faster-rcnn代码解读记录,github+tf
小小白最近对目标检测比较感兴趣,也看了许多关于rcnn相关的文章博客,大致有了一些概念,发现虽然原理好懂,但是具体如何搭建网络依旧不知所然,而网络上的代码解析也并不详细,对于我这种纯新手完全不太友好- -,所以结合在github下的一份大牛代码,研读了几天写一下大体思路,代码截图+分析,写的啰嗦一点方便日后还能看懂。
推荐先读:https://blog.csdn.net/zziahgf/article/details/79311275
github:https://github.com/endernewton/tf-faster-rcnn
首先,整个网络大体有三个部分组成,首先是公共的特征提取网络,目前在看的源码中可以选择VGG16等网络来作为特征提取网络,继而在特征提取网络的最后输出的基础上,再加一个RPN网络,RPN网络主要用于输出候选框(roi)的坐标修正量以及针对每一个候选框的可靠打分。最后是一个fast-rcnn网络,用于生成最终的目标框坐标以及目标框内的类别信息。
接下来是阅读代码后的一些解读:
锁定主要网络结构:
代码中使用network作为基类,又分别实现了vgg16等类,这些类的差别仅在于对于特征提取网络的不同选择,而整个网络结构的搭建主要在network.py的_build_network(self,is_training)函数中实现:
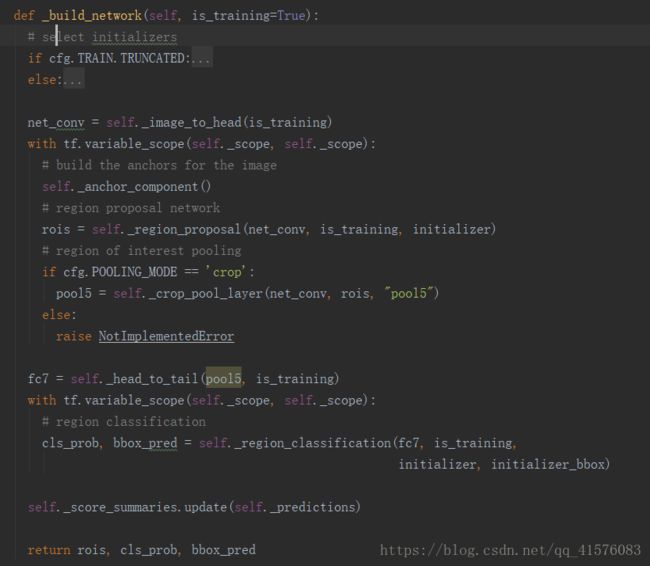
针对这个函数其实是由许多阶段性网络结构拼接而成,我们接下来逐个分析一下:
一、公共特征提取函数_image_to_head(is_training)
本函数可以理解为一个虚函数,在以不同网络结构作为基础的特征提取网络中,我是选择的vgg16网络,下面是其实现:
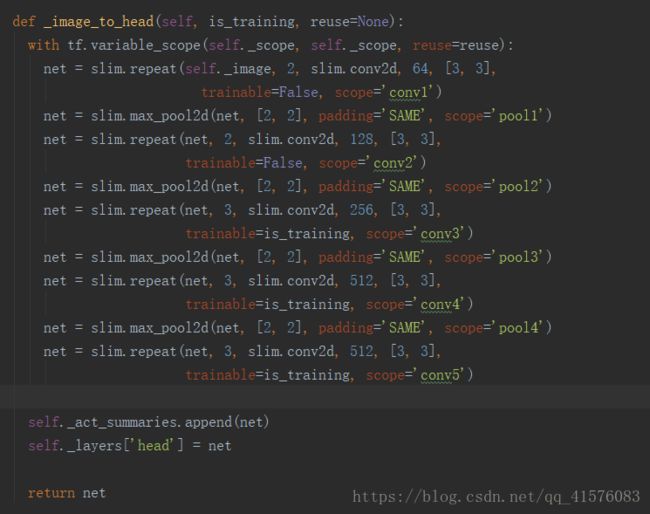
可以看到本函数输出的就是普通的一个vgg16的五层卷积后的输出特征图。
二、anchor机制以及RPN网络
