浅谈分布式任务调度框架
1、前言
上一篇文章谈了单机的定时任务解决方案,只能在单个JVM进程中使用;而我们的现在基本上是分布式场景,需要一套在分布式环境下高性能、高可用、可扩展的分布式任务调度框架;是否将之前的单机解决方案部署到分布式就可以?面临的分布式场景如何实现分布式的任务调度,如何解决单点故障问题实现高可用?接下来我们首先分析分布式任务调度框架相对单机的优势以及结合几种任务调度框架分析是如何逐步实现分布式的高可用、效率的,最后综合比较下业界比较流行的框架,在项目开发中方便选择。
2、Why 分布式任务调度框架
背景
1、单点故障
举个例子,村里只有一口井,有口井突然被污染了,村里就都没有井水喝了;分布式就是平时挖了多口井,一口井出问题照样有水喝。


之前我们说到单机的定时任务可能机器存在异常,如果没有分布式任务调度,那这个机器上所有定时任务只能等到这个机器恢复后才可以执行,这显然可用性就很低。
分布式任务调度就是在集群中多台调度、多台执行,一台调度机器或者执行机器出问题,能够立刻故障转移,不影响后续任务的执行,提高整体的可用性。
2、性能瓶颈
都知道一台机器的CPU、内存资源是有限的,像我们单机任务都直接写在业务机器上,单机任务瓶颈立现;当定时任务多,每秒执行上W个定时任务,单机是难以支撑的,而且定时任务会影响到业务系统的资源,整个系统就会非常不可靠。单机靠多线程,单机瓶颈达到后就要依靠分布式集群来水平扩展,解决资源瓶颈问题。
3、协同效率
每个定时任务调度的使用业务方都需要自己在业务系统构造一套分布式定时任务调度框架吗?这显然是低效?专业分工是必然的发展趋势,这就需要分布式的任务调度框架的出现,其他业务作为接入方,使用即可,不需要再考虑分布式调度的调度策略的高可用、异常故障恢复、控制台配置等等问题,只需要专注业务逻辑即可。
3、演进过程
什么是分布式任务调度
分布式任务调度,三个关键词:分布式、任务调度、配置中心。
分布式:平台是分布式部署的,各个节点之间可以无状态和无限的水平扩展(保证可扩展);
任务调度:涉及到任务状态管理、任务调度请求的发送与接收、具体任务的分配、任务的具体执行;(集群中哪些机器什么时候执行什么任务,所以又需要一个可以感知整个集群运行状态的配置中心)
配置中心:可以感知整个集群的状态、任务信息的注册
常见的分布式任务调度框架一般有以下5个部分
1、控制台:负责调度任务的配置、任务状态、信息展示
2、接入:将控制台的任务转化下发给调度器,并且向注册中心注册任务
3、调度器:接收接入下发的调度任务,进行任务拆分下发,在注册中心找执行器,然后把任务下发到执行器执行,同时也注册到注册中心
4、执行器:接收调度任务,并且上报状态给注册中心
5、注册中心:机器、任务状态的同步、协调
现在林林总总的框架,大部分都是在Quartz的基础上进行改进,我们先来看看经典的Quartz怎么做的?
