程序员应该掌握的经典算法面试题
不忘初心,方得始终。何谓“初心”?初心便是在深度学习、人工智能呼风唤雨的时代,对数据和结论之间那条朴素之路的永恒探寻,是集前人之大智,真诚质朴求法向道的心中夙愿。
没有最好的分类器,只有最合适的分类器。随着神经网络模型日趋火热,深度学习大有一统江湖之势,传统机器学习算法似乎已经彻底被深度学习的光环所笼罩。然而,深度学习是数据驱动的,失去了数据,再精密的深度网络结构也是画饼充饥,无的放矢。在很多实际问题中,我们很难得到海量且带有精确标注的数据,这时深度学习也就没有大显身手的余地,反而许多传统方法可以灵活巧妙地进行处理。
本章将介绍有监督学习中的几种经典分类算法,从数学原理到实例分析,再到扩展应用,深入浅出地为读者解读分类问题历史长河中的胜败兴衰。掌握机器学习的基本模型,不仅是学好深度学习、成为优秀数据工程师的基础,更可以将很多数学模型、统计理论学以致用,探寻人工智能时代数据海洋中的规律与本源。
01 支持向量机
场景描述
支持向量机(Support Vector Machine,SVM)是众多监督学习方法中十分出色的一种,几乎所有讲述经典机器学习方法的教材都会介绍。关于SVM,流传着一个关于天使与魔鬼的故事。
传说魔鬼和天使玩了一个游戏,魔鬼在桌上放了两种颜色的球,如图3.1所示。魔鬼让天使用一根木棍将它们分开。这对天使来说,似乎太容易了。天使不假思索地一摆,便完成了任务,如图3.2所示。魔鬼又加入了更多的球。随着球的增多,似乎有的球不能再被原来的木棍正确分开,如图3.3所示。
图3.1 分球问题1
图3.2 分球问题1的简单解
图3.3 分球问题2
SVM实际上是在为天使找到木棒的最佳放置位置,使得两边的球都离分隔它们的木棒足够远,如图3.4所示。依照SVM为天使选择的木棒位置,魔鬼即使按刚才的方式继续加入新球,木棒也能很好地将两类不同的球分开,如图3.5所示。
图3.4 分球问题1的优化解
图3.5 分球问题1的优化解面对分球问题2
看到天使已经很好地解决了用木棒线性分球的问题,魔鬼又给了天使一个新的挑战,如图3.6所示。按照这种球的摆法,世界上貌似没有一根木棒可以将它们完美分开。但天使毕竟有法力,他一拍桌子,便让这些球飞到了空中,然后凭借念力抓起一张纸片,插在了两类球的中间,如图3.7所示。从魔鬼的角度看这些球,则像是被一条曲线完美的切开了,如图3.8所示。
图3.6 分球问题3
图3.7 高维空间中分球问题3的解
图3.8 魔鬼视角下分球问题3的解
后来,“无聊”的科学家们把这些球称为“数据”,把木棍称为“分类面”,找到最大间隔的木棒位置的过程称为“优化”,拍桌子让球飞到空中的念力叫“核映射”,在空中分隔球的纸片称为“分类超平面”。这便是SVM的童话故事。
在现实世界的机器学习领域,SVM涵盖了各个方面的知识,也是面试题目中常见的基础模型。本节的第1个问题考察SVM模型推导的基础知识;第2题~第4题则会侧重对核函数(Kernel Function)的理解。
知识点
SVM模型推导,核函数,SMO(Sequential Minimal Optimization)算法
问题1 在空间上线性可分的两类点,分别向SVM分类的超平面上做投影,这些点在超平面上的投影仍然是线性可分的吗?
