ElasticSearch+Django打造个人爬虫搜索引擎
ElasticSearch+Django打造个人爬虫搜索引擎
学习至慕课课程
利用ElasticSearch数据库,Python的Django框架,配合scrapy爬虫,打造属于自己的搜索引擎。
Windows10本地运行都OK,docker服务器环境配置到一半发现Java运行内存不够了。。留下了贫穷的泪水。。
环境配置
Java和nodejs以及redis安装
安装教程很多,动动手百度一下就有,其中Java要求1.8以上版本。
Elasticsearch-RTF安装
链接:https://github.com/medcl/elasticsearch-rtf:
说明:
什么是Elasticsearch-RTF? RTF是Ready To Fly的缩写,在航模里面,表示无需自己组装零件即可直接上手即飞的航空模型,Elasticsearch-RTF是针对中文的一个发行版,即使用最新稳定的elasticsearch版本,并且帮你下载测试好对应的插件,如中文分词插件等,目的是让你可以下载下来就可以直接的使用(虽然es已经很简单了,但是很多新手还是需要去花时间去找配置,中间的过程其实很痛苦),当然等你对这些都熟悉了之后,你完全可以自己去diy了,跟linux的众多发行版是一个意思。
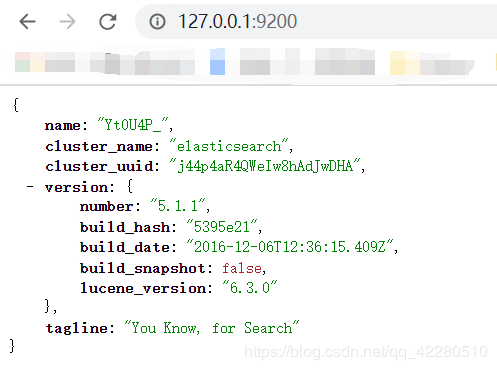
当前版本 Elasticsearch 5.1.1
Windows下启动
cd elasticsearch/bin
elasticsearch.bat
浏览器打开127.0.0.1:9200
elasticsearch-head安装
链接:https://github.com/mobz/elasticsearch-head
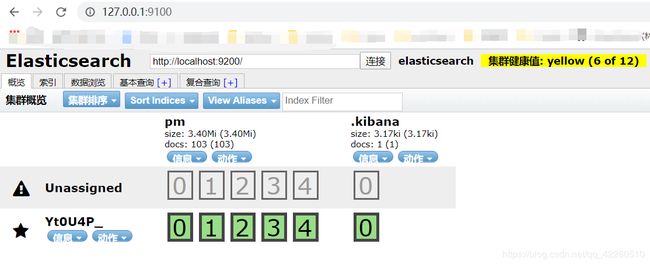
说明:elasticsearch集群的web前端
Windows下运行:
cd elasticsearch-head
npm install
npm run start
浏览器打开127.0.0.1:9100
Kibana安装
链接:https://www.elastic.co/cn/downloads/past-releases#kibana
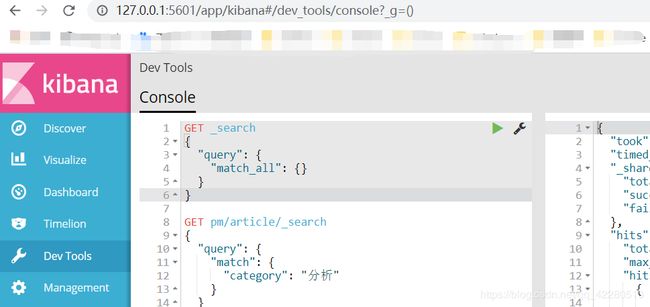
说明:Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。
下载版本:5.1.2(对应elasticsearch版本)
Windows下运行:
cd kibana-5.1.2-windows-x86\bin
kibana.bat
浏览器打开127.0.0.1:5601
scrapy爬虫
需安装相关库:
pip install elasticsearch-dsl
主要model代码,用来创建elasticsearch数据的index和type:
# -*- coding: utf-8 -*-
from elasticsearch_dsl import DocType, Date, Completion, Keyword, Text, Integer
from elasticsearch_dsl.analysis import CustomAnalyzer as _CustomAnalyzer
from elasticsearch_dsl.connections import connections
connections.create_connection(hosts=["localhost"])
class CustomAnalyzer(_CustomAnalyzer):
# 版本问题,需要重新继承CustomAnalyzer,重写get_analysis_definition方法
def get_analysis_definition(self):
return {}
ik_analyzer = CustomAnalyzer("ik_max_word", filter=["lowercase"])
class ArticleType(DocType):
"""
# elasticsearch_dsl安装5.4版本
"""
# 文章类型
suggest = Completion(analyzer=ik_analyzer)
title = Text(analyzer="ik_max_word")
create_date = Date()
url = Keyword()
view = Integer()
tag = Text(analyzer="ik_max_word")
content = Text(analyzer="ik_max_word")
url_id = Keyword()
class Meta:
index = "pm" # 数据库名
doc_type = "article" # 表名
if __name__ == "__main__":
data = ArticleType.init()
print(data)
item数据处理主要代码:
import redis
import scrapy
from articles.model.es_types import ArticleType
from elasticsearch_dsl.connections import connections
es = connections.create_connection(ArticleType._doc_type.using)
redis_cli = redis.StrictRedis()
def gen_suggests(index, info_tuple):
# 根据字符串生成搜索建议数组
used_words = set()
suggests = []
for text, weight in info_tuple:
if text:
# 调用es的analyze接口分析字符串
words = es.indices.analyze(index=index, analyzer="ik_max_word", params={'filter': ["lowercase"]}, body=text)
anylyzed_words = set([r["token"] for r in words["tokens"] if len(r["token"]) > 1])
