树莓派3B+ 语音唤醒snowboy库的使用
由于百度语音识别 linux版本的sdk默认不支持语音唤醒功能,想要在树莓派3b+上做一个语音唤醒+识别的小玩意儿,要想实现唤醒的功能,只能另寻他法,然后我在网络上搜索到了这个snowboy,它是一个语音唤醒引擎。
snowboy下载地址:https://github.com/Kitt-AI/snowboy
snowboy自定义唤醒词网站:https://snowboy.kitt.ai/
snowboy完整文档介绍:http://docs.kitt.ai/snowboy/
Snowboy是一个高度可定制的热门词检测引擎,它实时嵌入并始终与Raspberry Pi,(Ubuntu)Linux和Mac OS X兼容(网络离线时同样可用--说明该引擎使用时是完全具有隐私性的,不需要依赖于网络,可用性极强)。目前的百度的语音唤醒实际上也是使用的snowboy引擎。
snowboy具有一下特性:
>高度可定制.我们可以自由的定制语音唤醒词。可自定义任何唤醒词,只需要在https://snowboy.kitt.ai/网站上进行唤醒词模型训练即可。
>持续实时监听,但却能保护您的隐私。因为Snowboy语音唤醒的机制不需要链接到互联网。
>轻量级和嵌入式。允许您在Raspberry Pi上运行它,在最小的Pi(单核700M Hz ARMv6)上消耗不到10%的CPU。
>Apache协议
其具体的使用步骤如下:
1.首先我们在snowboy训练自定义唤醒词模型:
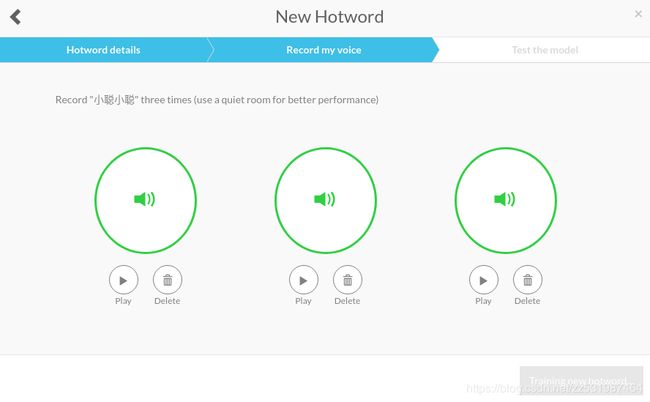
上传包含唤醒词的三段录音,训练自己的语音唤醒词模型,上传完成后点击右下角的开始训练,很快就训练好了
如果一直卡在上面这个画面,说明当前上传的wav文件语音质量较差,导致无法训练该模型,重新调整麦克风音量重新录入。
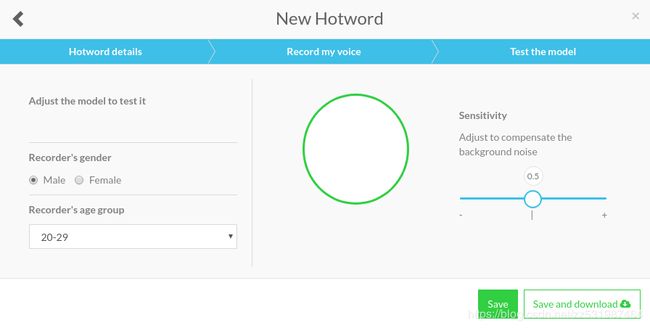
当训练结束后,会出现如上的弹框,我们可以在这里对这个模型进行测试,设置当前录制的是男声还是女声,以及录制的年龄,然后进行测试(可以调节灵敏度测试),插入麦克风,测试当前唤醒词是否有效,测试成功会显示successful,说明当前自定义的语音唤醒词模型可用。接下来我们直接点击保存并下载即可,文件名为 xxx.pmdl。
2.编译运行snowboy
在github上下载snowboy源码包,这里我下载的是release的snowboy-1.3的源码包。
下载后解压 tar xvf snowboy-1.3.0.tar.gz
目前网上大部分使用的是python环境,我这边因为是想在QT中集成语音唤醒功能,所以我选择c++
首先进入到example目录下编译符合c++环境的demo.
cd examples/C++/
sudo apt-get -y install libasound2-dev
./install_portaudio.sh
接下来直接执行 make,会报错显示
/usr/bin/ld: 找不到 -lf77blas
/usr/bin/ld: 找不到 -lcblas
/usr/bin/ld: 找不到 -llapack_atlas
/usr/bin/ld: 找不到 -latlas
collect2: error: ld returned 1 exit status
我们还需要安装其他一些库
sudo apt-get install swig3.0 sox
sudo apt-get install libatlas-base-dev
安装完成后执行 make
编译完成,执行demo
./demo
demo默认使用的唤醒词模型为snowboy.umdl,执行demo时我们可以使用麦克风唤醒。当识别到说的是snowboy时会显示打印Hotword 1 detected!。我们可以在代码中打印前加上一句system("play resources/ding.wav"),这样在识别到唤醒词时会自动播放一个叮的声音啦。
./demo2 xxx.wav
demo2运行时需要传入一个含有唤醒词的wav音频文件,这种用法应该用处不大,主要还是demo用的比较多。
当我们需要我们自定义的唤醒词模型时,只需要我们修改demo代码中的
207 std::string model_filename = "resources/models/snowboy.umdl"; 指定自己前面所设置的唤醒词模型
208 std::string sensitivity_str = "0.5"; 设置唤醒灵敏度
好啦,接下来我们可以让这个snowboy与百度语音相结合,来做一些语音操控树莓派啦、、、、、
注意:如果出现运行demo时报 "Fail to open PortAudio stream, error message is "Device unavailable" ,是因为前面安装portaudio之前没有安装libasound2-dev导致,我们只需要删除重新解压snowboy包,按照上面的顺序依次安装即可.
语音唤醒的效果实际上与你前面上传的三段唤醒词录音关系很大,我们很难有专业的设备来录制一段效果非常好的唤醒词录音,所以出现语音唤醒效果不好的情况是很正常的(例如:我唤醒词是小聪小聪,你说小朱小朱实际上也是会唤醒的),我们需要对上传的音频需要做一些降噪等方面的处理,提高音频质量.但最好还是考虑使用默认的唤醒词snowboy或者smart_mirror,当你说出soboy 等模糊音时,并不会被唤醒,这个默认的模型训练的还是比较准确的.