对于公共特征提取网络输出结果,stride和大概为16,即输入图片尺寸与输出特征图(也可以理解为是一个图片,反正都是一个矩阵)尺寸的比,假设最后输出特征图尺寸为60X60,那么可以理解为60X60个点,每一个点都可以作为一个窗口中心点,那么窗口的尺寸呢?这就是anchor的用处,每一个anchor即对应9个(一般是9个)窗口尺寸,再将每一个窗口应用在每一个中心点上,用来截取原图像,那么一共可以截取60X60X9约3W幅图片,即60X60X(9X4)个坐标。然后针对这些窗口,网络又需要预测窗口中是否存在目标,即对于每一个窗口还要有两个概率输出,也就是一共要有60X60X(9X2)概率得分,用于甄别对应的候选框里是否存在目标,达到候选窗筛选的功能,下面贴代码逐句分析:
2.1 anchor机制
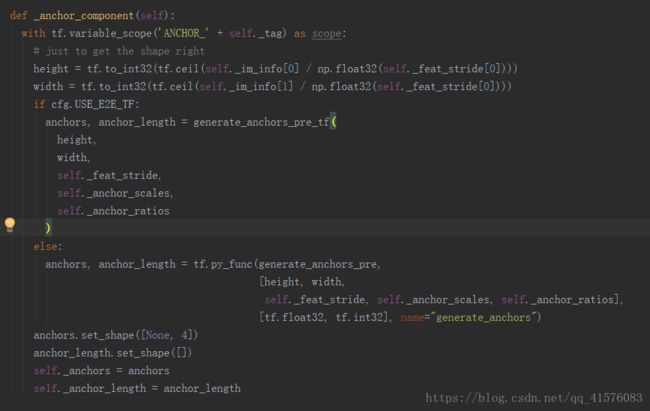
可以看到,函数一开始先利用原图尺寸以及stride数值来推算经过特征提取后输出的特征图尺寸,即上文中假设的60X60。
之后有两种情况,这也是通过配置类config的对象cfg提前设置的,不必深究,大概就是如果选择E2E(end to end端到端)的话,不将anchor的产生过程加入流图节点,下面主要看一下generate_anchors_pre函数:
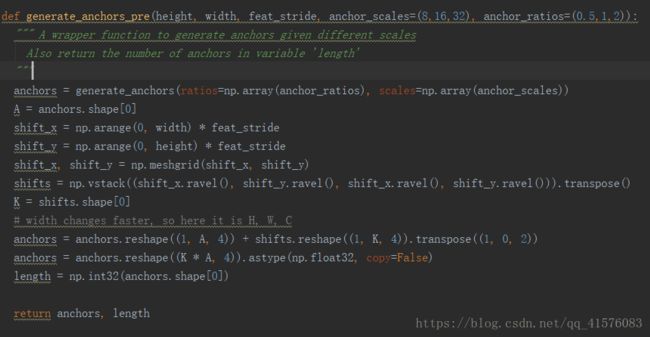
大概的分开看一下这个函数,首先是generate_anchors()函数,功能就是生成9个不同面积不同长宽比的窗口,接下来根据height和width,将9个尺寸的窗口应用于(height X width)个中心点上,生成height X width X 9 个具体的窗口,也就是height X width X (9X4)个具体的坐标,即上文中假设的60X60X(9X4)个坐标。
anchors为[H*W*9,4]张量,即针对每个中心点有九个窗口。
返回_anchor_componet()函数,将得到的候选窗坐标保存在类成员变量self._anchors中。
2.2 RPN网络
接下来,_build_network()又通过_region_proposal()函数来生成了roi区域,即该函数实现了RPN网络的功能,看一下代码:
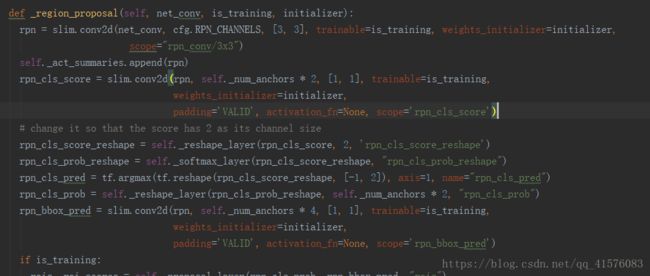
