MySQL的体系结构与存储引擎
一、MySQL的体系结构
本人用一张树状图来通俗易懂的展现MySQL的体系结构
从下图可以看到MySQL的体系结构分为MySQL Sever层和存储引擎层,以及往下的细分和功能

二、Query Cache详解
- Query Cache在生产中建议关闭,其只能缓存静态数据信息,一旦数据发生变化,又经常读写,Query Cache就显得力不从心了
- 一般数据仓库之类的可以考虑开启Query Cache
- MySQL5.6之前的版本默认开启Query Cache,5.6之后的默认关闭
1、介绍一款压力测试软件sysbench
- sysbench是一个开源的,模块化的,跨平台的多线程性能测试工具,用来进行CPU、内存、磁盘I/O、线程、数据库的性能测试
- 软件包下载地址:https://downloads.mysql.com/source/sysbench-0.4.12.14.tar.gz
sysbench的安装过程
# tar -zxf sysbench-0.4.12.14.tar.gz
# cd sysbench-0.4.12.14/
# ./configure --with-mysql-includes=/usr/local/mysql/include --with-mysql-libs=/usr/local/mysql/lib
# make && make install
# find / -name 'libmysqlclient*' #找到libmysqlclient.so.20文件做一个软链接
# ln -s /usr/local/mysql-5.7.26-linux-glibc2.12-x86_64/lib/libmysqlclient.so.20 /usr/local/lib/libmysqlclient.so.20
# vim /etc/ld.so.conf
/usr/local/lib
# /sbin/ldconfig -v
2、如何彻底关闭Query Cache
彻底关闭Query Cache需要关注两个核心参数:
如下:
root@localhost [(none)]>show variables like "%query_cache_size%";
- 将query_cache_sizes设置为0以及将 query_cache_type设置为OFF

root@localhost [(none)]>show variables like "%query_cache_type%";