难度:★★★☆☆
分析与解答
首先明确下题目中的概念,线性可分的两类点,即通过一个超平面可以将两类点完全分开,如图3.9所示。假设绿色的超平面(对于二维空间来说,分类超平面退化为一维直线)为SVM算法计算得出的分类面,那么两类点就被完全分开。我们想探讨的是:将这两类点向绿色平面上做投影,在分类直线上得到的黄棕两类投影点是否仍然线性可分,如图3.10所示。
图3.9 支持向量机分类面
图3.10 样本点在分类面上投影
显然一眼望去,这些点在分类超平面(绿色直线)上相互间隔,并不是线性可分的。考虑一个更简单的反例,设想二维空间中只有两个样本点,每个点各属于一类的分类任务,此时SVM的分类超平面(直线)就是两个样本点连线的中垂线,两个点在分类面(直线)上的投影会落到这条直线上的同一个点,自然不是线性可分的。
但实际上,对于任意线性可分的两组点,它们在SVM分类的超平面上的投影都是线性不可分的。这听上去有些不可思议,我们不妨从二维情况进行讨论,再推广到高维空间中。
由于SVM的分类超平面仅由支持向量决定(之后会证明这一结论),我们可以考虑一个只含支持向量SVM模型场景。使用反证法来证明。假设存在一个SVM分类超平面使所有支持向量在该超平面上的投影依然线性可分,如图3.11所示。根据简单的初等几何知识不难发现,图中AB两点连线的中垂线所组成的超平面(绿色虚线)是相较于绿色实线超平面更优的解,这与之前假设绿色实线超平面为最优的解相矛盾。考虑最优解对应的绿色虚线,两组点经过投影后,并不是线性可分的。
图3.11 更优的分类超平面
我们的证明目前还有不严谨之处,即我们假设了仅有支持向量的情况,会不会在超平面的变换过程中支持向量发生了改变,原先的非支持向量和支持向量发生了转化呢?下面我们证明SVM的分类结果仅依赖于支持向量。考虑SVM推导中的KKT条件要求
(3.1)
,
(3.2)
(3.3)
(3.4)
.
(3.5)

,
(3.6)
其中,
.
(3.7)
可以看到,除支持向量外,其他系数均为0,因此SVM的分类结果与仅使用支持向量的分类结果一致,说明SVM的分类结果仅依赖于支持向量,这也是SVM拥有极高运行效率的关键之一。于是,我们证明了对于任意线性可分的两组点,它们在SVM分类的超平面上的投影都是线性不可分的。
实际上,该问题也可以通过凸优化理论中的超平面分离定理(Separating Hyperplane Theorem,SHT)更加轻巧地解决。该定理描述的是,对于不相交的两个凸集,存在一个超平面,将两个凸集分离。对于二维的情况,两个凸集间距离最短两点连线的中垂线就是一个将它们分离的超平面。
借助这个定理,我们可以先对线性可分的这两组点求各自的凸包。不难发现,SVM求得的超平面就是两个凸包上距离最短的两点连线的中垂线,也就是SHT定理二维情况中所阐释的分类超平面。根据凸包的性质容易知道,凸包上的点要么是样本点,要么处于两个样本点的连线上。因此,两个凸包间距离最短的两个点可以分为三种情况:两边的点均为样本点,如图3.12(a)所示;两边的点均在样本点的连线上,如图3.12(b)所示;一边的点为样本点,另一边的点在样本点的连线上,如图3.12(c)所示。从几何上分析即可知道,无论哪种情况两类点的投影均是线性不可分的。
图3.12 两个凸包上距离最短的两个点对应的三种情况
至此,我们从SVM直观推导和凸优化理论两个角度揭示了题目的真相。其实,在机器学习中还有很多这样看上去显而易见,细究起来却不可思议的结论。面对每一个小问题,我们都应该从数学原理出发,细致耐心地推导,对一些看似显而易见的结论抱有一颗怀疑的心,才能不断探索,不断前进,一步步攀登机器学习的高峰。
问题2 是否存在一组参数使SVM训练误差为0?
难度:★★★☆☆

分析与解答
根据SVM的原理,我们可以将SVM的预测公式可写为
,
(3.8)

(3.9)
将任意x(j)代入式(3.9)则有
,
(3.10)
,
(3.11)
.
(3.12)
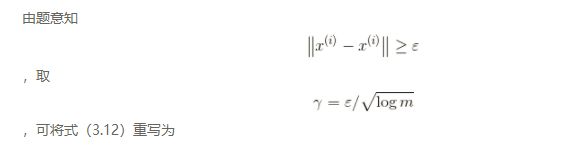
.
