Domain-Adversarial Training of Neural Networks
本篇是迁移学习专栏介绍的第十八篇论文,发表在JMLR2016上。
Abstrac
提出了一种新的领域适应表示学习方法,即训练和测试时的数据来自相似但不同的分布。我们的方法直接受到域适应理论的启发,该理论认为,要实现有效的域转移,必须基于不能区分训练(源)域和测试(目标)域的特征进行预测。
该方法在神经网络体系结构的上下文中实现了这一思想,神经网络体系结构的训练对象是源域的标记数据和目标域的未标记数据(不需要标记目标域数据)。随着培训的进展,该方法促进了(i)对源领域的主要学习任务具有任意的特征的出现,(ii)对域之间的转换具有不加区别的特征。
我们证明,这种自适应行为几乎可以在任何前馈模型中实现,通过增加几个标准层和一个新的梯度反转层。生成的增强架构可以使用标准的反向传播和随机梯度下降进行训练,因此可以使用任何深度学习包轻松实现。我们证明了我们的方法成功地解决了两个不同的分类问题(文档情感分析和图像分类),其中在标准基准上实现了最先进的领域适应性能。我们还验证了描述符学习任务在人员再识别应用中的方法。
1. Introduction
为新的机器学习任务生成标记数据的成本通常是应用机器学习方法的一个障碍。特别是,这是深度神经网络体系结构进一步发展的一个限制因素,深度神经网络体系结构已经在各种机器学习任务和应用中带来了令人印象深刻的最新进展。对于缺少标记数据的问题,仍然有可能获得足够大的训练集来训练大规模的深度模型,但是这些训练集的数据分布与测试时遇到的实际数据发生了变化。一个重要的例子是在合成或半合成图像上训练一个图像分类器,合成或半合成图像可能数量很多,并且被完全标记,但不可避免地具有与真实图像不同的分布(Liebelt and Schmid, 2010; Stark et al., 2010; V´azquez et al., 2014; Sun and Saenko, 2014)。另一个例子是在书面评论的情感分析上下文中,人们可能为一种类型的产品(如电影)的评论标记了数据,同时需要对其他产品(如书籍)的评论进行分类。
在训练分布和测试分布之间存在转移的情况下学习判别分类器或其他预测器被称为域适应(DA)。提出的方法构建源(培训时间)和目标(测试时间)域之间的映射,这样,当使用域之间的学习映射组合时,为源域学习的分类器也可以应用于目标域。域适应方法的吸引力在于,当目标域数据要么完全无标记(无监督域注释),要么标记样本很少(半监督域适应)时,能够学习域之间的映射。下面,我们将重点讨论更困难的无监督情况,尽管所提出的方法(领域对抗性学习)可以相当直接地推广到半监督情况。
与以往许多使用固定特征表示的领域适应论文不同,我们侧重于将领域适应和深度特征学习结合在一个训练过程中。我们的目标是将领域自适应嵌入到学习表示的过程中,使最终的分类决策基于对领域变化既具有鉴别性又不变性的特征,即,在源和目标域中具有相同或非常相似的分布。这样,得到的前馈网络可以应用于目标域,而不受两个域之间位移的影响。我们的方法是受到领域适应理论的启发(Ben-David et al., 2006, 2010),这表明一个好的跨领域转移表示是一个算法无法识别输入观测的原点域。
因此,我们关注结合(i)辨别力和(ii)域不变性的学习特性。这是通过联合优化底层特征以及两种区别的分类器操作这些功能:(i)预测,预测类标签的标签和使用在训练和测试时间,(ii)的域分类器源和目标域之间的歧视在训练。对分类器参数进行优化,使其在训练集上的误差最小;对底层深度特征映射参数进行优化,使标签分类器的损失最小,使域分类器的损失最大。后者因此,update与域分类器相反,它鼓励在优化过程中出现域不变的特性。
