平面提取论文
文章目录
- 单张图片输入
- 几何方法
- √(2015)Recognising Planes in a Single Image
- ×(2012)Detecting planes and estimating their orientation from a single image
- √(2009)Accurate 3D ground plane estimation from a single image
- √(2009)Geometric reasoning for single image structure recovery
- √(2007)Automatic single-image 3d reconstructions of indoor Manhattan world scenes
- (2001)Ground Plane Segmentation for Mobile Robot Visual Navigation
- 神经网络
- √(2019)Single-Image Piece-wise Planar 3D Reconstruction via Associative Embedding
- √(2019)Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
- √(2018)PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
- √(2018)Recovering 3D Planes from a Single Image via Convolutional Neural Networks
- √(2018)PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image
- 多张图片输入
- √(2010)Multiple Plane Detection in Image Pairs using J-Linkage
- (2010)Piecewise Planar and Non-Planar Stereo for Urban Scene Reconstruction
- √(2009)Manhattan-world Stereo
- (2009)Piecewise planar stereo for image-based rendering
- 点云输入
- (2016)Analysis of Efficiency and Accuracy of Plane Fitting Methods
- (2012)Indoor Mapping Using Planes Extracted Rome Noisy RGB-D Sensors
- (2011)The 3D Hugh Transform for Plane Detection in Point Clouds: A Review and a new Accumulator Design
- √(2011)Real-Time Plane Segmentation using RGB-D Cameras
- (2010)Plane Detection in Point Cloud Data
- √(2010)Robust Piecewise-Planar 3D Reconstruction and Completion from Large-Scale Unstructured Point Data
- (2008)Fast Plane Detection and Polygonalization in noisy 3D Range Images
- 相关领域
- SLAM
- √(2017)Keyframe-based Dense Planar SLAM
- (2014)Dense Planar SLAM
- (2013)Point-Plane SLAM for Hand Held 3D Sensors
- 矩形检测
- (2008)Detection and matching of rectilinear structures
- (2003)Extraction, matching, and pose recovery based on dominant rectangular structures
- 场景理解
- (2014)Unfolding an indoor origami world
- 恢复场景三维结构
- (2016)Efficient 3D room shape recovery from a single panorama
- (2008)Fast Automatic Single-View 3-d Reconstruction of Urban Scenes
- 表面布局恢复
- (2007)Recovering surface layout from an image
这篇博客是我在准备写关于平面提取综述的时候记笔记用的,里面有我读每一篇相关论文时记录的一些信息,比如现实应用、优缺点、大体和详细方法等。
所有的笔记都是我边读边写的,没有系统的框架,只求自己看懂,然后给大家一个参考,若有哪儿理解有偏差欢迎评论区讨论:)
前面带√的表示我已经读过了。然后读过了没有笔记的,是因为是以前读的,笔记记在其他地方,有空了想补的话补上
最后,我现在本科大四,水平实在有限,有些翻译直接搬的谷歌翻译。
单张图片输入
几何方法
√(2015)Recognising Planes in a Single Image
- 优点:无需任何场景约束,平面数量也没有限制,准确度还行(对点的分类达到83.6%的准确度,方向误差的中位数达到15°,检测出的平面占图像面积75%)。
缺点:无法提取小平面(因为先判断图像区域再判断整张图片);平面边缘效果不好(因为来自点的德劳内三角化) - 大致方法:分为两部分——plane recognition algorithm + graph-based detection stage
- Plane Recognition
输入:平面的某个区域(半径50像素),而不是整张图片
输出:该区域是不是平面(为平面的概率),是的话给出平面法向量。
流程:1)使用DoG(其实就是SIFI)提取特征点,然后以点为圆心选取一个patch;2)每个patch提取边缘和颜色信息,建立梯度方向直方图和RGB直方图;3)第一轮降维:词袋,用K-Means分别聚类梯度方向和颜色直方图得到“词”,从而建立两个“词典”;4)第二轮降维:主题,使用Latent topic model;5)由于词袋丢失了空间信息,使用空间直方图(spatiograms)来还原位置信息;6)RVM + sigmoid函数判断某个图片区域是平面/非平面,是平面的话,使用多变量回归RVM得到区域方向。注意,此时区域的概率和方向就是区域中每个特征点的概率和方向
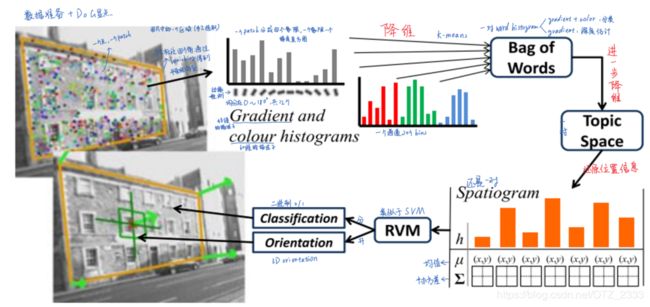
