python调用图灵机器人实现微信公众号的自动回复功能
刚刚创建这个公众号的时候,我的一个同事就找我的公众号聊天,但是那个时候我的公众号还是仅支持根据关键词,如果要做到支持智能回复,那基本上就是不可能。然后我结合我之前做的微信自动回复机器人的经历,我首先就想到了图灵机器人。是不是可以把图灵机器人和微信公众号进行连接呢?于是我开始查看
图灵机器人的接口文档
微信公众号
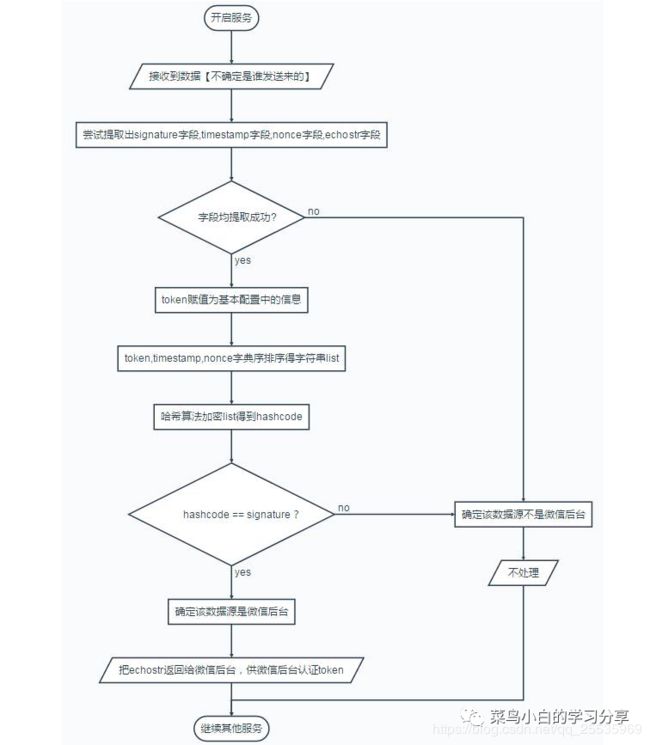
发现其实只要我们拥有一个公网的web服务器地址,微信公众号和web服务器进行通信,我们对接收的微信公众号消息进行解析转发给图灵机器人,图灵机器人根据我们请求的内容返回对应的回复,我们再将回复返回给微信公众号即可。整个流程如下:
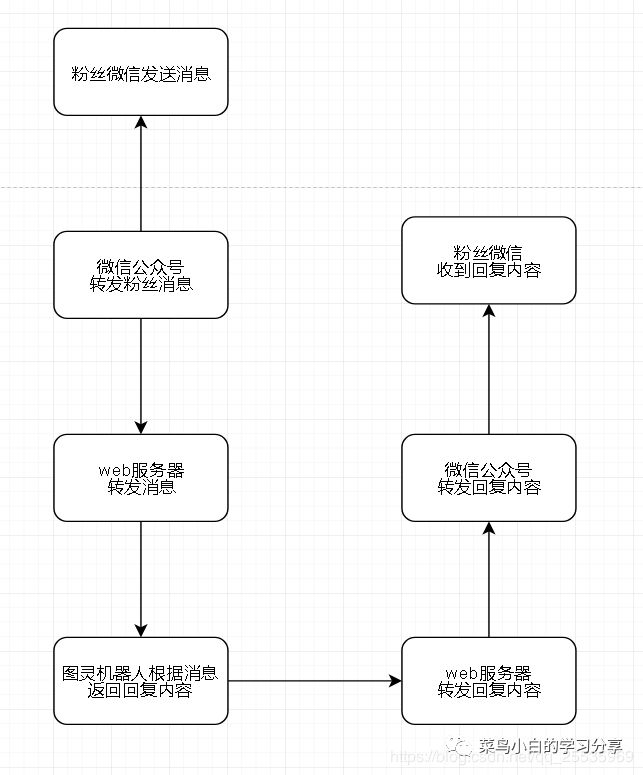
微信公众号服务器的配置
首先我们需要搭建一个web服务器用于接收微信公众号的请求,我们可以通过flask进行搭建。
在pycharm中中新建一个工程和main.py文件,输入如下内容:
from flask import Flask
from flask import request
app = Flask(__name__)
@app.route("/")
def index():
return "Hello World!"
