buffer cache 深度解析+
本文内容整理自网络:
本文首先详细介绍了oracle中buffer cache的概念以及所包含的内存结构。然后结合各个后台进程(包括DBWRn、CKPT、LGWR等)深入介绍了oracle对于buffer cache的管理机制,并详细解释了oracle为什么会采用现在的管理机制,是为了解决什么问题。比如为何会引入touch次数、为何会引入增量检查点等等。最后全面介绍了有关buffer cache监控以及调优的实用方法。
1. buffer cache的概念
用最简单的语言来描述oracle数据库的本质,其实就是能够用磁盘上的一堆文件来存储数据,并提供了各种各样的手段对这些数据进行管理。作为管理数据的最基本要求就是能够保存和读取磁盘上的文件中的数据。众所周知,读取磁盘的速度相对来说是非常慢的,而内存相对速度则要快的多。因此为了能够加快处理数据的速度,oracle必须将读取过的数据缓存在内存里。而oracle对这些缓存在内存里的数据起了个名字:数据高速缓存区(db buffer cache),通常就叫做buffer cache。按照oracle官方的说法,buffer cache就是一块含有许多数据块的内存区域,而这些数据块主要都是数据文件里的数据块内容的拷贝。通过初始化参数:buffer_cache_size来指定buffer cache的大小。oracle实例一旦启动,该区域大小就被分配好了。
buffer cache所能提供的功能主要包括:
1) 通过缓存数据块,从而减少I/O。
2) 通过构造CR块,从而提供读一致性功能。
3) 通过提供各种lock、latch机制,从而提供多个进程并发访问同一个数据块的功能。
2.buffer cache的内存结构
2.1 buffer cache概述
oracle内部在实现其管理的过程中,有两个非常有名的名词:链表和hash算法。
链表是一种数据结构,通过将对象串连在一起,从而构成链表结构。这样,如果要修改、删除、查找某个对象的话,都可以先到链表中去查找,而不必实际的访问物理介质(这样可以直接修改删除查找某个块对应的buffer header)。oracle中最有名的链表大概就是LRU链表了,我们后面会介绍它。
而hash算法则是为了能够进行快速查找定位所使用一种技术。所谓hash算法,就是根据要查找的值,对该值进行一定的hash算法后得出该值所在的索引号,然后进入到该值应该存在的一列数值列表(可以理解为一个二维数组)里,通过该索引号去找它应该属于哪一个列表。然后再进入所确定的列表里,对其中所含有的值,进行一个一个的比较,从而找到该值。这样就避免了对整个数值列表进行扫描才能找到该值,这种全扫描的方式显然要比hash查找方式低效很多。其中,每个索引号对应的数值列在oracle里都叫做一个hash bucket。
我们来列举一个最简单的hash算法。假设我们的数值列表最多可以有10个元素,也就是有10个hash buckets,每个元素最多可以包含20个数值。则对应的二维数组就是t[10][20]。我们可以定义hash算法为n MOD 10。通过这种算法,可以将所有进入的数据均匀放在10个hash bucket里面,hash bucket编号从0到9。比如,我们把1到100都通过这个hash函数均匀放到这10个hash bucket里,当查找32在哪里时,只要将32 MOD 10等于2,这样就知道可以到2号hash bucket里去找,也就是到t[2][20]里去找,2号hash bucket里有10个数值,逐个比较2号hash bucket里是否存在32就可以了。
buffer cache就是使用多个hash bucket来管理的,其hash算法当然比我们前面列举的要复杂多了。
我们先来看下面这个图一。这副图从逻辑上说明了整个buffer cache的结构是怎么样的。这副图的右
上角列出了三个名词:hash bucket、buffer header和hash chain。
这里的hash bucket就是我们前面说明hash算法中提到的二维数组的第一维。它是通过对buffer header
里记录的数据块地址和数据块类型运用hash算法以后,得到的组号。
这里的hash chain就是属于同一个hash bucket的所有buffer header所串起来的链表。实际上,hash
bucket只是一个逻辑上的概念。每个hash bucket都是通过不同的hash chain而体现出来的。每个hash chain都会由一个cache buffers chains latch来管理其并发操作。
而对于buffer header来说,每一个数据块在被读入buffer cache时,都会先在buffer cache中构造一个buffer header,buffer header与数据块一一对应。buffer header包含的主要信息有:
1) 该数据块在buffer cache中实际的内存地址。就是上图中的虚线箭头所表示的意思。
2) 该数据块的类型,包括data、segment header、undo header、undo block等等。
3) 该buffer header所在的hash chain,是通过在buffer header里保存指向前一个buffer header的指针和指向后一个buffer header的指针的方式实现的。
4) 该buffer header所在的LRU、LRUW、CKPTQ等链表(这些链表我们后面都会详细说明)。也是通过记录前后buffer header指针的方式实现。
5) 当前该buffer header所对应的数据块的状态以及标记。
6) 该buffer header被访问(touch)的次数。
7) 正在等待该buffer header的进程列表(waiter list)和正在使用该buffer header的进程列表(user list)。(难道正在使用该buffer header和正在等待该buffer header的进程表会皴法在当前buffer header中?对,正在使用的进程存在里面,可以理解,为什么正在等待的进程也在里面呢?)
buffer cache中,缺省的hash bucket的数量或者说缺省有多少条hash chain链表,是由一个隐藏参数:
_db_block_hash_buckets决定的。至于该参数的取值,在我的测试中,8i下,该参数缺省为db_block_buffers×2;但是到了9i以后,该参数似乎取的是小于且最接近于db_block_buffers×2的素数。
2.2 转储buffer cache
就象实例中的其他内存结构一样,oracle提供了可以将buffer cache转储到跟踪文件的方法。方法如下:
这里的level有很多值,分别可以转储buffer cache中的不同的内容。level的可选值包括:
1 只转储buffer header
2 在level 1的基础上再转储数据块头
3 在level 2的基础上再转储数据块内容
4 转储buffer header和hash chain
5 在level 1的基础上再转储数据块头和hash chain
6 在level 2的基础上再转储数据块内容和hash chain
8 转储buffer header和hash chain以及users/waiters链表
9 在level 1的基础上再转储数据块头、hash chain以及users/waiters链表
10 在level 2的基础上再转储数据块内容、hash chain以及users/waiters链表
我们创建一个简单的测试表,然后看看转储出来的buffer header是什么样子的。
这时我们知道buffer_test表的object_id是7987,同时,该表中只有2个block具有数据。1个是segment header,另一个就是实际存放了1这个值的数据块。接着我们把buffer header转储出来:
到user_dump_dest所定义的目录下,找到跟踪文件并打开,可以看到类似下面的信息,这里我们列出前两个buffer header以及我们建立的object_id为7087的buffer_test表所对应的buffer header的内容:
我们可以看到第一个BH (0x637F0720)的hash: [64be8000,65a5eab4]和第二个BH (0x64BE8000)的hash:[65a5eab4,637f0720]。这里记录的就是指向前一个buffer header和后一个buffer header的指针。这里,我们看到第一个BH所指向的后一个buffer header的指针是65a5eab4,而第二个BH所指向的前一个buffer header的指针也是65a5eab4,说明这两个buffer header是在同一个hash chain上。同样的,我们还可以看到类似结构的lru、ckptq、fileq,这些都是管理buffer header的一些链表结构。
然后,我们来看我们创建的buffer_test表所对应的buffer header。 首先,我们看到class,表示该buffer header所对应的数据块的类型,具体的值与含义的对应为:
1=data block;
2=sort block;
3=save undo block;
4=segment header;
5=save undo header;
6=free list;
7=extent map;
8=1st level bmb;
9=2nd level bmb;
10=3rd level bmb;
11=bitmap block;
12=bitmap index block;
13=unused;
14=undo header;
