2019独角兽企业重金招聘Python工程师标准>>> 
在 TiDB 中,底层索引结构为 LSM-Tree,如下图:

开篇
世界级的开源分布式数据库 TiDB 自 2016 年 12 月正式发布第一个版本以来,业内诸多公司逐步引入使用,并取得广泛认可。
对于互联网公司,数据存储的重要性不言而喻。在 NewSQL 数据库出现之前,一般采用单机数据库(比如 MySQL )作为存储,随着数据量的增加,“分库分表”是早晚面临的问题,即使有诸如 MyCat、ShardingJDBC 等优秀的中间件,“分库分表”还是给 RD 和 DBA 带来较高的成本; NewSQL 数据库出现后,由于它不仅有 NoSQL 对海量数据的管理存储能力、还支持传统关系数据库的 ACID 和 SQL,所以对业务开发来说,存储问题已经变得更加简单友好,进而可以更专注于业务本身。而 TiDB,正是 NewSQL 的一个杰出代表!
站在业务开发的视角,TiDB 最吸引人的几大特性是:
支持 MySQL 协议(开发接入成本低);
100% 支持事务(数据一致性实现简单、可靠);
无限水平拓展(不必考虑分库分表)。
基于这几大特性,TiDB 在业务开发中是值得推广和实践的,但是,它毕竟不是传统的关系型数据库,以致我们对关系型数据库的一些使用经验和积累,在 TiDB 中是存在差异的,现主要阐述“事务”和“查询”两方面的差异。
TiDB 事务和 MySQL 事务的差异
MySQL 事务和 TiDB 事务对比

在 TiDB 中执行的事务 b,返回影响条数是 1 (认为已经修改成功),但是提交后查询,status 却不是事务 b 修改的值,而是事务 a 修改的值。
可见,MySQL 事务和 TiDB 事务存在这样的差异:
MySQL 事务中,可以通过影响条数,作为写入(或修改)是否成功的依据;而在 TiDB 中,这却是不可行的!
作为开发者我们需要考虑下面的问题:
同步 RPC 调用中,如果需要严格依赖影响条数以确认返回值,那将如何是好?
多表操作中,如果需要严格依赖某个主表数据更新结果,作为是否更新(或写入)其他表的判断依据,那又将如何是好?
原因分析及解决方案
对于 MySQL,当更新某条记录时,会先获取该记录对应的行级锁(排他锁),获取成功则进行后续的事务操作,获取失败则阻塞等待。
对于 TiDB,使用 Percolator 事务模型:可以理解为乐观锁实现,事务开启、事务中都不会加锁,而是在提交时才加锁。参见 这篇文章( TiDB 事务算法)。
其简要流程如下:
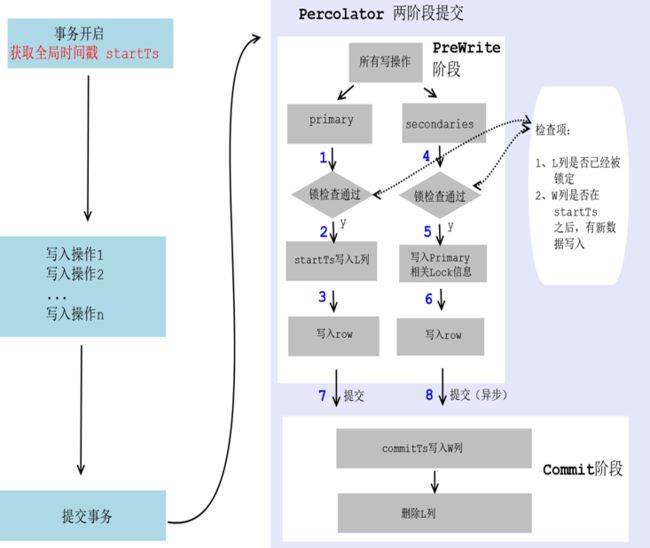
在事务提交的 PreWrite 阶段,当“锁检查”失败时:如果开启冲突重试,事务提交将会进行重试;如果未开启冲突重试,将会抛出写入冲突异常。
可见,对于 MySQL,由于在写入操作时加上了排他锁,变相将并行事务从逻辑上串行化;而对于 TiDB,属于乐观锁模型,在事务提交时才加锁,并使用事务开启时获取的“全局时间戳”作为“锁检查”的依据。
所以,在业务层面避免 TiDB 事务差异的本质在于避免锁冲突,即,当前事务执行时,不产生别的事务时间戳(无其他事务并行)。处理方式为事务串行化。
TiDB 事务串行化
在业务层,可以借助分布式锁,实现串行化处理,如下:
基于 Spring 和分布式锁的事务管理器拓展
在 Spring 生态下,spring-tx 中定义了统一的事务管理器接口:PlatformTransactionManager,其中有获取事务( getTransaction )、提交( commit )、回滚( rollback )三个基本方法;使用装饰器模式,事务串行化组件可做如下设计:
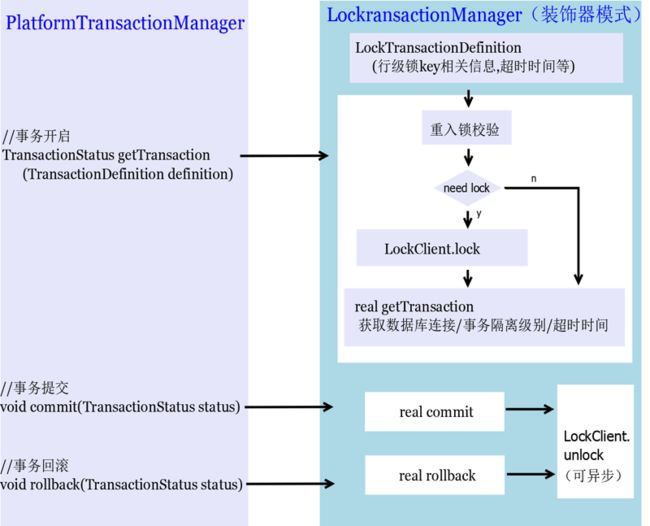
其中,关键点有:
超时时间:为避免死锁,锁必须有超时时间;为避免锁超时导致事务并行,事务必须有超时时间,而且锁超时时间必须大于事务超时时间(时间差最好在秒级)。
加锁时机:TiDB 中“锁检查”的依据是事务开启时获取的“全局时间戳”,所以加锁时机必须在事务开启前。
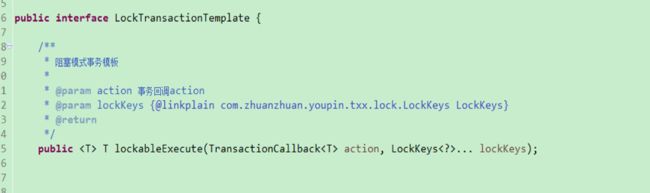
事务模板接口设计
隐藏复杂的事务重写逻辑,暴露简单友好的 API:

TiDB 查询和 MySQL 的差异
在 TiDB 使用过程中,偶尔会有这样的情况,某几个字段建立了索引,但是查询过程还是很慢,甚至不经过索引检索。
索引混淆型(举例)
表结构:
| CREATE TABLE `t_test` ( `id` bigint(20) NOT NULL DEFAULT '0' COMMENT '主键 id', `a` int(11) NOT NULL DEFAULT '0' COMMENT 'a', `b` int(11) NOT NULL DEFAULT '0' COMMENT 'b', `c` int(11) NOT NULL DEFAULT '0' COMMENT 'c', PRIMARY KEY (`id`), KEY `idx_a_b` (`a`,`b`), KEY `idx_c` (`c`) ) ENGINE=InnoDB; |
查询:如果需要查询 (a=1 且 b=1 )或 c=2 的数据,在 MySQL 中,sql 可以写为:SELECT id from t_test where (a=1 and b=1) or (c=2);,MySQL 做查询优化时,会检索到 idx_a_b 和 idx_c 两个索引;但是在 TiDB ( v2.0.8-9 )中,这个 sql 会成为一个慢 SQL,需要改写为:
| SELECT id from t_test where (a=1 and b=1) UNION SELECT id from t_test where (c=2); |
小结:导致该问题的原因,可以理解为 TiDB 的 sql 解析还有优化空间。
冷热数据型(举例)
表结构:
| CREATE TABLE `t_job_record` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键 id', `job_code` varchar(255) NOT NULL DEFAULT '' COMMENT '任务 code', `record_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '记录 id', `status` tinyint(3) NOT NULL DEFAULT '0' COMMENT '执行状态:0 待处理', `execute_time` bigint(20) NOT NULL DEFAULT '0' COMMENT '执行时间(毫秒)', PRIMARY KEY (`id`), KEY `idx_status_execute_time` (`status`,`execute_time`), KEY `idx_record_id` (`record_id`) ) ENGINE=InnoDB COMMENT='异步任务 job' |
数据说明:
a. 冷数据,status=1 的数据(已经处理过的数据);
b. 热数据,status=0 并且 execute_time<= 当前时间 的数据。
慢查询:对于热数据,数据量一般不大,但是查询频度很高,假设当前(毫秒级)时间为:1546361579646,则在 MySQL 中,查询 sql 为:
| SELECT * FROM t_job_record where status =0 and execute_time< = 1546361579646 |
