Hadoop之NameNode、DataNode
Namenode名字节点
对于Namenode的分析,分以下几个部分:
-
文件系统目录树管理
-
数据块和数据节点管理
-
租约管理
租约是Namenode给与租约持有者(客户端)在规定时间内拥有文件权限(写文件)的合同,Namenode会执行租约的发放、回收、检查以及恢复等操作。 -
缓存管理
2.3新增了集中式缓存管理功能,允许用户将文件和目录保存到HDFS缓存中。HDFS的集中式缓存是由分布在Datanode上的堆外内存组成的,并且由Namenode统一管理。 -
FSNamesystem
Namenode的FSNamesystem类是用于处理HDFS操作逻辑的(读 写 追加等) -
Namenode的启动和停止
在启动时会进入安全模式,在安全模式下Namenode不会接受客户端对空间的修改
Namenode的启动
这些操作都是在安全模式中进行的:
- 首先加载命名空间镜像(fsimage)并且合并编辑日志(editslog),建立Namenode的第一关系:文件系统目录树。
- 接受Datanode的块汇报(blockReport),获的数据块的存储信息,建立第二关系:数据块与副本和数据节点之间的对应关系
当Namenode收集到的阈值比例满足最低副本系数的数据块时才可以离开安全模式。
HA高可用
HDFS的高可用(High Availability, HA)方案就是为了解决Namenode的单点故障而产生的。
在HA HDFS集群中会同时运行两个Namenode
- 一个作为活动的(Active) Namenode,
- 一个作为备份的(Standby) Namenode.
备份Namenode的命名空间与活动Namenode是实时同步的,所以当活动Namenode发生故障而停止服务时,备份Namenode可以立即功换为活动状态,而不影响HDFS集群的服务。
1. HA架构
在一个HA集群中,会配置两个独立的Namenode。在任意时刻,只有一个节点会作为活动的节点,另一个节点则处于备份状态。活动的Namenode负责执行所有修改命名空间以及删除备份数据块的操作,而备份的Namenode则执行同步操作以保持与活动节点命名空间的一致性。
如图3-64所示,为了使备份节点与活动节点的状态能够同步一致,两个节点都需要与一组独立运行节点(JournalNodes, JNS)通信。当Active Namenode执行了修改命名空间的操作时,它会定期将执行的操作记录在editlog中,并写入JNS的多数节点中,而Standby Namenode会一直监听JNS上editlog的变化,如果发现editlog有改动, Standby Namenode就会读取editlog并与当前的命名空间合并。
当发生了错误切换时, Standby节点会先保证已经从JNS上读取了所有的editlog并与命名空间合并,然后才会从Standby状态切换为Active状态。通过这种机制,保证了Active Namenode与Standby Namenode之间命名空间状态的一致性,也就是第一关系链的一致性。
为了使错误切换能够很快地执行完毕,就需要保证Standby节点也保存了实时的数据块存储信息,也就是第二关系链。这样发生错误切换时, Standby节点就不需要等待所有的数据节点进行全量块汇报,而可以直接切换为Active状态。为了实现这个机制, Datanode会同时向这两个Namenode发送心跳以及块汇报信息。这样Active Nanenode和Standby Namenode的元数据就完全同步了,一旦发生故障,就可以马上切换,也就是热备。这里需要注意的是,Standby Namenode只会更新数据块的存储信息,并不会向Namenode发送复制或者删除数据块的指令,这些指令只能由Active Namenode发送。
为了防止脑裂的问题,HDFS提供了三个级别的隔离机制(fencing):
- 共享存储隔离:同一时间只允许一个Namenode向JournalNodes写入editlog数据。
- 客户端隔离:一时间只允许一个Namenode响应客户端请求。
- Datanode隔离:同一时间只允许一个Namenode向Datanode下发名字节点指令,例如删除、复制数据块指令等。
2 HA状态切换方式
- 管理员手动通过命令执行状态切换
- 自动状态切换机制触发状态切换(由ZKFailoverController控制切换流程)