- Plane Detection
输入:一张照片的100个区域,以及它们经上一部分算法后的结果,即概率+方向。注意:图片区域选取的方法未知,但是会有重叠
输出:平面实例+它们的方向
流程:1)由于区域之间会有重叠,图片中的一个点可能会属于多个平面,因此该点会有多个处于平面的概率和方向,只保留概率最高的结果。这样图片中的每个点只有一个概率和方向;2)使用德劳内三角化把所有点连接成网格,再根据所有点的概率使用MRF,将平面/非平面区域划分开;3)对所有点的方向使用均值漂移聚类获得几个主要方向,再根据这些主要方向使用MRF,将不同的平面实例分割开;4)其实到第三步就够了,但是为了证实提取出来的是平面区域和为了提升方向估计效果,又将每个平面实例区域输入上个“Plane Recognition”部分再次计算(然而实验表明没卵用)
备用方案:因为对于马路之类缺少纹理的地方,使用SIFT不能很好地提取特征点。论文提出,可以使用网格来代替SIFT特征点,即每10个像素(或者5、20、40个像素)取一个点以代替DoG point,patch的大小就是20个像素(或者10、40、80个像素。然后用所有点的上下左右连起来的网格代替德劳内三角化,其他不变。
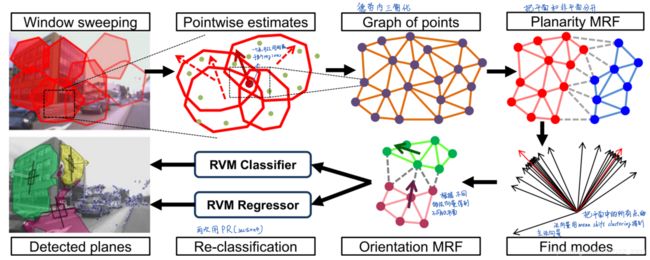
- 相关知识点
- 宽基线(wide baseline):宽基线一词用于匹配时,泛指两幅图像有明显不同的情况下的匹配。
- 纹理压缩(Texture compression):是一种专为在三维计算机图形渲染系统中存储纹理而使用的图像压缩技术。与普通图像压缩算法的不同之处在于,纹理压缩算法为纹素的随机存取做了优化
- 相关工作(翻译)
已知一个平面中的两对甚至更多的平行线,他们对应的灭点可以确定唯一的平面方向【17】。因此,在图片中提取这样的特征就可以提取平面。一种方法是寻找窗户、门之类的矩形结构【22】【27】,从而找到一个平面中的相互正交的平行直线,这可以恢复相机姿势和匹配宽基线(wide baselint)。但是这种方法只有在曼哈顿世界假设的环境中,检测到可靠的线条才有效,因此应用有限。
在形状纹理方法中,图片纹理的变化与表面形状有关,可以通过纹理恢复方向或曲率。以【10】的工作为例,使用投影后肉眼可见的纹理压缩来确定平面的倾斜(slant and tilt)。需要注意的是,这类方法通常不会解决检测问题,而是假定图像包含单个平面。
【1】使用了上述的几何方法和机器学习,利用对一个场景的主要垂直结构、地平线位置的估计,再加上一个线段分类器来识别地平线。这种方法也可以给出一个城市的大致3D重建,但远不能提供精确的平面方向估计。
机器学习方法。近来,更多的工作关注到可以学习外观与结构之间关系的技术。最好的例子就是【35】,利用“特定的结构往往出现在特定距离”的先验来估计总体深度。【32】更进一步,使用标注了绝对深度的图片来训练,然后估计整张照片的深度图。他们可以使用小平面建立场景的简单3D模型,并且它们的结果与ground truth比较,表现出不错。然而,它们的结果并不能准确地表现更高一级的结构——超像素片段都被当做局部平面了,且论文并未提及小平面方向的精度。相反,它们的目标是生成场景的视觉上合理的效果图,而且由人类评估。这与本文展示的工作相反,我们就是要找到图片中的大型平面,并分配给他们一个准确的方向。【19】的方法与我们的最像,多种纹理、颜色特征,加上明确的灭点,将平面片段分成粗糙的几何类别,代表“支撑表面”(水平)、“垂直表面”(左、右、正面)。这种粗糙的分类用于生成一般的场景布局,创建简单的“pop-up”式3D模型,或作为物体识别的先验。他们将图片分类成多个几何类别的方法弥合了语义理解和3D重建之间的差距。然而,由于方向是粗略量化的,这意味着重建的3D模型缺乏特殊性,无法区分出相似方向的平面。此外,他们要求的“相机与地面大致对齐”、“将灭点作为线索”,导致他们无法充分利用一般信息。跟我们的方法的主要不同点在于,他们并未像我们那样提供准确的平面估计,而是将结果量化为少量离散的几何类别。
×(2012)Detecting planes and estimating their orientation from a single image
此文跟15年的论文Recognising Planes in a Single Image作者一模一样,干的事情好像也差不多(只粗略看了一下图片),就没有进一步看了
√(2009)Accurate 3D ground plane estimation from a single image
- 优点:提取效果不错。估计的深度与真实值平均误差0.几米,且不受纹理变化影响;
缺点:只能提取水平地面,不能提取其他平面 - 大致方法:1)将图片转为YCbCr色彩空间,然后使用9个Laws mask filter、2个local averaging fliter、6个Nevatia-Babu texture gradient filter从纹理能量、纹理梯度、雾霾信息中提取特征向量。特征向量包含两部分——绝对特征向量(表示一个像素的深度信息)和相对特征向量(表示两个像素之间的深度关系);2)使用一种基于MRF的监督学习来估计深度图,并使用主成分分析(PCA)来估计MRF的平滑参数以面丢失障碍物信息。训练的时候则使用了最大后验概率(MAP)实现迭代梯度下降算法。3)从图片中提取超像素,然后转成图(graph);4)从底部中间的超像素开始(因为这儿最可能是地面),根据前面估计出的深度图,利用广度优先搜索(BFS)找出方向相似的超像素,和已有的融合。不断重复,直到分割出水平地面;5)利用相机内参/外参可以得出水平地面的绝对深度 d d d,即
d = D ∗ h ∗ ( h 1 − h 2 ) h 1 ∗ ( h 2 − h ) d = \frac{D*h*(h_1 - h_2 )}{h_1*(h_2 - h)} d=h1∗(h2−h)D∗h∗(h1−h2)
其中 P P P是相机光学中心, h h h是相机高度, f f f是相机焦距, I I I是成像平面, h 1 h_1 h1和 h 2 h_2 h2是地面在成像平面上的投影的下/上边界, D D D为图片中最下面一行对应的地面与成像平面的距离(来自相机外参)

√(2009)Geometric reasoning for single image structure recovery
- 优点:特定场景下效果不错(平面分割+深度估计的精度看着都挺好)——像素分类正确率为81%;可以推测被遮挡的地板与墙面的边界
缺点:场景约束太强(基本就是一个复杂盒子模型),不区分平面/非平面 - 约束:
- 室内场景+曼哈顿世界假设+一个地板一个天花板。这样约束的好处有:1)很容易用二维结构去表达三维世界;2)地板与墙面的连接线通常会被物体遮挡,可以通过天花板与墙面的连接线来推测被遮挡的地板与墙面的连接线