该函数比较复杂,因为RPN网络本身作为一个神经网络就需要训练,所以在得到结果的同时,必须还要根据样本构造其真值标签。而RPN网络又有两个输出支路(上文有提及的得分和坐标),所以可以将这一段程序看作两大部分,即构造网络结构,以及构造真值样本,其中又分别针对两个输出支路,故有4小部分。
现在看一下网络构造部分:
首先是一个3X3卷积,之后通过各种reshape,softmax得到rpn_cls_prob这个张量,尺寸为[-1,W, H, 9*2],即之前假设的对于每一张图的60X60X(9X2)个得分,以及rpn_bbox_pred,[-1, W, H, 9*4],为候选框roi的修正量,结合之前得到的self._anchors即可得候选框坐标。
再来关注一下后续的处理:
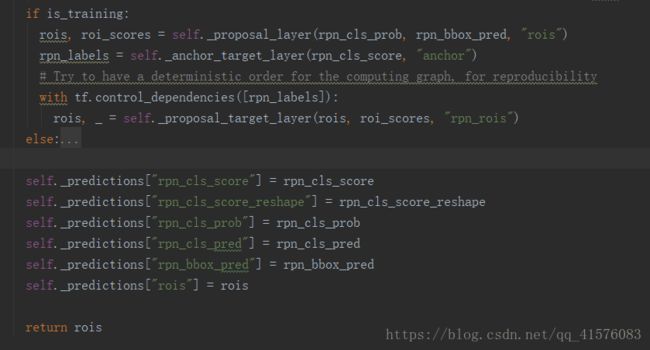
可以看到主要是三个函数:_proposal_layer, _anchor_target_layer, _proposal_target_layer,下面分开看一下这三个函数:
2.2.1 _proposal_layer
其实是调用了layer_utils.proposal_layer.py中的proposal_layer()函数,接下来再解剖一下该函数,首先提取一下得分与窗口坐标:

这里num_anchors=9,那么这个scores是什么意思呢,前面说到rpn_cls_prob是[-1,W, H, 9*2]的得分张量,即针对每个中心点的九个不同窗口的不含目标分数和含目标分数(也可以按含目标概率来理解),那么只取后9个的话,就是scores为[-1,W, H, 9]的张量,代表每一个中心点的每一个窗口含目标的分数,之后reshape成[W*H, 1]的分数列(此处假设对一张图片进行处理)。
同理,将之前所得的self._anchors通过bbox_transform_inv函数与RPN输出rpn_bbox_pred进行结合,得到各个窗口坐标,并reshape成[W*H, 4]的样子,顺序与scores对应。
那么这一共约3W个窗口,都是作为候选框,如果都拿去给后续的网络作为roi进行处理,势必过于浪费资源,所以要进行一定的筛选:
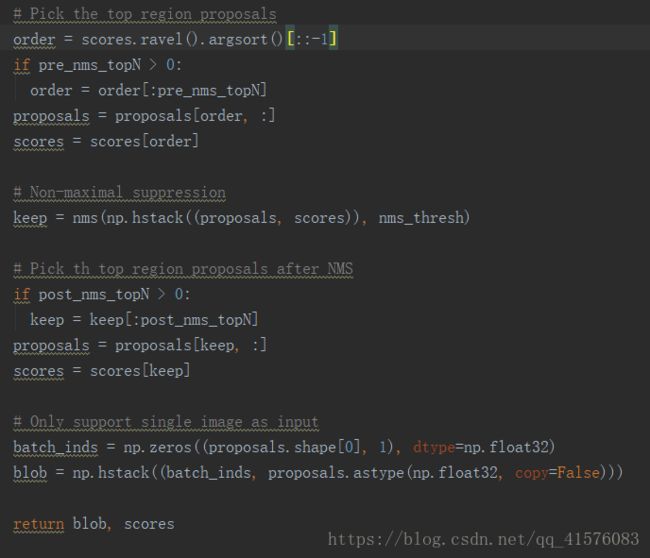
按照代码段落,分为四块:
1. 根据得分高低,取前pre_nms_topN个窗口