(3.13)

问题3 训练误差为0的SVM分类器一定存在吗?
难度:★★★★☆
虽然在问题2中我们找到了一组参数{α1,…,αm,b}以及γ使得SVM的训练误差为0,但这组参数不一定是满足SVM条件的一个解。在实际训练一个不加入松弛变量的SVM模型时,是否能保证得到的SVM分类器满足训练误差为0呢?
分析与解答
问题2找到了一组参数使得SVM分类器的训练误差为0。本问旨在找到一组参数满足训练误差为0,且是SVM模型的一个解。
问题4 加入松弛变量的SVM的训练误差可以为0吗?
难度:★★★☆☆
在实际应用中,如果使用SMO算法来训练一个加入松弛变量的线性SVM模型,并且惩罚因子C为任一未知常数,我们是否能得到训练误差为0的模型呢?
####分析与解答
使用SMO算法训练的线性分类器并不一定能得到训练误差为0的模型。这是由于我们的优化目标改变了,并不再是使训练误差最小。考虑带松弛变量的SVM模型优化的目标函数所包含的两项: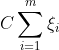 和
和![]() ,当我们的参数C选取较小的值时,后一项(正则项)将占据优化的较大比重。这样,一个带有训练误差,但是参数较小的点将成为更优的结果。一个简单的特例是,当C取0时,w也取0即可达到优化目标,但是显然此时我们的训练误差不一定能达到0。
,当我们的参数C选取较小的值时,后一项(正则项)将占据优化的较大比重。这样,一个带有训练误差,但是参数较小的点将成为更优的结果。一个简单的特例是,当C取0时,w也取0即可达到优化目标,但是显然此时我们的训练误差不一定能达到0。
{逸闻趣事}
SVM理论的创始人Vladimir Vapnik和他的牛人同事
“物以类聚,人以群分”,星光闪闪的牛人也往往扎堆出现。1995年,当统计学家Vladimir Vapnik和他的同事提出SVM理论时,他所在的贝尔实验室还聚集了一大批机器学习领域大名鼎鼎的牛人们,其中就包括被誉为“人工智能领域三驾马车”中的两位——Yann LeCun和Yoshua Bengio,还有随机梯度下降法的创始人Leon Bottou。无论是在传统的机器学习领域,还是当今如火如荼的深度学习领域,这几个人的名字都如雷贯耳。而SVM创始人Vapnik的生平也带有一丝传奇色彩。
1936年,Vladimir Vapnik出生于苏联。
1958年,他在乌兹别克大学完成硕士学业。
1964年,他于莫斯科的控制科学学院获得博士学位。毕业后,他一直在校工作到1990年。在此期间,他成了该校计算机科学与研究系的系主任。
1995年,他被伦敦大学聘为计算机与统计科学专业的教授。
1991至2001年间,他工作于AT&T贝尔实验室,并和他的同事们一起提出了支持向量机理论。他们为机器学习的许多方法奠定了理论基础。
2002年,他工作于新泽西州普林斯顿的NEC实验室,同时是哥伦比亚大学的特聘教授。
2006年,他成为美国国家工程院院士。
2014年,他加入了Facebook人工智能实验室。
02 逻辑回归
场景描述
逻辑回归(Logistic Regression)可以说是机器学习领域最基础也是最常用的模型,逻辑回归的原理推导以及扩展应用几乎是算法工程师的必备技能。医生病理诊断、银行个人信用评估、邮箱分类垃圾邮件等,无不体现逻辑回归精巧而广泛的应用。本小节将从模型与原理出发,涵盖扩展与应用,一探逻辑回归的真谛。
知识点
逻辑回归,线性回归,多标签分类,Softmax
###问题1 逻辑回归相比于线性回归,有何异同?