- 几何推理:拐角(不同墙的连接初)有三种——凸的、凹的、遮挡的;拐角的连接点有两种——和天花板连接的(地平线之上)、和地板连接的(地平线之下);2条垂直的灭线将图片划分为3个区域。总共有12种情况,每种情况都由五条线构成,见下图右;但其实,凹、凸拐角只需3条线就能表示,遮挡的拐角只需4条线,见下图左
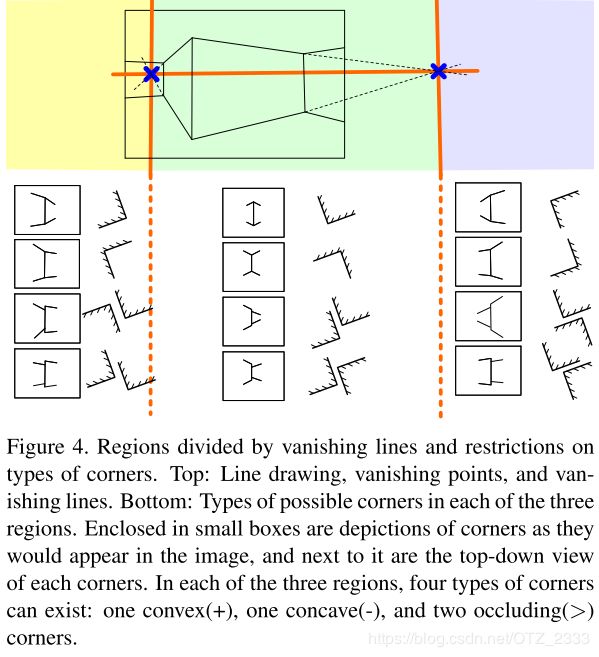
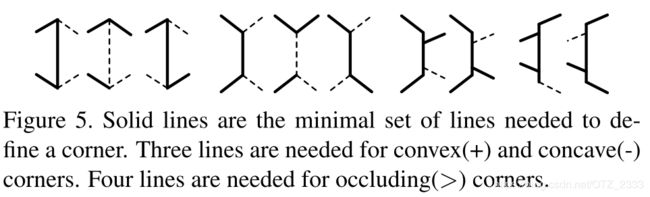
- 大致方法:1)用【16】的Matlab工具箱(Canny边缘检测)提取线段,然后用RANCA提取灭点(要求相机内参,没有的话用三对线段确定灭点),进而得到曼哈顿世界假设中的三个主要方向;2)每两条平行线(一个在地平线上,一个在下)向其两端延长到图片的边界,作为天花板和墙面的交线、地板和墙面的交线,形成一面墙;然后找新的可以跟这面墙交叉出拐角的平行线,与上图左右比较,确定拐角类型,从而生成一个平面假设;不断重复,找出所有的假设,见下图左;3)将指向同一个方向的所有线段归成一类,对于图中每一个像素点,找出将其包围的两种线条(不可能三种线段包围一个像素点,只能两种),改像素点的方向垂直这两条线,然后将方向相同、相近的像素聚类得到深度图,见下图右;4)将每一个平面假设跟深度图相对应的区域匹配,然后保留每个区域中匹配度最高(像素点最多)的平面假设。

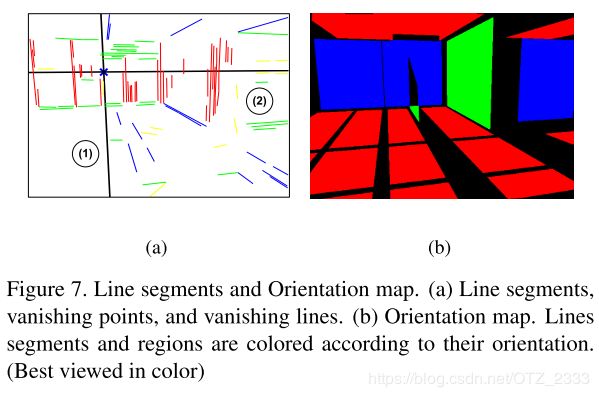
Reading | 一张图建一个屋
灭点检测算法综述
Canny边缘检测算法
√(2007)Automatic single-image 3d reconstructions of indoor Manhattan world scenes
- 优点:效果不错(平面的召回率80.6%,精确度89.1%)
缺点:不区分平面/非平面 - 大致流程:约束——室内+曼哈顿世界假设
1)使用Canny算子、Sobel算子、相位一致性提取边缘,然后利用强度梯度的方向确定灭点。还要用线段提取算法提取线段,并给每个线段分配一个灭点(即方向);2)使用基于图的分割算法【9】从颜色、纹理提取超像素;3)由于很多平面(比如墙)与地板相连,所以使用动态贝叶斯网络(DBN)专门提取水平地面掩膜;4)将图片划分为320*240的网格,然后使用MRF根据格点的特征将其分类,生成粗糙的平面分割+深度估计;5)使用拉普拉斯概率分布来优化结果,得到最终的3维结构。
(2001)Ground Plane Segmentation for Mobile Robot Visual Navigation
神经网络
√(2019)Single-Image Piece-wise Planar 3D Reconstruction via Associative Embedding
- 相关知识点:
- 外观(appearance):纹理+颜色
- 二次规划(Quadratic programming):求解一种特殊的数学优化问题的过程——具体地说,是一个(线性约束)二次优化问题,即优化(最小化或最大化)多个变量的二次函数,并服从于这些变量的线性约束。二次规划是一种特殊的非线性规划。
- RPN(Region Proposal Network):本质是基于滑窗的无类别obejct检测器
- Associative Embedding:一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“标签”,换句话说,标签将每个检测与同一组中的其他检测相关联。
- 相关工作(翻译)
基于几何的方法【6,2,24,20】通过二维图片中的几何线索来恢复3D信息。比如,【6】第一个从图片中提取出线段、灭点和超像素,然后用MRF模型给超像素打上标签,标签是预先定好的平面分类(比如曼哈顿世界假设下的三个主要平面)。同样,【2】假设环境由一个平地和多个垂直的墙组成,然后用条件随机场(conditional random field, CRF)给检测出来的基元打标签。【20】从一张图片中检测出线段和灭点,然后从最能匹配上几盒基元集合的假设集中,找到建筑模型。但是所有这些方法都依赖于强烈的场景假设,因此在现实中应用有限。
基于外观的方法,通过图片的外观推断几何原语。早期工作【15,10,12】使用一种自下而上的方法,他们先预测局部的图像小块(patch)的方向,然后将方向相似的小块聚合形成平面区域。【15】定义了一系列离散的表面布局标签,比如“支撑”、“垂直”、“天空”等,并且使用大量手工制作的局部图片特征(比如颜色,纹理,位置和透视(perspective))训练一个模型,来给一张图片中的超像素打标签。【12】的方法学着给预分割出的区域预测连续的3D方向,并将平面检测转变成使用MRF模型的优化问题。【10】第一个检测凸边/凹边、遮挡边界、超像素及其方向。然后将聚类问题表示为曼哈顿世界假设下的二进制二次规划(binary quadratic program)。本文的方法也属于这一类。与现有方法不同的是,本文将平面检测转变成实例分割问题,其中我们使用了一种相似度量标准来直接分割图片中的平面实例,然后为每个平面实例估计平面参数。
近来,几个基于CNN的方法可直接预测全局的3D平面结构。【23】提出一种深层神经网络可以学着去给图片中的每个像素推断平面参数和对应的平面ID(即分割眼膜)。【31】将问题转变为深度预测问题,并提出了一种不需要ground truth 3D平面的训练方案。然而这些方法都只能预测固定数量的平面,可能导致复杂环境中的糟糕表现。同时,【22】使用一种基于提议(proposal-based)的实例分割结构,也就是Mask R-CNN。相反,我们使用的一种无需提议的实例分割方法来解决这个问题。
2019 CVPR 论文之Single-Image Piece-Wise Planar 3D Reconstruction via Associative Embedding的翻译
SPPR阅读笔记:单张图片的3D平面重建
√(2019)Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
- 应用: AR、CAD之类的高质量视觉任务
- 相关工作:
- SfM、视觉SLAM中,生成的点云不完整、有噪声、不易存储和分享的问题,可用plane-fitting[12]、mesh-refinement[13],但是仍然不能用于手持相机、手机的高质量3D建模的需求
- 文献[2]: 人类不是用点云,而是用线、轮廓、平面、平滑表面来感知3D场景
- 使用深度学习寻找图片中的几何结构: 平面【30, 19】、表面【10】、2D线框(wireframe)【13】、房间布局(room layout)【35】、mesh fitting的关键点【31, 29】
- SfM、视觉SLAM使用SIFT、ORB、line segments[11, 5, 24]来提取角形特征
- 之前的一些论文试着在诸如SUNCG的3D人造数据集的帮助下,理解室内场景【25,32】。