15=undo block。
我们可以看到与buffer_test表相关buffer header有两个:一个是4(segment header),另一个是1(data block)。
然后,我们看到rdba,这表示buffer header所对应的数据块在磁盘数据文件上的地址。我们可以看到class为1的buffer header的rdba为0x0180b00a (6/45066)。十六进制数。说明该数据块的位置是6号文件的45066号block里。018表示数据文件号乘以4,而b00a表示数据块的号。
上面一句算法是错的,正确的算法是这样的:
这个RDBA由,rfile# + block#组成的
相对文件号10位 block号22位
0x0180b00a解码以后就是:
0000 0001 1000 0000 1011 0000 0000 1010前10位代表rfile#
也就是
0110 = 6
00 0000 1011 0000 0000 1010 = 45066
我们看到,该buffer header指向的就是6号文件里的45066号数据块。我们可以再来看看表buffer_test
里的rowid所告诉我们的文件号以及数据块号,从下面可以看到,结果是一样的。
关于ROWID 和 rdba 参考:http://blog.csdn.net/changyanmanman/article/details/7486103
我们可以来看一下st,这表示buffer cache所指向的数据块的状态。一共有六种状态:
FREE(0)=可以被重用的数据块;
XCURRENT(1)=实例以排他方式获取的当前模式数据块;
SCURRENT(2)=可以与其他实例共享的当前模式数据块;
CR(3)=作为一致性读镜像的数据块,永远不会被写入磁盘;
READING(4)=正在从磁盘读出的数据块;
MRECOVERY(5)=正在进行介质恢复的数据块;
IRECOVERY(6)=正在进行实例恢复的数据块。
从状态说明中我们可以看到,现在表buffer_test的数据块都是当前模式的数据块。我们可以来构造一个CR状态的数据块。
1、分别建立两个session,在一个session中,执行:
2、不要提交,然后在另外一个session中,执行:
3、 然后我们转储buffer header后,到跟踪文件中找到obj为7087的记录,可以看到类似如下的内容。可以看到该buffer header的状态就是CR。
另外,我们还可以看到tch,就是表示该数据块被扫描的次数。 以上这些是转储出来的内容。Oracle还提供了视图来显示buffer header的内容,这就是X$BH。这个视图就是把转储到平面文件以后所看到的诸如hash、st、tch等的值以列的方式呈现出来。这里就不做过多的介绍了,有兴趣的话,可以将该视图取出的结果与转储出来的文件进行比较,就可以知道每一列的含义。
3.buffer cache的内部管理机制
3.1 在buffer cache中获取所需要的数据块的过程
当前台进程发出SELECT或者其他DML语句时,oracle根据SQL语句的执行计划所找到的数据块(根据查询索引或者全表扫描,找到要查询的数据条目所在的块,一般根据ROWID等信息,举个列子:一个简单的select语句,条件是empno=7788,根据索引,oracle会知道7788这个条目的ROWID,然后就能知道数据块的位置,到底是在那个表空间,那个对象,那个数据文件中),会构造一个名为数据块描述(buffer descriptor)的内存结构。该buffer descriptor位于session的PGA中,所包含的内容主要是数据块所在的物理地址(根据ROWID信息的第33-64bit构造出rbda)、数据块的类型、数据块所属对象的object id等信息。
随后,oracle会把对数据块请求的锁定模式以及所构造出来的buffer descriptor传入专门搜索数据块的函数中。在该函数中,oracle根据buffer descriptor所记录的信息,应用hash算法以后,得到要找的数据块所处的hash bucket,也就是确定该数据块在哪条hash chain上。然后,oracle进入该hash chain,从上面所挂的第一个buffer header开始搜索,一直搜索到最后一个buffer header。
在hash chain上搜索的逻辑如下:
1) 比较buffer header上所记录的数据块的地址(rdba),如果不符合,则跳过该buffer header。
2) 跳过状态为CR的buffer header。(说明有别的进程正在进行一致性读,所以才构造了这个cr块,如果我也要找这个块的原块,我需要自己再重新构造一个新的cr块,不会使用这个旧的cr块,如果我不是找这个块的原块,那我不需要构造,所以这两种情况下都是跳过cr块)
3) 如果遇到状态为READING(正在从磁盘上读出的数据块)的buffer header,则等待,一直等到该buffer header的状态改变以后再比较所记录的数据块的地址是否符合。(说不定是之前的查询,有可能就是这条sql语句,也有可能是之前的(自己用户或者其他用户的sql)语句,正好也需要读这个块内的数据,正在往内存里读,这下我就可以直接用前辈的努力就可以了)
4) 如果发现数据块地址符合的buffer header,则查看该buffer header是否位于正在使用的列表上,如果是位于正在使用的列表上,则判断已存在的锁定模式与当前所要求的锁定模式是否兼容,如果是兼容的,则返回该buffer header所记录的数据块地址,并将当前进程号放入该buffer header所处的正在使用的列表上(在开始介绍buffer header的时候有这一项,还有等待该buffer header的进程列表)。
5) 如果发现锁定模式不兼容,则根据找到的buffer header所指向的数据块的内容,构建一个新的、内容一样的、数据块状态为XCURRENT(实例以排他方式获取的当前模式数据块)的复制数据块,并且构造一个状态为CR的buffer header,同时该buffer header指向所新建立的复制数据块。然后,返回该复制数据块的地址,并将当前进程号放入该buffer header所处的正在使用的列表上。
6) 如果比较完整个hash chain以后还没发现所要找的buffer header,则从磁盘上读取数据文件。并将读取到的数据块所对应的buffer header挂到hash chain上。(之前我有个疑问,到底是在生成执行计划的时候就开始往内存里读取数据块?还是在用buffer descriptor 比较地址的时候读?现在知道了,是在用buffer descriptor 比较地址的时候往里读取的)
3.2 LRU和LRUW链表结构及其管理机制
3.2.1 LRU和LRUW链表结构概述
在前面,我们已经知道了oracle是如何在hash chain中搜索要找的数据块所对应的buffer header的过程,我们也知道如果在hash chain上没有找到所要的buffer header时,oracle会发出I/O调用,到磁盘上的数据文件中获取数据块,并将该数据块的内容拷贝一份到buffer cache中的内存数据块里(顺带提一句,内存数据块通常叫做buffer,而数据文件里的数据块通常叫做block,二者是一个意思)。这个时候,假如buffer cache是空的,比较好办,直接拿一个空的内存数据块来用即可。但是如果buffer cache中的内存数据块全都被用掉了,没有空的内存数据块了,怎么办?应该重新使用哪一个内存数据块?当然我们可以一个一个的比较内存数据块与其对应在数据文件中的数据块的内容是否一致,如果一致则可以将该数据块拿来,将其内容清空,然后拷贝上当前数据块的内容;如果不一致,则跳过,再找下一个。毫无疑问,这种方式效率低下。为了高效的管理buffer cache中的内存数据块,oracle引入了LRU和LRUW等链表等结构。
在buffer cache中,最耳熟能详的链表可能就是LRU链表了。在前面描述buffer cache结构的图上,也可以看到有两个链表:LRU和LRUW。在介绍LRU和LRUW前,先说明几个概念。
1) 脏数据块(dirty buffer):buffer cache中的内存数据块的内容与数据文件中的数据块的内容不一致。
2) 可用数据块(free buffer):buffer cache中的内存数据块为空或者其内容与数据文件中的一致。注意,可用数据块不一定是空的。
3) 钉住的数据块(ping buffer):当前正在更新的内存数据块。
4) 数据库写进程(DBWR):这是一个很底层的数据库后台进程。既然是后台进程,就表示该进程是不能被用户调用的。由oracle内置的一些事件根据需要启动该进程,该进程用来将脏数据块写入磁盘上的数据文件。
LRU表示Least Recently Used,也就是指最近最少使用的buffer header链表。LRU链表串连起来的buffer header都指向可用数据块。而LRUW则表示Least Recently Used Write,也叫做dirty list,也就是脏数据块链表,LRUW串起来的都是修改过但是还没有写入数据文件的内存数据块所对应的buffer header。某个buffer header要么挂在LRU上,要么挂在LRUW上,不能同时挂在这两个链表上。