难度:★★☆☆☆
####分析与解答
逻辑回归,乍一听名字似乎和数学中的线性回归问题异派同源,但其本质却是大相径庭。
首先,逻辑回归处理的是分类问题,线性回归处理的是回归问题,这是两者的最本质的区别。逻辑回归中,因变量取值是一个二元分布,模型学习得出的是![]() ,即给定自变量和超参数后,得到因变量的期望,并基于此期望来处理预测分类问题。而线性回归中实际上求解的是
,即给定自变量和超参数后,得到因变量的期望,并基于此期望来处理预测分类问题。而线性回归中实际上求解的是![]() ,是对我们假设的真实关系
,是对我们假设的真实关系![]() 的一个近似,其中代表误差项,我们使用这个近似项来处理回归问题。
的一个近似,其中代表误差项,我们使用这个近似项来处理回归问题。
分类和回归是如今机器学习中两个不同的任务,而属于分类算法的逻辑回归,其命名有一定的历史原因。这个方法最早由统计学家David Cox在他1958年的论文《二元序列中的回归分析》(The regression analysis of binary sequences)中提出,当时人们对于回归与分类的定义与今天有一定区别,只是将“回归”这一名字沿用了。实际上,将逻辑回归的公式进行整理,我们可以得到![]()
 这便引出逻辑回归与线性回归最大的区别,即逻辑回归中的因变量为离散的,而线性回归中的因变量是连续的。并且在自变量x与超参数θ确定的情况下,逻辑回归可以看作广义线性模型(Generalized Linear Models)在因变量y服从二元分布时的一个特殊情况;而使用最小二乘法求解线性回归时,我们认为因变量y服从正态分布。
这便引出逻辑回归与线性回归最大的区别,即逻辑回归中的因变量为离散的,而线性回归中的因变量是连续的。并且在自变量x与超参数θ确定的情况下,逻辑回归可以看作广义线性模型(Generalized Linear Models)在因变量y服从二元分布时的一个特殊情况;而使用最小二乘法求解线性回归时,我们认为因变量y服从正态分布。
当然逻辑回归和线性回归也不乏相同之处,首先我们可以认为二者都使用了极大似然估计来对训练样本进行建模。线性回归使用最小二乘法,实际上就是在自变量x与超参数θ确定,因变量y服从正态分布的假设下,使用极大似然估计的一个化简;而逻辑回归中通过对似然函数的学习,得到最佳参数θ。另外,二者在求解超参数的过程中,都可以使用梯度下降的方法,这也是监督学习中一个常见的相似之处。
###问题2 当使用逻辑回归处理多标签的分类问题时,有哪些常见做法,分别应用于哪些场景,它们之间又有怎样的关系?
难度:★★★☆☆
分析与解答
使用哪一种办法来处理多分类的问题取决于具体问题的定义。首先,如果一个样本只对应于一个标签,我们可以假设每个样本属于不同标签的概率服从于几何分布,使用多项逻辑回归(Softmax Regression)来进行分类
, (3.15)
其中为模型的参数,而可以看作是对概率的归一化。为了方便起见,我们将这k个列向量按顺序排列形成n×k维矩阵,写作θ,表示整个参数集。一般来说,多项逻辑回归具有参数冗余的特点,即将同时加减一个向量后预测结果不变。特别地,当类别数为2时,
.
(3.16)
利用参数冗余的特点,我们将所有参数减去θ1,式(3.16)变为
,
(3.17)
其中。而整理后的式子与逻辑回归一致。因此,多项逻辑回归实际上是二分类逻辑回归在多标签分类下的一种拓展。
当存在样本可能属于多个标签的情况时,我们可以训练k个二分类的逻辑回归分类器。第i个分类器用以区分每个样本是否可以归为第i类,训练该分类器时,需要把标签重新整理为“第i类标签”与“非第i类标签”两类。通过这样的办法,我们就解决了每个样本可能拥有多个标签的情况。
03 决策树
场景描述
时间:早上八点,地点:婚介所。
“闺女,我又给你找了个合适的对象,今天要不要见一面?”
“多大?”“26岁。”
“长得帅吗?” “还可以,不算太帅。”
“工资高么?” “略高于平均水平。”
“会写代码吗?”“人家是程序员,代码写得棒着呢!”