- 大致方法:
- 输入——单张RGB图片(人造城市场景);先验——曼哈顿世界假设;
- 数据集: 由于只有2D的线框数据集,没有深度信息或者两种连接点,需要自建数据集——大量的人造城市场景(来源SceneCity数据集),具有准确的深度信息和从网格边缘提取的线框 + 少量的真实图片(来源MegaDepth V1 dataset[18]),精度稍微弱点
- 使用two-stack hourglass神经网络[23]预测全局线(Global lines, 两个平面的物理交线,包括平面的纹理线条)和两种连接点(c-junction: 直观可见的线面的交点,t-junction: 被遮挡的两条线的交点)以及它们的深度、灭点
- 使用矢量化(vectorization)将线和连接点变成图像空间的2.5D热图(image-space 2.5D heatmap)
- 在AD和3D设计等场景中,绝对深度信息是3D线框的6个自由度的操作所必须的。而神经网络预测的深度只是相对深度,还需要相机内参来确定绝对深度。但是对于MegaDepth之类的数据集,不提供相机内参。可以通过符合曼哈顿世界假设场景的3个相互正交的灭点来估计相机内参[21]
- 利用灭点改进神经网络估计出的深度。因为论文发现对灭点的估计比深度的估计更可靠,而这个可能是因为灭点的几何线索更多
- 最终生成3D的线框模型。
PS: 窗户之类的规则纹理上的线条会用于神经网络预测线框,但不会出现在最终结果里
- 未来工作:
- 更好的数据集: 高质量的图片和3d模型
- 扩展线框表示: 识别更复杂的几何结构(曲线、任意表面),并且无需曼哈顿世界假设
√(2018)PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
- 输入: 单张彩色图片
- 网络: pre-trained Mask-RCNN + 一种新奇的损失函数Warping Loss + 一种新的基准(benchmark) – 在ground truth中拥有更精细(finegrained)平面分割
- 输出: piecewise planar surfaces = plane parameters + segmentation masks
单独的平面 = 平面参数 + 分割掩膜 - 优点: 在平面检测、分割、重建的指标上比现有最先进的方法表现还好;鲁棒的平面提取(plane extraction);能检测小的平面;不用预先知道场景中最大平面数量;较好的跨区域泛化性
- 相关工作(翻译)
3D平面检测及重建,大多数传统的处理方法【10, 12, 37, 38, 52】需要多个视图或深度信息作为输入。他们用平面拟合3D点来生成平面候选区域,然后通过一个全局推断来为每个像素点分配候选区域。【7】提出了一个基于学习的方法用来恢复平面区域,但该方法仍然需要深度信息的输入。
最近,PlaneNet【27】通过从单张室内RGB图像得到的端到端(end-to-end)学习框架,重新看待了分段平面深度图重建问题。PlaneRecover【49】 后来提供了一种针对室外场景的非监督学习方法。PlaneRecover 和 PlaneNet 都将任务描述成一个有固定平面数量的像素分割问题(也就是PlaneNet 中10个平面和 PlaneRecover中5个平面),这严重限制了不同场景类型重建和泛化能力的表现。我们利用常用于物体识别的检测网络解决了这些限制。
基于检测的框架现已成功应用于许多3D理解得任务,比如,以边框(bounding box)【5,9,32】、线框(wireframe)【22,47,57】、or基于模板的形状组成(shape composition)【2,21,31,48】,来预测物体形状。然而,这些方法的粗略表示没有能力来精确地建模复杂、混乱的室内场景。
除了检测以外,分割掩膜的联合细化(joint refinement),对于一些需要精确平面参数和边界的应用来说,也很关键。在最近的语义分割技术中,全连接条件随机场(CRF)被证明对于局部的分割边界是有效的【4,20】。CRFasRNN 【55】在端到端的训练中促进了它的可辨别性。CRF 使用的只是低级信息,全局的上下文信息通过 RNNs【1,23,36】、更通用的图形模型【30、24】、or新型的神经架构设计【53,54,51】进一步发掘。这些分割细化技术不能感知实例,仅仅是在每个像素上进行的推断,并不能区别多个实例属于同一个语义的种类。
实例感知(instance-aware)的联合分割细化带来了更多的挑战。传统的方法【39,40,41,43,50】将场景当作图形来建模,然后使用图模型推理技术来联合优化所有的实例任务。使用一系列试探法,这些方法通常不鲁棒。为此,我们提出了一个能在检测网络之上、联合优化任意数量的分割掩码的分割细化网络。 - 方法框架: 三部分
- Plane detection network: 平面检测网络,基于Mask-RCNN。
- Segmentation refinement network: 分割细化网络
- Warping loss module:
翘曲损失模型
- 实验结果:
- 定性评价:PlaneRCNN对场景变化(大小、形状、纹理等)更鲁棒
- 平面检测(detection)精度:除了在深度误差阈值很小的时候MWS-G能利用真实实例深度值非常准确的拟合3D平面,PlaneRCNN效果最好
评价指标:平面召回量 = IOU阈值(0.5)+非固定深度误差阈值(0m-1m, 增量为0.05m)。这个准确性是在真实样本和检测出样本的重叠区域下计算测量的PlaneNet - 几何(Geometric)精度:新的方法
评价指标:联合估计的深度图和真实样本的平面分割——对于每个ground-truth的平面分割,利用Warping loss模型估计出的深度将其还原成3D的点,通过SVD 拟合3D平面,通过归一化平面系数将法向量变成单位向量,最后计算参数差异的均值和面积加权均值作为评估指标;除了这个平面参数标准以外,我们也使用文献8中的深度图评估标准。 - 模型简化测试:PlaneRCNN 在 Mask R-CNN 的主干网络里添加了:1)像素点的深度估计网络,2)以anchor为基础的平面法线回归,3)Warping loss模块,4)分割细化网络。通过一个一个的添加这些组件,然后测量比较性能的改变。
评价指标:variation of information (VOI)、Rand index (RI)、segmentation covering (SC)、average precision (AP,用 IOU 阈值为0.5和三个不同的深度误差阈值[0.4m, 0.6m, 0.9m]来计算)——除了VOI之外,数值越大代表效果越好
结果:每一个组件都增加了性能表现 - 遮挡推理:
目的:推断出被遮挡的平面并且重建分层的深度图模型
方法:添加一个掩膜预测模块
以下为具体方法
A. Plane detection network