这个在 MySQL 中很高效的查询,在 TiDB 中虽然也可从索引检索,但其耗时却不尽人意(百万级数据量,耗时百毫秒级)。
原因分析:在 TiDB 中,底层索引结构为 LSM-Tree,如下图:
当从内存级的 C0 层查询不到数据时,会逐层扫描硬盘中各层;且 merge 操作为异步操作,索引数据更新会存在一定的延迟,可能存在无效索引。由于逐层扫描和异步 merge,使得查询效率较低。
优化方式:尽可能缩小过滤范围,比如结合异步 job 获取记录频率,在保证不遗漏数据的前提下,合理设置 execute_time 筛选区间,例如 1 小时,sql 改写为:
| SELECT * FROM t_job_record where status =0 and execute_time> 1546357979646 and execute_time<= 1546361579646 |
优化效果:耗时 10 毫秒级别(以下)。
关于查询的启发
在基于 TiDB 的业务开发中,先摒弃传统关系型数据库带来的对 sql 先入为主的理解或经验,谨慎设计每一个 sql,如 DBA 所提倡:设计 sql 时务必关注执行计划,必要时请教 DBA。
和 MySQL 相比,TiDB 的底层存储和结构决定了其特殊性和差异性;但是,TiDB 支持 MySQL 协议,它们也存在一些共同之处,比如在 TiDB 中使用“预编译”和“批处理”,同样可以获得一定的性能提升。
服务端预编译
在 MySQL 中,可以使用 PREPARE stmt_name FROM preparable_stm 对 sql 语句进行预编译,然后使用 EXECUTE stmt_name [USING @var_name [, @var_name] ...] 执行预编译语句。如此,同一 sql 的多次操作,可以获得比常规 sql 更高的性能。
mysql-jdbc 源码中,实现了标准的 Statement 和 PreparedStatement 的同时,还有一个ServerPreparedStatement 实现,ServerPreparedStatement 属于PreparedStatement的拓展,三者对比如下:
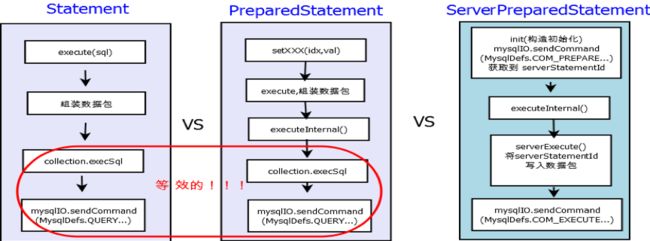
容易发现,PreparedStatement 和 Statement 的区别主要区别在于参数处理,而对于发送数据包,调用服务端的处理逻辑是一样(或类似)的;经测试,二者速度相当。其实,PreparedStatement 并不是服务端预处理的;ServerPreparedStatement 才是真正的服务端预处理,速度也较 PreparedStatement 快;其使用场景一般是:频繁的数据库访问,sql 数量有限(有缓存淘汰策略,使用不宜会导致两次 IO )。
批处理
对于多条数据写入,常用 sql 为 insert … values (…),(…);而对于多条数据更新,亦可以使用 update … case … when … then … end 来减少 IO 次数。但它们都有一个特点,数据条数越多,sql 越加复杂,sql 解析成本也更高,耗时增长可能高于线性增长。而批处理,可以复用一条简单 sql,实现批量数据的写入或更新,为系统带来更低、更稳定的耗时。
对于批处理,作为客户端,java.sql.Statement 主要定义了两个接口方法,addBatch 和 executeBatch 来支持批处理。
批处理的简要流程说明如下:

经业务中实践,使用批处理方式的写入(或更新),比常规 insert … values(…),(…)(或 update … case … when … then … end)性能更稳定,耗时也更低。