2. 非极大值抑制
3. 再选取前post_nms_topN个窗口
4. 将每个窗口的信息由4维(坐标)扩至5维
输出筛选后的窗口以及其得分
2.2.2 _anchor_target_layer

函数猛一看挺多,其实就是调用了layer_utils.anchor_target_layer.py里的函数,然后处理一下尺寸储存在_anchor_targets里面,字面含义,候选窗学习目标。
看一下anchor_target_layer(),函数很长,分开来看:
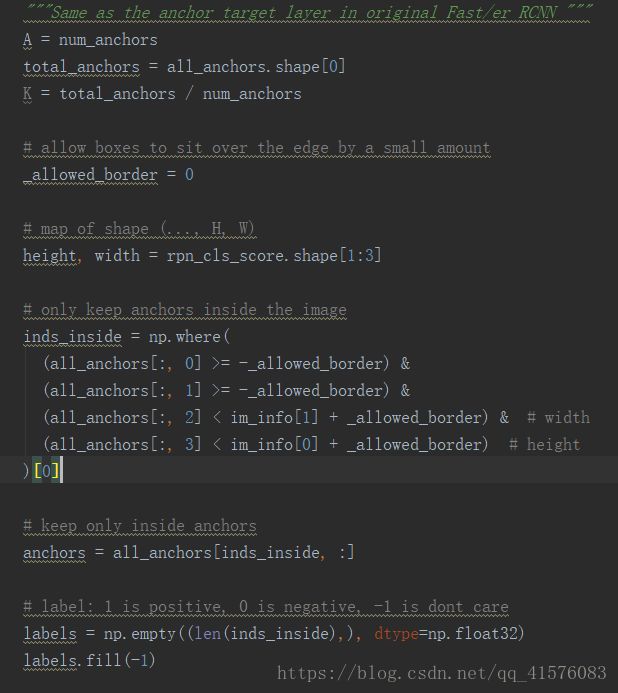
大体思想,将超出原图像尺寸范围的候选窗直接pass掉,保留剩下的窗口,并且创了一个label,用于存放相应窗口的ground truth。
继续看下一部分

overlaps为IOU矩阵,即overlaps[i][j]为第i个窗口与第j个真值窗口的IOU系数。
max_overlaps为针对每一个窗口,其与所有真值窗口中IOU最大的值,argmax_overlaps为其索引,这也是应用于后继判断label的依据
gt_argmax_overlaps为针对每一个窗口,完全被包含于某真值窗口,且IOU为真值窗口与所有窗口的最大值,满足该条件的窗口索引
有了这两组数据,就可以根据IOU对当前的窗口进行标定:
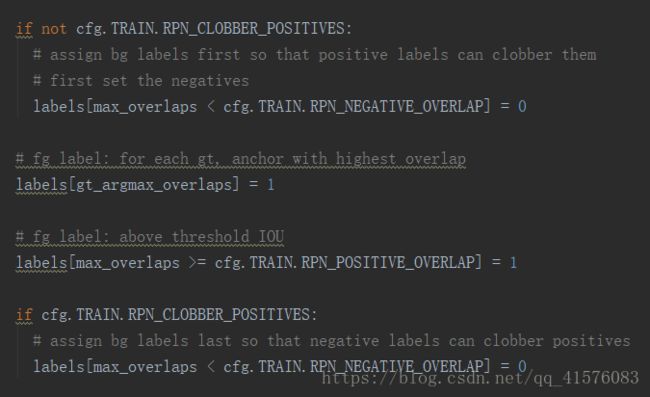
这里要提一下标注的原则:
1、对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
2、对剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本
3、如果其与任意一个标定的重叠比例都小于0.3,记为背景样本
这一段在代码上的实现也很简单,一目了然。
那么经过这样的处理,labels就是包含如下内容:
1、 对于废弃的窗口,其对应的label为-1
2、 对于认为是目标的窗口,其对应的label为1
3、 对于认为是背景的窗口,其对应的label为0
这样就可以根据这个labels作为ground truth来使用交叉熵训练RPN网络中的得分支路(就是rpn_cls_prob)