- 直接用Mask R-CNN可以意外地很好地直接检测出 plane / non-plane,并且对平面数量没有限制
- 用Mask R-CNN进行平面实例分割
- 估计三维平面参数:normal + offset information(法线+偏移信息)。CNNs可以成功地估计深度图和表面法线。但plane offset是个挑战(即使用了CoordConv),方法分为三个步骤:
- Plane normal estimation(Local image analysis): 在ROL pooling后直接连接一个参数回归模型,就可以得到合理的结果。但是对边界框回归借用二维anchor box可以进一步提高精度,具体分三小步: 1)选取一个anchor normal;2)回归残差三维向量;3)将和归一化为一个单位长度的向量。对1万张训练集图片的plane normal进行k-means聚类(成7类),聚类中心为Anchor normals。将原始Mask R-CNN的object category prediction替换成anchor ID prediction,再加一个独立的全链接层来输出每个anchor normal的三维残差向量(residual vector)。
- Depthmap estimation(Global image analysis): 在Mask R-CNN的FPN后面加了个decoder,就可以得到depthmap。 再双线性上采样跟输入大小一致,640*640
- Plane offset estimation: 对于一个平面法线 n n n,其plane offset d d d满足如下公式
d = ∑ i m i ( n T ( z i K − 1 x i ) ) ∑ i m i d = \frac{\sum _i m_i(n^T(z_iK^{-1}x_i))}{\sum _i m_i} d=∑imi∑imi(nT(ziK−1xi))
K K K是内参矩阵, x i x_i xi是第i个像素坐标(齐次), z i z_i zi是预测的深度值, m i m_i mi是标志位,如果像素属于这个平面则为1。所有像素都参加计算。
B. Segmentation refinement network
- 上个部分独立进行分割掩膜,这个部分则联合优化所有掩膜。挑战: 平面数量不定问题
- 其他人的一种方法: 假设平面的最大数量,联结所有掩膜,对缺失的部分填充0。缺点: 有上限,容易丢失小的平面。
- 本文使用ConvAccu,基于non-local module。输入为平面掩膜、原始图像、其他所有平面掩膜的并集、重建的深度图(平面+非平面)、特定平面的三维坐标图。
ConvAccu用卷积层处理image window中的每个平面分割掩膜;在传入下一层前,计算和联结同一层面的所有其他平面的平均特征;最后将精细的平面掩膜联结,使用交叉熵损失跟真实样本进行比较。
使用ConvAccu构造了U-Net结构。
C. Warping loss module
- 加强了重建好的三维平面跟nearby view(当前帧的前20帧)的一致性。
- 先对每一帧建立depthmap: 1)在相机坐标系中,从plane equation(?)计算平面区域的深度值;2)用Plane detection network 中为剩下像素(非平面区域)预测的像素深度值。再用相机内参矩阵将depthmap转化为3D坐标图。
- 计算Warping loss: 3D坐标图中,当前帧和nearby frame的3D坐标图分别用 M c M_c Mc和 M n M_n Mn表示。对于 M n M_n Mn中的每个3D点 p n p_n pn,用相机姿态信息就可以投射到当前帧,再用bilinear interpolation(双线性插值?)从 M c M_c Mc中读出 p c p_c pc。再根据相机位姿将 p c p_c pc转换到nearby frame的坐标系中,计算 p c t p_c^t pct、 p t p_t pt的三维距离。
W a r p i n g l o s s = 所 有 这 样 的 三 维 距 离 像 素 数 量 Warping \; loss = \frac{所有这样的三维距离}{像素数量} Warpingloss=像素数量所有这样的三维距离
D. Benchmark Construction
- 增加图片中的平面数量的三个修改:
- 减小单个平面区域(占整张图的比重)的阈值,从而保留小平面
- 不把一些共平面标记为一个平面(PlaneNet是当成一个平面的)
- 通过(生成的)ground-truth 3D plane跟传感器获得的原始深度图进行比较,从而找出image跟投影得到的ground-truth plane不重合的情况。也就是说,删除平面区域中平均深度差异(?)>0.1m的图片
《PlaneRCNN-单幅图像的三维平面检测与重建》论文中英文对照解读
【泡泡图灵智库】PlaneRCNN:单张影像的三维平面检测与重建(avXiv)
√(2018)Recovering 3D Planes from a Single Image via Convolutional Neural Networks
- 相关工作:
基于几何的方法明确分析了2D图片中的几何线索来恢复三维信息。比如,在针孔模型中,3D空间中平行的线条投射到图片中就会变成图片里平面上趋于一点的线条。相交处可能在无穷远,这称为灭点(vanishing point)【13】。通过检测一个平面的两对平行线的灭点,就可以确定该平面唯一的3D方向【6】【27】【3】。另一个重要的几何基元就是连接点(junction),由2条甚至更多的不同方向的线条交汇而成。有几篇论文使用连接点来生成看似可信的3D平面假设or者移除了不可能的那些平面【21】【34】。另一种不同的方法是检测图片中的矩形结构,其通常由一个平面的两对相互垂直的线条构成【26】。然而所有的这些方法都依赖于使用强烈的常规结构,比如曼哈顿世界假设中的平行or垂直线条,因此在现实中应用有限。
为了克服这种限制,基于外观的方法专注于从图片中的几何基元推断出外观。比如,【16】提出一个多样的特征集合(比如颜色,纹理,位置和形状),然后用它们训练一个模型,把图片中的每个超像素分类成离散的类别,比如“支撑”、“垂直”(左/中/右)。【11】使用一种基于学习的方法来为每个像素点预测连续的3D方向。还有,【9】为了单张图片的理解,自动学习有意义的3D基元。本文方法也属于这一类。但不同于现有的方法,即聚类局部几何基元的自下而上的方法,我们的方法训练一个网络来直接预测3D平面结构。最近,【22】也提出了一个深层神经网络,用于单张图片的分段平面重建。但这种训练要求ground truth 3D平面,并且没有利用数据集中的语义标签。
