Redis 高可用、缓存不一致、缓存雪崩
Redis 高可用、缓存不一致、缓存雪崩
文章目录
- Redis 高可用、缓存不一致、缓存雪崩
- 缓存雪崩
- 数据失效
- 对数据库访问限流,返回异常码
- 容错降级,返回异常码
- 针对内存不足,采用 Redis 集群方案
- 缓存击穿
- 布隆过滤器(Bloom Filter)
- Redis 实现布隆过滤器
- 高可用集群方案
- redis cluster 集群
- 数据库与 Redis 数据的一致性
- 推荐做法一
- 推荐做法二
缓存雪崩
数据失效
模拟 2000 并发的场景,从缓存中读数据,没有任何问题。而如果 redis 失效了呢?比如硬件升级、突然断电,这种怎么办?原本应该访问缓存的,结果缓存失效了,雪崩…
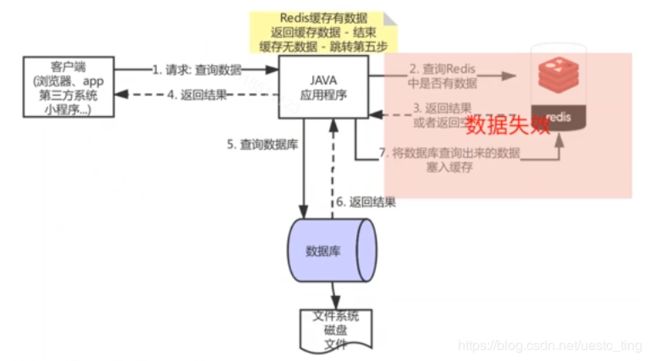
因为缓存失效,从而导致大量的请求怼到数据库。
- 大量请求,导致数据库处理不过来,整个系统依赖数据库的功能,全部崩溃;
- 单系统挂掉,其它依赖于该系统的应用也会出现不稳定,甚至崩溃;
显然,不能在生产环境出现这个问题。
一般,这么几种情况可能出现缓存失效:
- 数据淘汰,LRU/LFU,最大内存阈值,依据内存使用情况淘汰掉旧的数据;
- 数据过期 expire,超过时间了,缓存就没了。
- 服务重启、宕机、升级,虽然支持全量的文件存储,也支持主从复制。
上面这些问题,是不可避免的,或者无法全部避免。但是可以用一些方式,避免缓存雪崩。
缓存雪崩还是要针对出现的问题原因做解决,最终的目的是防止数据库崩溃导致全盘崩溃。主要方案有:
对数据库访问限流,返回异常码
典型的有Semaphore信号量限流,JUC 中重要的并发编程工具类,可以理解为“手牌”。核心方法有:
- acquire:获取一个许可,如果没有就等待
- release:释放一个许可
使用的方式,在读取数据库之前,给一个 semaphore.acquire() 获取一个令牌,这样就可以控制只有一定数量的线程能够通过,执行数据库访问。访问完之后,再 semaphore.release() 释放一个令牌。
容错降级,返回异常码
限流之后,等待时间太长了,于是就要有一个降级策略。比如告诉前台:网络不给力,请重试。
这时候,可以用 semaphore.tryAcquire(),或者设置超时时间。如果超时了,就返回一个错误,便可以触发降级了。
如果直接在代码里面写这些缓存、限流的代码,就也让业务代码变得复杂了。于是,就可以自定义组件,自定义注解,去扩展原来的功能。
针对内存不足,采用 Redis 集群方案
(见后面的“高可用集群方案”)
缓存击穿
比如,访问不存在的数据。针对高并发的场景,常用的读都会命中缓存。而如果去查不存在的数据呢?如果还照着原来的设计,就会不停的去查数据库。
这样,查询必然不存在的数据,请求透过 Redis,直击数据库,也会导致缓存雪崩。

思路是,查询之前先判断目标数据是否存在,不存在的直接忽略,将流量拦截于缓存和数据库之前。

问题的本质,就是判断集合中是否存在某个元素。类似的场景有:
- 数据库设计中,海量数据查询,快速判断数据是否存在?