三、存储引擎
最主流的两个引擎:InnoDB 和 MyISAM,现在数据库默认的存储引擎是InnoDB
1、InnoDB体系结构
数据库:MySQL数据库是一个单进程多线程模型的数据库
数据库实例:进程加内存的组合
就比如一个杯子里装了水,杯子相当于数据库,水就相当于数据库实例
- InnoDB体系结构由内存结构、线程、磁盘文件组成,以下细讲
2、InnoDB存储结构
InnoDB逻辑存储单元主要分为表空间、段、区和页
a)表空间
- InnoDB存储引擎表中的所有数据都存放在表空间中
- 表空间分为系统表空间和独立表空间
系统表空间:以ibdata1来命名,在安装数据库初始化时就是系统在建立一个ibdata1的表空间文件,它会储存所有数据的信息以及回滚段(undo)的信息
- 数据库默认的ibdata1的大小是10M,在遇到高并发事物时,会受到不小的影响,建议将ibdata1的大小调整到1G
独立表空间:默认使用独立表空间文件,每个表有自己的表空间文件不用储存在ibdata1中
- 储存 对应表的B+树数据、索引和插入缓冲
- 每个表都有自己的表空间,可以实现表空间的转移,回收表空间方便
- 缺点是每个表文件都有.frm和.ibd文件两个文件描述符,如果单表增加过快就容易出现性能问题
共享表空间:数据和文件放在一起管理
- 无法在线回收空间,回收空间的将全部InnoDB表中的数据备份,删除原表,然后再把数据导回到与原表结构一样的新表中
b)段
- 表空间由段组成,也可以将一个表理解成4个段
- 每个段由N个区和32个零散的页组成
- 段空间扩展以区为单位扩展
- 一般来说,创建一个索引同时会创建两个段(非叶子节点和叶子节点段)
- 一个表有四个段,是索引个数的两倍
c)区
- 区有连续的页组成的,在物理上是连续分配的一段空间,每个区的大小固定是1M
d)页
- InnoDB的最小物理存储分配单位是page
- 一般来说,一个区由64个连续的页组成,页的默认大小为16K
- 一个page页会默认预留1/16的空间用于更新数据。真正使用的是15/16的空间
e)行
-
页里面记录着行记录的信息
-
InnoDB存储引擎面向的是行,也就是数据是按照行存储的
-
行记录数据按照行格式进行存放
-
有两种文件格式,Antelope和Barracuda
-
Antelope有compact和redundant两种行记录格式
-
Barracuda有compressed和dynamic两种行记录格式
-
5.7默认使用 dynamic行记录格式和 Barracuda文件格式
-
行溢出:
需要存储的数据在当前储存界面之外,拆分到多个页进行储存 -
目前生产环境中建议使用dynamic行记录格式进行存储
3、Buffer状态及其链表结构
-
page是InnoDB磁盘I/O的最小单位,数据存放在page中,对应到内存就是一个个buffer
-
buffer有三种状态:
free buffer:这个状态下的buffer没有被使用,是空闲的。但是在生产环境中,数据库很繁忙的情况下,free buffer基本不存在
clean buffer:内存中buffer里的数据和磁盘中page的数据一致
dirty buffer:内存中新写入的数据还没有刷新到磁盘,uffer里的数据和磁盘中page的数据不一致 -
buffer在内存中,需要被chain(链)组织起来
-
InnoDB是双向链表结构,由三种不同的buffer状态衍生出三条链表
free list:把free buffer都串联起来。数据库跑起来的时候,每次把page调到内存中,都会判断free buffer是否够用,不够用的话从lru list和flush list中释放free buffer
lru list:把与磁盘数据一致,并且最近最少被使用的buffer串联起来,释放出free buffer
flush list:把dirty buffer串联起来,方便刷新线程将脏数据刷到磁盘。规则是将那些最近最少被弄脏的数据串起来,刷新到磁盘后,释放出更多的free buffer
4、各大刷新线程及其作用
a)master thread线程
后台线程中的主线程,优先级别最高
内部有四个循环:
- 主循环loop
- 后台循环backgroud loop
- 刷新循环flush loop
- 暂定循环suspend loop
根据数据的运行状态在这四个循环之间进行切换
- 主循环loop中包含了每1s和每10s的操作
- 每1s操作:
1、日志缓冲刷新到磁盘,即使这个事务还没有被提交
2、刷新脏页到磁盘
3、执行合并插入缓冲的操作
4、产生checkpoint
5、清除无用的table cache
6、如果当前没有用户活动,就可能切换到background loop - 每10s操作:
1、日志缓冲刷新到磁盘,即是事务还没有被提交
2、执行合并插入缓冲操作
3、刷新脏页到磁盘
4、删除无用的undo页
5、产生checkpoint
b)四大I/O线程
read/write thread:数据库的读写请求线程,默认值是4个,如果使用高转速磁盘,可适当调大该值
redo log thread:把日志缓存中的内容刷新到redo log文件中
change buffer thread:把插入缓存(change buffer)中的内容刷新到磁盘中
c)page cleaner thread
负责脏页刷新线程,可增加多个
d)purge thread
负责删除无用的undo页
- 由于进行DML语句操作都会生成undo,系统需要定期对undo页进行清理,这时就需要purge操作
- purge默认线程个数是1个,最大可调整至32个
e)checkpoint线程
在redo log发生切换时,执行checkpoint。
redo log 发生切换或文件快写满时,会触发把脏页刷新到磁盘,确保redo log刷新到磁盘,实现真正的持久化,避免数据丢失
- error monitor thread :负责数据库报错的监控线程
- lock monitor thread :负责锁的监控线程
5、内存刷新机制
MySQL这种关系型数据库,讲究日志先行策略,就是一条DML语句进入数据库之后,先写日志,再写数据文件
a)redo log
redo log 又称重做日志文件,用来记录事务操作的变化,记录数据修改之后的值,不管事务是否被提交,都会被记录下来
- 在实例和介质失败时,如数据库掉电,这时候InnoDB存储引擎会使用重做日志,恢复到掉电前的时刻
默认情况至少有两个redo log文件,在磁盘用ib_logfile(0-N)来命名

