本篇接续前一篇继续讲 Netty 中的内存分配。上一篇 先简单做一下回顾:
Netty 为了更高效的管理内存,自己实现了一套内存管理的逻辑,借鉴 jemalloc 的思想实现了一套池化内存管理的思路:
- Arena 作为内存分配器,可以被多个竞争获取内存的线程公用。
- Arena 将从操作系统中申请的内存块命名为 Chunk,每个 Chunk 为16M,后续所有的操作都是在 Chunk 内进行;
- Chunk 内部以 Page 为单位,一个 Page 大小为 8K;
- 有的时候8K对于待申请的资源来说还是很大,所以 Page 内部又做了进一步的划分,有了 SubPage 的概念,SubPage 并没有固定大小,取决于用于的需要。即在 Page 内部只要不超出 Page 大小,你需要多大就划分出多大的 SubPage 空间。
以上 4 个模块: Arena, Chunk,Page, SubPage 构成了 Netty 内存存储的基本概念。
Netty 内存分块的最小单位是 SubPage ,那么数据是以什么样的方式保存在 SubPage 中呢?这里就不得不说到 Netty 对象存储的最小单位:ByteBuf。
1. 为什么Netty 要自己实现数据容器
Netty 底层基于 NIO实现,NIO 的标准三件套:Selector,Channel,Buffer 因为使用比较复杂已经被 Netty 封装好同时提供更多扩展性功能对外用自定义的对象暴露相关操作。Buffer 的功能就是数据容器,Channel 读到数据先存储到 Buffer 中然后进行传输。今天我们要讨论的是 Netty 中的数据容器:ByteBuf,注意不是 java.nio.ByteBuffer。
Netty 为什么要重新写一套数据容器呢?众所周知 Netty 全面封装了 NIO 的核心 API,对外暴露的全都是自己封装的接口,很重要的原因就在于 NIO 的 API 使用起来太复杂,既然要封装,那就封装的彻底一些把该有的功能都补齐。NIO 的 Buffer 有以下缺点:
- 当调用
allocate()方法分配内存时,Buffer 的长度就固定了,不能动态扩展和收缩,当写入数据大于缓冲区的 capacity 时会发生数组越界错误; - Buffer只有一个位置标志位属性 position,读写切换时必须先调用
flip()或rewind()方法; - Buffer只提供了存取、翻转、释放、标志、比较、批量移动等缓冲区的基本操作,想使用高级的功能(比如池化),就得自己手动进行封装及维护,使用非常不方便。
另外很重要的一点就是,JDK 是基于堆的内存管理,Netty 出发点作为一款高性能的 RPC 框架必然涉及到频繁的内存分配销毁操作,如果是在堆上分配内存空间将会触发频繁的GC,JDK 在1.4之后提供的 NIO 也已经提供了直接直接分配堆外内存空间的能力,但是也仅仅是提供了基本的能力,创建、回收相关的功能和效率都很简陋。基于此,在堆外内存使用方面,Netty 自己实现了一套创建、回收堆外内存池的相关功能。
所以基于上面这些或多或少的缺点 Netty 自己封装了新的数据容器 ByteBuf,要解决的事情就是提供 更高性能,更多能力,API 更加简明 地操作数据内存分配的能力。
2. ByteBuf 整体结构
作为存储字节码的容器,大概的功能不外乎是字节数据的写入,读取,扩容,收缩等等相关的功能。ByteBuf 提供了 读指针 和 写指针 分别提示当前读取位置 和 可写入的位置。这些定义我们可以在 AbstractByteBuf 中看到,ByteBuf 作为一个接口,AbstractByteBuf 是它的默认实现类。

上图显示了 ByteBuf 的结构,主要由已读字节、可读字节、可写字节三部分组成,使用readerIndex与writerIndex分隔,三部分加起来称为容量 capacity。readerIndex 表示可读字节的起始位置,writerIndex 表示可写字节的起始位置。
- readerIndex(读指针):读取的起始位置,每读取一个字节就加 1,当它等于 writerIndex 时说明可读数据已读完;
- writerIndex(写指针):写入的起始位置,每写入一个字节就加 1,当它等于
capacity()时说明当前容量已满。此时会做扩容操作,如果不能扩容表示当前写操作结束; - maxCapacity(最大容量):可以扩容的最大容量,当前容量等于这个值时说明不能再扩容。
AbstractByteBuf 中的方法可分为三类:
读取数据、写入数据、操作游标。
2.1 读取数据:readByte()
首先检查当前缓冲区是否有可读的字节,如果要读取的字节数等于0,或者大于已写入的字节长度则抛异常。
@Override
public ByteBuf readBytes(byte[] dst, int dstIndex, int length) {
checkReadableBytes(length);
getBytes(readerIndex, dst, dstIndex, length);
readerIndex += length;
return this;
}
private void checkReadableBytes0(int minimumReadableBytes) {
ensureAccessible();
if (readerIndex > writerIndex - minimumReadableBytes) {
throw new IndexOutOfBoundsException(String.format(
"readerIndex(%d) + length(%d) exceeds writerIndex(%d): %s",
readerIndex, minimumReadableBytes, writerIndex, this));
}
}
getBytes() 是真正的读取字节数据的方法,由对应子类去实现。
2.2 写数据:writeBytes()
写入操作会伴随着一个扩容操作。前面说过,最小写入单位是SubPage,在ensureWritable0()方法中有如下判断:
minWritableBytes <= capacity() - writerIndex ,当前要写入的值 小于 还剩下的可写入容量,不需要扩容;
minWritableBytes > maxCapacity - writerIndex,当前要写入的值 大于 容量上限-写入起始值坐标,已经超了,抛异常;
排除这两种情况,走扩容之路。
public ByteBuf writeBytes(byte[] src, int srcIndex, int length) {
ensureAccessible();
ensureWritable(length);
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format(
"minWritableBytes: %d (expected: >= 0)", minWritableBytes));
}
ensureWritable0(minWritableBytes);
return this;
}
private void ensureWritable0(int minWritableBytes) {
if (minWritableBytes <= writableBytes()) {
return;
}
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
// Normalize the current capacity to the power of 2.
