欢迎关注"生信修炼手册"!
VCF全称为Variant Call Format, 是一种纯文本文件,用来存储变异位点信息,主要包括3个部分的内容
mate-information line
header line
-
data line
示例文件如下
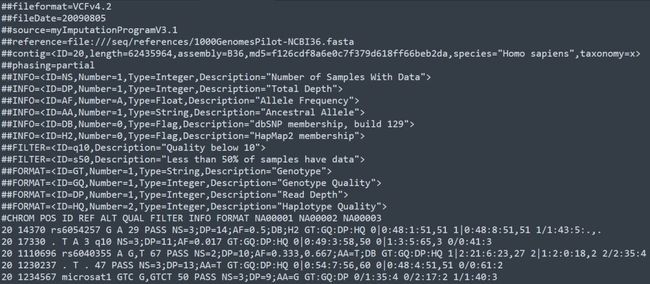
1. mate-information line
以##开头,格式为key=value。 fileformat是必须的字段,表明VCF格式的版本,写法如下
##fileformat=VCFv4.2
其他行主要用来描述INFO, FORMAT, FILTER等字段的具体含义。
2. header line
以#开头,\t分隔,至少包含以下8个字段
CHROM : 染色体名字
POS : 染色体的位置,起始位置为1
ID : 变异位点在数据库中的ID,如果是dbsnp数据库,推荐使用rs号,如果没有ID,用点号表示缺失值
REF : 参考基因组上的碱基
ALT : 变异之后的碱基
QUAL : 变异位点的质量,质量值越高,为真实的变异位点的概率越大
FILTER : 过滤信息,PASS 代表通过了过滤;对于过滤失败的位点,会给出对应的过滤失败的原因,具体的含义可以查看mate-information line 中对FILTER 字段的描述
INFO :额外的信息,具体的含义可以查看mate-information line 中对INFO 字段的描述
3 .data line
每一行记录一个变异位点的信息,具体的内容可以参考header line 中的解释。常见的变异类型包括SNP, 插入和缺失这3种,这3者的差别主要体现在REF和ALT两个字段上。
SNP 示例如下, 由G突变成A
REF ALT
G A
缺失示例如下,缺失了TC
REF ALT
GTC G
插入示例如下, 插入了T碱基
REF ALT
C CT
SNP很好理解,REF和ALT单个碱基不同,插入和缺失在表示时,起始位置都会在发生变异的位点的前面几个碱基,比如上面例子中的TC缺失,在REF中起始位置为前面的G碱基;T碱基的插入,在REF中起始位置为前面的C碱基。
多个样本的变异分析结果中,有时会看到下面的例子
#CHROM POS ID REF ALT QUAL FILTER INFO
20 2 . TC TG,T . PASS DP=100
在ALT字段中用逗号连接了多个字符,表示在不同的样本中检测到了多种变异类型。上述示例中,参考基因组碱基为TC, 共检测到两种变异类型,TC代表一个SNP,由C碱基突变成G碱基;T代表缺失,C碱基缺失,由TC变成了T。
在VCF文件中,除了每个变异位点具体的碱基变化信息之外,基因型genotype 信息也是较为关注的。每个样本1个基因型信息,用GT字段的值来表示。不同的等位基因allel 用|或者\连接,示例如下
FORMAT NA01 NA02 NA03
GT 0|0 0|1 0/0
这里为了展示省略掉了VCF必备的8列信息, FORMAT实际是第9列的信息了。FORMAT指定后续字段的含义,GT是genotype 的缩写,表示基因型,NA01到NA03代笔3个样本。用数字来表示不同的allel,0代表REF allel, 1代表ALT 中的第一个allel, 2代表ALT中的第二个allel, 依次类推。对于多个allel, 可以用|或者/连接。
以二倍体生物为例,基因型由两条染色体上的allel构成。当我们知道每一个allel来自于具体哪条染色体时,这种genotype叫做Phased genotype, 用|连接,1|0和0|1代表两种不同的基因型;不清楚allel对应的染色体的时, genotype叫做unphased genotype, 用/连接,0/1和1/0这两种写法是等价的。目前高通量分析鉴定到的基因型,大多数都是unphased genotype。
扫描关注微信号,更多精彩内容等着你!