if __name__ == "__main__":
app.run(host='0.0.0.0')
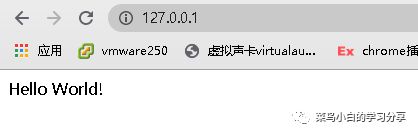
运行成功后,你可以在浏览器上访问自己的服务器
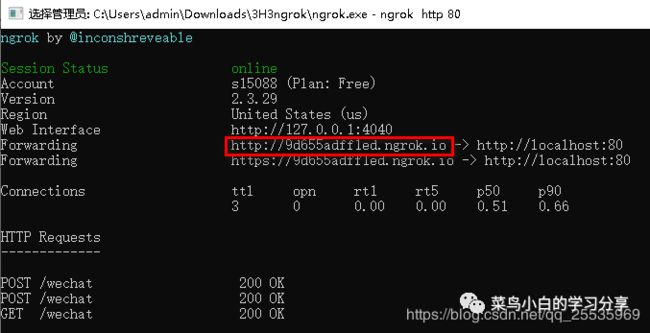
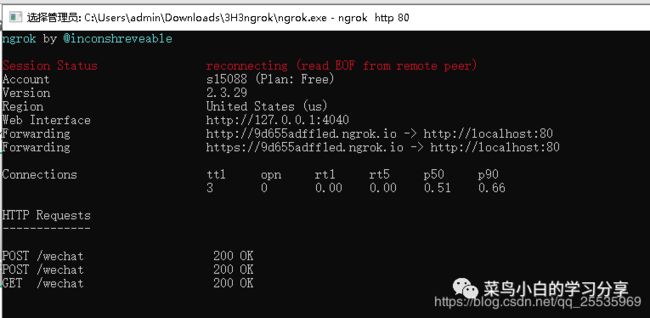
接下来我们需要将这个服务器映射到公网上获取一个公网url,我这边使用的ngrok,将下载的exe文件打开后,输入“ngrok http 80”,就出现一个公网映射地址如下图:
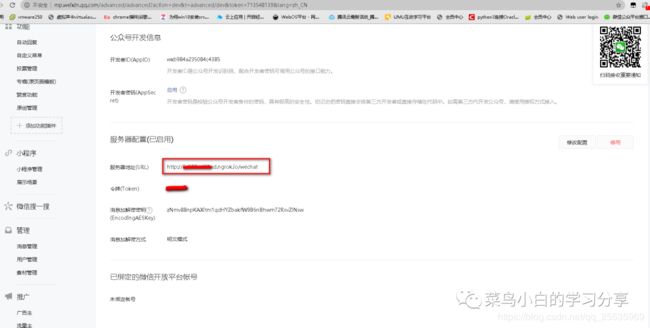
将红色框标注的地址拷贝到微信公众号的开发-基本配置-服务器配置的服务器地址(此时不要点击保存,因为我们需要对字段信息进行处理,否者是不会校验通过的)
查看微信公众号的开发手册,可以了解到信息处理流程。
# -*- coding:utf-8 -*-
from flask import Flask
from flask import request
import hashlib
app = Flask(__name__)
@app.route("/")
def index():
return "Hello World!"
@app.route("/wechat", methods=["GET","POST"])
def weixin():
if request.method == "GET": # 判断请求方式是GET请求
my_signature = request.args.get('signature') # 获取携带的signature参数
my_timestamp = request.args.get('timestamp') # 获取携带的timestamp参数
my_nonce = request.args.get('nonce') # 获取携带的nonce参数
my_echostr = request.args.get('echostr') # 获取携带的echostr参数
token = 'Your token' # 一定要跟刚刚填写的token一致
# 进行字典排序
data = [token,my_timestamp ,my_nonce ]
data.sort()
# 拼接成字符串,进行hash加密时需要为字符串类型
temp = ''.join(data)
#创建一个hash对象
s = hashlib.sha1()
#对创建的hash对象更新需要加密的字符串
s.update(data.encode("utf-8"))
#加密处理
mysignature = s.hexdigest()
# 加密后的字符串可与signature对比,标识该请求来源于微信
if my_signature == mysignature:
return my_echostr
else:
return ""
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
再次运行程序,此时再在微信公众号的配置页面点击提交可以看到提交成功的提示信息。然后再我们的ngrok上可以看到200 OK的GET连接信息
这样我们的完成了一步——服务器的配置,将微信公众号和我们搭建的web服务器进行通信。
接入图灵机器人
刚刚我们在程序中判断了一个GET的连接信息就是进行通信认证的程序,若连接信息是一个POST请求那便是我们公众号的转发信息了。接下来我们需要对这个POST信息进行处理,提取出消息内容转发给图灵机器人即可。
# -*- coding:utf-8 -*-
from flask import Flask
from flask import request
import hashlib
import tyuling_replay
import time
import re
import ReplayFromExcel
import xml.etree.ElementTree as ET
app = Flask(__name__)
@app.route("/")
def index():
return "Hello World!"