随着硬件技术的发展,电脑的内存越来越大。buffer cache也是越来越大,只用一条LRU和一条LRUW来管理buffer header已经不够用了。同时oracle还引入了多个DBWR后台进程来帮助将buffer cache中的脏数据块写入数据文件,显然,多个DBWR后台进程都去扫描相同的LRUW链表会引起争用。为此oracle引入了working set(工作集)的概念。每个working set都具有它自己的一组LRU和LRUW链表。每个working set都由一个名为“cache buffers lru chain”的latch(也叫做lru latch)来管理,所以从这个意义上说,每一个lru latch就是一个working set。而每个被加载到buffer cache的buffer header都以轮询的方式挂到working set上去。也就是说,当buffer cache加载一个新的数据块时,其对应的buffer header会去找一个可用的lru latch(找这个工作集中的lru列表,将新加载进来的数据块挂到LRU列表上),如果没有找到,则再找下一个lru latch,直到找到为止。如果轮询完所有的lru latch也没能找到可用的lru latch,该进程只有等待latch free等待事件,同时出现在v$session_wait中,并增加“latch misses”。如果启用了多个DBWR后台进程的话,每个DBWR进程都会对应一个不同的working set,而且每个DBWR只会处理分配给它的working set,不会处理其他的working set。
我们已经知道一个lru latch就是一个working set,那么working set的数量也就是lru latch的数量。而lru latch的数量是由一个隐藏参数:_db_block_lru_latches决定的。该参数缺省值为DBWR进程的数量×8。
该参数最小必须为8,如果强行设置比8小的数值,oracle将忽略你设置的值,而使用8作为该参数值。
3.2.2 深入LRU链表
我们已经知道LRU链表是用来查找可以重用的内存数据块的,那么oracle是怎么使用LRU链表的呢?这里需要分为8i之前和8i以后两种情况。
在8i之前,我们举一个例子。假设buffer cache只能容纳4个数据块,同时只有一个hash chain和一个LRU。当数据库刚刚启动,buffer cache是空的。这时前台进程发出SELECT语句获取数据块时,oracle找一个空的内存数据块,并将其对应的buffer header挂到hash chain上。同时,oracle还会把该buffer header挂到LRU的最尾端。随后前台进程又发出SELECT语句,这时所找到的buffer header在LRU上会挂到前一个buffer header的后面,也就是说第二次SELECT语句所找到的buffer header现在变成了LRU的最尾端了。假设发出4句SELECT以后找到了4个buffer header,从而用完了所有的buffer cache空间。这个时候的LRU可以用下图二来表示。
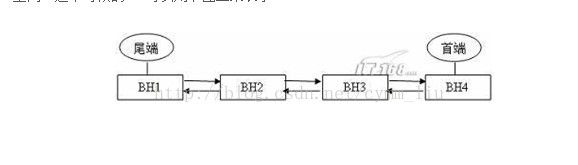
这个时候,发来了第五句SELECT语句。这时的buffer cache里已经没有空的内存数据块了。但是既然需要容纳下第五个数据块,就必然需要找一个可以被替换(后面会看到类似牺牲、重用的字样,它们和替换都是一个意思)的内存数据块。这个内存数据块会到LRU上去找。按照oracle设定的最近最少使用的原则,位于LRU最尾端的BH1将成为牺牲者,oracle会把该BH1对应的内存数据块的内容清空,并将当前第五句SQL所获得的数据块的内容拷贝进去。这个时候,BH1就成了LRU的首端,而BH2则成为了LRU的尾端。如下图三所示。在这种方式下,经常被访问的数据块可以一直靠近LRU的首端,也就保证了这些数据块可以尽可能的不被替换掉,从而保证了访问的效率。

图三
到了8i以后,oracle引入了一种更加复杂的机制来管理LRU上的数据块。8i以后,LRU和LRUW链表都具有两个子链表,分别叫做辅助链表和主链表。同时还对buffer header增加了一个属性:touch数量,也就是每个buffer header曾经被访问过的次数,来对LRU链表进行管理。oracle每访问一次buffer header,就会将该buffer header上的touch数量增加1,因此,touch数量“近似”的体现了某个内存数据块总共被访问的次数。注意,这只是近似,并不精确。因为touch的增加并没有使用latch来管理并发性。这只是一个大概值,表示趋势的,不用百分百的精确。
还是用上面的这个例子来说明。还是假设buffer cache只能容纳4个数据块,同时只有一个hash chain和一个LRU(确切的说应该是一对LRU主链表和辅助链表)。读入第一个数据块时,该数据块对应的buffer header会挂到LRU辅助链表(注意,这里是辅助链表,而不是主链表)的最末端,同时touch数量为1。读取第二个不同的数据块时,该数据块对应的buffer header会挂到前一个buffer header的后面,从而位于LRU辅助链表的最末端,同样touch为1。假设4个数据块全都用完以后的LRU链表可以用下图四描述。每个buffer header的touch数量都为1。

从上图中我们可以看到辅助LRU链表都挂满了,而主LRU链表还是空的。这个时候,前台发出第五句SQL语句,要求返回指定的数据块。这时,oracle发现buffer cache里已经没有空的内存数据块了,于是从辅助LRU链表的尾部开始扫描,也就是从BH1开始扫描,以查找可以被替代的数据块。扫描的过程中按照下面的逻辑来选择被牺牲的(也就是可以被替代的)数据块:
1) 如果被扫描到的buffer header的touch数量小于隐藏参数_db_aging_hot_criteria(该参数缺省为2)的值,则选中该buffer header作为牺牲者,并立即返回该buffer header所含有的数据块的地址。
2) 如果当前buffer header的touch数量大于_db_aging_hot_criteria的值,则不会使用该buffer header。但是如果当前的_db_aging_stay_count的值小于_db_aging_hot_criteria的值,则会将当前该buffer header的touch值赋值给_db_aging_stay_count;否则将当前buffer header的touch数量减掉一半。
按照上述的逻辑,这时将选出BH1作为牺牲者(因为BH1的touch数量为1,小于_db_aging_hot_criteria
的值),并将其对应的内存数据块的内容清空,同时将当前第五个数据块的内容拷贝进去。但是这里要注意,这个时候该BH1在LRU链表上的位置并不会发生任何的变化(这里是插入了新的数据块的内容,所以touc的数量没有变化,下面是返回已经有的数据块,所以touch的数量加1了,这样就保证了touch为1的数据块即不常用的数据块一直在辅助链表,而不会跑到主lru链表上)。而不会像8i之前的那样,BH1变成LRU链表的首端。
接下来,前台发来了第六句和第七句SQL,分别要返回与第五句和第四句SQL一样的数据块,也就是要返回当前的BH1和BH4。这个时候,oracle会增加BH1和BH4的touch数量,同时将该BH1和BH4从辅助LRU链表上摘下,转移到主LRU链表的中间位置。可以用下图五描述。

图五
这个时候,如果发来了第八句SQL,要求返回与第三句SQL相同的数据块,也就是当前的BH3,则这时该BH3会插入主LRU链表上的BH1和BH4中间 ,注意每次向主LRU列表插入buffer header时都是向中间位置插入。如果发来了第九句SQL要求返回BH2,则我们可以知道,BH2会转移到主LRU链表的中间。这个时候,辅助LRU链表就空了,没有buffer header了。
这时,如果又发来第十句SQL,要求返回一个新的、buffer cache中不存在所需内容的数据块时。oracle会先扫描辅助LRU链表,发现上面没有任何的buffer header时,则必须扫描主LRU链表。从尾部开始扫描,采用前面说到的与扫描辅助LRU链表相同的规则挑选牺牲者。挑出的可以被替代的buffer header将从主LRU链表上摘下,放入辅助LRU链表。
从上面所描述的buffer header在辅助LRU链表和主LRU链表之间交替的过程中,我们可以看出,oracle改进LRU链表的 管理方式的目的,就是想千方百计的能够将多次被访问的数据块保留在内存里,同时又要平衡有限的内存资源。这种方式相比较8i之前而言,无疑是进步很多的。在8i之前中,某个数据块可能只会被访问一次,但是就这么一次的访问就将该数据块放到了LRU的首端,从而可能就挤掉了一个LRU上不是那么经常被访问,但是也会多次访问的数据块。而8i以后,将访问一次的数据块和访问一次以上的数据块彻底分开,而且查找可用数据块时,始终都是从辅助LRU链表开始扫描。实际上也就使得越倾向于只访问一次的数据块越快的从内存中清理出去。
3.2.3 LRUW链表管理
从前面我们已经知道SELECT语句读取数据块到buffer cache的过程。那么我们必然会产生另外一个疑问,就是当使用DML等语句修改了buffer cache里的内存数据块以后的过程是怎样的?实际上,为了能够最有效、安全的完成将内存数据块写入数据文件的过程,oracle提供了比读取数据块更为复杂的机制。
我们已经知道LRUW表示脏数据块链表,该链表上的buffer header指向的都是已经从LRU链表上摘下来、其对应的内存数据块里的内容已经被修改、但是还没有被写入数据文件的内存数据块。在这些脏数据块在能够被重用之前,它们必须要被DBWR写入磁盘。从8i以后,LRUW链表同样包含两个子链表:辅助LRUW链表和主LRUW链表。那么LRUW链表是如何产生buffer header的呢?oracle又是如何对其进行管理的呢?