new_words = anylyzed_words - used_words
else:
new_words = set()
if new_words:
suggests.append({"input": list(new_words), "weight": weight})
return suggests
class PmArticlesItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
content = scrapy.Field()
view = scrapy.Field()
tag = scrapy.Field()
url_id = scrapy.Field()
def save_to_es(self):
article = ArticleType()
article.title = self['title']
article.create_date = self["create_date"]
article.content = self["content"]
article.url = self["url"]
article.view = self["view"]
article.tag = self["tag"]
article.meta.id = self["url_id"]
article.suggest = gen_suggests(ArticleType._doc_type.index, ((article.title, 10), (article.tag, 7)))
article.save()
redis_cli.incr("pm_count") # redis存储爬虫数量
return
Pipeline存储主要代码:
class ElasticsearchPipeline(object):
# 将数据写入到es中
def process_item(self, item, spider):
# 将item转换为es的数据
item.save_to_es()
return item
Django:
class SearchView(View):
"""
搜索视图,根据搜索词q和类型s_type返回搜索结果
"""
def get(self, request):
key_words = request.GET.get("q", "")
s_type = request.GET.get("s_type", "article")
# TODO
# 根据类型不同,动态取对应的数据库内容
# 热门搜索设置和排序
redis_cli.zincrby("search_keywords_set", 1, key_words) # redis最新版本参数坑
topn_search = redis_cli.zrevrangebyscore("search_keywords_set", "+inf", "-inf", start=0, num=5)
page = request.GET.get("p", "1")
try:
page = int(page)
except:
page = 1
pm_count = redis_cli.get("pm_count") # 获取爬虫数量
start_time = datetime.now()
response = client.search(
index="pm",
body={
"query": {
"multi_match": {
"query": key_words,
"fields": ["tag", "title", "content"]
}
},
"from": (page-1)*10,
"size": 10,
"highlight": {
"pre_tags": [''],
"post_tags": [''],
"fields": {
"title": {},
"content": {},
}
}
}
)
end_time = datetime.now()
last_seconds = (end_time-start_time).total_seconds() # 搜索计时
total_nums = response["hits"]["total"]
if (page % 10) > 0:
page_nums = int(total_nums/10) + 1
else:
page_nums = int(total_nums/10)
hit_list = []
for hit in response["hits"]["hits"]:
hit_dict = {}
if "title" in hit["highlight"]:
hit_dict["title"] = "".join(hit["highlight"]["title"])
else:
hit_dict["title"] = hit["_source"]["title"]
if "content" in hit["highlight"]:
hit_dict["content"] = "".join(hit["highlight"]["content"])[:500] # 取前五百个词
else:
hit_dict["content"] = hit["_source"]["content"][:500]
hit_dict["create_date"] = hit["_source"]["create_date"]
hit_dict["url"] = hit["_source"]["url"]
hit_dict["score"] = hit["_score"]
hit_list.append(hit_dict)
return render(request, "result.html", {"page": page,
"all_hits": hit_list,
"key_words": key_words,
"total_nums": total_nums,
"page_nums": page_nums,
"last_seconds": last_seconds,
"pm_count": pm_count,
"topn_search": topn_search})


GitHub:https://github.com/downdawn/eswork