接下就要根据样本中的真值窗口搞出来对RPN网络中的窗口回归训练真值:

bbox_targets,以及后续的outside,inside权重,用于构建训练窗口回归的loss函数
_compute_targets函数正常是调用model.bbox_transform.py中的bbox_transform函数:
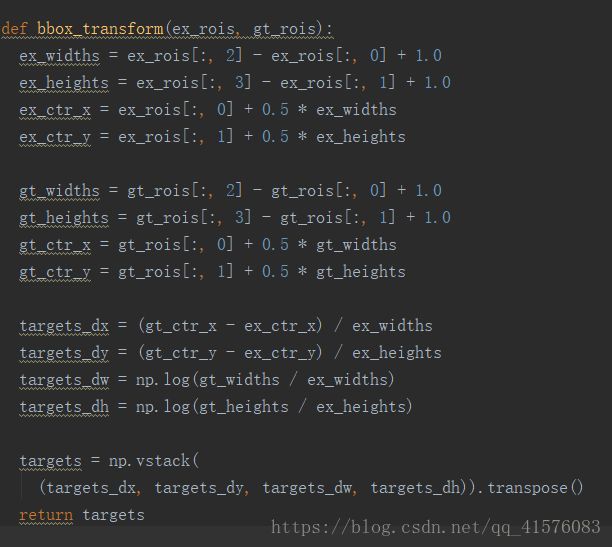
很简单的返回了每一个预测窗口与其对应iou最大的真实窗口的尺寸差别尺度。
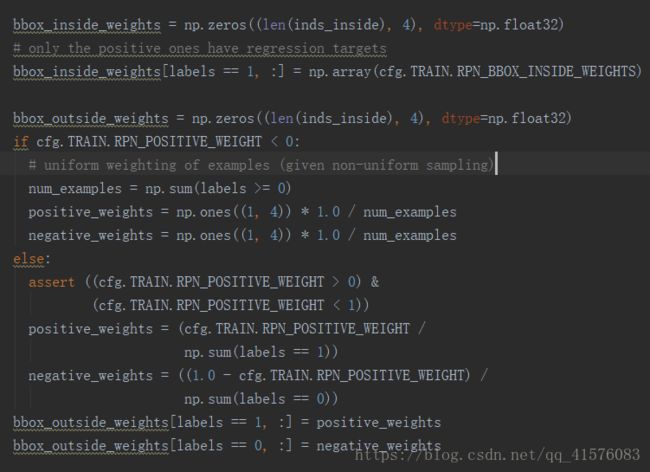
至于后续的bbox_outside_weights以及bbox_inside_weights就是简单的针对前后景样本的权值。
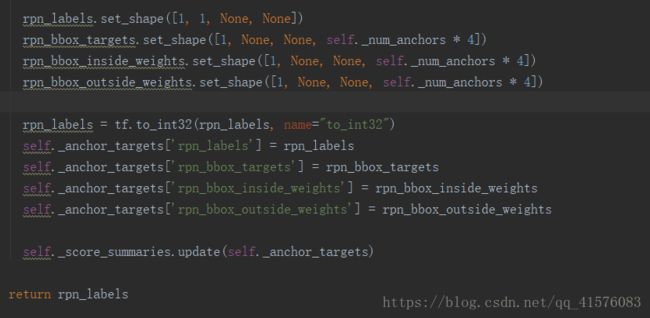
至此anchors_target_layer就结束了,分别得到rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights, 储存在self._anchor_targets中,分别应用于后续构造RPN的分类和回归loss。
2.2.3 _proposal_target_layer
这一个layer用于创建训练后续fast-RCNN的真值标签以及回归目标:
函数内部先调用layer_utils.proposal_target_layer.py中的proposal_target_layer函数来构造target:
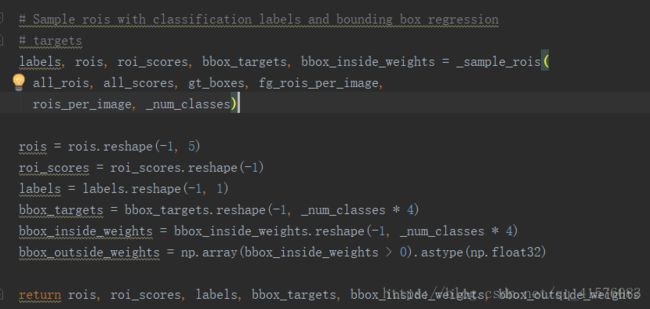
调用_sample_rois构造标签与回归框修正:
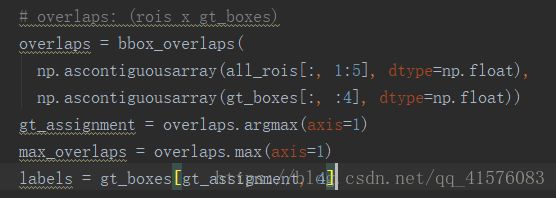
初步将labels定义为每个预测窗口对应IOU最大的真值窗口的标签
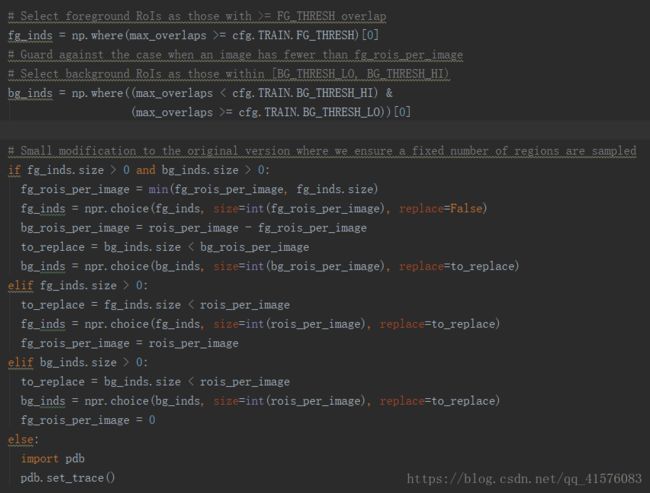
进一步筛选,根据前景阈值,背景阈值将所有预测窗口分为前景窗口,背景窗口以及无效窗口,并将索引保存在fg_roi_per_image, bg_roi_per_image。
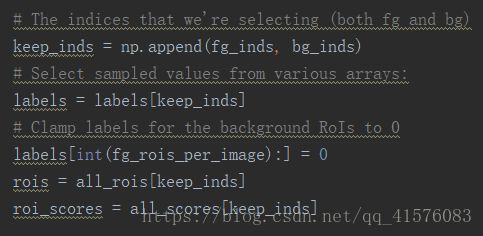