“好,那把他联系方式发来吧,我抽空见一面。”
这便是中国特色相亲故事,故事中的女孩做决定的过程就是一个典型的决策树分类,如图3.13所示。通过年龄、长相、工资、是否会编程等属性对男生进行了两个类别的分类:见或不见。
图3.13 女孩的分类决策过程
决策树是一种自上而下,对样本数据进行树形分类的过程,由结点和有向边组成。结点分为内部结点和叶结点,其中每个内部结点表示一个特征或属性,叶结点表示类别。从顶部根结点开始,所有样本聚在一起。经过根结点的划分,样本被分到不同的子结点中。再根据子结点的特征进一步划分,直至所有样本都被归到某一个类别(即叶结点)中。
决策树作为最基础、最常见的有监督学习模型,常被用于分类问题和回归问题,在市场营销和生物医药等领域尤其受欢迎,主要因为树形结构与销售、诊断等场景下的决策过程十分相似。将决策树应用集成学习的思想可以得到随机森林、梯度提升决策树等模型,这些将在第12章中详细介绍。完全生长的决策树模型具有简单直观、解释性强的特点,值得读者认真理解,这也是为融会贯通集成学习相关内容所做的铺垫。
一般而言,决策树的生成包含了特征选择、树的构造、树的剪枝三个过程,本节将在第一个问题中对几种常用的决策树进行对比,在第二个问题中探讨决策树不同剪枝方法之间的区别与联系。
知识点
信息论,树形数据结构,优化理论
问题1 决策树有哪些常用的启发函数?
难度:★★☆☆☆
我们知道,决策树的目标是从一组样本数据中,根据不同的特征和属性,建立一棵树形的分类结构。我们既希望它能拟合训练数据,达到良好的分类效果,同时又希望控制其复杂度,使得模型具有一定的泛化能力。对于一个特定的问题,决策树的选择可能有很多种。比如,在场景描述中,如果女孩把会写代码这一属性放在根结点考虑,可能只需要很简单的一个树结构就能完成分类,如图3.14所示。
图3.14 以写代码为根节点属性的决策过程
从若干不同的决策树中选取最优的决策树是一个NP完全问题,在实际中我们通常会采用启发式学习的方法去构建一棵满足启发式条件的决策树。
常用的决策树算法有ID3、C4.5、CART,它们构建树所使用的启发式函数各是什么?除了构建准则之外,它们之间的区别与联系是什么?
分析与解答
首先,我们回顾一下这几种决策树构造时使用的准则。
■ ID3—— 最大信息增益
对于样本集合D,类别数为K,数据集D的经验熵表示为
(3.18)
其中Ck是样本集合D中属于第k类的样本子集,|Ck|表示该子集的元素个数,|D|表示样本集合的元素个数。
然后计算某个特征A对于数据集D的经验条件熵H(D|A)为
,
(3.19)
其中,Di表示D中特征A取第i个值的样本子集,Dik表示Di中属于第k类的样本子集。
于是信息增益g(D,A)可以表示为二者之差,可得
.
(3.20)
这些定义听起来有点像绕口令,不妨我们用一个例子来简单说明下计算过程。假设共有5个人追求场景中的女孩,年龄有两个属性(老,年轻),长相有三个属性(帅,一般,丑),工资有三个属性(高,中等,低),会写代码有两个属性(会,不会),最终分类结果有两类(见,不见)。我们根据女孩有监督的主观意愿可以得到表3.1。
表3.1 5个候选对象的属性以及女孩对应的主观意愿
| 年龄 | 长相 | 工资 | 写代码 | 类别 | |
|---|---|---|---|---|---|
| 小A | 老 | 帅 | 高 | 不会 | 不见 |
| 小B | 年轻 | 一般 | 中等 | 会 | 见 |
| 小C | 年轻 | 丑 | 高 | 不会 | 不见 |
| 小D | 年轻 | 一般 | 高 | 会 | 见 |
| 小L | 年轻 | 一般 | 低 | 不会 | 不见 |
在这个问题中,
,
根据式(3.19)可计算出4个分支结点的信息熵为
,
,
,
.
于是,根据式(3.20)可计算出各个特征的信息增益为
.
