此小项目参考《微信好友数据分析 》——余本国
一、功能介绍:
三、运行环境及相关库的安装
- Python 3.x(使用Anaconda的spyder编辑器)
- 使用到的Python库安装:
- 在Anaconda的Anaconda Prompt下运行下列命令,安装前先升级pip,代码如下:
Python -m pip install --upgrade pip
- 安装 wxpy: pip install wxpy
-
安装 PIL: pip install pillow
-
安装 pyecharts:pip install pyecharts
-
安装 Itchat: pip install itchat
-
安装 Jieba: pip install jieba
-
安装 Pandas:pip install Pandas
- 安装 Numpy:pip install Numpy
- 安装 wordcloud:pip install wordcloud
- 安装地图数据包:pip install echarts-china-provinces-pypkg
- pip install echarts-countries-pypkg
四、如何运行?(初次运行可以使用spyder的IPython console进行交互式输入)
以上库安装好了以后就可进行以下步骤coding
1.登录——获取用户信息:
打开spyder的IPython console 进行交互式编写

In [3]: from wxpy import * #导入模块 In [4]: bot=Bot(cache_path=True)#初始化机器人,选择缓存模式(扫码)登录 Getting uuid of QR code. Downloading QR code. Please scan the QR code to log in. Please press confirm on your phone. Loading the contact, this may take a little while. Login successfully as 舒心陈 In [5]: friend_all=bot.friends() In [6]: print(friend_all[0].raw)#friend_all[0]是你的微信昵称,.raw则是获取你的全部信息 {'UserName': '@616bbbd522bbfce0dcad9082de7100b2548b9d8c54f466933fe26ce46f4eb80c', 'City': '', 'DisplayName': '', 'PYQuanPin': '', 'RemarkPYInitial': '', 'Province': '', 'KeyWord': '', 'RemarkName': '', 'PYInitial': '', 'EncryChatRoomId': '', 'Alias': '', 'Signature': '好开心啊~', 'NickName': '舒心陈', 'RemarkPYQuanPin': '', 'HeadImgUrl': '/cgi-bin/mmwebwx-bin/webwxgeticon?seq=879163398&username=@616bbbd522bbfce0dcad9082de7100b2548b9d8c54f466933fe26ce46f4eb80c&skey=@crypt_6e5fb2f2_41b8311b5e5bb5ea58c12688ff48ccf9', 'UniFriend': 0, 'Sex': 1, 'AppAccountFlag': 0, 'VerifyFlag': 0, 'ChatRoomId': 0, 'HideInputBarFlag': 0, 'AttrStatus': 0, 'SnsFlag': 1, 'MemberCount': 0, 'OwnerUin': 0, 'ContactFlag': 0, 'Uin': 3129189532, 'StarFriend': 0, 'Statues': 0, 'MemberList': [], 'WebWxPluginSwitch': 0, 'HeadImgFlag': 1}
2、统计用户信息
In [7]: len(friend_all) #统计查阅了多少好友 Out[7]: 173
lis=[] for a_friend in friend_all: NickName = a_friend.raw.get('NickName',None) #Sex = a_friend.raw.get('Sex',None) Sex ={1:"男",2:"女",0:"其它"}.get(a_friend.raw.get('Sex',None),None) City = a_friend.raw.get('City',None) Province = a_friend.raw.get('Province',None) Signature = a_friend.raw.get('Signature',None) HeadImgUrl = a_friend.raw.get('HeadImgUrl',None) HeadImgFlag = a_friend.raw.get('HeadImgFlag',None) list_0=[NickName,Sex,City,Province,Signature,HeadImgUrl,HeadImgFlag] lis.append(list_0)
注意:这里令lis=[ ]在一下存储数据如Excel时会使得表格缺少列标题行,在此我建议将lis=[ ]改为如下:
lis=[['NickName','Sex','City','Province','Signature','HeadImgUrl',\ 'HeadImgFlag']]
def lis2e19(filename,lis): ''' 将列表写入 07 版 excel 中,其中列表中的元素是列表. filename:保存的文件名(含路径) lis:元素为列表的列表,如下: lis = [["名称", "价格", "出版社", "语言"], ["暗时间", "32.4", "人民邮电出版社", "中文"], ["拆掉思维里的墙", "26.7", "机械工业出版社", "中文"]] ''' import openpyxl wb = openpyxl.Workbook() sheet = wb.active sheet.title = 'list2excel19' file_name = filename for i in range(0, len(lis)): for j in range(0, len(lis[i])): sheet.cell(row=i+1, column=j+1, value=str(lis[i][j])) wb.save(file_name) print("写入数据成功!") lis2e19(r'C:\Users\Benny\Desktop\Python\Python练习\wechat_02.xlsx',lis)
lis2e19(r'C:\Users\Benny\Desktop\Python\Python练习\wechat_02.xlsx',lis)
打开文件(部分截图):
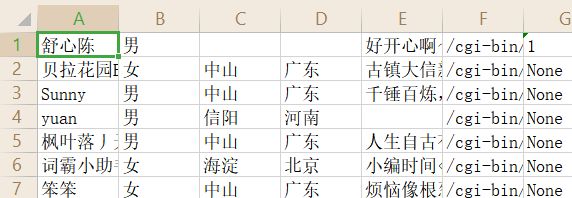
4. 对数据进行初略的认知分析。
#对数据进行初步探索 #方法一 #粗略获取好友的统计信息 data = friend_all.stats_text(total=True, sex=True,top_provinces=10, top_cities=100) from pandas import read_excel df=read_excel(r'C:\Users\Benny\Desktop\Python\Python练习\wechat_02.xlsx',sheetname='list2excel19')
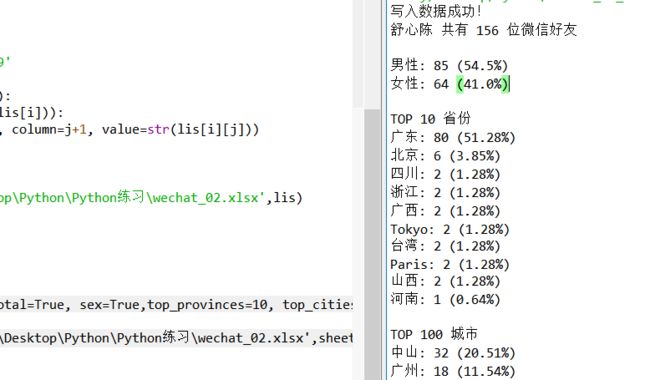
print(data)
部分数据截图如下:
5. 现在手动为上述表格插入一个列标题行:如:

6. 然后我们可以方便的进行如下编写:(注意,此部分由于需要手动插入列标题行,所以一下程序应与上述程序分开执行,或者上述代码中使得 lis=['nickname','sex','city','province','headImgUrl','headImgFlag']
]is
In[10]from pandas import read_excel df = read_excel('yubg1.xlsx',sheetname='list2excel19') df.tail(5) #输出表格最后5行 Out[11]: 舒心陈 ... 1 169 鹿森丶 ... None 170 琳达大大 ... None 171 Coy lin ... None 172 A ... None 173 孟小傲 ... None
print(df.city.count()) print(df.city.describe())
结果:
nickname ... Unnamed: 6 170 鹿森丶 ... None 171 琳达大大 ... None 172 Coy lin ... None 173 A ... None 174 孟小傲 ... None [5 rows x 7 columns] 114 count 114 unique 39 top 中山 freq 32 Name: city, dtype: object
6. 对 city 列数据做成词云
from wordcloud import WordCloud import matplotlib.pyplot as plt import pandas as pd from pandas import DataFrame word_list= df['city'].fillna('0').tolist()#将 dataframe 的列转化为 list,其中的 nan 用“0”替换 new_text = ' '.join(word_list) wordcloud = WordCloud(font_path='simhei.ttf', background_color="black").generate(new_text) plt.imshow(wordcloud) plt.axis("off") plt.show()
图片:

pip install wheel
pip install pyecharts==0.1.9.4
运行完成上述代码后:
#利用 pyecharm 做词云 import pandas as pd #count = df.city.value_counts() #对 dataframe 进行全频率统计,排除了 nan city_list = df['city'].fillna('NAN').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_city = pd.value_counts(city_list)#对 list 进行全频率统计 from pyecharts import WordCloud name = count_city.index.tolist() value = count_city.tolist() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.show_config() wordcloud.render(r'C:\Users\Benny\Desktop\Python\map1.html')
图片如下:(已经过水印处理)
#将这些个好友在全国地图上做分布 province_list = df['province'].fillna('NAN').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 from pyecharts import Map value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype='china', is_visualmap=True, visual_text_color='#000', is_label_show = True) #显示地图上的省份 map.show_config() map.render(r'C:\Users\Benny\Desktop\Python\map3.html')
图片如下:(已经过水印处理)