至关重要的是,我们表明,所有三个训练过程可以嵌入到一个适当的由深前馈网络,称为domain-adversarial神经网络(丹)(图1所示,第12页),使用标准层和损失函数,可以使用标准的反向传播算法训练基于随机梯度下降法或其修改(例如,SGD动量)。该方法是通用的,因为DANN版本几乎可以为任何可以通过反向传播训练的现有前馈体系结构创建。实际上,所提议的体系结构的唯一非标准组件是一个相当简单的梯度反转层,它在正向传播期间保持输入不变,并在反向传播期间通过将其乘以一个负标量来反转梯度。
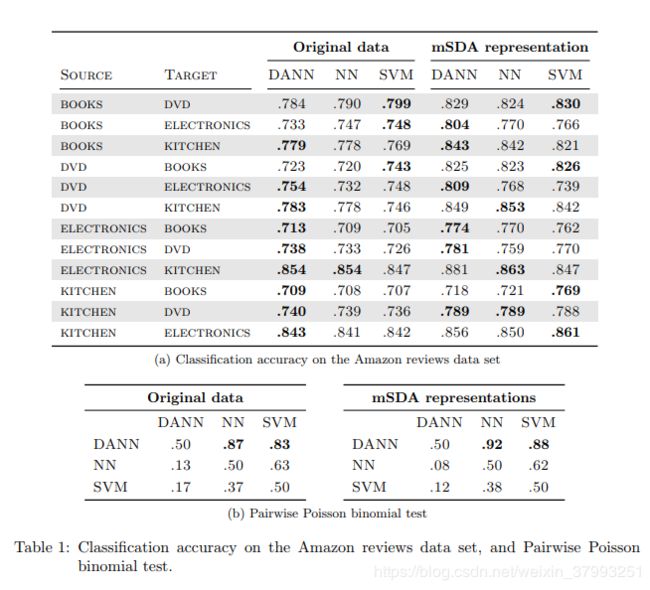
我们提供了一个在一系列深层架构和应用领域的领域对抗学习思想的实验评估。我们首先考虑最简单的DANN体系结构,其中三个部分(标签预测器、领域分类器和特征提取器)是线性的,并证明了这种体系结构的领域对抗学习的成功。对综合数据和自然语言处理中的情绪分析问题进行评估,其中DANN改进了Chen等人(2012)在Amazon review common benchmark上的最先进的边缘化堆叠式自动编码器(mSDA)。
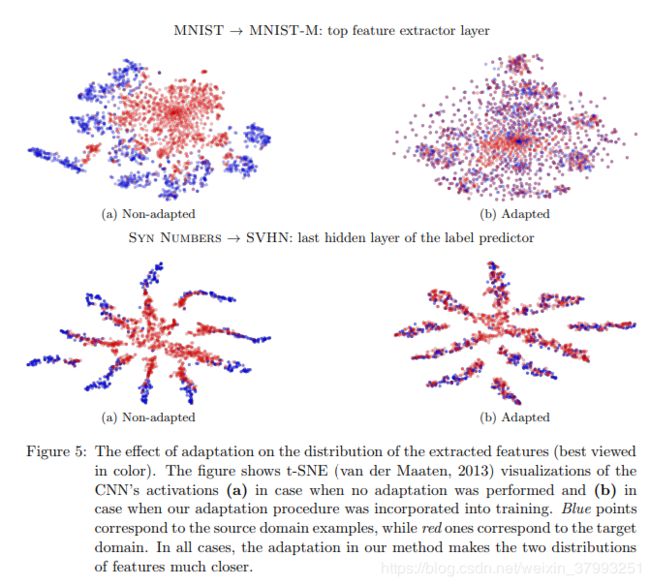
我们进一步评估该方法广泛的图像分类任务,和现在的结果MNIST等传统深度学习图像数据集(勒存et al ., 1998)和SVHN (Netzer et al ., 2011)以及Office benchmarks(Saenko et al ., 2010),在domain-adversarial学习允许获得一个深架构,先进的精度比以往大大提高。
最后,我们评估了领域对抗性描述符学习在人的再识别应用中的应用(Gong et al., 2014),其中的任务是获得适合检索和验证的良好的行人图像描述符。我们使用领域对抗性学习,因为我们考虑一个训练有类似暹罗损失的描述符预测器,而不是训练有分类损失的标签预测器。在一系列的实验中,我们证明了域对抗性学习可以显著提高跨数据集的再识别能力。
2. Related work
从许多方面探讨了实现领域适应的一般方法。多年来,大部分文献主要集中在线性假设(Blitzer et al., 2006; Bruzzone and Marconcini, 2010; Germain et al., 2013; Baktashmotlagh et al., 2013; Cortes and Mohri, 2014)。近年来,非线性表征得到了越来越多的研究,包括神经网络表征(Glorot et al., 2011; Li et al., 2014);最著名的是最先进的mSDA (Chen et al., 2012)。该文献主要侧重于开发基于去噪自动编码器范式的鲁棒表示原则(Vincent et al., 2008)。
同时,针对无监督域自适应问题,提出了多种匹配源域和目标域特征分布的方法。一些方法通过从源域重新称重或选择样本来实现这一点(Borgwardt et al., 2006; Huang et al., 2006; Gong et al., 2013),而其他人则寻求一种明确的特征空间转换,将源分布映射到目标分布(Pan et al., 2011; Gopalan et al., 2011; Baktashmotlagh et al., 2013)。分布匹配方法的一个重要方面是度量分布之间相似性的方法。在这里,一个流行的选择是匹配核再生希尔伯特空间中的分布方式(Borgwardt et al., 2006;Huang et al., 2006),而Gong et al.(2012)和Fernando et al.(2013)绘制了与每个分布相关的主轴。
