四篇NeurIPS 2019论文,快手特效中的模型压缩了解一下

在即将过去的 2019 年中,快手西雅图实验室在 ICLR、CVPR、AISTATS、ICML 和 NeurIPS 等顶会上发表了十多篇论文。
除了这些研究方面的成果,针对实际业务,西雅图实验室和快手商业化还推出了基于 GPU 的广告推荐训练系统 Persia,采用这样的训练系统单机能提升 640 倍的效率,已经在业务场景中广泛使用;此外提出的新算法对商业化广告收益也有大量提升,新技术在视频风格迁移和游戏业务中也有多项落地成果。这是快手西雅图实验室在 2019 交出的一份成绩单。
那么在 NeurIPS 2019,在模型压缩领域,快手短视频最新应用的技术是什么样的?我们在应用各种视觉特效时,为什么以庞大著称的深度神经网络能满足我们的要求?在本文中,机器之心将介绍快手在 NeurIPS 2019 的四篇研究成果,并重点探讨他们在模型压缩方面的努力。
下面是本文的目录,我们将以如下结构介绍这四项研究成果:
快手在 NeurIPS 2019
在快手做研究
研究框架用什么?
论文代码要开源?
模型压缩在快手
模型压缩这条逻辑线
优化器:「有些参数生而冗余」
从数学看优化器
对抗训练:「我也能变压缩」
从数学看对抗与压缩
快手在 NeurIPS 2019
在最近的 NeurIPS 2019 中,快手及合作者展示了四项新研究。这四项研究中有三项已经或者正在应用到实际业务中,例如第一篇跟 University of Rochester 和 TAMU 合作的模型压缩的工作,它已经应用到一些 CV 任务中,包括快手比较炫酷的风格迁移。
第二篇模型压缩更像新方法方面的探索,它也能用于部分应用而加速视频的处理过程。第三篇强化学习正应用于游戏 AI,它可以令智能体学会「团队协作」。
论文:Adversarially Trained Model Compression: When Robustness Meets Efficiency
地址:https://papers.nips.cc/paper/8410-model-compression-with-adversarial-robustness-a-unified-optimization-framework
论文:Global Sparse Momentum SGD for Pruning Very Deep Neural Networks
地址:https://papers.nips.cc/paper/8867-global-sparse-momentum-sgd-for-pruning-very-deep-neural-networks
论文:LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning
地址:https://papers.nips.cc/paper/8691-liir-learning-individual-intrinsic-reward-in-multi-agent-reinforcement-learning
论文:Efficient Smooth Non-Convex Stochastic Compositional Optimization via Stochastic Recursive Gradient Descent
地址:https://papers.nips.cc/paper/8916-efficient-smooth-non-convex-stochastic-compositional-optimization-via-stochastic-recursive-gradient-descent
当然,这些研究成果是快手与合作者联合完成的,例如第二篇模型压缩就是清华大学-快手未来媒体数据联合研究院以及快手西雅图实验室共同完成的。
快手西雅图实验室负责人刘霁表示:「这四项研究都有其独特的亮点。在第一篇对抗训练的模型压缩中,它会把各种压缩方法都集中到一起,并做一种联合优化,这和之前按照 Pipeline 的形式单独做压缩有很大的不同。与此同时,模型还能抵御对抗性攻击,这是两个比较有意思的思路。」
「一般剪枝方法都需要大量调参以更好地保留模型性能,而全局稀疏动量 SGD 会端到端地学习到底哪些权重比较重要,重要的就少压缩一点,不重要的就多压缩一点。」,论文合著者,清华大学软件学院副院长丁贵广说,「第二篇论文的核心思想在于,我们给定一个压缩率,模型在训练中就能自己剪裁,并满足这个压缩率。」
「对于第三篇多智能体强化学习是跟腾讯 AI Lab 和 Robotics X 合作,它希望智能体能快速学会利用自己所观测的信息来相互配合。比如说在星际争霸中,我们发现确实会产生多智能体合作的现象,模型会让一些防高血厚的单位去抗对方的输出,己方输出高的单元会躲到后方攻击。」,刘霁说。
「虽然把所有的 agents 看成是一个 agent,理论上也可以学到最终的配合效果,但是效率会非常低,不具有可扩展性。我们的方法通过一种 intrinsic reward 的机制兼顾了可扩展性和效率,通过鼓励每个 agent 按照单体利益最大化的原则去学习自己的 policy,然后这种 intrinsic reward 的影响会越来越小最后快速达到学到整体最后的方案」,刘霁说。