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
// Adjust to the new capacity.
capacity(newCapacity);
}
扩容调用了 AbstractByteBufAllocator 类 的 calculateNewCapacity()方法:
@Override
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
if (minNewCapacity < 0) {
throw new IllegalArgumentException("minNewCapacity: " + minNewCapacity + " (expectd: 0+)");
}
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
final int threshold = 1048576 * 4; // 4 MiB page
if (minNewCapacity == threshold) {
return threshold;
}
// If over threshold, do not double but just increase by threshold.
if (minNewCapacity > threshold) {
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// Not over threshold. Double up to 4 MiB, starting from 64.
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}
扩容设置首次递增的阈值为:threshold = 1048576 * 4,即 1024 * 1024 * 4 = 4M。
如果待申请内存空间等于 4M,即返回。
如果待申请内存空间大于 4M,申请空间 = 待申请内存空间 / 4M * 4M,这个值应该是 4M 的一点几倍的大小。
如果申请空间 > 容量上限 - 4M,那么申请空间 = 容量上限,否则 申请空间 = 当前申请空间 + 4M。
2.3 指针操作
指针操作主要是对读写指针的位移操作,以及指定位置读写。
ByteBuf 的分类
下图给出了 ByteBuf 下的分类,可以看到所有的子类都是继承 AbstactBytebuf:
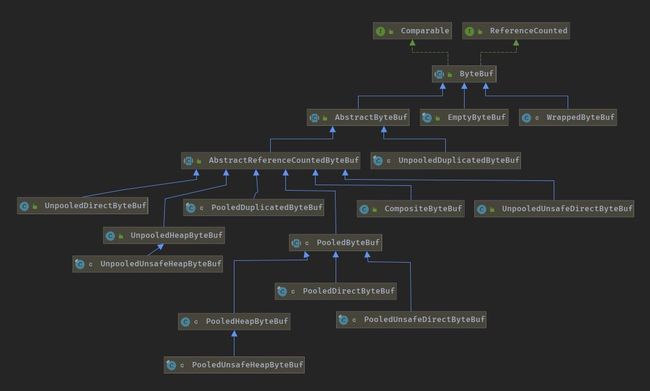
根据操作和存储方式大概可分为3种大类:
Pooled:使用池化内存。从预先分配好的内存池中取出一段连续空间给应用使用;
Direct:使用堆外内存。不在 JVM 中管理这一部分内存的使用,由 Netty 来控制分配和释放;
UnSafe:使用 JDK底层的 UnSafe api 基于对象的内存地址进行操作。
根据以上三个大的方向,对应的子类:
- PooledHeapByteBuf :池化的堆内缓冲区;
- PooledUnsafeHeapByteBuf :池化的 Unsafe 堆内缓冲区;
- PooledDirectByteBuf :池化的直接(堆外)缓冲区;
- PooledUnsafeDirectByteBuf :池化的 Unsafe 直接(堆外)缓冲区;
- UnpooledHeapByteBuf :非池化的堆内缓冲区;
- UnpooledUnsafeHeapByteBuf :非池化的 Unsafe 堆内缓冲区;
- UnpooledDirectByteBuf :非池化的直接(堆外)缓冲区;
- UnpooledUnsafeDirectByteBuf :非池化的 Unsafe 直接(堆外)缓冲区;
除了上面这些,另外Netty 的 Buffer 家族还有 CompositeByteBuf、ReadOnlyByteBufferBuf、ThreadLocalDirectByteBuf 等等。
使用 堆内存 和 堆外内存各自有各自的好处。
堆内存分配回收快,可被JVM自动管理,缺点是多一次复制,需要从内核缓冲区复制到堆缓冲区。
直接内存缓冲区需要自己处理回收相关的操作,但是减少了一次复制。
业务上来看,对于 I/O 操作比较频繁的通信操作,要求响应快这种情况下使用直接内存比较合适;对于业务的数据处理,对性能没有什么要求使用堆内存合适。
引用计数器:AbstractReferenceCountedByteBuf
由上面的类结构能看到所有的子类都是继承 AbstractReferenceCountedByteBuf 类,这个类的主要功能是对引用进行计数,就是 Netty 自己实现的内存回收机制,类似于 JVM 的引用计数。非池化的 ByteBuf 每次 I/O 都会创建一个 ByteBuf,可由 JVM 管理其生命周期;池化的 ByteBuf 要手动进行内存回收和释放。
AbstractReferenceCountedByteBuf 内部有两个变量:
private static final AtomicIntegerFieldUpdater refCntUpdater;
private volatile int refCnt = 1;
static {
AtomicIntegerFieldUpdater updater = PlatformDependent.newAtomicIntegerFieldUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
if (updater == null) {
updater = AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
}
refCntUpdater = updater;
}