我们的方法也尝试匹配特征空间分布,但是这是通过修改特征表示本身来实现的,而不是通过重新加权或几何变换。此外,我们的方法使用了一种非常不同的方法来测量分布之间的差异,基于他们的可分性,通过一个深度判别训练分类器。还要注意,有几种方法执行从源到目标域的转换(Gopalan et al., 2011; Gong et al., 2012)通过逐步改变培训分布。在这些方法中,Chopra等人(2013)通过对一系列深度自编码器进行分层训练,逐步用目标域样本替代源域样本,从而进行了深入的研究。与Glorot et al.(2011)的类似方法相比,这一方法得到了改进,Glorot et al.(2011)的方法只是为两个域训练一个单独的深层自动编码器。在这两种方法中,实际的分类器/预测器都是使用自动编码器学习的特征表示在单独的步骤中学习的。与Glorot et al.(2011)相反;Chopra等(2013),我们的方法在统一的体系结构中,使用单一的学习算法(反向传播),联合执行特征学习、领域自适应和分类器学习。因此,我们认为我们的方法更简单(无论是在概念上还是在实现上)。我们的方法在流行的Office基准测试上也取得了相当好的结果。
虽然上述方法执行无监督域自适应,但也有一些方法通过利用目标域的标记数据来执行监督域自适应。在深度前馈架构的背景下,这些数据可以用来微调在源域上训练的网络(Zeiler and Fergus, 2013; Oquab et al., 2014; Babenko et al., 2014).。我们的方法不需要标记目标域数据。同时,当这些数据可用时,它可以很容易地合并它们。
Goodfellow等(2014)描述了一个与我们相关的想法。虽然他们的目标是完全不同(建筑生成深层网络,可以合成样品),,他们测量的方式,减少训练数据的分布之间的差异和合成数据的分布非常类似于我们的架构方式措施和最小化两个域之间的差异特征分布。此外,作者提到了饱和乙状结肠的问题,这可能出现在早期的训练阶段,由于领域的显着差异。他们用来回避这个问题的技术(梯度的对抗性部分被相对于适当成本计算的梯度所取代)直接适用于我们的方法。
曾等人(2014)近期及同期报道;Long和Wang(2015)专注于前馈网络中的域适应。他们的技术集度量并最小化跨域的数据分布方式之间的距离(在将分布嵌入RKHS之后,可能会这样做)。因此,他们的方法不同于我们的想法,匹配分布,使他们难以区分的判别分类器。下面,我们将我们的方法与曾等人(2014)进行比较;龙和王(2015)关于办公室基准。Chen et al.(2015)同时开发了另一种深度域适应方法,可以说它与我们的方法更不同。
从理论的角度来看,我们的方法直接来源于Ben-David et al.(2006, 2010)开创性的理论著作。实际上,DANN直接优化了h散度的概念。我们确实注意到了Huang和Yates(2012)的工作,他们使用后验正则化器学习HMM表示来标记单词,后验正则化器也是受到Ben-David等人工作的启发。除了Huang和Yates(2012)的任务不同之外,我们认为DANN learning objective更接近于优化H-divergence, Huang和Yates(2012)出于效率的原因依赖于更为粗糙的逼近。