@app.route("/wechat", methods=["GET","POST"])
def weixin():
if request.method == "GET": # 判断请求方式是GET请求
my_signature = request.args.get('signature') # 获取携带的signature参数
my_timestamp = request.args.get('timestamp') # 获取携带的timestamp参数
my_nonce = request.args.get('nonce') # 获取携带的nonce参数
my_echostr = request.args.get('echostr') # 获取携带的echostr参数
# my_token = request.args.get('token')
print(my_signature)
print(my_timestamp)
print(my_nonce)
print(my_echostr)
# print(my_token)
token = '123456' # 一定要跟刚刚填写的token一致
# 进行字典排序
data = [token,my_timestamp ,my_nonce ]
data.sort()
# 拼接成字符串,进行hash加密时需为字符串
data = ''.join(data)
#创建一个hash对象
s = hashlib.sha1()
#对创建的hash对象更新需要加密的字符串
s.update(data.encode("utf-8"))
#加密处理
mysignature = s.hexdigest()
print("handle/GET func: mysignature, my_signature: ", mysignature, my_signature)
# 加密后的字符串可与signature对比,标识该请求来源于微信
if my_signature == mysignature:
return my_echostr
else:
return ""
else:
# 解析xml
xml = ET.fromstring(request.data)
toUser = xml.find('ToUserName').text
fromUser = xml.find('FromUserName').text
msgType = xml.find("MsgType").text
createTime = xml.find("CreateTime")
# 判断类型并回复
if msgType == "text":
content = xml.find('Content').text
#根据公众号粉丝的ID生成符合要求的图灵机器人userid
if len(fromUser)>31:
tuling_userid = str(fromUser[0:30])
else:
tuling_userid = str(fromUser)
tuling_userid=re.sub(r'[^A-Za-z0-9]+', '', tuling_userid)
#调用图灵机器人API返回图灵机器人返回的结果
tuling_replay_text = tyuling_replay.get_message(content,tuling_userid)
return reply_text(fromUser, toUser, tuling_replay_text)
else:
return reply_text(fromUser, toUser, "我只懂文字")
def reply_text(to_user, from_user, content):
"""
以文本类型的方式回复请求
"""
return """
{}
""".format(to_user, from_user, int(time.time() * 1000), content)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
我们将图灵机器人的调用封装在一个tyuling_replay模块中,具体内容如下:
import json
import urllib.request
tuling_key='图灵机器人的APIkey'
api_url = "http://openapi.tuling123.com/openapi/api/v2"
def get_message(message,userid):
req = {
"perception":
{
"inputText":
{
"text": message
},
"selfInfo":
{
"location":
{
"city": "",
"province": "",
"street": ""
}
}
},
"userInfo":
{
"apiKey": tuling_key,
"userId": userid
}
}
req = json.dumps(req).encode('utf8')
http_post = urllib.request.Request(api_url, data=req, headers={'content-type': 'application/json'})
response = urllib.request.urlopen(http_post)
response_str = response.read().decode('utf8')
response_dic = json.loads(response_str)
results_code = response_dic['intent']['code']
print(results_code)
if results_code == 4003:
results_text = "4003:%s"%response_dic['results'][0]['values']['text']
else:
results_text = response_dic['results'][0]['values']['text']
return results_text
详细的内容可以参考图灵机器人的API接入文档。
至此,我们的微信公众号自动回复机器人就做好了,但是免费版的图灵机器人每天的调用次数也是有限,如何彻底解决这个问题呢?我们后续再讲我们的方法。
关注微信公众号“菜鸟小白的学习分享”回复“101”获取微信公众号自动回复机器人源码哦。
关注微信公众号——菜鸟小白的学习分享
妈妈再也不用担心我找不到路了

一个人的学习——孤单
一群人的学习——幸福