显然,特征“写代码”的信息增益最大,所有的样本根据此特征,可以直接被分到叶结点(即见或不见)中,完成决策树生长。当然,在实际应用中,决策树往往不能通过一个特征就完成构建,需要在经验熵非0的类别中继续生长。
■ C4.5——最大信息增益比
特征A对于数据集D的信息增益比定义为
,
(3.21)
其中
,
(3.22)
称为数据集D关于A的取值熵。针对上述问题,我们可以根据式(3.22)求出数据集关于每个特征的取值熵为
,
,
,
.
于是,根据式(3.21)可计算出各个特征的信息增益比为
信息增益比最大的仍是特征“写代码”,但通过信息增益比,特征“年龄”对应的指标上升了,而特征“长相”和特征“工资”却有所下降。
■ CART——最大基尼指数(Gini)
Gini描述的是数据的纯度,与信息熵含义类似。
(3.23)
CART在每一次迭代中选择基尼指数最小的特征及其对应的切分点进行分类。但与ID3、C4.5不同的是,CART是一颗二叉树,采用二元切割法,每一步将数据按特征A的取值切成两份,分别进入左右子树。特征A的Gini指数定义为
(3.24)
还是考虑上述的例子,应用CART分类准则,根据式(3.24)可计算出各个特征的Gini指数为
Gini(D|年龄=老)=0.4, Gini(D|年龄=年轻)=0.4,
Gini(D|长相=帅)=0.4, Gini(D|长相=丑)=0.4,
Gini(D|写代码=会)=0, Gini(D|写代码=不会)=0,
Gini(D|工资=高)=0.47, Gini(D|工资=中等)=0.3,
Gini(D|工资=低)=0.4.
在“年龄”“长相”“工资”“写代码”四个特征中,我们可以很快地发现特征“写代码”的Gini指数最小为0,因此选择特征“写代码”作为最优特征,“写代码=会”为最优切分点。按照这种切分,从根结点会直接产生两个叶结点,基尼指数降为0,完成决策树生长。
通过对比三种决策树的构造准则,以及在同一例子上的不同表现,我们不难总结三者之间的差异。
首先,ID3是采用信息增益作为评价标准,除了“会写代码”这一逆天特征外,会倾向于取值较多的特征。因为,信息增益反映的是给定条件以后不确定性减少的程度,特征取值越多就意味着确定性更高,也就是条件熵越小,信息增益越大。这在实际应用中是一个缺陷。比如,我们引入特征“DNA”,每个人的DNA都不同,如果ID3按照“DNA”特征进行划分一定是最优的(条件熵为0),但这种分类的泛化能力是非常弱的。因此,C4.5实际上是对ID3进行优化,通过引入信息增益比,一定程度上对取值比较多的特征进行惩罚,避免ID3出现过拟合的特性,提升决策树的泛化能力。
其次,从样本类型的角度,ID3只能处理离散型变量,而C4.5和CART都可以处理连续型变量。C4.5处理连续型变量时,通过对数据排序之后找到类别不同的分割线作为切分点,根据切分点把连续属性转换为布尔型,从而将连续型变量转换多个取值区间的离散型变量。而对于CART,由于其构建时每次都会对特征进行二值划分,因此可以很好地适用于连续性变量。
从应用角度,ID3和C4.5只能用于分类任务,而CART(Classification and Regression Tree,分类回归树)从名字就可以看出其不仅可以用于分类,也可以应用于回归任务(回归树使用最小平方误差准则)。
此外,从实现细节、优化过程等角度,这三种决策树还有一些不同。比如,ID3对样本特征缺失值比较敏感,而C4.5和CART可以对缺失值进行不同方式的处理;ID3和C4.5可以在每个结点上产生出多叉分支,且每个特征在层级之间不会复用,而CART每个结点只会产生两个分支,因此最后会形成一颗二叉树,且每个特征可以被重复使用;ID3和C4.5通过剪枝来权衡树的准确性与泛化能力,而CART直接利用全部数据发现所有可能的树结构进行对比。
至此,我们从构造、应用、实现等角度对比了ID3、C4.5、CART这三种经典的决策树模型。这些区别与联系总结起来容易,但在实际应用中还需要读者慢慢体会,针对不同场景灵活变通。
问题2 如何对决策树进行剪枝?