Quartz
Quartz是OpenSymphony开源组织在任务调度领域的一个开源项目,完全基于java实现。作为一个优秀的开源框架,Quartz具有以下特点:强大的调度功能、灵活的应用方式、分布式和集群能力,另外作为spring默认的调度框架,很容易实现与Spring集成,实现灵活可配置的调度功能。
Quartz框架的核心对象
Scheduler – 核心调度器,就是任务调度、分配的控制器
Job – 任务,代表具体要执行的任务,是个接口,里面有默认方法,开发者需要实现该接口,并且业务逻辑写在默认的execute方法中
JobDetail – 任务描述,描述job的静态消息,是调度器需要的数据,跟Job区分开来,主要是为了一个Job可以在多台机器并行,每个调度器new一个Job的实现类
Trigger – 触发器,用于定义任务调度的时间规则
#对象之间的关系
这是单机Quartz最小的执行单元的关系

集群部署
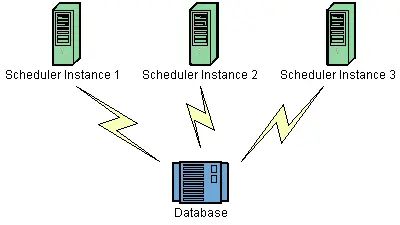
上图3个节点在数据库中都有同一份Job定义,如果某一个节点失效,那么Job会在其他节点上执行。因为每个节点上的代码都是一样的,那么如何保证只有一台机器上触发呢?答案是使用了数据库锁。在quartz集群解决方案了有张scheduler_locks,采用了悲观锁的方式对triggers表进行了行加锁,以保证任务同步的正确性。
简单来说,quartz的分布式调度策略是以数据库为边界的一种异步策略。各个调度器都遵守一个基于数据库锁的操作规则从而保证了操作的唯一性,同时多个节点的异步运行保证了服务的可靠。(实际上是用数据库锁作为分布式锁解决同步问题实现异步运行,跟redis、zk做分布式锁时是一样的)
但这种策略有自己的局限性:集群特性对于高CPU使用率的任务效果特别好,但是对于大量的短任务,各个节点都会抢占数据库锁,这样就出现大量的线程等待资源。
因此Quartz的分布式只解决了任务高可用(减少单点故障)的问题,处理能力瓶颈会在数据库,而且没有执行层面的任务分片,无法最大化效率,只能依靠shedulex调度层面做分片,但是调度层做并行分片难以结合实际的运行资源情况做最优的分片。
quartz通过数据库锁的方式来保证分布式环境下定时任务调度的同步,解决了单点故障,只引入了数据库,整体的结构简单;但是在效率上,由于数据库锁带来的竞争冲突,会使得在短任务较多时的低效,并且没有在执行时对任务分片,无法充分利用集群性能,也就是说没法真正的做到水平扩展,瓶颈被数据库锁限制住了。
Elastic-job
要解决这个分布式的水平扩展、效率问题,我们知道需要引入注册中心进行协调,这里当当退出的Elastic-job就是Quartz的基础上,引入ZK做注册中心。并且在2.0版本后出现了两个相互独立的产品线:Elastic-job-lite和Elastic-job-cloud。Elastic-job-lite定位为轻量级无中心化的解决方案,使用jar包的形式提供分布式任务的协调服务,外部依赖仅依赖于zookeeper。
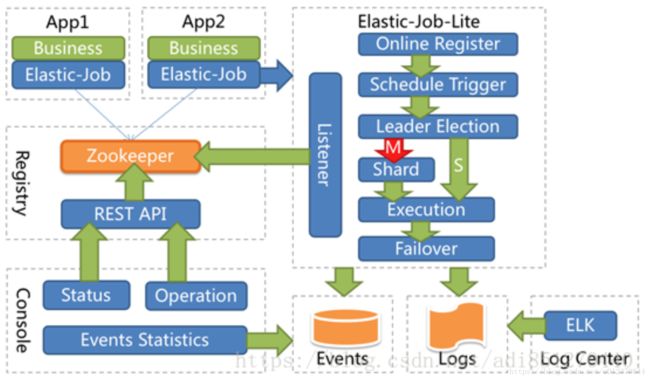