本文的一部分已作为会议论文发表(Ganin and Lempitsky, 2015)。这个版本扩展了Ganin和Lempitsky(2015)很明显通过合并报告Ajakan et al。(2014)(作为第二个研讨会的一部分转让和多任务学习),这带来了新的术语,深入的理论分析和论证的方法,广泛的实验与浅丹案例对合成数据以及自然语言处理任务(情绪分析)。此外,在这个版本中,我们超越了分类,并对人员重新标识应用程序中的描述符学习设置评估领域对抗性学习。
3. Domain Adaptation
我们考虑分类任务,其中![]() 是输入空间,
是输入空间,![]() 是个可能的
是个可能的![]() 标签的集合。此外,我们在
标签的集合。此外,我们在![]() 上有两种不同的分布,称为源域
上有两种不同的分布,称为源域![]() 和目标域
和目标域![]() 。然后,给出了一个无监督域自适应学习算法,其中,源样本
。然后,给出了一个无监督域自适应学习算法,其中,源样本![]() 从
从![]() 绘制i.i.d,目标样本
绘制i.i.d,目标样本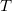 从
从![]() 绘制i.i.d,其中
绘制i.i.d,其中![]() 为
为![]() 的边缘分布。
的边缘分布。
其中![]() 为样本总数。学习算法的目标是建立一个分类器
为样本总数。学习算法的目标是建立一个分类器![]() 低目标的风险
低目标的风险
![]()
而没有关于![]() 标签的信息。
标签的信息。
3.1 Domain Divergence
为了解决具有挑战性的领域自适应任务,许多方法通过源误差和源分布与目标分布之间的距离来确定目标误差。通过一个简单的假设,可以直观地证明这些方法是正确的:当两个分布相似时,预期源风险是目标风险的良好指示器。已有几个领域适应的距离概念被提出(Ben-David et al., 2006, 2010; Mansour et al., 2009a,b; Germain et al., 2013)。在本文中,我们主要关注Ben-David等人(2006,2010)使用的H-divergence算法。基于Kifer早期的工作,注意,我们在下面的定义1中假设假设类H是一组(离散的或连续的)二进制分类器![]()
Definition 1 (Ben-David et al., 2006, 2010; Kifer et al., 2004) 给定![]() 和
和![]() 的两个域分布,以及一个假设类H,
的两个域分布,以及一个假设类H,![]() 和
和![]() 的H散度是
的H散度是
也就是说,H散度依赖于假设类H区分由![]() 生成的例子和由
生成的例子和由![]() 生成的例子的能力。Ben-David等(2006,2010)证明,对于对称假设类H,可以通过计算计算两个样本
生成的例子的能力。Ben-David等(2006,2010)证明,对于对称假设类H,可以通过计算计算两个样本![]() 和
和![]() 之间的经验H散度
之间的经验H散度
其中![]() 是指标函数,如果谓词a为真,则为1,否则为0。
是指标函数,如果谓词a为真,则为1,否则为0。
3.2 Proxy Distance
Ben-David et al.(2006)提出,即使通常很难精确计算![]() (例如,当H是X上线性分类器的空间时),我们也可以通过对源和目标示例之间的判别问题运行一个学习算法来很容易地逼近它。为此,我们构造一个新的数据集
(例如,当H是X上线性分类器的空间时),我们也可以通过对源和目标示例之间的判别问题运行一个学习算法来很容易地逼近它。为此,我们构造一个新的数据集
![]()