注意到在 AbstractReferenceCountedByteBuf 内部并不直接对 refCnt 进行操作,这里必须要保证操作的原子性, Netty 包装了一个 AtomicIntegerFieldUpdater, 原子性 int 类型字段更新器,通过反射的方式拿到字段,底层调用 UnSafe.compareAndSwapInt() 来实现原子更新。
refCnt 使用 volatile 修饰,保证各个线程之间可见。如果单独使用原子操作面对并发情况并不一定能保证 refCnt 的值正确。
池化堆内存分析-PooledByteBuf
从上面的类图中可以看到 PooledHeapByteBuf、PooledUnsafeHeapByteBuf、PooledDirectByteBuf都继承自 PooledByteBuf。
abstract class PooledByteBuf extends AbstractReferenceCountedByteBuf {
// 对象池的对象引用,通过Recycler.Handle实现对象池的功能,线程级的缓存
private final Recycler.Handle> recyclerHandle;
// PoolChunk
protected PoolChunk chunk;
// chunk分配内存后的handle(位置)
protected long handle;
// 实际内存区域(byte[]或者ByteBuffer)
protected T memory;
// 实际内存区域的开始偏移量
protected int offset;
// 长度
protected int length;
// 最大长度
int maxLength;
// 线程缓存
PoolThreadCache cache;
// 临时的Nio缓冲区
ByteBuffer tmpNioBuf;
// ByteBuf分配器
private ByteBufAllocator allocator;
protected PooledByteBuf(Recycler.Handle> recyclerHandle, int maxCapacity) {
super(maxCapacity);
this.recyclerHandle = (Handle>) recyclerHandle;
}
}
池化的主要操作是对象管理, Netty 提供了 Recycler 类作为对象池管理员,先说结论,等会再分析:
- 每个线程都有一个当前线程的对象池,Recycler 类提供了一个类成员变量用来保存各个线程曾经使用过的对象,当然不能无限新增,有一定的回收机制。
- 每个线程结束当前对象池即被回收。
对象池通过 Recycler 里面定义以下对象来实现对象池功能:
| 对象名 | 作用 |
|---|---|
| DefaultHandle | Recycler 中缓存的对象都会包装成 DefaultHandle 类 |
| WeakOrderQueue | 存储其它线程回收到当前线程 stack 的对象,每个线程的 Stack 拥有1个WeakOrderQueue 链表,链表每个节点对应1个其它线程的 WeakOrderQueue,其它线程回收到该 Stack 的对象就存储在这个 WeakOrderQueue 里。当某个线程从 Stack中获取不到对象时会从 WeakOrderQueue 中获取对象。 |
| Stack | 存储当前线程回收的对象。Stack 会与线程绑定,即每个用到 Recycler 的线程都会拥有1个 Stack,在该线程中获取对象都是在该线程的 Stack 中弹出出一个可用对象。对象的获取和回收对应 Stack 的 pop 和 push,即获取对象时从 Stack 中弹出1个DefaultHandle,回收对象时将对象包装成 DefaultHandle push 到 Stack 中。 |
| Link | WeakOrderQueue 中包含1个 Link 链表,回收对象存储在链表某个 Link 节点里,当Link节点存储的回收对象满了时会新建1个 Link 放在 Link 链表尾。 |
子类继承它时需要实现上面贴出代码中的构造方法, 因为不同的子类针对不同的对象进行池化,具体是什么对象由子类自己实现。这个构造方法初始化了 Recycler.Handle,我们上面说对象池属于当前线程,那如果在当前线程中 new 了多个 Recycler.Handle,这还是同一个对象池吗?接着看 Recycler 的代码:
public abstract class Recycler {
/**
* 表示一个不需要回收的包装对象,用于在禁止使用Recycler功能时进行占位的功能
* 仅当io.netty.recycler.maxCapacityPerThread<=0时用到
*/
@SuppressWarnings("rawtypes")
private static final Handle NOOP_HANDLE = new Handle() {
@Override
public void recycle(Object object) {
// NOOP
}
};
//当前线程ID,WeakOrderQueue的id
private static final AtomicInteger ID_GENERATOR = new AtomicInteger(Integer.MIN_VALUE);
private static final int OWN_THREAD_ID = ID_GENERATOR.getAndIncrement();
private static final int DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD = 32768; // Use 32k instances as default.
