非参数统计之局部多项式回归
局部多项式回归
局部多项式回归是非参数回归的一种方法,主要是由于 N a d a r a y a − W a t s o n Nadaraya-Watson Nadaraya−Watson估计方法的加权是基于整个样本点,而且往往在边界上的估计效果并不理想。
局部线性回归
解决上述问题的办法就是用一个变动的函数取代局部固定的权重。局部线性回归就是在待估计点 x x x的领域内用一个线性函数 Y i = β 0 + β 1 X i Y_i=\beta_0+\beta_1X_i Yi=β0+β1Xi, X i ∈ [ x − h , x + h ] X_i\in[x-h,x+h] Xi∈[x−h,x+h]来取代 Y i Y_i Yi的平均, β 0 , β 1 \beta_0,\beta_1 β0,β1是局部参数,首先回顾一下Nadaraya-Watson估计:
m ^ h = n − 1 ∑ i = 1 n K h ( x − X i ) Y i n − 1 ∑ j = 1 n K h ( x − X j ) = 1 n ∑ i = 1 n ( K h ( x − X i ) n − 1 ∑ j = 1 n K h ( x − X j ) ) Y i = 1 n ∑ i = 1 n W h i ( x ) Y i \begin{aligned} \hat{m}_h &= \frac{n^{-1}\sum_{i=1}^nK_h(x-X_i)Y_i}{n^{-1}\sum_{j=1}^nK_h(x-X_j)}\\ &=\frac{1}{n}\sum_{i=1}^n \left( \frac{K_h(x-X_i)}{n^{-1}\sum_{j=1}^nK_h(x-X_j)}\right)Y_i \\ &=\frac{1}{n}\sum_{i=1}^nW_{hi}(x)Y_i \end{aligned} m^h=n−1∑j=1nKh(x−Xj)n−1∑i=1nKh(x−Xi)Yi=n1i=1∑n(n−1∑j=1nKh(x−Xj)Kh(x−Xi))Yi=n1i=1∑nWhi(x)Yi
其中 K h ( x − X i ) = 1 h K ( x − X i h ) K_h(x-X_i)=\frac{1}{h}K\left( \frac{x-X_i}{h} \right) Kh(x−Xi)=h1K(hx−Xi).接下来我们考虑一个估计量 a ≡ m h ^ ( x ) a\equiv \hat{m_h}(x) a≡mh^(x)来使得目标函数(误差平方和) 1 2 ∑ i = 1 n ( Y i − a ) 2 \frac{1}{2}\sum_{i=1}^n(Y_i-a)^2 21∑i=1n(Yi−a)2达到最小,很明显它的解是:
∑ i = 1 n ( Y i − a ) = 0 ∑ i = 1 n Y i = n a a = Y ˉ = m h ^ ( x ) \begin{aligned} \sum_{i=1}^n(Y_i-a)&=0 \\ \sum_{i=1}^nY_i&=na\\ a &= \bar{Y}=\hat{m_h}(x) \end{aligned} i=1∑n(Yi−a)i=1∑nYia=0=na=Yˉ=mh^(x)
它显然不是 m ( x ) m(x) m(x)的一个好的估计,现在定义权函数 w i ( x ) = K ( ( x i − x ) / h ) w_i(x)=K((x_i-x)/h) wi(x)=K((xi−x)/h),再使得下述加权平方和达到最小:
1 2 ∑ i = 1 n w i ( x ) ( Y i − a ) 2 \frac{1}{2}\sum_{i=1}^nw_i(x)(Y_i-a)^2 21i=1∑nwi(x)(Yi−a)2
显然它的解是:
m h ^ ( x ) = ∑ i = 1 n w i ( x ) Y i ∑ i = 1 n w i ( x ) \hat{m_h}(x)=\frac{\sum_{i=1}^nw_i(x)Y_i}{\sum_{i=1}^nw_i(x)} mh^(x)=∑i=1nwi(x)∑i=1nwi(x)Yi
它刚好就是核回归估计,也说明NW估计是一种由局部加权最小二乘得到的局部常数估计。很明显如果利用线性函数而不是一个常数的话就能得到局部线性回归:
∑ i = 1 n { ( Y i − β 0 − β 1 X i ) } 2 w i ( x ) \sum_{i=1}^n\{ (Y_i-\beta_0-\beta_1X_i)\}^2w_i(x) i=1∑n{(Yi−β0−β1Xi)}2wi(x)
容易得当不存在 w i ( x ) w_i(x) wi(x)时上述解为:
{ β 0 = ∑ Y i n − β 1 ∑ X i n β 1 = n ∑ X i Y i − ∑ X i Y i n ∑ X i 2 − ∑ X i ∑ X i \begin{cases} \beta_0=\frac{\sum Y_i}{n}-\frac{\beta_1\sum X_i}{n} \\ \beta_1=\frac{n\sum X_iY_i-\sum X_iY_i}{n\sum X_i^2-\sum X_i\sum X_i} \end{cases} {β0=n∑Yi−nβ1∑Xiβ1=n∑Xi2−∑Xi∑Xin∑XiYi−∑XiYi
当存在 w i ( x ) w_i(x) wi(x)时上述解为:
{ ∑ w i ( x ) Y i = β 0 ∑ w i ( x ) + β 1 ∑ w i ( x ) X i ∑ w i ( x ) Y i X i = β 0 ∑ w i ( x ) X i + β 1 ∑ w i ( x ) X i 2 \begin{cases} \sum w_i(x)Y_i=\beta_0\sum w_i(x)+\beta_1 \sum w_i(x)X_i \\ \sum w_i(x)Y_iX_i=\beta_0\sum w_i(x)X_i+\beta_1\sum w_i(x)X_i^2 \end{cases} {∑wi(x)Yi=β0∑wi(x)+β1∑wi(x)Xi∑wi(x)YiXi=β0∑wi(x)Xi+β1∑wi(x)Xi2
局部多项式回归(local polynomial regression)
如果我们把上述中的常数 a a a换为一个 p p p阶的局部多项式就能得到局部多项式回归.令 x x xw为在其上想要估计 m ( x ) m(x) m(x)的某个固定值.则对于在 x x x一个邻域中的值 u u u,定义多项式
P x ( u ; a ) = a 0 + a 1 ( u − x ) + a 2 2 ! ( u − x ) 2 + ⋯ + a p p ! ( u − x ) p P_x(u;a)=a_0+a_1(u-x)+\frac{a_2}{2!}(u-x)^2+\cdots+\frac{a_p}{p!}(u-x)^p Px(u;a)=a0+a1(u−x)+2!a2(u−x)2+⋯+p!ap(u−x)p
能够在目标值 x x x的一个邻域用下面的多项式来近似一个光滑回归函数 m ( u ) m(u) m(u):
m ( u ) ≈ P x ( u ; a ) m(u)\thickapprox P_x(u;a) m(u)≈Px(u;a)
有些书籍中的多项式定义为: m ( ⋅ ) m(\cdot) m(⋅)
m ( t ) ≈ m ( x ) + m ′ ( x ) ( t − x ) + ⋯ + m ( p ) ( x ) ( t − x ) p 1 p ! m(t)\approx m(x)+m'(x)(t-x)+\cdots+m^{(p)}(x)(t-x)^p\frac{1}{p!} m(t)≈m(x)+m′(x)(t−x)+⋯+m(p)(x)(t−x)pp!1
此时的目标函数为:
min β ∑ i = 1 n { Y i − β 0 − β 1 ( X i − x ) − ⋯ − β p ( X i − x ) p } 2 K h ( x − X i ) \min_\beta\sum_{i=1}^n\{Y_i-\beta_0-\beta_1(X_i-x)-\dots-\beta_p(X_i-x)^p \}^2K_h(x-X_i) βmini=1∑n{Yi−β0−β1(Xi−x)−⋯−βp(Xi−x)p}2Kh(x−Xi)
其中 β \beta β表示系数向量 ( β 0 , β 1 , … , β p ) T (\beta_0,\beta_1,\dots,\beta_p)^{\rm{T}} (β0,β1,…,βp)T.
