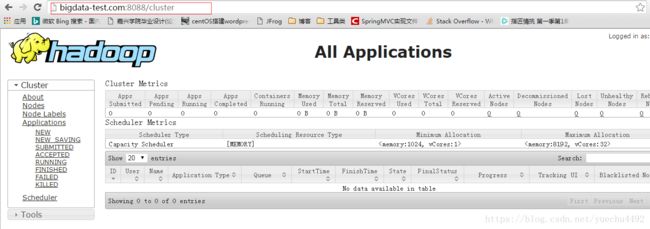
如果没有出现下图检查yarn-site.xml里面配置的主机名是否正确以及是否启动的yarn服务
配置MapReduce历史服务器MRHistoryServer
复制并重命名hadoop下面的配置文件
cp mapred-site.xml.template mapred-site.xml复制完打开mapre-site.xml
在里面添加如下属性
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
bigdata-hpsk01.huadian.com:10020
mapreduce.jobhistory.webapp.address
bigdata-hpsk01.huadian.com:19888

启动服务
$ sbin/mr-jobhistory-daemon.sh start historyserver配置yarn-site.xml
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800

重启YARN和JobHistoryServer服务