受伤的智能体 2 躲入血厚的智能体背后,并继续输出伤害。
「最后第四篇是与腾讯 AI Lab 合作的更偏理论的一项研究,它是针对复合函数的最优化方法。这里复合指的是一个数学期望函数中复合了另一个数学期望,而常规的 ML 目标函数就只有最外面一个数学期望。」,刘霁说,「这种最优化方法在风险管理或 RL 中非常有用,例如在 RL 中解贝尔曼方程,它本质上就是复合函数最优化问题。」
在快手做研究
在快手做研究,数据与算力并不是难事,实习生在授权条件下也能拿到很多一手脱敏数据。在快手做研究,从 Idea 到模型上线这条链路非常短,研究者能很快看到实验室结果对产品的影响。
因为链路短,研究者很容易接触一手的线上反馈,这一点特别重要。刘霁说:「我认为最好的研究工作一定是从现实场景与反馈中生成出来的,因此我们做的解决方案、理论分析或算法升级才能真正服务于某个具体的问题。」
清华大学软件学院副院长丁贵广也表明,「清华大学软件学院与快手联合建立了未来媒体数据联合研究院,其研究方向主要围绕着快手短视频业务以及未来媒体。我们的合作研究很多都和媒体任务相关,快手会提供很多技术需求与对应的资源。」正因为研究与应用之间的路径非常短,新研究才能更快得到迭代。
在快手做研究应该会很有意思,机器之心也比较好奇做研究的框架或开源策略都是什么样的。为此,下面我们可以从两方面一瞥快手研究者的思路。
研究框架用什么?
「这当然会分场景,对于 CV 研究来说,PyTorch 或 TensorFlow 开源框架是足够的。但是对于产品,我们新成立的 AI 平台部门则主要致力于提供一些通用化的机器学习和深度学习的工具,它会为不同的业务优化一些底层技术。」,刘霁说。
对于研究框架,新入职的博士同学说:「TensorFlow 2.0 尝试构建易于使用的动态图编程,但 1.X 的很多历史包袱也要支持,因此整体上很难做到统一。此外,TensorFlow 1.X 暴露了过多不需要关心的 API,而 2.0 目前又存在很多问题。所以,做研究我更喜欢用 PyTorch。」
论文代码要开源?
在快手研究者的眼中,开源是一件很重要的事,但好的研究成果并不一定需要通过开源来体现。
「首先,开源代码对研究肯定是一件有益的事,能极大方便同行的研究做比较。但与此同时,能够复现结果的代码,并不一定表示其方法有价值,这两者并不一定是绝对的相关性。」,刘霁说,「我个人认为,好方法并不一定需要实验来辅证,它们本身就有足够深远的洞见。大家在看实验之前就能预见它在哪些条件下能 Work,这样的研究就是非常有价值的。」
有了众多资源与研究经验,西雅图实验室才能持续地针对某个研究领域做出重要贡献。这里有一个例子,那就是模型压缩,西雅图实验室今年在这个领域已经发了 4 篇顶会论文。
模型压缩在快手
从今年 ICLR、CVPR 到正在进行中的 NeurIPS,快手西雅图实验室及合作者探索了很多模型压缩方法。这些方法从不同的维度解决深度学习应用问题,例如降低模型能耗、创新压缩算法、联合优化压缩算法等等。
「快手的应用平台大多都体现在手机上,很多模型与算法都要部署到手机端,因此功耗、实时响应都非常重要。模型的应用价值,首先在于它的延迟、能耗等指标满足要求,其次才着重提高准确率。」,刘霁说,「除了移动端的应用,云端也需要模型压缩。当模型非常大,推断效率就很低,这不仅影响服务效果,同时服务器也容易宕机。」
目前快手针对不同手机型号会单独考虑压缩算法,但很快就会将这些前沿的压缩算法都会做成 API,并用于更广泛的压缩。刘霁表示:「应用模型压缩最困难的地方在于打通链路,从底层硬件、压缩算法到部署到实际产品,我们需要理解每一个环节,然后再完成整体的联合优化。」
模型压缩这条逻辑线
之前机器之心曾介绍过「快手有的放矢的模型压缩」,它以硬件能耗为目标进行剪枝等操作,并期待构建最节能的深度学习模型。在近日举办的 NeurIPS 2019 中,快手及合作者又在另外两方面探讨模型压缩的新可能:修改最优化器以「自动」剪枝模型权重、联合不同的压缩算法以学习怎样组合最合适。
「今年 4 篇模型压缩方面的顶会论文是有一条逻辑线的,我们从不同的维度来提升模型压缩的效果。」,刘霁说,「之前 ICLR 与 CVPR 2019 的研究主要是利用对硬件的建模指导模型压缩,后面第一篇尝试对各种压缩方法做一个联合优化,第二篇则探索最优化方法本身的效果。这三者分别从不同的维度探索模型压缩,它们是可以联合的。」
现在,让我们看看快手及合作者在 NeurIPS 2019 完成的两项模型压缩研究,它们的核心思想都非常有价值。
优化器:「有些参数生而冗余」
剪枝在模型压缩中非常常见,我们训练模型后,可以根据某些标准删除一些不重要的权重。但通常情况下,这种裁剪会造成精度损失,所以需要重新微调模型。那么有没有办法在训练中就完成剪枝,让模型在剪枝率的约束下进行学习?我们可以把剪枝嵌入到最优化器内,让模型不再更新「生而冗余」的权重。
对于直接学习紧凑的网络,最直观的思路是,对于那些「重要的」权重,我们使用优化器更新,而对于那些「不重要」的权重,那就让它们衰减到零吧。思想很简单,但问题是,什么是重要的,什么又是不重要的权重?这就是这篇论文该解决的问题。