难度:★★★☆☆
一棵完全生长的决策树会面临一个很严重的问题,即过拟合。假设我们真的需要考虑DNA特征,由于每个人的DNA都不同,完全生长的决策树所对应的每个叶结点中只会包含一个样本,这就导致决策树是过拟合的。用它进行预测时,在测试集上的效果将会很差。因此我们需要对决策树进行剪枝,剪掉一些枝叶,提升模型的泛化能力。
决策树的剪枝通常有两种方法,预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。那么这两种方法是如何进行的呢?它们又各有什么优缺点?
分析与解答
预剪枝,即在生成决策树的过程中提前停止树的增长。而后剪枝,是在已生成的过拟合决策树上进行剪枝,得到简化版的剪枝决策树。
■ 预剪枝
预剪枝的核心思想是在树中结点进行扩展之前,先计算当前的划分是否能带来模型泛化能力的提升,如果不能,则不再继续生长子树。此时可能存在不同类别的样本同时存于结点中,按照多数投票的原则判断该结点所属类别。预剪枝对于何时停止决策树的生长有以下几种方法。
(1)当树到达一定深度的时候,停止树的生长。
(2)当到达当前结点的样本数量小于某个阈值的时候,停止树的生长。
(3)计算每次分裂对测试集的准确度提升,当小于某个阈值的时候,不再继续扩展。
预剪枝具有思想直接、算法简单、效率高等特点,适合解决大规模问题。但如何准确地估计何时停止树的生长(即上述方法中的深度或阈值),针对不同问题会有很大差别,需要一定经验判断。且预剪枝存在一定局限性,有欠拟合的风险,虽然当前的划分会导致测试集准确率降低,但在之后的划分中,准确率可能会有显著上升。
■ 后剪枝
后剪枝的核心思想是让算法生成一棵完全生长的决策树,然后从最底层向上计算是否剪枝。剪枝过程将子树删除,用一个叶子结点替代,该结点的类别同样按照多数投票的原则进行判断。同样地,后剪枝也可以通过在测试集上的准确率进行判断,如果剪枝过后准确率有所提升,则进行剪枝。相比于预剪枝,后剪枝方法通常可以得到泛化能力更强的决策树,但时间开销会更大。
常见的后剪枝方法包括错误率降低剪枝(Reduced Error Pruning,REP)、悲观剪枝(Pessimistic Error Pruning,PEP)、代价复杂度剪枝(Cost Complexity Pruning,CCP)、最小误差剪枝(Minimum Error Pruning,MEP)、CVP(Critical Value Pruning)、OPP(Optimal Pruning)等方法,这些剪枝方法各有利弊,关注不同的优化角度,本文选取著名的CART剪枝方法CCP进行介绍。
代价复杂剪枝主要包含以下两个步骤。
(1)从完整决策树T0开始,生成一个子树序列{T0,T1,T2,…,Tn},其中Ti+1由Ti生成,Tn为树的根结点。
(2)在子树序列中,根据真实误差选择最佳的决策树。
步骤(1)从T0开始,裁剪Ti中关于训练数据集合误差增加最小的分支以得到Ti+1。具体地,当一棵树T在结点t处剪枝时,它的误差增加可以用R(t)−R(Tt)表示,其中R(t)表示进行剪枝之后的该结点误差,R(Tt)表示未进行剪枝时子树Tt的误差。考虑到树的复杂性因素,我们用|L(Tt)|表示子树Tt的叶子结点个数,则树在结点t处剪枝后的误差增加率为
.
(3.25)
在得到Ti后,我们每步选择α最小的结点进行相应剪枝。
用一个例子简单地介绍生成子树序列的方法。假设把场景中的问题进行一定扩展,女孩需要对80个人进行见或不见的分类。假设根据某种规则,已经得到了一棵CART决策树T0,如图3.15所示。
此时共5个内部结点可供考虑,其中
{-:-},
,
,
,
.