-
redo log 写的方式是顺序写、循环写
顺序写、循环写是什么意思呢?
也就是说,第一个文件写满之后,写第二个文件,这样依次写到最后一个文件,直至最后一个文件写满之后,又重新写第一个文件,就这样循环 -
写满日志文件会产生切换操作,并执行checkpoint,触发脏页的刷新
-
数据库重启过程中,如果参数文件中的redo log值大小和当前redo log值大小不一致,那就删除当前redo log文件,按照参数文件中的redo log值大小,生成新的redo log文件
在生成redo log之前,数据写在redo log buffer中

redo log buffer刷新到磁盘的条件:
(1)通过innodb_flush_log_at_trx_commit 参数来控制
-
0:redo log thread 每隔1s会将redo log buffer中的数据写入redo log中,同时进行刷盘操作
每次事务提交并不会触发redo log thread 将日志缓冲中的数据写入redo log中去 -
1:每次事务提交时,都会触发redo log thread 将日志缓冲中的数据写入redo log,并flush到磁盘
-
2:每次事务提交时,把redo log buffer的数据写入redo log中,不刷到磁盘
这三种模式:0的性能 最好,但不安全,有丢失1s的数据的风险。1的安全性最高,不会丢失任何已经提交的事务,但就是数据库的性能最慢。2介于两者之间

(2)master thread :每秒进行刷新
(3)redo log buffer:使用超过一半的时候就触发刷新
b)binlog
MySQL的二进制文件,用于备份恢复和主从复制
-
从binlog cache刷新到磁盘binlog文件中所需条件:
sync_binlog=0时,当事务提交后,MySQL不做fsync之类的磁盘同步指令、将binlog_cache中的信息刷新到磁盘,而是让Filesystem自行决定什么时候来做同步,或cache满了之后,才同步到磁盘
sync_binlog=n时,每进行n次事务提交后,MySQL进行一次fsync之类的磁盘同步指令、将binlog_cache中的信息刷新到磁盘 -
sync_binlog设置为1,更安全
-
sync_binlog设置为0,性能最好
c)redo log 和 binlog的区别
redo log 和 binlog都记录了数据真实修改的语句,那他们为何要并存呢?
-
1、记录内容不同
binlog是逻辑日志,记录所有数据的改变信息
redo log是物理日志,记录所有InnoDB表数据的变化 -
2、记录内容的时间不同
binlog记录commit完毕之后的DML和DDL SQL语句
redo log记录事务发起之后的DML和DDL SQL语句 -
3、文件使用方式不同
binlog不是循环使用,在写满或者实例重启之后,会生成新的binlog文件
redo log是循环使用,最后一个文件写满之后,会重新写第一个文件 -
4、作用不同
binlog可以作为恢复数据使用,主从复制搭建
redo log作为异常宕机或者介质故障后的数据恢复使用
d)脏页刷新条件
- 1、重做日志ib_logfile文件写满之后,在切换的过程中会执行checkpoint,会触发脏页的刷新
- 2、innodb_max_dirty_pages_pct参数控制,其含义是在 buffer pool 中 dirty page 所占百分比,达到设置的值,会触发脏页的刷新

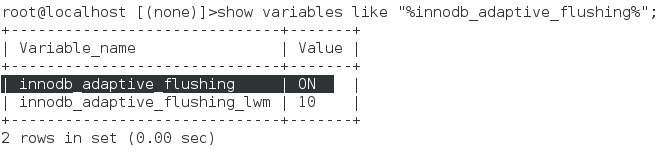
- 3、innodb_adaptive_flushing 参数控制,其影响每秒刷新脏页的数目,默认开启
6、InnoDB的三大特性
-
1、插入缓冲
把普通索引上的DML操作从随即I/O变成顺序I/O,提高I/O效率
原理是:先判断插入的普通索引页是否在缓冲池中,在就直接插入,不在就先放到change buffer 中,进行change buffer 和普通索引的合并操作,可将多个插入合并到一个操作中,提高普通索引的插入性能 -
2、两次写(double write)
保证写入的安全性,防止MySQL实例发生宕机的时候,InnoDB发生数据页部分页写的问题,如果页损坏了,redo log 是无法恢复的,所以需要有页的副本,如果实例宕机了,先通过副本把原来的页还原出来,再通过redo log进行恢复、重做 -
3、自适应哈希索引