- 数十亿网站域名,快速判定网址不合法;
- 垃圾邮件快速判定;
- 爬虫应用中的 URL 地址去重场景;
如果把所有数据都放到内存,这肯定是不合理的。设计思路:
- 目的:减少内存占用
- 方式:不保存所有 ID 信息,只在内存中做一个标记
布隆过滤器(Bloom Filter)
布隆过滤器是 1970 年由布隆提出的,实际上是一个很长的二进制数组和一系列 hash 函数。
可以用于检索一个元素是否在一个集合中。优点是空间效率(内存占用)和查询时间都比一般的算法要好得多,缺点是有一定的误识率和删除困难。
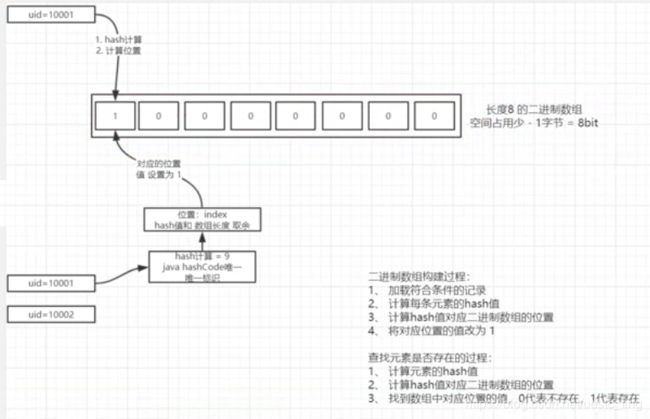
*二进制数组的构建过程
- 加载符合条件的记录;
- 计算每条元素的 hash 值;
- 计算 hash 值对应二进制数组的位置,比如取余;
- 将对应位置的值改为 1;
元素是否存在的过程:
- 计算元素的 hash 值;
- 计算 hash 值对应二进制数组的位置;
- 找到数组中对应位置的值,0 代表不存在,1 代表存在;
换种方式表达,注意这儿的 bitmap 长度不是实际长度。比如 redis 中这么一个 bitmap 数组,长度有 40 亿~
Redis 实现布隆过滤器
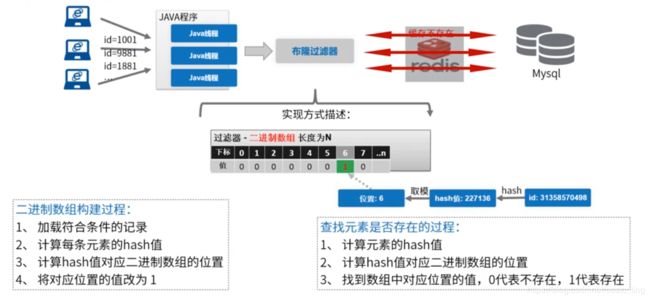
利用 Redis 特性和命令:bitmaps(SETBIT 设置指定位置的值、GETBIT 获取值),可以理解为这是 Redis 自带的二进制数组特性。
在每次操作数据库之外,还需要维护这么个布隆数组。如果是第一次使用,还需要在启动的时候,把所有数据给初始化了。(在生产环境,只需要初始化一次,后续做数据维护即可)
在 Redis 里面,这么一个 bitmaps,长达 40 亿。按这种方式,出现重复的概率比较小。
而且,布隆过滤器并非拦截所有的请求,而是意在将缓存击穿控制在一定的数量。
高可用集群方案
单机的内存不够怎么办?比如,用户量 3 千万,内存需要 10 G,如何设计 Redis 的缓存架构?

故此,引出了分片存储的技术,一个集群的方案。而集群的难点不是部署,而是出问题了要怎么排查?
集群之后,不同的用户信息,数据就在不同的服务器上。而如果,某台服务器挂了,怎么办?那么,就也需要给 redis 集群做一个主从复制,给每个数据都有一个副本。
redis cluster 集群
redis cluster 是 redis 的分布式集群解决方案,在 3.0 版本推出后有效地解决了 redis 分布式方面的需求。实现了数据在多个 redis 节点之间自动分片、故障自动转移、扩容机制等等。参考官方文档
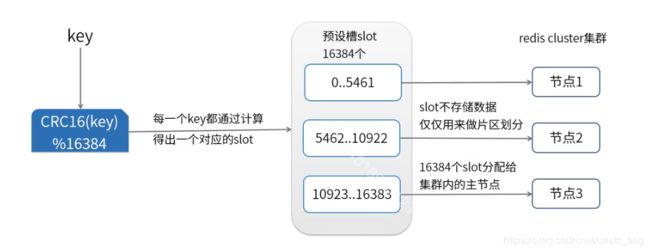
问题1:用户 1 存哪里,用户 2 存哪里?
- 类似于火车车厢里面有许多的座位,整个 redis 集群,会在建立之初,就把 redis(多个车厢)各自分了许多的虚拟槽(座位),最大为 16383。
- 要怎么找到位置呢?比如,把 key 做 hash 计算,再和位置取个模,这样就找到座位了。每个 key 值计算出来的 hash 都是不会变的,任一台服务器,都可以知道集群中的哪个机器有哪些座位。
- 这儿的位置,不是用来存储数据的,而只是一个分片区的概念。
问题2:对于客户端要怎么操作呢?现在服务多了,位置的算法也都是 redis 内部的,要连哪个?
- 随便连哪个都可以,如果上错车了,redis 会响应一个重定向,告诉你应该把数据放到别个地方;
- 客户端收到重定向之后,就会把数据转移到正确的那一个实例;
问题3:如果客户端都不知道数据正确位置,发 1 万个错误服务器的请求,会影响性能吗?