X = ( 1 X 1 − x ( X 1 − x ) 2 ⋯ ( X 1 − x ) p 1 X 2 − x ( X 2 − x ) 2 ⋯ ( X 2 − x ) p ⋮ ⋮ ⋮ ⋱ ⋮ 1 X n − x ( X n − x ) 2 ⋯ ( X n − x ) p ) , Y = ( Y 1 Y 2 ⋮ Y n ) X= \begin{pmatrix} 1& X_1-x & (X_1-x)^2 & \cdots & (X_1-x)^p \\ 1& X_2-x & (X_2-x)^2 & \cdots & (X_2-x)^p \\ \vdots & \vdots & \vdots & \ddots & \vdots\\ 1& X_n-x & (X_n-x)^2 & \cdots & (X_n-x)^p \\ \end{pmatrix} , Y= \begin{pmatrix} Y_1 \\ Y_2 \\ \vdots \\ Y_n \\ \end{pmatrix} X=⎝⎜⎜⎜⎛11⋮1X1−xX2−x⋮Xn−x(X1−x)2(X2−x)2⋮(Xn−x)2⋯⋯⋱⋯(X1−x)p(X2−x)p⋮(Xn−x)p⎠⎟⎟⎟⎞,Y=⎝⎜⎜⎜⎛Y1Y2⋮Yn⎠⎟⎟⎟⎞
W = ( K h ( x − X 1 ) 0 ⋯ 0 0 K h ( x − X 2 ) ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ K h ( x − X n ) ) , W= \begin{pmatrix} K_h(x-X_1) & 0 & \cdots & 0 \\ 0 & K_h(x-X_2) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & K_h(x-X_n) \\ \end{pmatrix}, W=⎝⎜⎜⎜⎛Kh(x−X1)0⋮00Kh(x−X2)⋮0⋯⋯⋱⋯00⋮Kh(x−Xn)⎠⎟⎟⎟⎞,
根据加权最小二乘估计可以得到 β ^ \hat{\beta} β^:
β ^ ( x ) = ( X T W X ) − 1 X T W Y \hat{\beta}(x)=(X^{\rm{T}}WX)^{-1}X^{\rm{T}}WY β^(x)=(XTWX)−1XTWY
利用上篇文章中的数据举个栗子:
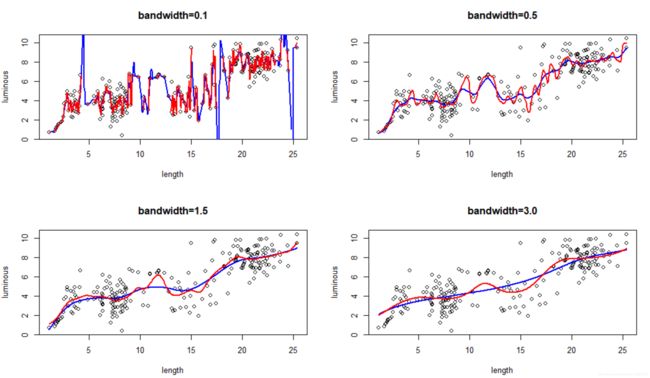
上图中,在相同核函数和窗宽的条件下,红线代表了上篇文章讲到的核回归的结果,蓝线代表了本文中局部多项式回归的结果.可以看到,局部多项式回归的结果更加平缓,极值点处的拟合效果更好.
- R语言代码如下:
par(mfrow=c(2,2))
fit1 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 0.1,range.x = range(data$length),n.points = length(x))
fit2 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 0.5,range.x = range(data$length),n.points = length(x))
fit3 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 1.5,range.x = range(data$length),n.points = length(x))
fit4 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 3.0,range.x = range(data$length),n.points = length(x))
polyfit <- locpoly(x1,x2,bandwidth = 0.1)
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=0.1')
lines(polyfit,lwd=2.0,col='blue')
lines(fit1,lwd=2.0,col='red')
polyfit <- locpoly(x1,x2,bandwidth = 0.5)
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=0.5')
lines(polyfit,lwd=2.0,col='blue')
lines(fit2,lwd=2.0,col='red')
polyfit <- locpoly(x1,x2,bandwidth = 1.5)
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=1.5')
lines(polyfit,lwd=2.0,col='blue')
lines(fit3,lwd=2.0,col='red')
polyfit <- locpoly(x1,x2,bandwidth = 3.0)
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=3.0')
lines(polyfit,lwd=2.0,col='blue')
lines(fit4,lwd=2.0,col='red')