/**
* 每个Stack默认的最大容量
* 注意:
* 1、当io.netty.recycler.maxCapacityPerThread<=0时,禁用回收功能(在netty中,只有=0可以禁用,<0默认使用4k)
* 2、Recycler中有且只有两个地方存储DefaultHandle对象(Stack和Link),
* 最多可存储MAX_CAPACITY_PER_THREAD + 最大可共享容量 = 4k + 4k/2 = 6k
*
* 实际上,在netty中,Recycler提供了两种设置属性的方式
* 第一种:-Dio.netty.recycler.ratio等jvm启动参数方式
* 第二种:Recycler(int maxCapacityPerThread)构造器传入方式
*/
private static final int DEFAULT_MAX_CAPACITY_PER_THREAD;
//每个Stack默认的初始容量,默认为256,后续根据需要进行扩容,直到<=MAX_CAPACITY_PER_THREAD
private static final int INITIAL_CAPACITY;
//最大可共享的容量因子= maxCapacity / maxSharedCapacityFactor,默认为2
private static final int MAX_SHARED_CAPACITY_FACTOR;
//每个线程可拥有多少个WeakOrderQueue,默认为2*cpu核数,实际上就是当前线程的Map, WeakOrderQueue>的size最大值
private static final int MAX_DELAYED_QUEUES_PER_THREAD;
/**
* WeakOrderQueue中的Link中的数组DefaultHandle[] elements容量,默认为16,
* 当一个Link中的DefaultHandle元素达到16个时,会新创建一个Link进行存储,这些Link组成链表,当然
* 所有的Link加起来的容量要<=最大可共享容量。
*/
private static final int LINK_CAPACITY;
//回收因子,默认为8,即默认每8个对象,允许回收一次,直接扔掉7个,可以让recycler的容量缓慢的增大,避免爆发式的请求
private static final int RATIO;
static {
// In the future, we might have different maxCapacity for different object types.
// e.g. io.netty.recycler.maxCapacity.writeTask
// io.netty.recycler.maxCapacity.outboundBuffer
int maxCapacityPerThread = SystemPropertyUtil.getInt("io.netty.recycler.maxCapacityPerThread",
SystemPropertyUtil.getInt("io.netty.recycler.maxCapacity", DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD));
if (maxCapacityPerThread < 0) {
maxCapacityPerThread = DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD;
}
DEFAULT_MAX_CAPACITY_PER_THREAD = maxCapacityPerThread;
MAX_SHARED_CAPACITY_FACTOR = max(2,
SystemPropertyUtil.getInt("io.netty.recycler.maxSharedCapacityFactor",
2));
MAX_DELAYED_QUEUES_PER_THREAD = max(0,
SystemPropertyUtil.getInt("io.netty.recycler.maxDelayedQueuesPerThread",
NettyRuntime.availableProcessors() * 2));
LINK_CAPACITY = safeFindNextPositivePowerOfTwo(
max(SystemPropertyUtil.getInt("io.netty.recycler.linkCapacity", 16), 16));
RATIO = safeFindNextPositivePowerOfTwo(SystemPropertyUtil.getInt("io.netty.recycler.ratio", 8));
INITIAL_CAPACITY = min(DEFAULT_MAX_CAPACITY_PER_THREAD, 256);
}
private final int maxCapacityPerThread;
private final int maxSharedCapacityFactor;
private final int ratioMask;
private final int maxDelayedQueuesPerThread;
/**
* 每一个线程包含一个Stack对象
* 1、每个Recycler对象都有一个threadLocal
* 原因:因为一个Stack要指明存储的对象泛型T,而不同的Recycler对象的T可能不同,所以此处的FastThreadLocal是对象级别
* 2、每条线程都有一个Stack对象
*/
private final FastThreadLocal> threadLocal = new FastThreadLocal>() {
@Override
protected Stack initialValue() {
return new Stack(Recycler.this, Thread.currentThread(), maxCapacityPerThread, maxSharedCapacityFactor,
ratioMask, maxDelayedQueuesPerThread);
}
};
protected Recycler() {
this(DEFAULT_MAX_CAPACITY_PER_THREAD);
}
}
在 PooledByteBuf 中通过持有 DefaultHandle: ecycler.Handle 调用 recycle()方法将对象转为 DefaultHandle 存入 Recycler:
@Override
public void recycle(Object object) {
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
stack.push(this);
}
将当前 DefaultHandle 存入 Stack,从这里看:
static final class DefaultHandle implements Handle {
private int lastRecycledId;
private int recycleId;
boolean hasBeenRecycled;
private Stack stack;
private Object value;
DefaultHandle(Stack stack) {
this.stack = stack;
}
......