我们还是接着上面图五所示的例子来说明。假设这个时候,前台用户发出DML语句,要求修改BH2所指向的内存数据块。这时,按顺序发生下面的动作:
1) oracle会将BH2从辅助LRU链表上摘下,同时插入主LRU链表的中间,也就是插入BH1和BH4中间,同时增加BH2的touch的数量。(与selectBH2的效果一样, 都会使要查找的块从辅助链表上摘下,放入主LRU链表)
2) 将该BH2的标记设置为钉住(ping)。(这个在select语句中没有说明,不知道有没有,应该是没有的)
3) 更新BH2对应的内存数据块的内容。
4) 更新完以后,取消钉住的标记(在主LRU列表上进行第一次更新)。
5) 将BH2从主LRU链表转移到主LRUW链表上。
6) 如果这个时候又有进程发出更新BH2所对应的内存数据块的内容,则BH2再次被钉住,更新,取消钉住(可以在主LRUW列表上继续更新)。
7) DBWR启动以后,在扫描主LRUW链表时会将BH2转移到辅助LRUW链表上(必须转移到辅助LURW列表才能写入到磁盘)。
8) DBWR将辅助LRUW链表上的BH2对应的数据块写入数据文件。
9) 确认成功写入数据文件以后,将BH2从辅助LRUW链表上转移到辅助LRU链表上(返回到辅助LUR列表)。
从上面的描述中,我们可以看到,主LRUW链表上包含的buffer header要么是已经更新完了的数据块,要么是被钉住正在更新的数据块。而当DBWR进程启动以后,它会扫描主LRUW链表,并跳过正在被钉住更新的buffer header,而将已经更新完了的buffer header从主LRUW链表上摘除,并转移到辅助LRUW链表上去。
扫描完主LRUW链表,或扫描的buffer header的个数达到一定限度时,DBWR会转到辅助LRUW上,将辅助LRUW上面的buffer header所对应的数据块写入数据文件。所以说,对于辅助链表上的buffer header来说,要么是正在等待被写入的;要么就是已经发出写入请求,正在写入而还没写完的。这里要注意的是,buffer header进入LRUW链表,是从尾端进入;而DBWR扫描LRUW链表时,则是从首端开始。
顺带提一句,这里将主LRUW链表和辅助LRUW链表分开,主要就是为了提高DBWR在主LRUW链表上扫描的效率。如果只有主LRUW链表而没有辅助LRUW链表的话,势必造成三种类型buffer header交织在LRUW链表上:
1)正在被钉住更新的buffer header;
2)已经更新完,而正在等待被写入数据文件的buffer header;
3)已经发出写请求,正在写而尚未写完的buffer header。
在这种情况下,必然造成DBWR为了找到第二种类型的buffer header而需要扫描不该扫描的第三种类型的buffer header。(把第三种已经发出写请求,但是还没有写完的BH放到了辅助LRUW列表里,避免了扫描第二种已经更新完成,等待被写入的的BH)
3.2.4 DBWR进程
我们已经知道DBWR进程负责将脏数据块写入磁盘。它是一个非常重要的进程,在后台进程中的sid为2,在PMON进程启动以后随即启动。
随着内存的不断增加,1个DBWR进程可能不够用了。所以从8i起,我们可以为系统配置多个DBWR进程。初始化参数:db_writer_processe决定了启动多少个DBWR进程。每个DBWR进程都会分配一个lru latch,也就是说每个DBWR进程对应一个working set。因此oracle建议配置的DBWR进程的数量应该等于lru latch的数量,同时应该小于CPU的数量。系统启动时,就确定好了working set与DBWR进程的对应关系,每个DBWR进程只会将分配给自己的working set上的脏数据块写入数据文件。
DBWR作为一个后台进程,只有在某些条件满足了才会触发。这些条件包括:
1) 当进程在辅助LRU链表和主LRU链表上扫描以查找可以覆盖的buffer header时,如果已经扫描的buffer header的数量到达一定的限度(由隐藏参数:_db_block_max_scan_pct决定)时,触发DBWR进程。_db_block_max_scan_pct表示已经扫描的buffer header的个数占整个LRU链表上buffer header总数的百分比。这时,搜索可用buffer header的进程挂起,在v$session_wait中表现为等待“free buffer wait”事件,同时增加v$sysstat中的“dirty buffers inspected”的值。
2) 当DBWR在主LRUW链表上查找已经更新完而正在等待被写入数据文件的buffer header时,如果找到的buffer header的数量超过一定限度(由隐藏参数:_db_writer_scan_depth_pct决定)时,DBWR就不再继续往下扫描了,而转到辅助LRUW链表上将其上的脏数据块写入数据文件。_db_writer_scan_depth_pct表示已经扫描的脏数据块的个数占整个主LRUW链表上buffer header总数的百分比。
3) 如果主LRUW链表和辅助LRUW链表上的脏数据块的总数超过一定限度,也将触发DBWR进程。该限度由隐藏参数:_db_large_dirty_queue决定。
4) 发生增量检查点(incremental checkpoint)或完全检查点(complete checkpoint)时触发DBWR。
5) 每隔三秒钟启动一次DBWR。
6) 将表空间设置为离线(offline)状态时触发DBWR。
7) 发出命令:alter tablespace … begin backup,从而将表空间设置为热备份状态时触发DBWR。
8) 将表空间设置为只读状态时,触发DBWR。
9) 删除对象时(比如删除某个表)会触发DBWR。
当DBWR要写脏数据块时,并不是说立即将所有的脏数据块都同时写入磁盘。为了尽量减少物理的
I/O的次数,DBWR会将要写的脏数据块所对应的buffer header拷贝到一个名为批量写(write batch)的结构中。每个working set所对应的DBWR进程都可以向该结构里拷贝buffer header。当write batch的buffer header的个数达到一定限额时,才会发生实际的I/O,从而将脏数据块写入磁盘。这个限额为硬件平台所能支持的同时并发的异步I/O的最大数量。8i之前是可以用隐藏参数(_db_block_write_batch)来控制这个限额的。但是8i以后,取消了该参数,而由oracle自己来计算。
将内存数据块写入数据文件实在是一个相当复杂的过程,在这个过程中,首先要保证安全。所谓安全,就是在写的过程中,一旦发生实例崩溃,要有一套完整的机制能够保证用户已经提交的数据不会丢失;其次,在保证安全的基础上,要尽可能的提高效率。众所周知,I/O操作是最昂贵的操作,所以应该尽可能的将脏数据块收集到一定程度以后,再批量写入磁盘中。
直观上最简单的解决方法就是,每当用户提交的时候就将所改变的内存数据块交给DBWR,由其写入数据文件。这样的话,一定能够保证提交的数据不会丢失。但是这种方式效率最为低下,在高并发环境中,一定会引起I/O方面的争用。oracle当然不会采用这种没有扩展性的方式。oracle引入了CKPT和LGWR这两个后台进程,这两个进程与DBWR进程互相合作,提供了既安全又高效的写脏数据块的解决方法。
用户进程每次修改内存数据块时,都会在日志缓冲区(redo buffer)中构造一个相应的重做条目(redo entry),该重做条目描述了被修改的数据块在修改之前和修改之后的值。而LGWR进程则负责将这些重做条目写入联机日志文件。只要重做条目进入了联机日志文件,那么数据的安全就有保障了,否则这些数据都是有安全隐患的。LGWR 是一个必须和前台用户进程通信的进程。LGWR 承担了维护系统数据完整性的任务,它保证了数据在任何情况下都不会丢失。
LGWR将重做条目写入联机日志文件的情况分两种:后台写(background write)和同步写(sync write)。触发后台写的条件有四个:
1)每隔三秒钟,LGWR启动一次;
2)在DBWR启动时,如果发现脏数据块所对应的重做条目还没有写入联机日志文件,则DBWR触发LGWR进程并等待LRWR写完以后才会继续;
3)重做条目的数量达到整个日志缓冲区的1/3时,触发LGWR;
4)重做条目的数量达到1MB时,触发LGWR。
而触发同步写的条件就一个:当用户提交(commit)时,触发LGWR。
