转:http://www.manongjc.com/article/1082.html(以转的链接为主)
在数据库开发过程中,我们要为每种类型的数据取出前几条记录,或者是取最新、最小、最大等等,这个该如何实现呢,本文章向大家介绍如何实现mysql分组取最大(最小、最新、前N条)条记录。需要的可以参考一下。
先看一下本示例中需要使用到的数据
创建表并插入数据:
create table tb(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2')
insert into tb values('a', 1, 'a1')
insert into tb values('a', 3, 'a3')
insert into tb values('b', 1, 'b1')
insert into tb values('b', 3, 'b3')
insert into tb values('b', 2, 'b2')
insert into tb values('b', 4, 'b4')
insert into tb values('b', 5, 'b5')
数据表如下:
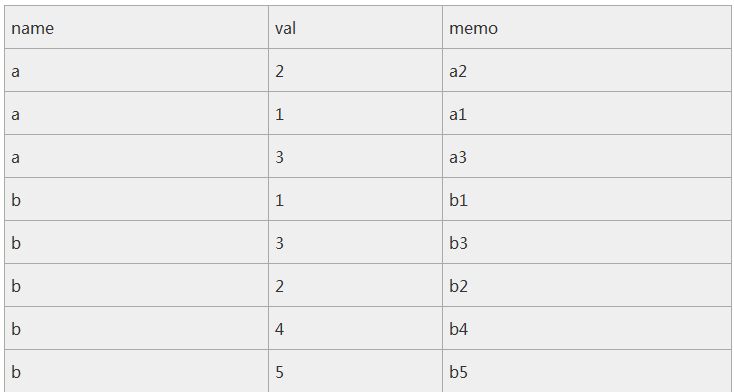
图片.png
按name分组取val最大的值所在行的数据
方法一:
select a.* from tb a where val = (select max(val) from tb where name = a.name) order by a.name
方法二:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val > a.val)
方法三:
select a.* from tb a,(select name,max(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
方法四:
select a.* from tb a inner join (select name , max(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by
方法五:
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name
以上五种方法运行的结果均为如下所示:

图片.png
推荐使用第一、第三、第四钟方法,结果显示第1,3,4种方法效率相同,第2,5种方法效率差些。
按name分组取val最小的值所在行的数据
方法一:
select a.* from tb a where val = (select min(val) from tb where name = a.name) order by a.name
方法二:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val < a.val)
方法三:
select a.* from tb a,(select name,min(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
方法四:
select a.* from tb a inner join (select name , min(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
方法五:
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val < a.val) order by a.name
以上五种方法运行的结果均为如下所示:

图片.png
按name分组取第一次出现的行所在的数据
sql如下:
select a.* from tb a where val = (select top 1 val from tb where name = a.name) order by a.name
结果如下:

图片.png
按name分组随机取一条数据
sql如下:
select a.* from tb a where val = (select top 1 val from tb where name = a.name order by newid()) order by a.name
结果如下:

图片.png
按name分组取最小的两个(N个)val
方法一:
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val < a.val ) order by a.name,a.val
方法二:
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val) order by a.name,a.val
方法三:
select a.* from tb a where exists (select count(*) from tb where name = a.name and val < a.val having Count(*) < 2) order by a.name
结果如下:
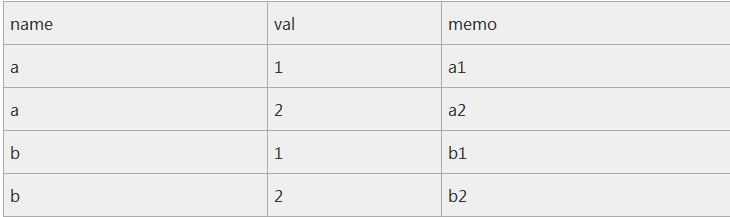
图片.png
按name分组取最大的两个(N个)val
方法一:
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name,a.val
方法二:
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val desc) order by a.name,a.val
方法三:
select a.* from tb a where exists (select count(*) from tb where name = a.name and val > a.val having Count(*) < 2) order by a.name
结果如下:
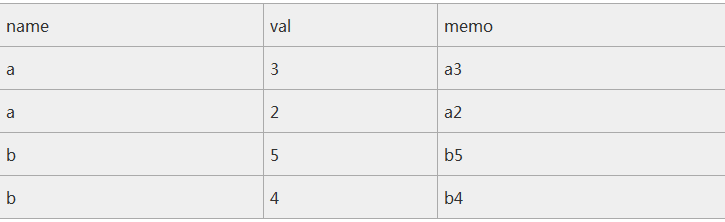
图片.png