sklearn-TfidfVectorizer 计算过程详解
文章目录
- 计算公式
- 手动计算
- 代码运行
- ngram_range
计算公式
下面为 TfidfVectorizer 的计算方法,此外还有其他公式计算 tf-idf 值
t f − i d f = t f ( t , d ) ∗ i d f ( t ) tf-idf=tf(t,d)*idf(t) tf−idf=tf(t,d)∗idf(t)
t f ( t , d ) tf(t,d) tf(t,d) 表示在文本 d 中词项 t 出现的词数
i d f ( t ) = ln 1 + n d 1 + d f ( d , t ) + 1 idf(t)=\ln\frac{1+n_d}{1+df(d,t)}+1 idf(t)=ln1+df(d,t)1+nd+1
i d f ( t ) idf(t) idf(t) 中 n d n_d nd 表示训练集文本数, d f ( d , t ) df(d,t) df(d,t) 表示包含词项 t 的文档总数
手动计算
例如有四句话,每句话对应一个文本
“Chinese Beijing Chinese”,
“Chinese Chinese Shanghai”,
“Chinese Macao”,
“Tokyo Japan Chinese”
计算第一句中 Chinese 和 Beijing 的 tf-idf 值
t f ( C h i n e s e , s e n t e n c e 1 ) = 2 tf(Chinese, sentence1)=2 tf(Chinese,sentence1)=2
t f ( B e i j i n g , s e n t e n c e 1 ) = 1 tf(Beijing, sentence1)=1 tf(Beijing,sentence1)=1
i d f ( C h i n e s e ) = ln 1 + 4 1 + 4 + 1 = 1 idf(Chinese)=\ln \frac{1+4}{1+4}+1=1 idf(Chinese)=ln1+41+4+1=1
i d f ( B e i j i n g ) = ln 1 + 4 1 + 1 + 1 = 1.9 idf(Beijing)=\ln \frac{1+4}{1+1}+1=1.9 idf(Beijing)=ln1+11+4+1=1.9
对 tf 和 idf 值作乘积得到 tf-idf 值
t f − i d f ( C h i n e s e , s e n t e n c e 1 ) = t f ( C h i n e s e , s e n t e n c e 1 ) ∗ i d f ( C h i n e s e ) = 2 tf-idf(Chinese, sentence1)=tf(Chinese, sentence1)*idf(Chinese)=2 tf−idf(Chinese,sentence1)=tf(Chinese,sentence1)∗idf(Chinese)=2
t f − i d f ( B e i j i n g , s e n t e n c e 1 ) = t f ( B e i j i n g , s e n t e n c e 1 ) ∗ i d f ( B e i j i n g ) = 1.9 tf-idf(Beijing, sentence1)=tf(Beijing, sentence1)*idf(Beijing)=1.9 tf−idf(Beijing,sentence1)=tf(Beijing,sentence1)∗idf(Beijing)=1.9
代码运行
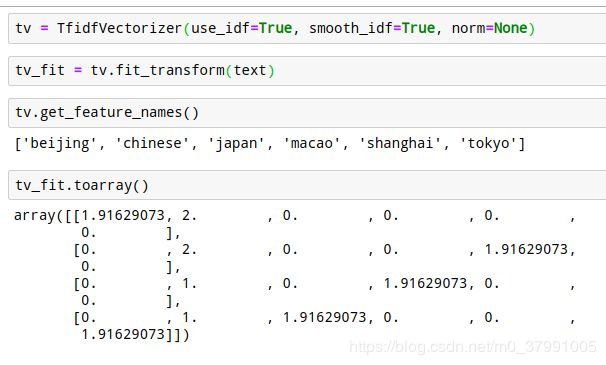
每一句话对应一个 vector,每个 vector 里面的值按照上面词语的顺序显示,可以看到 beijing 对应的是 1.9,后面是 chinese 对应 2,与手动计算相同。
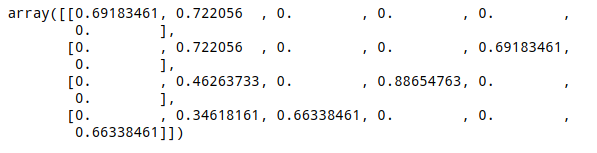
TfidfVectorizer 中 norm 项默认是 l2 正则化,按照上面的流程不修改 norm=None 时的 array 如下所示
ngram_range
TfidfVectorizer 类中有 ngram_range 参数,相当于用 TFidf 方法训练 ngram 的词向量

可见计算方法和上面一样,只是增加了 ngram 多出来的词并计算对应的词向量
参考资料
sklearn-TfidfVectorizer彻底说清楚
源码地址