机器学习&几何。有大量论文使用机器学习来推断场景的像素级别的几何基元,而且主要是深度估计【30】【7】和表面法向估计【8】【18】。但几乎没有方法使用监督数据来检测中高水平的3D结构。有一个例外,且跟我们的问题相关,就是研究室内房间布局(layout)的估计。然而在这些工作中,几何结构就是包含了几个人造垂直平面(比如地板、天花板、墙)的简单“盒子”模型。相反,我们的工作是为了检测任意情况下的3D平面。
√(2018)PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image
- 相关工作:
多视图(Multi-view)的片段平面重建分段。平面深度图的重建,曾经是多视图三维重建的热门研究话题【12,31,13,40】。这个任务就是推断出一系列的平面参数,并给每个像素点分配一个平面ID。现有的方法第一步都是建立精确的3D点,然后使用平面拟合方法(plane-fitting)生成平面假设,然后解决一个全局推断问题,就可以重建出分段平面的深度图。我们的方法直接从一张彩色图片中,推断平面参数和平面分割。 - 应用: 1) AR: 放东西在桌子上[17], 更换地板纹理;2) 机器人: 识别地板从而进行路径规划,识别桌面来放东西
- 缺点: 平面数量有上限;在低亮度、两个物体颜色相近、杂乱的地方,分割效果不好;
- 大致方法:
- 数据集: ScanNet。平面 = 语义标签 + RASAC提取。两个平面间距离大于5厘米,且一个平面包括其所在区域90%的点;不同于一标签的平面角度小于20度,且大平面和小平面平均距离误差小于5厘米,则融合两个平面;剔除面积小于图片1%的平面,剔除所有平面占总图片面积<50%的图片
- 神经网络: DRNs(Dialted Residual Networks) = 101-layer ResNet + Dilated convolution
三个分支: 平面参数、非平面深度图、分割掩膜
- 实验对比:
- 平面分割精度:
NYU-Toolbox[30]:是一个平面提取算法,来自NYU官方工具箱,使用RANSAC提取平面假设,然后通过马尔可夫随机场MRF来优化平面分割。
MWS[12] (manhatten-world stereo):除了在提取平面的时候使用曼哈顿世界假设并且利用vanishing line优化结果,其他和NYU-Toolbox类似。
PPS[31] (Piecewise Planar Stereo):放宽了Manhattan World假设,使用消失线来生成更好的平面提取 - 深度精度: Eigen-VGG[7]、SURGE[35]、FCRN[20]
深度学习之PlaneNet
《PlaneNet-单幅RGB图像的分段平面重建》论文中英文对照解读 - 平面分割精度:
多张图片输入
√(2010)Multiple Plane Detection in Image Pairs using J-Linkage
- 应用:stable landmarks for vision-based urban navigation
- 优点:72%的识别率;不需要先验(平面数量);没有false positives,即只会检测不到平面,不会把非平面区域当成平面;
- 步骤:SIFT matches → \rightarrow → generate multiple local homography hypotheses using J-Linkage → \rightarrow → globally merge → \rightarrow → spatially analyze → \rightarrow → robustly fit → \rightarrow → check for stability
- 缺点: 测试使用的图片全部为室外的,对室内的效果未知,且图片全为灰度,没有利用彩色信息;受限于SIFT——对于缺少纹理(比如屋顶、窗户)、太小、视角变化太大的平面对,方法的第一步就失效了,即SIFT检测不到、检测到太少特征点;
以下为具体方法
A. Feature correspondence extraction
- 步骤:
- 一对灰度图片(2张),分别用SIFT提取特征(点+描述子) I 1 I_1 I1、 I 2 I_2 I2
- I 1 I_1 I1中的每一个特征 p p p,使用nearest-neighbor search找到ta在 I 2 I_2 I2最近、第二近的 q q q、 q ′ q' q′
- 若满足欧氏距离 ∣ p − q ∣ ∣ p − q ′ ∣ \frac{|p-q|}{|p-q'|} ∣p−q′∣∣p−q∣小于设定的阈值,就确立correspondence c = ( p , q ) c = (p, q) c=(p,q)
- 用 x 1 c x^c_1 x1c、 x 2 c x^c_2 x2c分别独立地表示特征在两张图中的位置
B. Initial hypotheses using J-linkage
- 步骤
- 随机选择k个minimum sample sets (MSS):每个MSS包括四个correspondence,代表一个homography。其中第一个correspondence人工绘制(为了增加选择到一个由inlier组成的MSS的可能性)
- H 1 , . . . , H k H_1, ... , H_k H1,...,Hk代表每个MSS指定的homography;每个correspondence c c c,计算得ta的preference set P c P_c Pc,代表拟合 c c c足够好的模型的子集
P c = { H j : e r r H j ( c ) < ϵ , 1 ≤ j ≤ k } P_c = \{H_j : err_{H_j}(c) < \epsilon, 1 \leq j \leq k\} Pc={Hj:errHj(c)<ϵ,1≤j≤k}
其中, e r r H j ( c ) = ∣ H ( x 1 c ) − x 2 c ∣ err_{H_j}(c)=|H(x^c_1)-x^c_2| errHj(c)=∣H(x1c)−x2c∣,表示 c c c用 H H H变换后的reprojection error(二次投影误差); ϵ \epsilon ϵ为阈值,取1.5个像素。
多个 c c c的preference set则为ta们的 P c P_c Pc的交集。 - 用J-Linage进行聚类:
d J ( X , Y ) = ∣ X ∪ Y ∣ ∣ X ∩ Y ∣ X ∪ Y ∣ d_J(X, Y)=\frac{|X\cup Y||X\cap Y|}{X\cup Y|} dJ(X,Y)=X∪Y∣∣X∪Y∣∣X∩Y∣
其中, X , Y X,Y X,Y表示一不同的 P c P_c Pc;
d J d_J dJ最小的一对 P c P_c Pc将被融合。不断融合,直到所有 d J = 1 d_J=1 dJ=1,即所有 P c P_c Pc都没有相交。 - 然后剔除少于6个 c c c的 P c P_c Pc(因为很多outlier是在小的 P c P_c Pc中),剩下的每一个 P c P_c Pc代表一个平面假设