}
DefaultHandle 初始化的时候会带过来一个 Stack 赋值给当前的 stack,那么 Stack 是在什么时候初始化的呢,看这个代码:
private final FastThreadLocal> threadLocal = new FastThreadLocal>() {
@Override
protected Stack initialValue() {
return new Stack(Recycler.this, Thread.currentThread(), maxCapacityPerThread, maxSharedCapacityFactor,
ratioMask, maxDelayedQueuesPerThread);
}
};
一个 final 类型的 FastThreadLocal 对象包着 Stack 完成了初始化。FastThreadLocal 是 Netty 自己实现的 ThreadLocal,主要优化了 ThreadLocal 的 访问速度 和 内存泄漏 等问题,这里可以说明每个 Recycler 对象中的 Stack 是当前线程内共享的。
WeakOrderQueue 的作用又是什么呢?我们看到有这样一行代码:
private static final FastThreadLocal, WeakOrderQueue>> DELAYED_RECYCLED =
new FastThreadLocal, WeakOrderQueue>>() {
@Override
protected Map, WeakOrderQueue> initialValue() {
return new WeakHashMap, WeakOrderQueue>();
}
};
static final 表明当前 DELAYED_RECYCLED 对象是 Recycler 类变量,而不是 成员变量。这里表示每一个 Stack 都对应一个 WeakOrderQueue。这里还是没有看懂到底有什么用,我们看使用到它的地方:
void push(DefaultHandle item) {
Thread currentThread = Thread.currentThread();
if (thread == currentThread) {
// The current Thread is the thread that belongs to the Stack, we can try to push the object now.
pushNow(item);
} else {
// The current Thread is not the one that belongs to the Stack, we need to signal that the push
// happens later.
pushLater(item, currentThread);
}
}
private void pushNow(DefaultHandle item) {
// (item.recycleId | item.lastRecycleId) != 0 等价于 item.recycleId!=0 && item.lastRecycleId!=0
// 当item开始创建时item.recycleId==0 && item.lastRecycleId==0
// 当item被recycle时,item.recycleId==x,item.lastRecycleId==y 进行赋值
// 当item被poll之后, item.recycleId = item.lastRecycleId = 0
// 所以当item.recycleId 和 item.lastRecycleId 任何一个不为0,则表示回收过
if ((item.recycleId | item.lastRecycledId) != 0) {
throw new IllegalStateException("recycled already");
}
item.recycleId = item.lastRecycledId = OWN_THREAD_ID;
int size = this.size;
if (size >= maxCapacity || dropHandle(item)) {
// Hit the maximum capacity or should drop - drop the possibly youngest object.
return;
}
// 如果对象池已满则扩容,扩展为当前 2 倍大小
if (size == elements.length) {
elements = Arrays.copyOf(elements, min(size << 1, maxCapacity));
}
elements[size] = item;
this.size = size + 1;
}
private void pushLater(DefaultHandle item, Thread thread) {
// we don't want to have a ref to the queue as the value in our weak map
// so we null it out; to ensure there are no races with restoring it later
// we impose a memory ordering here (no-op on x86)
Map, WeakOrderQueue> delayedRecycled = DELAYED_RECYCLED.get();
WeakOrderQueue queue = delayedRecycled.get(this);
// 如果没有获取到 WeakOrderQueue,说明当前线程第一次帮该 Stack 回收对象
if (queue == null) {
// 每个线程最多能帮 maxDelayedQueues(2CPU)个外部 Stack 回收对象,超过数量回收失败
if (delayedRecycled.size() >= maxDelayedQueues) {
// 插入一个特殊的 WeakOrderQueue,下次回收时看到 WeakOrderQueue.DUMMY 就说明该线程无法帮该 Stack 回收
delayedRecycled.put(this, WeakOrderQueue.DUMMY);
return;
}
// 别的线程最多帮这个 Stack 回收 2K 个对象,检查是否超过数量,如果没有超过,就向这个 Stack 头插法新建 WeakOrderQueue 对象
if ((queue = WeakOrderQueue.allocate(this, thread)) == null) {
// drop object
return;
}
delayedRecycled.put(this, queue);
// 看到 WeakOrderQueue.DUMMY 就说明该线程无法帮该 Stack 回收,直接返回
} else if (queue == WeakOrderQueue.DUMMY) {
// drop object
return;
}
// 向 WeakOrderQueue 对应的 Link 存放对象
queue.add(item);
}
在存放 DefaultHandle 到 Stack 的时候会判断是否是当前线程,如果是就调用 pushNow()方法,如果不是则调用 pushLater() 方法。
pushNow() 方法中首先判断一个 对象是否是被回收过,如果是则抛异常。如果没有则存入 elements 数组中。
pushLater() 方法则先把 DefaultHandle 放入 DELAYED_RECYCLED 持有的 WeakOrderQueue 中,后面再压如 Stack。
这里大概的意思就是如果是当前线程创建的对象就存入 Stack,如果不是当前线程创建的就放入WeakOrderQueue。我们看 WeakOrderQueue 类里面有有一个子类 Link:
private static final class WeakOrderQueue {
static final WeakOrderQueue DUMMY = new WeakOrderQueue();
// Let Link extend AtomicInteger for intrinsics. The Link itself will be used as writerIndex.