假如DBWR在写脏数据块的过程中,突然发生实例崩溃。我们已经知道,用户提交时,oracle是不一定会把提交的数据块写入数据文件的。那么实例崩溃时,必然会有一些已经提交但是还没有被写入数据文件的内存数据块丢失了。当实例再次启动时,oracle需要利用日志文件中记录的重做条目在buffer cache中重新构造出被丢失的数据块,从而完成前滚和回滚的工作,并将丢失的数据块找回来。于是这里就存在一个问题,就是oracle在日志文件中找重做条目时,到底应该找哪些重做条目?换句话说,应该在日志文件中从哪个起点开始往后应用重做条目?注意,这里所指的日志文件可能不止一个日志文件。
因为oracle需要随时预防可能的实例崩溃现象,所以oracle在数据库的正常运行过程中,会不断的定位这个起点,以便在不可预期的实例崩溃中能够最有效的保护并恢复数据。同时,这个起点的选择非常有讲究。首先,这个起点不能太靠前,太靠前意味着要处理很多的重做条目,这样会导致实例再次启动时所进行的恢复的时间太长;其次,这个起点也不能太靠后,太靠后说明只有很少的脏数据块没有被写入数据文件,也就是说前面已经有很多脏数据块被写入了数据文件,那也就意味着只有在DBWR启动的很频繁的情况下,才能使得buffer cache中所残留的脏数据块的数量很少。但很明显,DBWR启动的越频繁,那么所占用的写数据文件的I/O就越严重,那么留给其他操作(比如读取buffer cache中不存在的数据块等)的I/O资源就越少。这显然也是不合理的。
从这里也可以看出,这个起点实际上说明了,在日志文件中位于这个起点之前的重做条目所对应的在buffer cache中的脏数据块已经被写入了数据文件,从而在实例崩溃以后的恢复中不需要去考虑。而这个起点以后的重做条目所对应的脏数据块实际还没有被写入数据文件,如果在实例崩溃以后的恢复中,需要从这个起点开始往后,依次取出日志文件中的重做条目进行恢复。考虑到目前的内存容量越来越大,buffer cache也越来越大,buffer cache中包含几百万个内存数据块也是很正常的现象的前提下,如何才能最有效的来定位这个起点呢?
为了能够最佳的确定这个起点,oracle引入了名为CKPT的后台进程,通常也叫作检查点进程(checkpoint process)。这个进程与DBWR共同合作,从而确定这个起点。同时,这个起点也有一个专门的名字,叫做检查点位置(checkpoint position)。
oracle为了在检查点的算法上更加的具有可扩展性(也就是为了能够在巨大的buffer cache下依然有效工作),引入了检查点队列(checkpoint queue),该队列上串起来的都是脏数据块所对应的buffer header。
而DBWR每次写脏数据块时,也是从检查点队列上扫描脏数据块,并将这些脏数据块实际写入数据文件的。当写完以后,DBWR会将这些已经写入数据文件的脏数据块从检查点队列上摘下来。这样即便是在巨大的buffer cache下工作,CKPT也能够快速的确定哪些脏数据块已经被写入了数据文件,而哪些还没有写入数据文件,显然,只要在检查点队列上的数据块都是还没有写入数据文件的脏数据块。
而且,为了更加有效的处理单实例和多实例(RAC)环境下的表空间的检查点处理,比如将表空间设置为离线状态或者为热备份状态等,oracle还专门引入了文件队列(file queue)。文件队列的原理与检查点队列是一样的,只不过每个数据文件会有一个文件队列,该数据文件所对应的脏数据块会被串在同一个文件队列上;
同时为了能够尽量减少实例崩溃后恢复的时间,oracle还引入了增量检查点(incremental checkpoint),从而增加了检查点启动的次数。如果每次检查点启动的间隔时间过长的话,再加上内存很大,可能会使得恢复的时间过长。因为前一次检查点启动以后,标识出了这个起点。然后在第二次检查点启动的过程中,DBWR可能已经将很多脏数据块已经写入了数据文件,而假如在第二次检查点启动之前发生实例崩溃,导致在日志文件中,所标识的起点仍然是上一次检查点启动时所标识的,导致oracle不知道这个起点以后的很多重做条目所对应的脏数据块实际上已经写入了数据文件,(我的理解:前滚恢复到日志的最后一条重做条目,发现没有检查点,接着再回滚,回到上一个检查点对应的日志条目)从而使得oracle在实例恢复时再次重复的处理一遍,效率低下,浪费时间。
上面说到了有关CKPT的两个重要的概念:检查点队列(包括文件队列)和增量检查点。
检查点队列在我们上面转储出来的buffer header里可以看到,就是类似ckptq: [65abceb4,63bec66c]和fileq: [65abcfbc,63becd10]的结构,记录的同样都是指向前一个buffer header和指向后一个buffer header的指针。这个队列上面挂的也是脏数据块对应的buffer header链表,但是它与LRUW链表不同。检查点队列上的buffer header是按照数据块第一次被修改的时间的先后顺序来排列的。越早修改的数据块的buffer header排在越前面,同时如果一个数据块被修改了多次的话,在该链表上也只出现一次。而且,检查点队列上的buffer header还记录了脏数据块在第一次被修改时,所对应的重做条目在重做日志文件中的地址,也就是RBA(Redo Block Address)。同样在转储出来的buffer header中可以看到类似LRBA: [0xe9.229.0]的结构,这就是RBA,L表示Low,也就是第一次被修改的时候的RBA。但是注意,在检查点队列上的buffer header,并不表示一定会有一个对应的RBA,比如控制文件重做(controlfile redo)就不会有相应的RBA。对于没有对应RBA的buffer header来说,在检查点队列上始终处于最尾端,其优先级永远比有RBA的脏数据块的buffer header要低。8i以前,每个working set都有一个检查点队列以及多个文件队列(因为一个数据文件对应一个文件队列);而从8i开始,每个working set都有两个检查点队列,每个检查点都会由checkpoint queue latch来保护。
而增量检查点是从8i开始出现的,是相对于8i之前的完全检查点(complete checkpoint)而言的。完全检查点启动时,会标识出buffer cache中所有的脏数据块,然后启动DBWR进程将这些脏数据块写入数据文件。8i之前,日志切换的时候会触发完全检查点。而到了8i及以后,完全检查点只有在两种情况下才会被触发:
1)发出命令:alter system checkpoint;
2)除了shutdown abort以外的正常关闭数据库。
注意,这个时候,日志切换不会触发完全检查点,而是触发增量检查点。8i所引入的增量检查点每隔三秒钟或发生日志切换时启动。它启动时只做一件事情:找出当前检查点队列上的第一个buffer header,并将该buffer header中所记录的LRBA(这个LRBA也就是checkpoint position了)记录到控制文件中去。如果是由日志切换所引起的增量检查点,则还会将checkpoint position记录到每个数据文件头中。也就是说,如果这个时候发生实例崩溃,oracle在下次启动时,就会到控制文件中找到这个checkpoint position作为在日志文件中的起点,然后从这个起点开始向后,依次取出每个重做条目进行处理。
上面所描述的概念,用一句话来概括,其实就是DBWR负责写检查点队列上的脏数据块,而CKPT负责记录当前检查点队列的第一个数据块所对应的的重做条目在日志文件中的地址。
从这个意义上说,检查点队列比LRUW还要重要,LRUW主要就是区分出哪些数据块是脏的,不可以被重用的。而到底应该写哪些脏数据块,写多少脏数据块,则还是要到检查点队列上才能确定的。
我们用一个简单的例子来描述这个过程。假设系统中发生了一系列的事务,导致日志文件如下所示:

图六
队列的首端,而事务T123最后发生,所以位于靠近尾端的地方。同时,可以看到事务T1和T5都更新了7号数据文件的623号数据块。 而在检查点队列上只会记录该数据块的第一次被更新时的RBA,也就是事务T1对应的RBA102,而事务T5对应的RBA105并不会被记录。因为根本就不需要在检查点队列上记录。 当DBWR写数据块的时候,在写RBA102时,自然就把RBA105所修改的内容写入数据文件了。日志文件中所记录的提交标记也不会体现在检查点队列上,因为提交本身只是一个标记而已,不会涉及到修改数据块。