在这一篇论文中,研究者提出了名为全局稀疏动量 SGD 的方法(GSM),该算法直接修改梯度流来进行 DNN 剪枝。在每一次训练迭代中,一般 SGD 用目标函数求得的梯度来更新所有参数,然而在 GSM 中,只有较为重要的少数参数用目标函数的梯度来更新(称为「活性更新」),大多数参数只用权值衰减来进行更新(称为「负向更新」)。
这样,随着训练的进行,大多数参数都会变得无限接近于 0。因而,当训练结束后,去除这些无限接近 0 的参数不会对网络的精度产生影响。
这种从优化器出发的剪枝方法有非常好的属性:
自动发现每层合适的稀疏率:如果 DNN 中的某一层对剪枝比较敏感,GSM 会对该层权重执行更「轻」的剪裁。也就是说,给定全局压缩率作为唯一目标,GSM 能够根据每层的敏感性自动选择合适的剪枝比率。
发现更好的 winning lottery tickets:ICLR 2019 最佳论文 The Lottery Ticket Hypothesis 表明,如果有些参数在训练后的网络中显得很「重要」,它们很可能在随机初始化后就是「重要」的。即在初始化的网络中存在某些稀疏子结构,单独训练这样的子结构可以得到与训练整个网络相媲美的性能,GSM 就能找到更好的稀疏子结构。
从数学看优化器
好了,该看看 GSM 的具体过程了,一般带动量的 SGD 如下所示,它会先计算一个累积的梯度,可以直观理解为下降小球的「惯性」。学习算法会根据这样的惯性找到更新方向,并更新对应的权重。
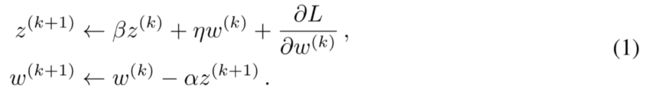
GSM 首先要决定对哪些参数进行「活性更新」,这就要求度量在一次迭代中每个参数对于模型的重要性。这样的重要性度量可以表示为:
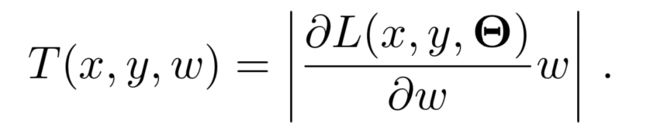
其中 Θ 表示模型的所有参数,如果权重的梯度小或者权重本身小,那么 T 值肯定很小,这个权重就不是重要的。我们可以根据全局压缩率为 P 以及刚算出来的 T 来选择更新哪些权重,具体而言,总参数量的 1/P 是需要更新的,因此对于 T 值最大的 1/P 个参数进行更新,其它参数执行权重衰减就行了。