@SuppressWarnings("serial")
private static final class Link extends AtomicInteger {
private final DefaultHandle[] elements = new DefaultHandle[LINK_CAPACITY];
private int readIndex;
private Link next;
}
// chain of data items
private Link head, tail;
// pointer to another queue of delayed items for the same stack
private WeakOrderQueue next;
private final WeakReference owner;
private final int id = ID_GENERATOR.getAndIncrement();
private final AtomicInteger availableSharedCapacity;
private WeakOrderQueue() {
owner = null;
availableSharedCapacity = null;
}
......
}
Link 的结构是一个链表,存放了 DefaultHandle[] 对象,放入的时机就是上面的 pushLater() 方法。
这里我们已经全部接触到了上面提到的 4 个对象,我用一张图来表述他们之间的关系:
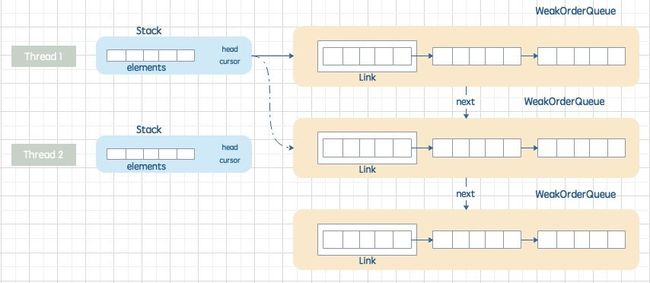
我们再来总结一下 4 者的关系:
- 每一个 Recycler 对象 都包含一个 Stack;
- 每一个 Stack 中都包含一个
DefaultHandle[]数组,用于保存 DefaultHandle; - Recyler 类包含一个类对象
FastThreadLocal,无论有多少个 Recyler 对象,都只会有一个DELAYED_RECYCLED。它的作用是保存除当前线程外别的线程创建的 DefaultHandle。 - WeakOrderQueue 对象中存储一个以 Head 为首的 Link 数组,每个 Link 对象中存储一个
DefaultHandle[]数组,用于存放回收对象。
同线程中是如何获取对象的呢?
public final T get() {
/**
* 如果maxCapacityPerThread == 0,禁止回收功能
* 创建一个对象,其Recycler.Handle<> handle属性为NOOP_HANDLE,该对象的recycle(Object object)不做任何事情,即不做回收
*/
if (MAX_CAPACITY_PER_THREAD == 0) {
return newObject((Handle) NOOP_HANDLE);
}
//获取当前线程的Stack对象
Stack stack = threadLocal.get();
//从Stack对象中获取DefaultHandle
DefaultHandle handle = stack.pop();
if (handle == null) {
//新建一个DefaultHandle对象 -> 然后新建T对象 -> 存储到DefaultHandle对象
//此处会发现一个DefaultHandle对象对应一个Object对象,二者相互包含。
handle = stack.newHandle();
handle.value = newObject(handle);
}
return handle.value;
}
调用 Stack 的 pop()方法获取 DefaultHandle 对象:
DefaultHandle pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
size --;
DefaultHandle ret = elements[size];
elements[size] = null;
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}
当 Stack 中 DefaultHandle[] 的 size=0 时,需要从其他线程的 WeakOrderQueue 中转移数据到 Stack 中的DefaultHandle[],即调用 scavenge() 方法。当 Stack 中的 DefaultHandle[] 中最终有了数据时直接获取最后一个元素,并进行一些健康检查。
假设最终确实无法从对象池中获取到对象,则会首先创建一个 DefaultHandle 对象,之后调用 Recycler 的子类重写的 newObject() 方法。
DirectBuffer-直接内存分配
Netty 中的堆外内存分配主要是调用 NIO 的 DirectByteBuffer 来操作。DirectByteBuffer 与 ByteBuffer 的区别在于底层没有使用 byte[] hb 来承接数据,而是放在了堆外管理,DirectByteBuffer的创建就是使用了 malloc 申请的内存。
如果我们使用普通的 Buffer 来分配内存是这样的:
ByteBuffer buf = ByteBuffer.allocate(1024);
这种方式分配的内存底层是一个 byte[] 数组保存在 JVM 堆上。
当我们想脱离 JVM 的管理,直接在系统内存上去分配一块连续空间的时候,Java 也提供了这种方式。DirectByteBuffer 并不是一个 public 类型的 class,所以我们无法直接使用,一般通过如下方式调用:
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
的构造方法如下:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//是否页对齐
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小4K
int ps = Bits.pageSize();
//最小申请1K,若需要页对齐,那么多申请1页,以应对初始地址的页对齐问题
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//检查堆外内存是否够用, 并对分配的直接内存做一个记录
Bits.reserveMemory(size, cap);
long base = 0;
try {
//直接内存的初始地址, 返回初始地址
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
//对直接内存初始化
unsafe.setMemory(base, size, (byte) 0);
//若需要页对其,并且不是页的整数倍,在需要将页对齐(默认是不需要进行页对齐的
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
//声明一个Cleaner对象用于清理该DirectBuffer内存
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