这款轻量级的架构做了很多的改进,这里只谈到两点,
1、无中心调度节点
Elastic-job-lite并无作业调度中心节点,不像我们谈到单机定时任务调度有统一的排序队列,它是基于部署作业框架的程序在到达相应时间点时各自触发调度。注册中心仅用于作业注册和监控信息存储,而主作业节点仅用于处理分片和清理的功能。
2、实现弹性扩容
通过zookeeper来动态给job节点分片。如果很大体量的用户需要我们在特定的时间段内计算完成,那么我们肯定是希望我们的任务可以通过集群达到水平的扩展,集群里的每个节点都处理部分的用户,不管用户的数量有多大,我们只需要增加机器就可以了。
举个例子:比如我们希望3台机器跑job,我么将我们的任务分成3片,框架通过zk的协调,最终会让3台机器分配到0,1,2的任务片,比如server0->0、server1->1、server2->2,当server0执行时,可以只查询id%30的用户,server1可以只查询id%31的用户,server2可以只查询id%3==2的用户。
在以上的基础上再增加一个server3,此时,server3分不到任何的分片,没有分到任务分片的程序将不执行。如果此时server2挂了,那么server2被分到的任务分片将会分配给server3,所以server3就会代替server2执行。如果此时server3也挂了,那么框架也会自动的将server3的任务分片随机分配到server0或者server1,那么就可能成:server0->0、server1->1,2。
这样就没有基于数据库的锁冲突问题,也可以实现水平扩展
不过也是有问题的
1、分片数是由业务代码层决定,调度执行协调时没法进一步优化,比较静态,机器扩容后其实没法直接用到扩容后的性能
2、缺乏统一调度,每个调度任务有重复的调度开销(检测任务trigger),并且在实现复杂的dag调度时,只能把所有业务调度写在一个实现中,不够灵活。
阿里的定时任务框架
1、早期是:TBSchedule
也是基于Zk做注册中心
优点:是支持集群、分布式,灵活的任务分片,并且有动态的服务扩容和资源回收
缺点:使用的是Timer而不是线程池执行任务调度。TBSchedule的作业类型比较单一,只能是获取/处理数据一种模式,而且目前文档偏少
####2、目前推出了基于Akka架构的Schedulerx2.0
新一代定时任务,提供分布式执行、多种任务类型、统一日志等框架,用户只要依赖schedulerx-worker这个jar包,通过schedulerx2.0提供的编程模型,简单几行代码就能实现一套高可靠可运维的分布式执行引擎。在海量数据并行任务、复杂dag调度
可扩展的执行引擎
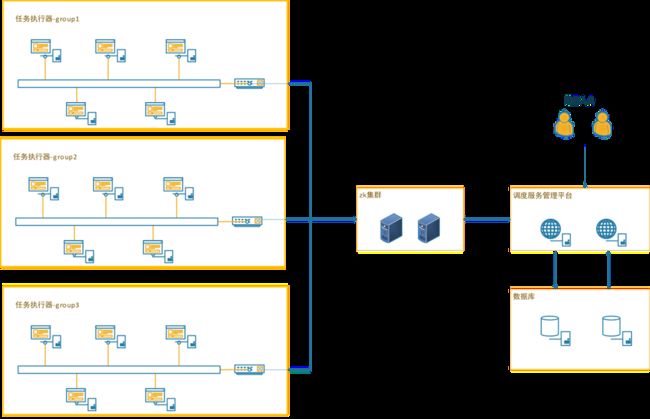
Worker总体架构参考Yarn的架构,分为TaskMaster, Container, Processor三层:
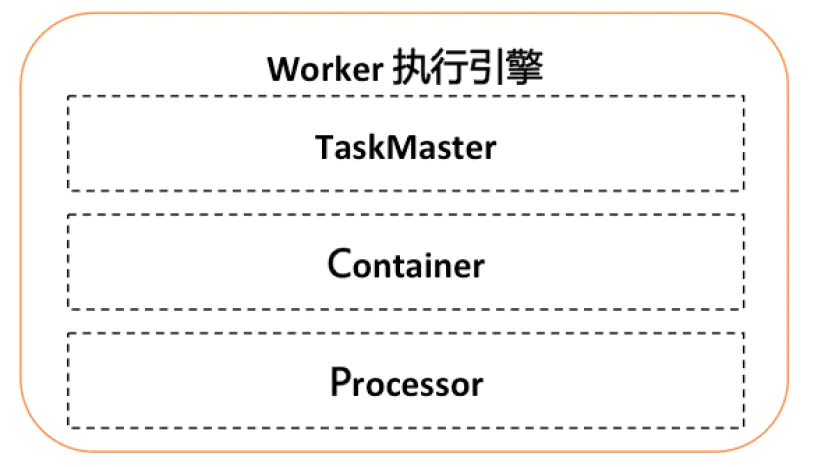