C. Global merging
- 原因: 上一步的平面假设都只包含附近的点,即一个真正的平面,可能被分成多个平面假设
- 步骤:
- 用 d F d_F dF测量对所有 c c c的union拟合最好的一个模型的平均误差
d F ( X , Y ) = ∑ c ∈ X ∪ Y e r r H ^ ( c ) ∣ X ∪ Y ∣ d_F(X, Y) = \frac{\sum _{c \in {X \cup Y}} err_{\hat H}(c)}{|X \cup Y|} dF(X,Y)=∣X∪Y∣∑c∈X∪YerrH^(c)
其中, H ^ \hat H H^是 X ∪ Y X\cup Y X∪Y的透视变换的最小二乘解; - 当最小的 d F > ϵ ( ϵ = 1.5 像 素 , 跟 之 前 的 一 样 ) d_F > \epsilon (\epsilon = 1.5像素,跟之前的一样) dF>ϵ(ϵ=1.5像素,跟之前的一样),就不再将 X 、 Y X、Y X、Y融合
- PS: SIFT中的错误匹配(比如窗户)可能导致部分平面假设不能融合
- 用 d F d_F dF测量对所有 c c c的union拟合最好的一个模型的平均误差
D. Spatial analysis
- 原因: 之前的所有步骤只考虑了特征描述子,单应性空间的信息,还未利用特征位置(feature location)的信息,导致平面假设里有rogue correspondence
- 步骤:
- 在图片对的其中一张图片里,对于每一个平面假设计算其所有特征位置的Delaunay三角剖分,然后删掉长度比平均值大一个标准差的边长
- 若出现了分离的子图,则每个子图都作为一个单独的平面假设,并且要舍弃少于6个 c c c的子图
E. Robust fitting and stability checks
- 目的: 提高准确度,并进一步剔除outlier
- 步骤:
- 对于每个model(平面假设) C C C,再次利用最小二乘计算题最好的单应 H ^ \hat H H^(变换矩阵),删掉 C C C中 e r r H ^ ( c ) > ϵ i err_{\hat H}(c) > \epsilon _i errH^(c)>ϵi的 c c c,其中 ϵ i \epsilon _i ϵi是变化的阈值,开始的时候比较大,然后慢慢减小到1.5像素(跟之前的一样)——就是先把 e r r err err大的删掉,再删小的
- 使用与平面假设的边框大小成比例的、符合正态分布的噪声来轻微扰动两张图中的特征位置,计算最好的模型(平面假设),并将边框的角投影到这个新模型中
原因: 对于一个拥有良好分布特征并且稳定的模型,轻微扰动导致平面假设的边框位移的标准差应与扰动保持在同一个数量级 - 如果扰动后边框偏移的标准差过大,则否决掉这个模型
- 剩下的模型就是最终输出的平面
(2010)Piecewise Planar and Non-Planar Stereo for Urban Scene Reconstruction
√(2009)Manhattan-world Stereo
- 相关知识点:
- 照片一致性(photo consistency): 将投影到中的每个可见图像中,并且将它们投影附近的图像纹理的相似度计算为photo consistency
- 多视角立体视觉(Multiple View Stereo,MVS): 能够在多个视角(从外向里)观察和获取景物的图像,并以此完成匹配和深度估计
- 马尔可夫随机场:也叫概率无向图模型,具有马尔可夫性质的随机场。 随机场:当给每一个位置(site)按照某种分布随机赋予相空间(phase space)的一个值之后,其全体就叫做随机场
- 图割(graph cut):
- SfM(structure from motion): 一种三维重建的方法,用于从motion中实现3D重建。也就是从时间系列的2D图像中推算3D信息。
- 应用: 建筑(architectural)场景的三维重建——全局尺度上的多城市建模(比如谷歌地图)
建筑场景的特点: 包含大量具有严密结构的东西,比如缺乏纹理或者被绘画过的墙,尖锐的棱角,轴对齐几何 - 优点: 1) 输出结果干净、简单(clean and simple);2) 在缺乏文理的地方表现良好;3) 适用于室内、室外场景
- 大致流程: 输入: 一系列(a set of)校正过的图片
- 使用鲁棒的PMVS算法重建有纹理的区域,获得一系列定向的3D点(位置+法线),保留纹理区域内可信度高的点
- 使用均值漂移算法,从点的法线中提取三个主要的平面方向,即x, y, z坐标轴;从点的位置生成平面假设(和坐标轴平行)
- (主要步骤)使用马尔可夫随机场和图割(graph cut)恢复稠密的深度图
PS: 使用SfM恢复数据集的相机参数
- 未来工作: 1) 本文的主要目的为计算图片集合的深度图,未来工作可以着重于将它们融合成一个大尺度场景的模型;2) 探索用于建模更广泛的建筑场景的先验
(2009)Piecewise planar stereo for image-based rendering
点云输入
(2016)Analysis of Efficiency and Accuracy of Plane Fitting Methods
(2012)Indoor Mapping Using Planes Extracted Rome Noisy RGB-D Sensors
(2011)The 3D Hugh Transform for Plane Detection in Point Clouds: A Review and a new Accumulator Design
3D Hough变换点云平面检测算法
√(2011)Real-Time Plane Segmentation using RGB-D Cameras
- 优点:①实时;②可以可靠地检测障碍物,检测可抓取的物体以及支撑它们的平面,以及对所获取的3D数据中的所有平面进行分割和分类
- 相关知识点:
- 计算点云的法向量、曲率:点云中的一点 p p p,其周围 k k k个最近的点 or 所有距离它小于 r r r的点,可以计算这些点协方差矩阵的最小特征值和其对应的特征向量,然后估算 p p p点处的法向量,而最小特征值与所有特征值之和间的比例可以用来估算该点的曲率。 k , r k, r k,r不能太大(不然把拐角都抹平了),不能太小(不然噪声影响太大)。常用的方法是计算所有点距离估算出的平面的距离,反过来权衡这些点的协方差矩阵(计算量太大了);另一种方法是,计算旁边区域或者不同尺度下的法向量,从而为每个点选择最可能成为平面的法向量
- 积分图( integral images):虽然也可以理解为一张图,但该图上任意一点(x,y)的值是指从灰度图像的左上角与当前点所围成的举行区域内所有像素点灰度值之和。