这时,假设发生三秒钟超时,于是增量检查点启动。 增量检查点会将检查点队列的第一个脏数据块所对应的RBA记录到控制文件中去。在这里,也就是RBA101会作为checkpoint position记录到控制文件中。
然后,DBWR后台进程被某种条件触发而启动。DBWR根据一系列参数及规则,计算出应该写的脏数据块的数量,从而将RBA101到RBA107之间的这5个脏数据块写入数据文件,并在写完以后将这5个脏数据块从检查点队列上摘除,而留下了4个脏数据块在检查点队列上。如果在写这5个脏数据块的过程中发生实例崩溃,则下次实例启动时,oracle会从RBA101开始应用日志文件中的重做条目。

图七
而在9i以后,在DBWR写完这5个脏数据块以后,还会在日志文件中记录所写的脏数据块的块号。如下图所示。这主要是为了在恢复时加快恢复的速度。

这时,又发生三秒钟超时,于是增量检查点启动。这时它发现checkpoint position为RBA109,于是将RBA109写入控制文件。如果接着发生实例崩溃,则oracle在下次启动时,就会从RBA109开始应用日志。(待续..........)
4. buffer cache的优化
4.1 buffer cache的设置优化
buffer cache的设置随着oracle版本的升级而不断变化。8i下使用db_block_buffers来设置,该参数表示buffer cache中所能够包含的内存数据块的个数;9i以后使用db_cache_size来设置,该参数表示buffer cache的总共的容量,可以用字节、K、M为单位来进行设置。而到了10g以后则更加简单,甚至可以不用去单独设置buffer cache的大小。因为10g引入了ASMM(Automatic Shared Memory Management)这样一个可以进行自我调整的组件,该组件可以自动调整shared pool size、db cache size等SGA中的组件。只需要设置sga_target参数,则其他组件就能够根据系统的负载和历史信息自动的调整各个部分的大小。要启动ASMM,只需要设置statistics_level为typical或all。
oracle8.0以前只能设置一种buffer cache,而从8.0以后,oracle提供了三种类型的buffer cache,分别是default、keep、recyle。keep和recycle是可选的,default必须存在。8i以前使用db_block_buffer设置default、buffer_pool_keep设置keep、buffer_pool_recycle设置recyle。
而8i以后使用db_cache_size设置default、
db_keep_cache_size设置keep、
db_recycle_cache_size设置recycle。
10g不能自动设置db_keep_cache_size和db_recycle_cache_size,必须手工设置。
同时,8i以前,这三种buffer cache是独立指定的,互不制约。而8i以后,这三种buffer cache是有相互制约关系的。如果指定了keep和recycle的buffer cache,则default类型的buffer cache的大小就是db_cache_size - buffer_pool_keep - buffer_pool_recycle。
通常将经常访问的对象放入keep类型的buffer cache里,而将不常访问的大表放入recycle类型的buffer cache里。其他没有指定buffer cache类型的对象都将进入default类型的buffer cache里。为对象指定buffer cache类型的方法如下:
如果没有指定buffer_pool短语,则表示该对象进入default类型的buffer cache。
这里要说明的是,从名字上看,很容易让人误以为这三种buffer cache提供了三种不同的管理内存数据块的机制。但事实上,它们之间在管理和内部机制上没有任何的区别。它们仅仅是为DBA们提供了一个选择,就是能够将数据库对象分成“非常热的”、“比较热的”和“不热的”这三种类型。因为数据库中总会存在一些“非常热”的对象,它们频繁的被访问。而如果某个时候系统偶尔做了一次大表的全表扫描,就有可能将这些对象清除出内存。为了防止这种情况的发生,我们可以设置keep类型的buffer cache,并将这种对象都移入keep buffer cache中。同样的,数据库中也总会有一些很大的表,可能每天为了生成一张报表,而只需要访问一次就可以了。但有可能就是这么一次访问,就将大部分的内存数据块清除出了buffer cache。为了避免这种情况的发生,可以设置recycle类型的buffer cache,并将这种偶尔访问的大表移入recycle buffer cache。
毫无疑问,如果你要设置这三种类型的buffer cache,你需要自己研究并等于你的数据库中的对象进行分类,并计算这些对象的大小,从而才能够正确的把它们放入不同的buffer cache。但是,不管怎么说,设置这三种类型的buffer cache只能算是最低层次的优化,也就是说在你没有任何办法的情况下,可以考虑设置他们。但是如果你能够优化某条buffer gets非常高SQL使其buffer gets降低50%的话,就已经比设置多个buffer cache要好很多了。
9i以后还提供了可以设置多种数据块尺寸(2、4、8、16 或 32k)的buffer cache,以便存放不同数据块尺寸的表空间中的对象。使用初始化参数:db_Nk_cache_size来指定不同数据块尺寸的buffer cache,这里的N就是2、4、8、16 或 32。创建数据库时,使用初始化参数:db_block_size所指定缺省的数据块尺寸用于system表空间。然后可以指定最多4个不同数据块尺寸的表空间,每种数据块尺寸的表空间必须对应一种不同尺寸的buffer cache,否则不能创建不同数据块尺寸的表空间。
我们可以看到,由于16k数据块所对应的buffer cache没有指定,所以创建16k数据块的表空间会失
败。于是我们先设置db_16k_cache_size,然后再试着创建16k数据块的表空间。
不同尺寸数据块的buffer cache的管理和内部机制与缺省数据块的buffer cache没有任何的分别。它最大的好处是,当使用可传输的表空间从其他数据库中将不同于当前缺省数据块尺寸的表空间传输过来的时候,可以不做很多处理的直接导入到当前数据库,只需要设置对应的数据块尺寸的buffer cache即可。同时,它对于调优OLTP和OLAP混合的数据库也有一定的用处。OLTP环境下,倾向于使用较小的数据块,而OLAP环境下,由于基本都是执行全表扫描,因此倾向于使用较大的数据块。这时,可以将OLAP的表转移到使用大数据块(比如32k)的表空间里去。而将OLTP的表放在中等大小的数据块(比如8k)的表空间里。
对于应该设置buffer cache为多大,oracle从9i开始通过设置初始化参数:db_cache_advice,从而提供了可以参照的建议值。oracle会监控default类型、keep类型和recycle类型的buffer cache的使用,以及其他五种不同数据库尺寸(2、4、8、16 或 32k)的buffer cache的使用。在典型负荷的时候,启用该参数,从而收集数据帮助用户确定最佳的db_cache_size的大小。该参数有三个值:
1) off:不收集数据。
2) on:开始分配内存收集数据,有可能引发CPU和内存的负担,可能引起4031错。
3) ready:不收集数据,但是收集数据的内存已经预先分配好了。通过把该参数值从off设置为ready,然后再设置为on,就可以避免出现4031错。
oracle会根据当前所监控到的物理读的速率,从而估算出在不同大小尺寸的buffer cache下,所产生的可能的物理读的数量。oracle会将这些收集到的信息放入视图:v$db_cache_advice中。每种类型的buffer cache都会有相应的若干条记录来表示所建议的buffer cache的大小。比如下面,我们显示对于缺省类型的、缺省数据块尺寸的buffer cache的建议大小应该是多少。
这里的字段estd_physical_read_factor表示在相应的buffer cache尺寸(由字段size_for_estimate表示)
下,估计从硬盘里读取数据的次数除以在内存里读取数据的次数。如果没有发生物理读则该比值为空。在