- TaskMaster:类似于yarn的AppMaster,支持可扩展的分布式执行框架,进行整个jobInstance的生命周期管理、container的资源管理,同时还有failover等能力。默认实现StandaloneTaskMaster(单机执行),BroadcastTaskMaster(广播执行),MapTaskMaster(并行计算、内存网格、网格计算),MapReduceTaskMaster(并行计算、内存网格、网格计算)。
- Container:执行业务逻辑的容器框架,支持线程/进程/docker/actor等。
- Processor:业务逻辑框架,不同的processor表示不同的任务类型。
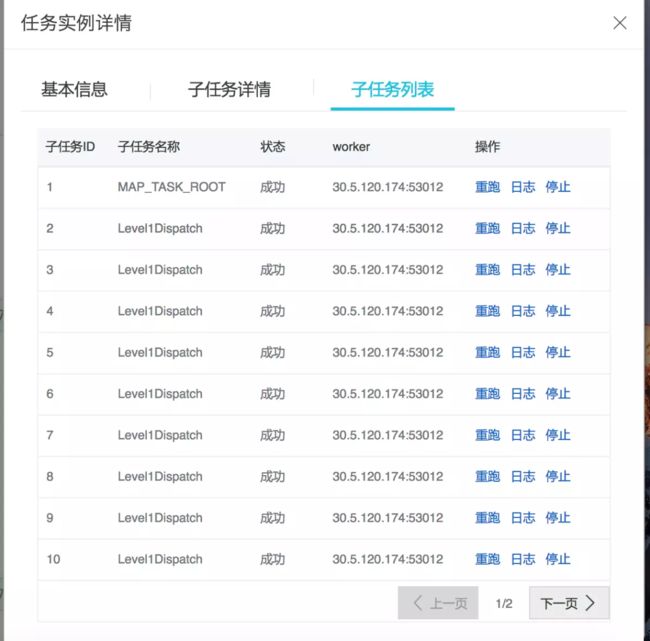
以MapTaskMaster为例,大概的原理如下图所示:
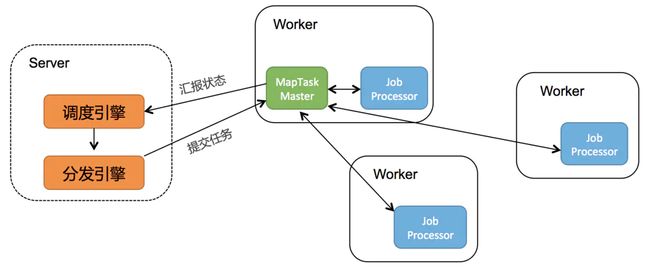
其借鉴了MapReduce的模式,支持Map、MapReduce模型,在海量数据分发多台机器的效率上非常方便,支持分布跑批,针对不同的跑批场景,map模型作业还提供了并行计算、内存网格、网格计算三种执行方式:
并行计算:子任务300以下,有子任务列表。
内存网格:子任务5W以下,无子任务列表,速度快。
网格计算:子任务100W以下,无子任务列表。
考拉的kSchedule
这里再说一个考拉的分布式定时任务框架kSchedule,大体与elastic-job类似,
这里说一点,kSchedule的无侵入性做的更好,对于简单任务不需要事先Job接口,只需要把任务bean注册成容器的Service的public方法即可,然后再配置界面配置调度任务的方法和参数即可,大大的方便的简单任务的开发和配置工作;(其实就是实现了普通类的方法级别的定时任务配置,而一般的定时任务都是类继承Job类,重写execute方法)
这点在其他框架中实现时需要写个简单任务的调度分配任务,然后把普通类的方法和入参作为动态参数传到调度分配任务,然后利用反射,进行动态执行。
4、综合比较选型
简单几条原则
1、业务起步阶段:没有自主研发运维能力,选择业界使用最多最成熟的,最好是直接买,比如阿里云的Schedulerx2.0,把技术、运维都交给阿里云,只开发业务逻辑即可;或者Elastic-job-cloud版本,在私有云上部署,功能支持也比较完善,花钱都能解决
2、业务发展阶段:数据规模和任务规模都在扩大,有一定的研发能力,可以考虑接入成熟开源框架,比如quartz或者Elastic-job-lite都是开源的,几台机器搭建起来就可以跑,出问题了开源用解答的也比较多。每秒几千个任务没问题
3、业务成熟阶段:每秒任务扩大到几万、几十万个,而且业务个性化需要越来越多,比如各种调度策略,批处理任务的个性化支持,这时候要选择一个开源框架的基础上进行二次开发,目前quartz或者Elastic-job-lite都是不错的选择
具体的对比表格
各个框架对比文档—转自:分布式调度框架大集合
5、参考文章
分布式调度框架大集合
详解应对平台高并发的分布式调度框架TBSchedule
Quartz架构整理
开源的作业调度框架Quartz
考拉定时任务框架kSchedule
Schedulerx2.0分布式计算原理&最佳实践