首先 Bits.reserveMemory(size, cap) 方法用来判断系统是否有足够的空间可以申请,如果已经没有空间可以申请,则抛出 OOM:
static void reserveMemory(long size, int cap) {
// 获取最大可以申请的对外内存大小,默认值是64MB
// 可以通过参数-XX:MaxDirectMemorySize=设置这个大小
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
//如果计算当前用户申请的空间 小于用户设置的最大堆外空间大小,且小于当前可用的
//系统内存则表示申请通过
// optimist!
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
//尝试释放那些正在正在清理中的堆外内存任务以释放一些空间
while (jlra.tryHandlePendingReference()) {
if (tryReserveMemory(size, cap)) {
return;
}
}
// 如果经历上面两步空间还是不足,那就只好手动调用 System.gc()释放内存
System.gc();
// a retry loop with exponential back-off delays
// (this gives VM some time to do it's job)
boolean interrupted = false;
try {
long sleepTime = 1;
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
if (!jlra.tryHandlePendingReference()) {
try {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
} catch (InterruptedException e) {
interrupted = true;
}
}
}
// no luck
throw new OutOfMemoryError("Direct buffer memory");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
private static boolean tryReserveMemory(long size, int cap) {
// -XX:MaxDirectMemorySize限制的是用户申请的大小,而不考虑对齐情况
// 所以使用两个变量来统计:
// reservedMemory:真实的目前保留的空间
// totalCapacity:目前用户申请的空间
long totalCap;
while (cap <= maxMemory - (totalCap = totalCapacity.get())) {
if (totalCapacity.compareAndSet(totalCap, totalCap + cap)) {
reservedMemory.addAndGet(size);
count.incrementAndGet();
return true;
}
}
return false;
}
可以通过 -XX:+PageAlignDirectMemor 参数控制堆外内存分配是否需要按页对齐,默认不对齐。
Bits#reserveMemory() 方法判断是否有足够内存不是判断物理机是否有足够内存,而是判断 JVM 启动时,指定的堆外内存空间大小是否有剩余的空间。这个大小由参数 -XX:MaxDirectMemorySize= 设置。
接着调用 base = unsafe.allocateMemory(size) 操作堆外内存, 返回的是该堆外内存的直接地址, 存放在 address 中, 以便通过 address 进行堆外数据的读取与写入。而 allocateMemory() 是一个 native 方法,会调用 malloc 方法。UnSafe 类底层是基于 C 语言的,所以在 Java 源码中看不到,我们可以下载 OpenJDK 的源码看看,源码链接:https://github.com/openjdk/jdk/blob/5a6954abbabcd644ad2639ea11e843da5b17a11d/src/hotspot/share/prims/unsafe.cpp#L359
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory0(JNIEnv *env, jobject unsafe, jlong size)) {
size_t sz = (size_t)size;
assert(is_aligned(sz, HeapWordSize), "sz not aligned");
void* x = os::malloc(sz, mtOther);
return addr_to_java(x);
} UNSAFE_END
可以看到底层是使用系统的malloc()函数来申请内存。
在 C 语言的内存分配和释放函数 malloc/free,必须要一一对应,否则就会出现内存泄露或者是野指针的非法访问。Java 中 ByteBuffer 申请的堆外内存需要手动释放吗?ByteBuffer 申请的堆外内存也是由 GC 负责回收的,Hotspot 在 GC 时会扫描 Direct ByteBuffer 对象是否有引用,如没有,当堆内的引用被 gc 回收时通过虚拟引用回收其占用的堆外内存。(前提是没有关闭 DisableExplicitGC)
-XX:+DisableExplicitGC
这个参数作用是禁止显式调用 GC,即通过 System.gc() 函数调用。如果加上了这个 JVM启动参数,那么代码中调用 System.gc() 没有任何效果,相当于是没有这行代码一样。
上面贴出来而代码示例:DirectByteBuffer 的构造函数里面:
Bits.reserveMemory(size, cap);
该方法去申请堆外内存是会显式调用 System.gc()的。
也就是说使用了Java NIO 中的 Direct memory,那么 -XX:+DisableExplicitGC一定要谨慎设置,存在潜在的内存泄露风险。
再说另一个问题:-XX:MaxDirectMemorySize=参数用来限制能申请的最大堆外内存大小,那如果我忘记设置这个值默认能够申请的堆内存大小是多少呢?我们还是要看 OpenJDK源码,这个参数的设置位于:https://github.com/openjdk/jdk/blob/847a3baca8a19b4f506dcaf23079e1b339e5321b/src/java.base/share/classes/jdk/internal/misc/VM.java

可以看到代码中默认是 64M。但是你好好看一下注释:
The initial value of this field is arbitrary; during JRE initialization
it will be reset to the value specified on the command line, if any,
otherwise to Runtime.getRuntime().maxMemory().