如上将 T 应用到方程 1 就能得到 GSM 更新式。B 矩阵中只有 1/P 的值为 1,其它为 0,它再与梯度矩阵执行对应元素相乘就表明,模型只会采用梯度更新这 1/P 的参数。
对抗训练:「我也能变压缩」
现在我们从另一个角度,看看怎样统一模型紧凑性与鲁棒性,怎样联合不同的压缩方法。也就是说,我们要保证压缩过后的模型具有足够小,且该模型还能抵御来自于对抗样本的攻击。
为了同时兼顾模型的鲁棒性和紧凑性,研究者提出了一个全新的对抗训练模型压缩算法(ATMC)。该方法同时囊括了剪枝和量化方法,并且将模型压缩作为对抗性训练的约束条件,从而得到满足压缩约束的模型。
在研究者的实验中,ATMC 压缩后的模型在压缩比例、泛化能力和模型鲁棒性之间达到了较好的平衡。

ATMC 算法的优点在于,它首次通过联合训练实现了鲁棒性与紧凑性兼顾,它可以将大规模模型压缩为更稳健的小模型。它的三大特点在于:
ATMC 以对抗性训练问题作为优化目标(极小化极大优化问题);
研究者将结构化的权重分解、元素级的稀疏化剪枝、以及模型权重量化作为整个优化问题的约束;
研究者证明 ADMM 算法可以有效解决带有约束的极小化极大优化问题,并得到具有紧凑性和鲁棒性的模型。
从数学看对抗与压缩
对于对抗训练,研究者将其作为 ATMC 的优化目标,这是一个极小极大化问题。首先通过白盒攻击,攻击者通过这些窃听权重、架构等信息,生成一个能最大程度欺骗模型的对抗性样本。随后作为防御者,它会最小化模型在对抗样本出错的概率,从而变得更稳健。这种极小极大地对抗训练,其实思想和生成对抗网络比较像。
具体的,这种对抗性训练目标可以表示为如下两个方程,即最大化错误以获得对抗样本,最小化错误以获得准确的模型。

其次对于联合模型压缩,研究者将剪枝、权重分解和量化作为上述优化目标的约束条件,希望模型在控制大小的情况学习如何变得准确与稳健。值得注意的是,所有优化约束仅包含两个超参数,ATMC 将根据对压缩性和鲁棒性的需求自动地调整每层权重的稀疏性。
如下所示分别为权重分解、剪枝和量化三种约束条件。权重 W 为某个卷积层的权重矩阵,权重分解相当于通道级的剪枝算法、剪枝相当于元素级的裁剪方法。在考虑模型修剪的压缩方法的同时,研究者也引入了权重量化方法来进行模型压缩,即给定每层参数的比特宽度,并根据每层的具体情况计算量化字典。

结合这两大模块,我们就可以得到 ATMC 框架的整体优化目标:
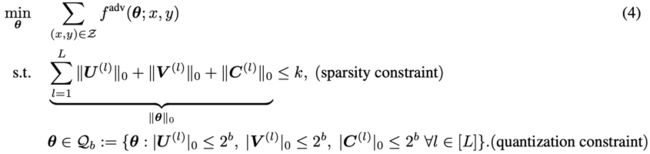
这个目标函数看起来很复杂,极小极大化优化目标也就算了,还带有两组约束条件,似乎常见的优化器都无能为力了。至于如何解这样带约束的优化目标,那又是外一个很有意思的话题了。读者可以参考原论文或者之前基于能耗的模型压缩方法,看看 ADMM 优化框架如何解这类带约束的最优化问题。
最后,除了各种压缩算法,本身更紧凑的模型也是非常重要的一个方向,从最近 Quoc V. Le 等研究者的 EfficientNet 与 EfficientDet 就能明显感觉到。总的来说,深度学习想要应用,模型的计算要求还是最为关键的那一类问题。
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。