进一步,抛弃无效窗口,只保存有效窗口的roi,labels,roi_scores,其中labels设置为前景为样本真值标签,背景为0,这也符合原论文中,将背景单作为一类用于分类的想法。
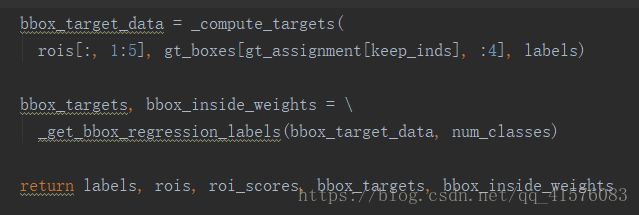
通过两个函数得到bbox_targets以及bbox_inside_weights,与anchors基本一致的方法。
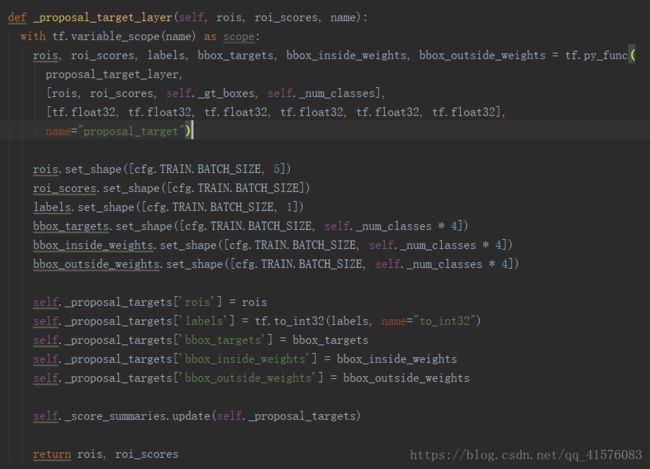
至此,最终fast-rcnn的预测标签以及回归框修正就已经构造完成,将其保存在self._proposal_targets里面,用于后续loss定义。
这样整个RPN网络就构造完成了,除了RPN网络外,在训练时还额外加了两个真值生成层(anchors_target_layer, proposal_target_layer)以及roi筛选层proposal_layer。
三、 fast-RCNN
在分析这部分代码之前,先简要提一下rcnn,rcnn完成目标检测的流程大概分为两部分,先是使用selective search来选出候选窗,按候选窗尺寸在原图截出候选区域,将其输入cnn网络提取特征后,再通过svm挨个区域进行分类,最后将属于同一类的窗口进行回归,得到最终窗口完成了目标检测。
而fast-rcnn有什么改变呢,首先来看rcnn的弊端,最大的弊端,是对于每个候选区域都要挨个过一遍cnn来提取特征,而fast-rcnn是这样做的:将整个图输入cnn得到一个完整的特征图,然后将每个候选区域尺寸通过映射关系找到对应的特征图区域,再送去分类,这样的好处就是只要过一遍cnn。
这样我们就能很轻易的看懂接下来的代码:

这是在build_network中的部分函数,其中可以看到rois就是我们通过上文的RPN网络筛选出的一些候选区域,_crop_pool_layer就是将这些候选区域映射至5层卷积后的特征图上,并截取相应区域,完成池化后输出第五层池化结果pool5。
之后再将pool5输入后继全连接网络_head_to_tail,该函数也是个虚函数,具体的定义要根据选择的基础网络而定,本次选择vgg16,故可以在vgg16.py中看到此函数定义,简单的讲就是两层全连接层,输出结果fc7。