可见α(t3)最小,因此对t3进行剪枝,得到新的子树T1,如图3.16所示。
图3.15 初始决策树T0
图3.16 对初始决策树T0的t3结点剪枝得到新的子树T1
而后继续计算所有结点对应的误差增加率,分别为α(t1)=3,α(t2)=3,α(t4)=4。因此对t1进行剪枝,得到T2,如图3.17所示。此时α(t0)=6.5,α(t2)=3,选择t2进行剪枝,得到T3。于是只剩下一个内部结点,即根结点,得到T4。
在步骤(2)中,我们需要从子树序列中选出真实误差最小的决策树。CCP给出了两种常用的方法:一种是基于独立剪枝数据集,该方法与REP类似,但由于其只能从子树序列{T0,T1,T2,…,Tn}中选择最佳决策树,而非像REP能在所有可能的子树中寻找最优解,因此性能上会有一定不足。另一种是基于k折交叉验证,将数据集分成k份,前k−1份用于生成决策树,最后一份用于选择最优的剪枝树。重复进行N次,再从这N个子树中选择最优的子树。
图3.17 对T1中t1结点剪枝得到新的子树T2
代价复杂度剪枝使用交叉验证策略时,不需要测试数据集,精度与REP差不多,但形成的树复杂度小。而从算法复杂度角度,由于生成子树序列的时间复杂度与原始决策树的非叶结点个数呈二次关系,导致算法相比REP、PEP、MEP等线性复杂度的后剪枝方法,运行时间开销更大。
剪枝过程在决策树模型中占据着极其重要的地位。有很多研究表明,剪枝比树的生成过程更为关键。对于不同划分标准生成的过拟合决策树,在经过剪枝之后都能保留最重要的属性划分,因此最终的性能差距并不大。理解剪枝方法的理论,在实际应用中根据不同的数据类型、规模,决定使用何种决策树以及对应的剪枝策略,灵活变通,找到最优选择,是本节想要传达给读者的思想。
{逸闻趣事}
奥卡姆剃刀定律(Occam’s Razor,Ockham’s Razor)
14世纪,逻辑学家、圣方济各会修士奥卡姆威廉(William of Occam)提出奥卡姆剃刀定律。这个原理最简单的描述是“如无必要,勿增实体”,即“简单有效原理”。
很多人误解了奥卡姆剃刀定律,认为简单就一定有效,但奥卡姆剃刀定律从来没有说“简单”的理论就是“正确”的理论,通常表述为“当两个假说具有完全相同的解释力和预测力时,我们以那个较为简单的假说作为讨论依据”。
奥卡姆剃刀的思想其实与机器学习消除过拟合的思想是一致的。特别是在决策树剪枝的过程中,我们正是希望在预测力不减的同时,用一个简单的模型去替代原来复杂的模型。而在ID3决策树算法提出的过程中,模型的创建者Ross Quinlan也确实参照了奥卡姆剃刀的思想。类似的思想还同样存在于神经网络的Dropout的方法中,我们降低模型复杂度,为的是提高模型的泛化能力。
严格讲,奥卡姆剃刀定律不是一个定理,而是一种思考问题的方式。我们面对任何工作的时候,如果有一个简单的方法和一个复杂的方法能够达到同样的效果,我们应该选择简单的那个。因为简单的选择是巧合的几率更小,更有可能反应事物的内在规律。
本文摘自《百面机器学习 算法工程师带你去面试》

作者:葫芦娃
- 人工智能时代不可不读机器学习面试宝典
- 全面收录100+真实算法面试题
- 互联网头部企业都在用
- 直通人工智能领域
不可不读的机器学习面试宝典!微软全球执行副总裁、美国工程院院士沈向洋,《浪潮之巅》《数学之美》作者吴军,《计算广告》作者、科大讯飞副总裁刘鹏,联袂推荐!
人工智能几起几落,最近这次人工智能浪潮起始于近10年,技术的飞跃发展,带来了应用的可能性。未来的几年,是人工智能技术全面普及化的时期,也是算法工程师稀缺的时期。