内存足够的前提下,这个比值应该是越低越好的。从上面的输出中,我们可以看到,如果将buffer cache
设置为60M,可以获得较好的性能,物理读也将会有一个显著的下降。但是设置为大于60M的话(比如
64M或68M),则不会降低物理读,反而浪费内存空间。所以从上面的查询结果中,我们可以知道,设置
为60M是比较合适的。
4.2 buffer cache的统计信息
为了对buffer cache进行性能的诊断,oracle提供了很多有关buffer cache的统计信息。这些统计信息大致可以分成三类:
1)有关用户发出的对内存数据块的请求相关的统计信息;
2)有关DBWR后台进程对内存数据块处理相关的统计信息;
3)RAC相关的统计信息。
我们在诊断buffer cache时,不需要关注所有的统计信息。这里主要介绍几个重要的统计信息,其他的统计信息都可以到《Oracle9i Database Reference: Appendix C》中找到。如下所示:
1) session logical reads:所有的逻辑读的数据块的数量。注意,其中包括先从硬盘上读数据块到内存里,再从内存里读数据块。
2) consistent gets:在一致性(consistent read)读模式下读取的内存里的数据块数量。包括从rollback segment里读取的数据块数量以及从data block buffer里读取的数据块数量。主要是通过select产生的。Update/delete也能产生很少量的此类数据块。注意:如果oracle的运行时间过长,由于oracle的bug导致consistent gets大大超过实际的数量。因此建议使用‘no work - consistent read gets’, ‘cleanouts only - consistent read gets’,‘rollbacks only - consistent read gets’, ‘cleanouts and rollbacks - consistent read gets’之和来代替consistent gets的值。
3) db block gets:在当前(current)模式下读取的内存里的数据块的数量。不是读取过去某个时点的数据块,而必须是当前最新的数据块。主要是通过update/delete/insert来产生的,因为DML需要当前最新的数据块才能对之进行改变。在字典管理表空间下,一些获得当前可用扩展空间的select语句也会产生此类数据块,因为必须得到当前最新的空间使用信息才能扩展。逻辑上,session logical reads = consistent gets + db block gets。
4) physical reads:从硬盘里读取的数据块的数量。注意,这个数量大于实际从硬盘里读取的数量,因为这部分block也包括了从操作系统缓存里读取的数据块数量。
5) physical reads direct:有些数据块不会先从硬盘读入内存再从内存读入PGA再传给用户,而是绕过SGA直接从硬盘读入PGA。比如并行查询以及从临时表空间读取数据。这部分数据块由于不缓存使得hit ratio不会被提高。
6) physical reads direct (lob):与physical reads direct一样。
7) free buffer inspected:这个值表示为了找到可用数据块而跳过的数据块的数量。这些被跳过的数据块就是脏的或被锁定的数据块。明显,这个值如果持续增长或很高,就需要增加buffer cache的大小了。
在获得了这些统计信息以后,我们可以计算buffer cache的命中率:
通常在OLTP下,hit ratio应该高于0.9。否则如果低于0.9则需要增加buffer cache的大小。在考虑
调整buffer cache hit ratio时,需要注意以下几点。
1) 如果上次增加buffer cache的大小以后,没有对提高hit ratio产生很大效果的话,不要盲目增加buffer cache的大小以提高性能。因为对于排序操作或并行读,oracle是绕过buffer cache进行的。
2) 在调整buffer cache时,尽量避免增加很多的内存而只是提高少量hit ratio的情况出现。
我们还可以查询每种buffer cache的统计信息,主要关注的还是consistent_gets和db_block_gets以及
physical_reads的值。
4.3 buffer cache的等待事件
与buffer cache相关的等待事件包括:latch free、buffer busy waits、free buffer waits。曾经发生过的等
待事件可以从v$system_event(一个等待事件对应一行记录)和v$session_event(一个session一个等待事件对应一行记录)中看到。而当前系统正在经历的等待事件可以从v$session_wait看到。
4.3.1 latch free等待
等待事件“latch free”中与buffer cache有关的有两类:cache buffers chains latch和cache buffers lru chain latch。在理解了上面所描述的有关buffer cache的内部管理机制以后,就应该很容易理解这两个latch产生的原因。
对于buffer cache中的每个hash chain链表来说,都会有一个名为cache buffers chains latch的latch来保护对hash chain的并发操作,这种latch通常也叫作hash latch或CBC latch。
数据库中会有很多的cache buffers chains latch,每个latch都叫做child cache buffers chains latch。一个child cache buffers chains latch会管理多个hash chain。前面我们知道,hash chain的数量由一个隐藏参数:_db_block_hash_buckets决定。同样也有一个隐藏参数:_db_block_hash_latches来决定有多少个cache buffers chains latch来管理这些hash chain。该参数的缺省值由buffer cache中所含有的内存数据块的多少决定,当内存数据块的数量
•少于2052个时,_db_block_hash_latches = power(2,trunc(log(2, 内存块数量 - 4) - 1))
•多于131075个时,_db_block_hash_latches = power(2,trunc(log(2, db_block_buffers - 4) - 6))
•位于2052与131075 buffers之间,_db_block_hash_latches = 1024
可以使用下面的SQL语句来确定当前系统的cache buffers chains latch的数量。
不够优化的SQL语句是导致cache buffers chains latch的主要原因。如果SQL语句需要访问过多的内存数据块,那么必然会持有latch很长时间。找出逻辑读特别大的sql语句进行调整。v$sqlarea里那些buffer_gets/executions为较大值的SQL语句就是那些需要调整的SQL语句。这种方式不是很有针对性,比较盲目。
网上曾经有人提供了一个比较有针对性的、查找这种引起较为严重的cache buffers chains latch的SQL语句的方式,其原理是根据latch的地址,到x$bh中找对应的buffer header,x$bh的hladdr表示该buffer header所对应的latch地址。然后根据buffer header可以找到所对应的表的名称。最后可以到v$sqltext(也可以到stats$sqltext)中找到引用了这些表的SQL语句。我也列在这里。where条件中的rownum<10主要是为了不要返回太多的行,只要能够处理掉前10个latch等待就能有很大改观。
通过前面我们已经知道,每个working set都会有一个名为cache buffers lru chain的latch(也叫做lru latch)来管理。任何要访问working set的进程都必须先获得cache buffers lru chain latch。cache buffers lru chain latch争用也是由于低效的扫描过多的内存数据块的SQL语句引起的。调整这些语句以降低逻辑读和物理读。只要修改一下上面找引起cache buffers chains latch的SQL语句即可找到这样的SQL语句。