3 Active Namenode和Standby Namenode之间如何共享editlog日志?
Active Namenode会将日志文件写到共享存储上,Standby Namenode会实时从共享存储读取editlog文件,然后合并到命名空间 。
- Hadoop2.6之前使用的共享存储时NAS(网络附属存储)+NFS(网络文件系统),缺点时要求有一个互斥脚本,在Namenode发生故障切换时关闭上一个活动节点
- 2.6提供了QJM(Quorum Journal Manager)方案来实现HA共享存储,这是一个基于Paxos算法实现的HA方案
4 QJM方案中有两个组件:
-
JournalNode:独立运行的服务器,保存editlog文件,向外提供读写接口;HDFS集群中有2N+1个JN节点写入,则认为写入成功。基于Paxos算法
-
QuorumJournalManagerr:运行在Namenode上,QJM通过调用QJournalProtocol中的方法向JounralNode发送请求。(并行发送日志)
5 租约管理
我们知道HDFS文件是write-once-read-many,并且不支持客户端的并行写操作,那么这里就需要一种机制保证对HDFS文件的互斥操作。HDFS提供了租约(Lease)机制来实现文件的互斥操作。
租约:是Namenode给予租约持有者(LeaseHolder,一般是客户端)在规定时间内拥有文件权限(写文件)的合同。
在HDFS中,客户端写文件时需要先从租约管理器(LeaseManager)申请一个租约,成功申请租约之后客户端就成为了租约持有者,也就拥有了对该HDFS文件的独占权限,其他客户端在该租约有效时无法打开这个HDFS文件进行操作。
Namenode的租约管理器保存了 HDFS文件与租约、租约与租约持有者的对应关系,租约管理器还会定期检查它维护的所有租约是否过期。租约管理器会强制收回过期的租约,所以租约持有者需要定期更新租约(renew),维护对该文件的独占锁定。当客户端完成了对文件的写操作,关闭文件时,必须在租约管理器中释放租约。
-
LeaseManager.Lease
我们知道一个HDFS客户端是可以同时打开多个HDFS文件进行读写操作的,为了便于管理,在租约管理器中将一个客户端打开的所有文件组织在一起构成一条记录,也就是 LeaseManager.Lease类。 -
LeaseManager类
是Namenode中维护所有租约操作的类,它不仅仅保存了HDFS中所有租约的信息,提供租约的增、删、改、查方法,同时还维护了一个Monitor线程定期检查租约是否超时,对于长时间没有更新租约的文件(超过硬限制时间),LeaseManager会触发租约恢复机制,然后关闭文件。
添加租约---addLease()
检查租约---FsNamesystem.checkLease()
租约更新---renewLease()
删除租约---removeLease()
租约检查---Monitor线程
租约恢复---Monitor线程发起
Datandoe数据节点
- Datanode以存储数据块(Block)的形式保存HDFS文件
- 同时Datanode还会响应HDFS客户端读、写数据块的请求
- Datanode会周期性地向Namenode上报
心跳信息、
数据块汇报信息(BlockReport )、
缓存数据块汇报信息(CacheReport)
增量数据块块汇报信息。
- Namenode会根据块汇报的内容,修改Namenode的命名空间(Namespace),同时向Datanode返回名字节点指令。Datanode会响应Namenode返回的名字节点指令,如创建、删除和复制数据块指令等。
HDFS联邦机制(Federation)
1.X的缺点导致引入了联邦机制
HDFSl.x架构使用一个Namenode来管理文件系统的命名空间以及数据块信息,这虽然使得HDFS的实现非常简单,但是单一的Namenode会导致以下缺点。
- 由于Namenode在内存中保存整个文件系统的元数据,所以Namenode内存的大小直接限制了文件系统的大小。
- 由于HDFS文件的读写等流程都涉及与Namenode交互,所以文件系统的吞吐量受限于单个Namenode的处理能力。
- Namenode作为文件系统的中心节点,无法做到数据的有效隔离。
- Namenode是集群中的单一故障点,有可用性隐患
- Namenode实现了数据块管理以及命名空间管理功能,造成这两个功能高度耦合,难以让其他服务单独使用数据块存储功能。
考虑到上述缺点,为了能够水平扩展Namenode,HDFS2.X引入了联邦机制,提供了Federation架构:
为了能够水平扩展Namenode,HDFS 2.X提供了Federation架构。如图4-3所示, Federation架构的HDFS集群可以定义多个Namenode/Namespace,这些Namenode之间是相互独立的, '它们各自分工管理着自己的命名空间。
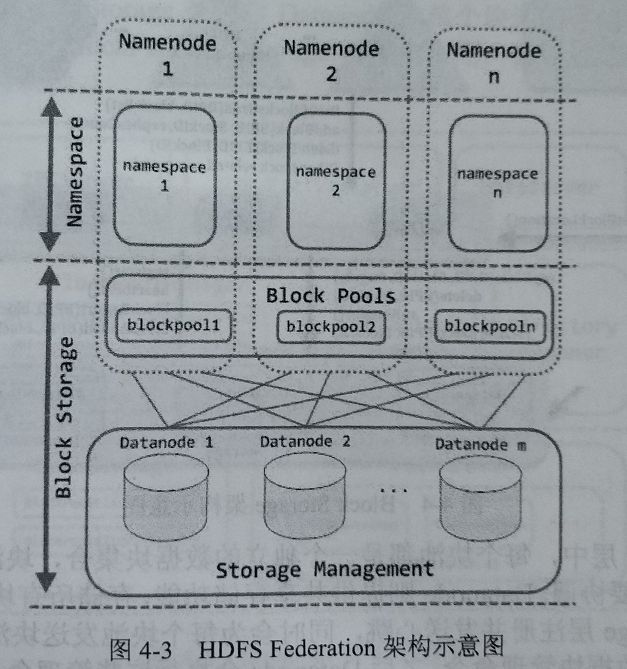
HDFS Federation架构图
HDFS Federation两个新的概念:
-
块池:BlockPool。一个块池由属于同一个命名空间的所有数据块组成,这个块池中的数据块可以存储在集群中的所有Datanode上,而每个Datanode都可以存储集群中所有块池的数据块。这里需要注意的是,每个块池都是独立管理的,不会与其他块池交互。所以一个Namenode出现故障时,并不会影响集群中的Datanode服务于其他的Namenode;
-
命名空间卷:NamespaceVolume。一个Namenode管理的命名空间以及它对应的块池一起被称为命名空间卷,当一个Namenode/Namespace被删除后,它对应的块池也会从集群的Datanode上删除。需要特别注意的是,当集群升级时,每个命名空间卷都会作为一个基本的单元进行升级
HDFS Federation架构相对于HDFS 1.X架构具有如下优点:
- 支持Namenode/Namespace的水平扩展性,同时为应用程序和用户提供了命名空间卷级别的隔离性。
- Federation架构实现起来比较简单, Namenode (包括Namespace)的实现并不需要太大的改变,只需更改Datanode的部分代码即可。例如将BlockPool作为数据块存储的一个新层次,以及更改Datanode内部的数据结构等。
后续:
可以分离Block storage层,有一下的优势:
解耦合Namespace管理以及Block Storage管理;
绕过Namenode/Namespace直接管理数据块,例如:Hbase可直接使用数据块;
可以在Block Storage上构建新文件系统(non-HDFS)