网络搭建到这一步,就只剩下根据fc7完成最后的目标分类和目标框分类:
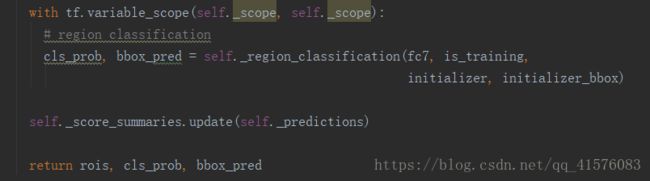
可以看到,终于是最后一步了,cls_prob和bbox_pred就是我们这整个网络的输出,关注一下_region_classification函数:
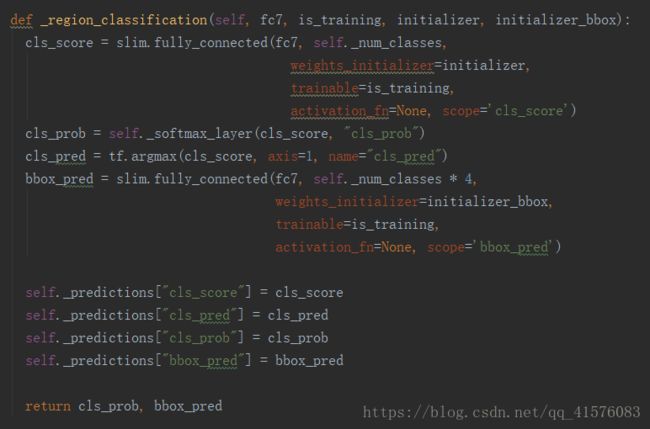
可以看到,十分简单的网络结构,一个全连接+softmax来分类,一个全连接来回归边框,将结果储存在self._predictions中,完成。
四、 loss组装
源码中loss的定义位于network.py中的_add_losses函数中
由于整个大的网络是由三个网络拼接的,最前面的vgg16只是提取特征,而RPN以及fast-RCNN均有预测输出,所以整个loss由4个部分组成:
4.1 RPN分类loss
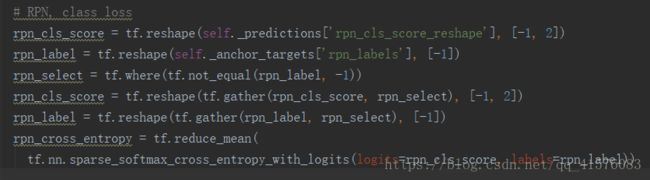
这里有一点需要注意,首先是rpn_label中,在上文中也有提及,我们将无效窗口的label置为了-1,所以在这里计算误差的时候,忽视这部分label,选择不为-1的label以及对应的score,计算softmax交叉熵,作为分类loss。
4.2 RPN候选窗回归loss
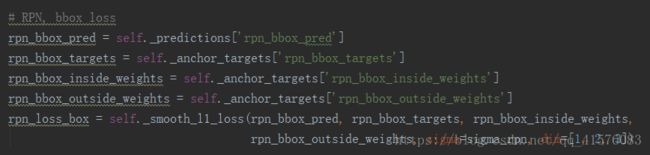
简单的讲,就是计算了l1误差
4.3 fast-RCNN分类loss

因为这了已经在proposal_target_layer中抛弃了无效标签以及相应的roi,所以直接softmax交叉熵。
4.4 fast-RCNN窗口回归loss

这里也没什么奇特的,就是一个l1误差。
这样,整个网络就搭建完成了,优化loss或者预测等均可以通过常规操作来进行,源码上写的较为复杂,就没有研究。
这里需要注意一下一共有3个placehold:
self._image, [1,None,None,3] , 输入图片
self._im_info, [3] , 图片长,宽,色道
self._image, [None,5] , 输入图片的真值标签,真值目标框坐标(4个)
详情见create_architecture函数,位于network.py