这个值只是在初始化的时候的默认赋值。如果用户有通过参数设置自己的值就会用设置的参数值取代,否则:就会使用 JVM 参数 -Xmx 最大堆的值取代。所以,64M 是没有发挥到作用的。
堆外内存的回收
既然在 heap 外分配了内存空间给 Java 线程使用,JVM 也不管回收这事。那是怎么触发回收的呢?这里要说明,JVM 并不是真的不管,堆外分配内存保存对象这事儿板上钉钉,那 JVM 是怎么着知道堆外哪哪块是我这个对象的专属空间,这个就要求在 JVM 中要保存一个引用的关系。
在 DirectBuffer 构造函数最后面有这么一句:
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
使用 Cleaner 机制注册内存回收处理函数。Java 本身提供了finalize()机制来进行垃圾回收,无赖它靠不住不到内存撑不住的最后时刻它是不会被触发的,所以 Java 官方都不推荐你这样用。Java 官方推荐使用虚引用-PhantomReference 来处理对象的回收,Cleaner 就是 PhantomReference 的子类,用来处理对象回收流程。
这里create()方法传入了一个参数 Deallocator 对象,Deallocator 继承了Runnable,作为可执行的线程,看一下run() 方法:
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
这里调用了 UnSafe 的 freeMemory()拿到堆外内存地址偏移量来释放内存。
ByteBuf 的管理
在 Netty 中并不是通过 new 的方式来创建一个 Bytebuf 对象。常用的有三种方式:
- ByteBufAllocator 创建;
- ByteBufUtil:提供一些实用的静态方法用于 内存分配 和 对象转换;
- Unpooled 非池化内存分配。
ByteBufAllocator 是 Netty 中最顶层的内存分配接口,负责所有 Bytebuf 类型的分配,AbstractByteBufAllocator 是默认实现类。
我们看一下它是如何分配内存空间的:
@Override
public ByteBuf buffer(int initialCapacity) {
if (directByDefault) {
return directBuffer(initialCapacity);
}
return heapBuffer(initialCapacity);
}
首先会检查是否支持分配直接内存,如果支持就优先分配堆外内存空间。
@Override
public ByteBuf directBuffer(int initialCapacity, int maxCapacity) {
if (initialCapacity == 0 && maxCapacity == 0) {
return emptyBuf;
}
validate(initialCapacity, maxCapacity);
return newDirectBuffer(initialCapacity, maxCapacity);
}
protected abstract ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity);
newDirectBuffer() 是一个抽象方法,最终会交给它的子类去实现进行空间分配:

可以看到实现类其实就两种:池化 和 非池化的 buffer 分配。上面的 Buffer 分配我们看到还有 Unsafe 类型的Buffer,那么这里为什么没有体现呢?既然找不到答案,就继续往下看看,我们看一下PooledByteBufAllocator 类的实现:
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
首先还是判断是否支持直接内存分配,如果不支持,会判断当前平台是否支持使用 Unsafe 工具包,如果支持那自然优先使用 Unsafe 工具去直接分配内存。
这里有一个 Unsafe 工具类:
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity)
Unpooled 使用
一般来说 ByteBufAllocator 已经提供了池化和非池化内存分配的实现,但是 Netty 还是提供了一个简单版的 非池化内存分配工具:Unpooled,以防在极端的情况下你无法使用 ByteBufAllocator 进行内存分配。
从源码上能看到底层还是引用了 UnpooledByteBufAllocator 类来实现非池化的内存分配。
ByteBufUtil
ByteBufUtil 就更厉害了,默认使用的内存分配方式取决于你的设置:

未设置默认会选择池化的方式。
ByteBufUtil 主要提供一些静态方法,其中 hexdump() 以十六进制的表示形式打印ByteBuf 的内容。这在各种情况下都很有用,比如调试的时候记录ByteBuf 的内容,总比你看一堆二进制的天书好吧。
还有 encodeString() 对字符串进行编码转换为 ByteBuffer。