其中源样例标记为0,目标样例标记为1。然后,对新数据集进行分类器风险训练U接近 (1)式(1)的“min”部分,给出一个泛化误差在源算例和目标算例的判别问题上,用h -散度近似
(1)式(1)的“min”部分,给出一个泛化误差在源算例和目标算例的判别问题上,用h -散度近似
![]()
在Ben-David等人(2006)中,值![]() 称为代理A-distance (PAD)。A-distance定义为
称为代理A-distance (PAD)。A-distance定义为其中A是x的子集,注意,通过选择
![]() ,与
,与![]() 集特征函数所代表的η,定义1的距离和H-divergence是相同的。
集特征函数所代表的η,定义1的距离和H-divergence是相同的。
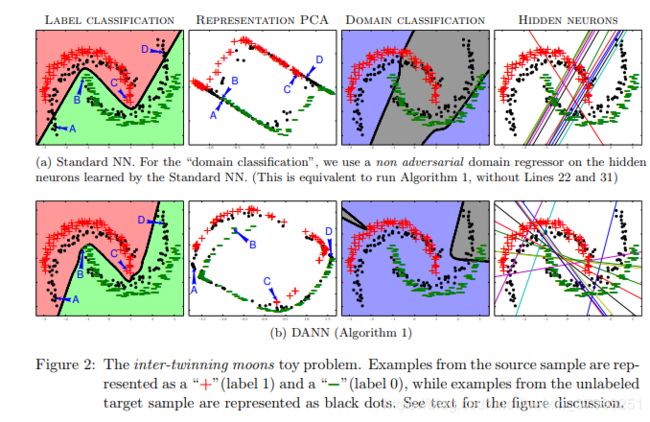
在本文的实验部分,我们采用Glorot等(2011)的方法计算PAD值;Chen等(2012),即,我们训练一个线性支持向量机或更深的MLP分类器对U(公式2)的一个子集,和我们使用分类器获得误差子集在方程(3)的价值。更多的细节和插图的线性支持向量机情况下提供了部分是5.1.5。
3.3 Generalization Bound on the Target Risk
Ben-David et al。(2006年,2010年)也显示,H-divergence![]() 上有界的实证估计
上有界的实证估计![]() 加上一个常数项取决于复杂性的VC维H和样本大小的S和T .通过结合这个结果与类似的绑定源风险上,下面的定理。
加上一个常数项取决于复杂性的VC维H和样本大小的S和T .通过结合这个结果与类似的绑定源风险上,下面的定理。
4. Domain-Adversarial Neural Networks (DANN)
我们方法的一个原始方面是将定理2所展示的思想显式地实现为一个神经网络分类器。也就是说,为了学习一个可以很好地从一个领域推广到另一个领域的模型,我们确保神经网络的内部表示不包含关于输入源(源或目标)来源的区别信息,同时在源(标记)示例上保持低风险。
在本节中,我们详细介绍了将领域自适应组件集成到神经网络的方法。在第4.1节中,我们首先对最简单的情况,即,单层隐层,全连通神经网络。然后,我们将描述如何将该方法推广到任意(深度)网络体系结构。
4.1 Example Case with a Shallow Neural Netwo
让我们首先考虑一个标准的神经网络(NN)结构与一个单一的隐藏层。为了简单起见,我们假设输入空间由m维真实向量构成。因此,![]() 。隐层Gf学习一个函数
。隐层Gf学习一个函数![]() ,该函数将一个示例映射到一个新的d维表示,并由矩阵-向量对
,该函数将一个示例映射到一个新的d维表示,并由矩阵-向量对![]() 参数化,
参数化,
![]()
![]() 。
。
这里我们有![]() 。通过使用softmax函数,向量
。通过使用softmax函数,向量![]() 的每个分量表示神经网络将x赋值给由该分量表示的Y中的类的条件概率。给定一个源示例
的每个分量表示神经网络将x赋值给由该分量表示的Y中的类的条件概率。给定一个源示例![]() ,使用的自然分类损失是正确labe的负对数概率:
,使用的自然分类损失是正确labe的负对数概率:
![]()
然后对神经网络进行训练,在源域上得到如下优化问题
是第i个例子中预测损失的简写符号,R(W, b)是一个可选的正则化器,由超参数加权
·该方法的核心是直接从定义1的h散度出发设计一个域正则化器。为此,我们将隐层Gf(·)(式4)的输出作为神经网络的内部表示。因此,我们表示源样例表示