- 不会的,客户端自己知道,可以把位置与redis信息做缓存。这样,就不需要每次都重复请求了,可以精准的对应到服务的相应节点。
问题4:redis 用着用着,满了,怎么办?
- 分配的信息是会不断变化的,如果加多了车厢,那么集群就会刷新分配信息;
- 如果客户端在没有更新的时候,去请求了服务节点,那么服务节点会响应重定向;
- 这时候,客户端会知道自己缓存的位置信息,失效了,就要重新进行刷新。
数据库与 Redis 数据的一致性
当我在执行查询的时候,通过注解 @Cacheable 把缓存加到了 redis,
数据修改了,怎么同步到 redis?
1、【不推荐】先更新数据库,再更新缓存;
2、【不推荐】先更新缓存,再更新数据库;
3、【不推荐】删除缓存,再更新数据库;
4、【推荐】先更新数据库,再删除缓存;
在多线程里面,一些看似可用的代码,却不是想要的效果。数据库里面数据更新了,可是缓存还是旧的值。可参考:究竟先操作缓存,还是数据库?、缓存与数据库不一致,咋办?
推荐做法一
- 读请求,先读缓存,如果没有,读数据库,再set回缓存;
- 写请求,先修改数据库,再删除缓存;
Spring 的注解 @CacheEvict 也是如此,方法执行结束,才会删除缓存;
数据库主从不一致怎么办?
1、直接忽略
如果业务可以接收,最推荐这种做法。任何脱离业务的架构设计都是耍流氓,绝大部分业务,例如:百度搜索,淘宝订单,QQ消息,58帖子都允许短时间不一致。
2、强制读主
- 使用一个高可用主库提供数据库服务
- 读和写都落到主库上
- 采用缓存来提升系统读性能
3、选择性读主
有没有可能实现,只有这一段时间,可能读到从库脏数据的读请求读主,平时读从呢?可以利用一个缓存记录必须读主的数据。把写入数据分为这么 2 个步骤:
- 写主库
- 同时将“哪个库,哪个表,哪个主键”三个信息拼装一个 key 设置到 cache 里,这条记录的超时时间,设置为“主从同步时延”
这样,在读数据的时候,先把“读哪个库,哪个表,哪个主键”的数据拼装成 key 到 cache 里去查询:
- cache里有这个key,说明1s内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询
- cache里没有这个key,说明最近没有发生过写请求,此时就可以去从库查询
推荐做法二
思路为:在从库同步完成之后,如果有旧数据入缓存,应该及时把这个旧数据淘汰掉。
 执行流程为:
执行流程为:
- 主从同步。
- 通过工具订阅从库的 binlog,这里能够最准确的知道,从库数据同步完成的时间。比如,可以使用 DTS 订阅工具、cannal、或者自己分析 binlog。
- 从库执行完写操作,向缓存再次发起删除,淘汰这段时间内可能写入缓存的旧数据。
- 如此这般,至少能够保证,引入缓存之后,主从不一致,不会比没有引入缓存更坏。
实际上呢,即使引入缓存,也只有一个很小的时间间隔,可能读到旧数据。
换个方式表达,即:
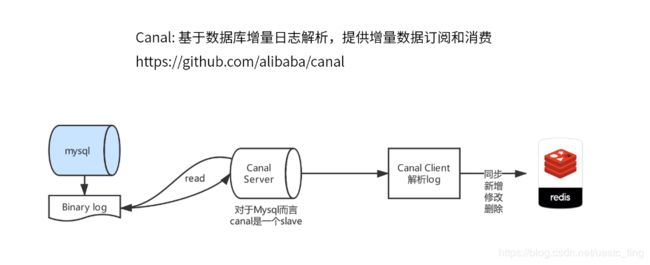
- mysql 手动打开 Binary log,监控 insert/update 的操作;
- 业务代码执行数据更新或插入,不会处理缓存;
- AOF 持久化,在监听到 insert/update 之后,异步操作缓存。比如使用 Cacal
具体的操作:
1、开启 mySql 的 binLog 信息,即修改 /etc/my.cnf…
# 开启binlog,并且把每一行都记录下来
binlog-format=ROW
2、阿里的 Canel-Server 服务,是一个单独启动的程序,可以监听多个数据库服务。包括要监控哪些表,都可以做到。
3、业务在 update 的时候不操作缓存了,取而代之引入 Canel 客户端,读取 Canel 服务端的 binLog 文件;
4、客户端依据不同的服务,采用不同的缓存策略。
这儿以用户信息更新为例,比如每隔 1 秒钟时间,用 canel 的 api 拿到数据库的操作事件(UPDATE/DELETE/INSERT…),依据事件进行 redis 的操作,把数据同步到 redis 里面去。
5、这样,把缓存的操作异步执行,业务部分就不需要关注这部分,只需要做好增删改查,其它的事情就交给架构来做!