4.3.2 buffer busy waits等待
当一个session在读取或修改buffer cache里的内存数据块时,首先必须获得cache buffers chains latch,获得以后,到hash chain上遍历直到找到需要的buffer header后。这时,该session必须在该buffer header上以share或exclusive模式(具体哪个模式由该session的操作决定)获得一个buffer lock或一个buffer pin。一旦buffer header被pin住,session就将释放cache buffers chains latch,然后可以在该buffer上进行操作了。如果无法获得buffer pin,那么该session就会等待buffer busy waits等待事件。该等待事件不会出现在session的私有PGA里。
buffer busy waits等待事件不能像latch free等待那样可以相对比较容易的进行事后跟踪。对于该等待事件,oracle提供了v$waitstat视图。v$waitstat里的记录都是buffer busy waits等待事件发生时进行更新的。也就是说,该视图体现的都是buffer busy waits等待事件的统计数据。但这只能给你提供一个大概的buffer busy waits的分布。如果要想具体的诊断该等待事件,只能当发生该等待时,到v$session_wait里去找原因,从而才能找到解决的办法。处理buffer busy wait等待事件时,首先使用下面的SQL语句找到发生等待的数据块类别以及对应的segment。
然后,根据不同的数据块类型进行相应的处理。
1) 如果数据块类型为data block,如果版本为10g之前,则可以同时参照p3列的值来共同诊断。如果p3为130意味着同时有很多session在访问同一个data block,而且该data block没有在内存里,而必须从磁盘上获取。有三种方法可以降低该事件出现的频率:
a、降低并发性。这个比较难实现。
b、找出并优化含有这些segment的SQL语句,以降低物理和逻辑读。
c、增加freelists和freelist groups。
如果没有足够的freelists,当同时对同一个表进行insert时,这就很容易引起buffer busy waits等待。如果正在等待buffer busy waits的session正在进行insert操作,那么需要检查以下那个表有多少freelists了。当然,由于freelists的不足主要会导致对于segment header的buffer busy waits等待。
如果p3为220意味着有多个session同时修改在一个block(该block已经被读入内存了)里的不同的行。这种情况通常出现在高DML并发性的环境里。有三种方法可以降低该事件出现的频率:
a、降低并发性。这个比较难实现。
b、通过增加pctfree减少block里含有的行数。
c、将该对象移到拥有较小block尺寸的表空间里(9i或以上)。
2) 如果数据块类型为data segment header(表或索引的segment header,不是undo segment header)上发生buffer busy waits等待事件,通常表明数据库里有些表或索引的段头具有频繁的活动。
进程访问segment header主要有两种原因:一是获得或修改process freelists信息;二是扩展HWM。有三种方法可以降低该事件出现的频率:
a、增加争用对象的freelists和freelist groups的数量。
b、确定pctfree和pctused之间的间隔不要太小。
c、确保next extent的尺寸不要太小。
d、9i以后,使用ASSM特性来管理block。
3) 如果数据块类型为undo segment headers的争用等待,表明数据库中的rollback segments太少,或者他们的extent size太小,导致对于同一个segment header的大量更新。如果使用了9i以后的auto undo management,则不用处理,因为oracle会根据需要自动创建新的undo segments。如果是9i之前,则可以创建新的private rollback segments,并把它们online,或者通过降低transactions_per_rollback_segment参数来减轻该等待。
4) 如果数据块类型为undo block,说明有多个session同时访问那些被更新过的block。这是应用系统的问题,在数据库来说对此无能为力。
4.3.3 buffer busy waits等待
在一个数据块被读入buffer cache之前,oracle进程必须为该数据块获得一个对应的可用的内存数
据块。当session在LRU list上无法发现一个可用的内存数据块或者搜寻可用的内存数据块被暂停的时候,该session就必须等待free buffer waits事件。
从前面的描述,我们已经知道,一个需要可用内存数据块的前台进程会连续扫描LRU 链表,直到达到一个限定值(也就是隐藏参数_db_block_max_scan_pct所指定的值,表示已经扫描的buffer header数量占整个LRU链表上的buffer header的总数量,在9i中该限定值为40%)。如果到该限定值时还没找到可用内存数据块时,该前台进程就会触发DBWR进程以便清空一些脏数据块,从而使得在辅助LRU链表上能够挂上一些可用的内存数据块。在DBWR进程工作时,该前台进程就必须等待free buffer waits。
oracle跟踪每次对于可用的内存数据块的请求次数(记录在v$sysstat里的free buffer requested),也跟踪每次请求可用的内存数据块失败的次数(记录在v$system_event里的free buffer waits的total_waits)。而v$sysstat里的free buffer inspected则说明oracle为了找到可用的内存数据块所所跳过的数据块的个数,如果buffer cache很空,有很多空的数据块的话,则该值为0。如果free buffer inspected相对free buffer requested来说很高,则说明oracle进程需要扫描更多的LRU链表上的数据块才可以找到可用的数据块。
可以看到,该系统的free buffer waits等待很少,总共等待的时间才0.476秒。同时也可以看到,请求了290532493(free buffer requested)个可用的内存数据块,但是在这个过程中只跳过了2983596(free buffer inspected)个数据块,二者相差2个数量级。说明系统很容易就找到可用的内存数据块。
如果一个session花费了很多的时间等待free buffer waits等待事件的话,通常可能有以下原因:
1) 低效率的SQL语句:对于那些引起很大逻辑读的SQL语句(v$sql里的disk_reads),那些SQL语句可能进行了全表扫描,索引全扫描、或者通过了不正确的索引扫描表等。调整这些SQL语句以降低逻辑读。
2) DBWR进程不够多:也可以通过增加DBWR checkpoints的个数来降低free buffer waits。9i下,可以通过减小fast_start_mttr_target参数来缩短MTTR,从而增加DBWR进程启动的次数。然而,这也有可能引起进程等待write complete waits事件。
3) I/O子系统太慢。
4) 延迟的块清除(block clearouts):通常发生的情形是,晚上向数据库导入了一个很大的表。然后早上运行应用系统时,会发现有有进程在等待buffer busy waits。这是因为第一个访问该表的进程将进行一个延迟的块清除,而这会导致free buffer waits等待事件。解决方法是在导入表完毕以后,执行一句全表扫描,比如通常是:select count(*) from该大表。这样在后面的进程再次访问的时候就不会产生free buffer waits等待事件了。
5) buffer cache太小:遇到free buffer waits事件,首先想到的就是增加buffer cache的大小。