- 反射矩阵(reflection matrix):反射矩阵将Q点变换为其关于平面n·p+d=0的对称点Q’’
- 正规空间(normal space)
- 大致方法: 输入:RGB-D
- 点云中的每一个点,分别连接其和下、右方向的点得到两个切向量
- 使用积分图( integral images),对领域内的所有切向量计算平均向量,从而进行平滑处理减少噪声的干扰
- 两个切向量叉乘获得该点的法向量
- 在normal space(貌似为下图右上角那个)中,对points聚类并融合后得planes
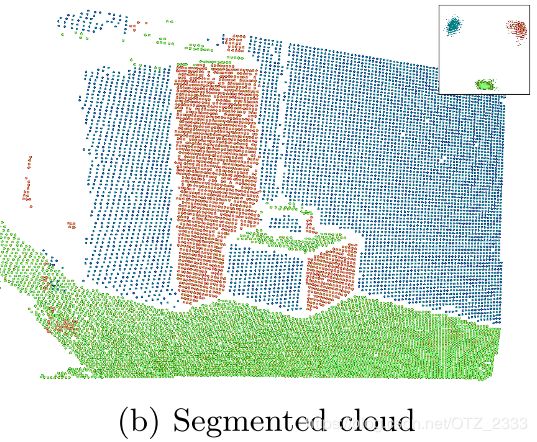
- 将法线的方向相似的小平面聚合成一簇(不同但平行的平面,图a)。使用相应的平均、归一化法线可以计算平面与原点的距离(图b),同时针对距离越远噪声越大的情况,使用对数直方图(logarithmic histogram)进行计算,一簇中落在同一bin(即距离相近)的点聚合成最终的平面(图c)

- 未来工作:更可靠、快速的方法来完成更复杂的任务(如点云的自主配准或利用获取的表面信息识别检测到的物体)
(2010)Plane Detection in Point Cloud Data
√(2010)Robust Piecewise-Planar 3D Reconstruction and Completion from Large-Scale Unstructured Point Data
-
应用:AR、导航、城市规划、环境影响评估的物理模拟
-
输入:无组织、高噪声、大量outliers的大规模点云(百万个点)
输出:轻量、封闭、无自相交的多边形网格 -
相关知识:
- K-最近邻算法(KNN):选择未知样本的一定范围内确定个数的K个样本,若该K个样本大多数属于某一类型,则未知样本判定为该类型。
- 主成分分析(PCA):通过正交变换将n维特征映射到k维上(k
- 区域生长算法(region growing approach):将具有相似性的像素集合起来构成区域。首先对每个需要分割的区域找出一个种子像素作为生长的起点,然后将种子像素周围邻域中与种子有相同 or 相似的像素(事先确定的生长or相似准则来确定)合并到种子像素所在的区域中。而新的像素继续作为种子向四周生长,直到再没有满足条件的像素可以包括进来,一个区域就生长而成了。
- Alpha Shapes:从离散的空间点集(point sets)中抽象出其直观形状的一种方法,简言之,从一堆无序的点中获取大致的轮廓。
-
方法原则
- 一阶近似
- 几何基元(primitive)的程度:平面(人造环境一定是分段平面的,曲面可以用平面逼近)
- 分析规模:平面距离、角度有域值
- 拓扑保证:本方法基于可将3D空间分解成空白or占用区域的标签,保证生成的表面封闭
- 可见一致性:通过获取过程提供的可见性信息来最大化表面的一致性
- 利用先验补齐被遮挡的地方:幽灵基元形式的先验。由假设的平面基元组成,这些平面基元可确保检测到的基元的预期连续性,并在城市和建筑场景中增强垂直结构和正交相交的普遍性。
-
大致方法: PS:论文重点在输出模型的简洁性和理想化,而不是精确度。
- 输入点云中任意两个点,若其都为对方的满足KNN算法的邻居,则它们为邻居
- 每个输入点周围一定距离的球域内,使用PCA估计该点的有向切平面(oriented tangent planes)
- 使用区域生长算法检测出平面基元,种子的选取参考文中提及的局部复杂度。在计算完基元之后,将构成它的所有点讲不再考虑(因此,此时每一个点都恰好分配给一个基元)。最后,舍弃太小的平面基元。
- 由于之前舍弃掉小的基元和采集点云时遇到的遮挡可能导致最终生成的模型不封闭,需要生成一些幽灵基元(ghost primitive)来补齐:使用二维的Alpha Shapes算法得出构成平面基元点的投影的边界,迭代合并后舍弃重复边界,保留真实边界,最终,包含边界的垂直平面、和前者正交且通过同一边界的平面,这两种平面即为幽灵平面基元
- 构建细胞复合体(cell complex),然后标记细胞复合体——太多了,看不下去了:(
- 使用Delaunay三角剖分,将很多小平面合成大平面,输出最终结果。
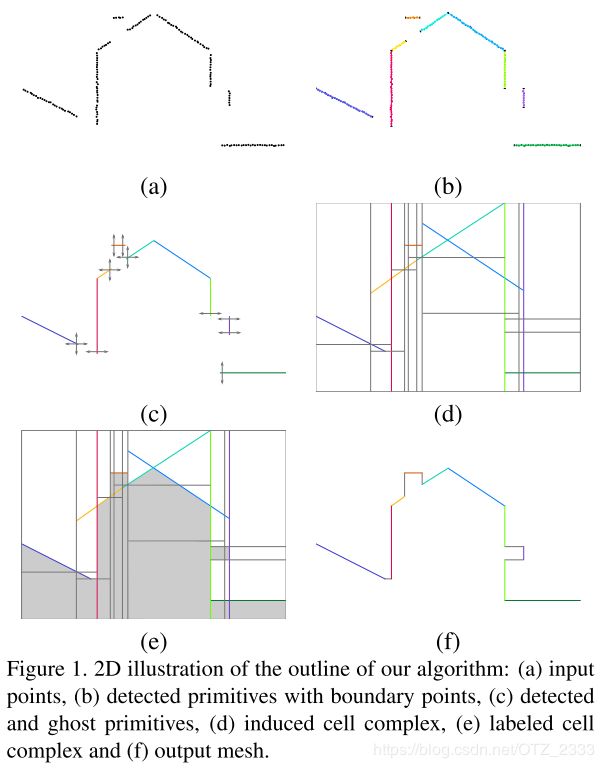
-
未来工作:①结合垂直度,水平度和正交性,以提高3D模型的视觉可接受性;②探索从地面或倾斜航空影像(oblique aerial imagery)对整个城市进行核心外3D重建的流方法(streaming approach)的可行性。
(2008)Fast Plane Detection and Polygonalization in noisy 3D Range Images
相关领域
SLAM
√(2017)Keyframe-based Dense Planar SLAM
- 相关知识:Kintinuous——适合做大场景的三维重建
- 本文方法缩写KDP-SLAM,特点:以平面为landmark
- 优点:只用CPU可以实时大规模重建,重建模型简洁(cheaper)
缺点:不能重建非平面区域,只能应用于高度平面化的环境 - 关于平面提取的大致方法: 输入:传感器采集的RGB-D
- 预处理:提取平面前,为了减小噪声,将深度图中RGB梯度小的地方进行深度平滑处理,从而更好提取小的平面(因为颜色变化不明显区域很大可能为平面)
- 把深度图划分为10×10像素大小的网格,每个网格选几个点计算法向量。若一定量的法向量平行;则利用这些点和法向量合成平面
- 使用文中涉及的快速里程计(fast odometry),可得到每帧的相机姿态估计。融合多帧后,使用文献[11]中的聚类算法进行平面分割,得到的结果更加精确(比如,可以将墙上的白板与墙分割开,即使它们深度距离只差1cm)
- 未来工作:①加入IMU数据;②加入除平面外其他的结构,比如楼梯、柱子等,增加系统鲁棒性;③recover dense 3D for complex structure locally anchored to planes ,以便可以在整体上对其进行优化
(2014)Dense Planar SLAM
(2013)Point-Plane SLAM for Hand Held 3D Sensors
矩形检测
(2008)Detection and matching of rectilinear structures
(2003)Extraction, matching, and pose recovery based on dominant rectangular structures
场景理解
(2014)Unfolding an indoor origami world
单幅图像场景理解,论文解读
恢复场景三维结构
(2016)Efficient 3D room shape recovery from a single panorama
图像算法 |单一全景图中高效的恢复三维结构