![]()
类似地,给定目标域中的未标记样本,我们表示相应的表示:
![]()
根据式(1),给出了对称假设类H在样本![]() 之间的经验H散度
之间的经验H散度
假设H是表示空间中超平面的一类。灵感来自代理距离(见3.2节),我们建议估算方程(6)的最小部分由域分类层Gd学习物流回归量Gd: RD[0, 1],由一对vector-scalar参数化![]() ,模型的概率给定输入从源域
,模型的概率给定输入从源域![]() 或目标域
或目标域![]() 。因此,
。因此,
![]()
因此,函数Gd(·)是一个域回归器。我们定义它的损失b
其中di表示第i个示例的二进制变量(域标签),表示习是来自源分布(![]() )还是来自目标分布(
)还是来自目标分布(![]() )。回想一下,对于源分布(di=0)中的示例,在训练时已知相应的标签
)。回想一下,对于源分布(di=0)中的示例,在训练时已知相应的标签![]() 。对于来自目标域的示例,我们不知道训练时的标签,我们希望在测试时预测这些标签。这使我们能够向式(5)的目标添加一个域自适应项,给出如下正则化
。对于来自目标域的示例,我们不知道训练时的标签,我们希望在测试时预测这些标签。这使我们能够向式(5)的目标添加一个域自适应项,给出如下正则化
![]() 。根据定理2,由式(5)和式(8)给出的优化问题实现了源风险RS(·)最小化与散度dH(·,·)之间的权衡。的hyper-parameterλ用于优化学习过程中这两个量之间的权衡。为了便于学习,我们首先注意到,我们可以将式(5)的完整优化目标重写为
。根据定理2,由式(5)和式(8)给出的优化问题实现了源风险RS(·)最小化与散度dH(·,·)之间的权衡。的hyper-parameterλ用于优化学习过程中这两个量之间的权衡。为了便于学习,我们首先注意到,我们可以将式(5)的完整优化目标重写为
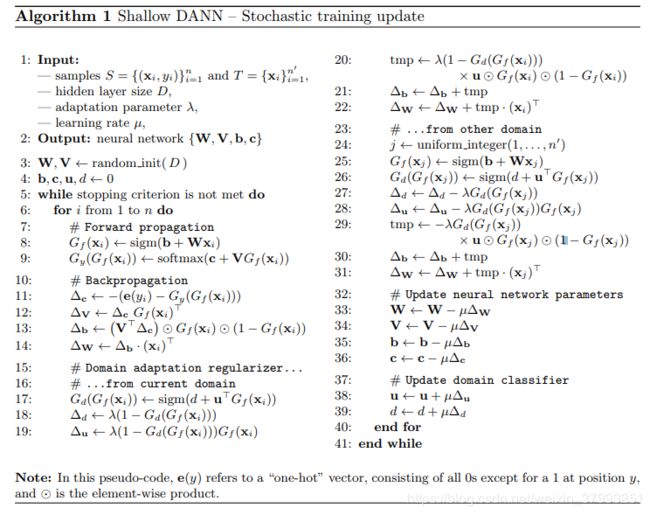
4.2 Generalization to Arbitrary Architectures
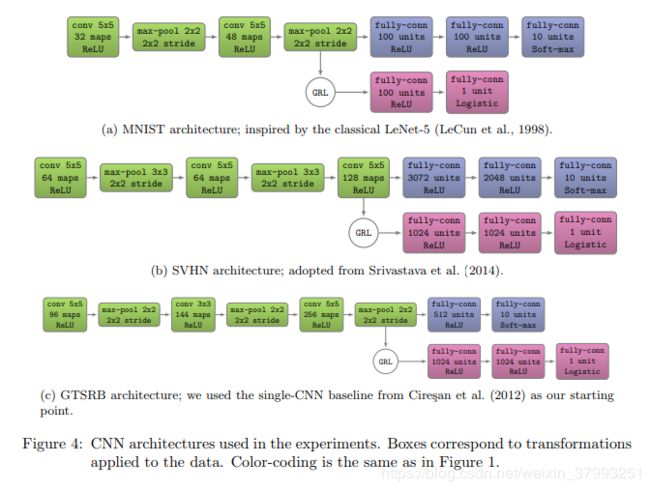
为了便于说明,到目前为止,我们主要关注单个隐藏层DANN的情况。然而,将其推广到其他复杂的体系结构非常简单,这可能更适合手头的数据。例如,深度卷积神经网络作为学习图像鉴别特征的最先进模型而闻名(Krizhevsky et al., 2012)。
训练DAAN然后平行于单层的情况,并
如前所述,由式(11-12)定义的鞍点可以作为后续梯度更新的驻点
 图1:提出的体系结构包括一个深特征提取器(绿色)和一个深标签预测器(蓝色),它们共同构成一个标准的前馈体系结构。在基于反向传播的训练过程中,通过梯度反转层将梯度乘以一定的负常数,将一个域分类器(红色)连接到特征提取器,实现无监督域自适应。否则,训练将按标准进行,并最小化标签预测损失(对于源示例)和域分类损失(对于所有示例)。梯度反转确保了两个域上的特征分布是相似的(对于域分类器来说,尽可能难以区分),从而产生域不变的特征。
图1:提出的体系结构包括一个深特征提取器(绿色)和一个深标签预测器(蓝色),它们共同构成一个标准的前馈体系结构。在基于反向传播的训练过程中,通过梯度反转层将梯度乘以一定的负常数,将一个域分类器(红色)连接到特征提取器,实现无监督域自适应。否则,训练将按标准进行,并最小化标签预测损失(对于源示例)和域分类损失(对于所有示例)。梯度反转确保了两个域上的特征分布是相似的(对于域分类器来说,尽可能难以区分),从而产生域不变的特征。
5. Experiment