五、全部代码:
一、环境与库准备:
Anaconda Prompt下运行:
Python -m pip install --upgrade pip pip install wxpy pip install pillow pip install pyecharts pip install itchat pip install jieba pip install Pandas install Numpy pip install wordcloud pip install echarts-china-provinces-pypkg pip install echarts-countries-pypkg pip install wheel pip install pyecharts==0.1.9.4
完整代码:
# -*- coding: utf-8 -*- """ Created on Tue Jun 4 22:21:18 2019 @author: Benny """ from wxpy import * import openpyxl import pandas as pd from wordcloud import WordCloud import matplotlib.pyplot as plt from pyecharts import Map #from pyecharts import WordCloud def alldata_connect_in(): ''' 连接网页版微信并返回所有朋友信息 bot:初始化机器人并选择缓存模式(扫码)登录 friend_all:获取我所有微信好友信息 ''' bot=Bot(cache_path=True) friend_all=bot.friends() return friend_all def analyse_friends(friend_all,top_provinces=10,top_cities=100): Friends = friend_all data = Friends.stats_text(total=True, sex=True,top_provinces=30, top_cities=500) print(data) def insert_column_title(lis=[]): '''输入并列标题行 ls=[] 默认为无 ''' column_titles=[] column_titles.append(lis) return colomn_titles def data_dict_to_list(friend_all): ''' data_ls:初值:设列表初值为包含列标题行列表的列表\ 遍历所有好友信息字典提取数据加入到数据列表,并返回此数据列表 list_0:一个微信好友的数据列表,包括'NickName','Sex','City','Province',\ 'Signature','HeadImgUrl','HeadImgFlag'. ''' data_lis=[['NickName','Sex','City','Province','Signature','HeadImgUrl',\ 'HeadImgFlag']] for a_friend in friend_all: NickName = a_friend.raw.get('NickName',None) #Sex = a_friend.raw.get('Sex',None) Sex ={1:"男",2:"女",0:"其它"}.get(a_friend.raw.get('Sex',None),None) City = a_friend.raw.get('City',None) Province = a_friend.raw.get('Province',None) Signature = a_friend.raw.get('Signature',None) HeadImgUrl = a_friend.raw.get('HeadImgUrl',None) HeadImgFlag = a_friend.raw.get('HeadImgFlag',None) list_0=[NickName,Sex,City,Province,Signature,HeadImgUrl,HeadImgFlag] data_lis.append(list_0) return data_lis def data_lis_savein_excel(data_lis=[],filename='wechat_data',\ sheet_title='wechat1'): ''' 将列表写入 07 版 excel 中,其中列表中的元素是列表. filename:保存的文件名(含路径) lis:元素为列表的列表,如下: lis = [["名称", "价格", "出版社", "语言"], ["暗时间", "32.4", "人民邮电出版社", "中文"], ["拆掉思维里的墙", "26.7", "机械工业出版社", "中文"]] ''' wb = openpyxl.Workbook() sheet = wb.active sheet.title =sheet_title file_name = filename +'.xlsx' for i in range(0, len(data_lis)): for j in range(0, len(data_lis[i])): sheet.cell(row=i+1, column=j+1, value=str(data_lis[i][j])) wb.save(file_name) return file_name print("写入数据成功!") def count_sing(file_name,sheet_name='wechat1',column_name='NickName'): '''输出单个列的统计数据''' f=open(file_name,'rb') data=pd.read_excel(f,sheetname=sheet_name) print(column_name+'\t'+str(data[column_name].count())) print(data[column_name].describe()) f.close() def wordcloud_show(file_name,sheet_name='wechat1',column_name='City'): '''用 plt+wordcloud 方法得到词云图''' f=open(file_name,'rb') data=pd.read_excel(f,sheetname=sheet_name) word_list= data[column_name].fillna('0').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“0”替换 new_text = ' '.join(word_list) wordcloud = WordCloud(font_path='simhei.ttf', \ background_color="black").generate(new_text) plt.imshow(wordcloud) plt.axis("off") plt.show() f.close() def save_wordcloud_to_html(save_road,file_name,sheet_name='wechat1',\ column_name='City'): '''利用 pyecharm 做词云并存为html文件''' f=open(file_name,'rb') data=pd.read_excel(f,sheetname=sheet_name) #count = df.city.value_counts() #对 dataframe 进行全频率统计,排除了 nan city_list = data[column_name].fillna('NAN').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_city = pd.value_counts(city_list)#对 list 进行全频率统计 name = count_city.index.tolist() value = count_city.tolist() from pyecharts import WordCloud wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.show_config() wordcloud.render(save_road+'.html') f.close() def show_data_in_countrymap(save_road,file_name,sheet_name='wechat1',\ column_name='Province'): '''将这些个好友在全国地图上做分布''' f=open(file_name,'rb') data=pd.read_excel(f,sheetname=sheet_name) province_list = data[column_name].fillna('NAN').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype='china', is_visualmap=True, visual_text_color='#000', is_label_show=True) #显示地图上的省份 map.show_config() map.render(save_road+'map2'+'.html') f.close() def main(): friends_data=alldata_connect_in() data_ls=data_dict_to_list(friends_data) file_name=data_lis_savein_excel(data_ls) analyse_friends(friends_data) count_sing(file_name) wordcloud_show(file_name) save_road=r'C:\Users\Benny\Desktop\Python\wechat_01_statlist\picture' save_wordcloud_to_html(save_road,file_name) show_data_in_countrymap(save_road,file_name) main()
对于学习过程中的的出现地错误与解决办法和疑问:
问题1:
不能从pyecharts库中导入模块,如WordCloud Bar等
解决办法:
在运行环境的命令行运行(Anaconda Prompt):
pip install wheel
pip install pyecharts==0.1.9.4
注意!:运行上述命令后要将spyder的console重启!!否则依旧会出现同样的问题!!

问题2:
在完全代码中我将lis列表赋初值为列标题行,这使得在对Excel表格进行词云分析时可用列标题行进行索引,如果不加,会由于Excel表格首行某列中为空而无法索引!!
问题3:
完全代码中我在某个函数中进行模块的引入,但当我将此模块放到完全代码前引用时,出现了如下错误:(而在函数内引用却没有报错)
super(WordCloud, self).__init__(title, subtitle, **kwargs) TypeError: __init__() got an unexpected keyword argument 'font_path'
解决办法:还么有。