大数据【企业级360°全方位用户画像】之USG模型和决策树分类算法
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
在之前的一篇博客《大数据【企业级360°全方位用户画像】之RFM模型和KMeans聚类算法》中,博主为大家带来了KMeans聚类算法的介绍。并在之后,基于不同的模型开发标签,例如RFM,RFE,PSM,都使用到了KMeans算法。
本篇博客,我们来认识一种叫做USG的模型,并为大家简单介绍下关于决策树算法原理和实现。
文章目录
- USG模型引入
- 1.1 AI驱动的电商用户模型
- 1.1.1 用户画像需要的数据
- 1.1.2 如何理解建模过程
- 1.1.3 模型确立过程
- 1.1.4 购物性别的定义
- 1.1.5 建模数据准备过程
- 1.1.6 模型效果分析
- 1.1.7 回顾总结
- 决策树分类算法详解
- 2.1 概念入门
- 2.2 算法原理
- 2.3 快速体验
- 结语
USG模型引入
USG(User Shopping Gender)
1.1 AI驱动的电商用户模型
首先带领大家了解一下,如何通过大数据来确定用户的真实性别。
我们经常谈论的用户精细化运营,到底是什么?简单来讲,就是将网站的每个用户标签化,制作一个属于他自己的网络身份证。然后,运用人员通过身份证来确定活动的投放人群,圈定人群范围,更为精准的用户培养和管理。当然,身份证最基本的信息就是姓名,年龄和性别,与现实不同的是,网络上用户填写的资料不一定完全准确,还需要进行进一步的确认和评估。
确定性别这件事很重要,简单举个栗子,比如店铺想推荐新品的Bra,如果粗糙的全部投放人群或者投放到不准确性别的人群,那后果可想而知了。下面来介绍一下具体的识别思路。

1.1.1 用户画像需要的数据
用户平时在电商网站的购物行为、浏览行为、搜索行为,以及订单购买情况都会被记录在案,探查其消费能力,兴趣等。数据归类后,一般来讲,可以通过三类数据对用户进行分群和定义。
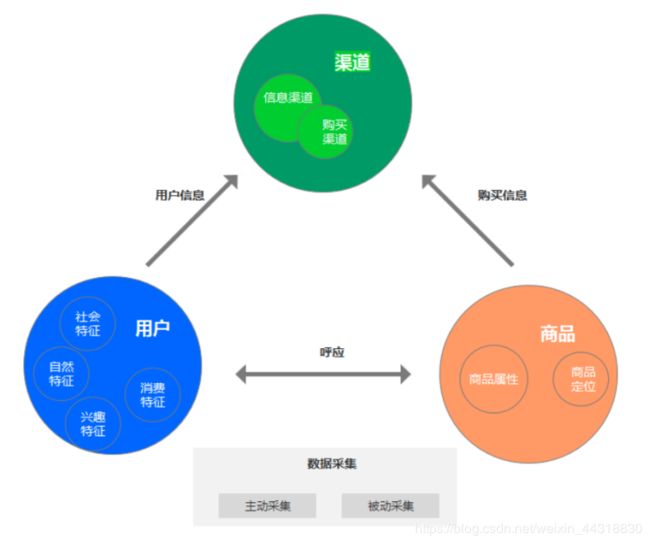
1、用户信息
社会特征:马克思的人性观把人分为社会属性和自然属性。社会特征主要指的是人在社会上的阶级属性,当然也包括服从性、依赖性或者自觉性等,这是人类发展的必然的基本要求。
自然特征:也可以说成是人的生物性,通常来讲可以是食欲,物欲或者购买欲,自我保存能力。但不同人会有不同的自然特征,比如学习能力和逻辑思维等。
兴趣特征:对于电商来讲,主要是对某件商品,某个品牌或者品类的兴趣程度,如加购、浏览、收藏、搜索和下单行为。
消费特征:消费能力的评估,消费倾向的评估,能够判断用户的消费层级,是高消费力还是低消费力。
2、商品
商品属性:基本信息,品类,颜色尺码型号等。
商品定位:商品层级,是否为高中低端,商品类型倾向于哪类客户,区域或者其他的特征。最后通过以上的信息来获取用户信息,判断其具体的画像特征,然后得到类似于这样子的网络身份证。

通常,拿到数据后,我们会将每个环节进行拆解,落实到具体的行动策略上。大体可以根据以下流程进行模型的预估:

业务目标: 精准投放,针对已有产品,寻找某性别偏好的精准人群进行广告投放。
技术目标: 对用户购物性别识别:男性,女性,中性
解决思路:选择一种分类算法,建立机器学习算法模型,对模型进行应用
线上投放:对得到的数据进行小范围内的测试投放,初期不宜过大扩大投放范围
效果分析:对投放的用户进行数据分析,评估数据的准确性。若不够完美,则需要重新建模和测试。
1.1.2 如何理解建模过程
重点来了,虽然能够通过用户的行为、购买和兴趣数据,了解用户的基本信息,但是仍然不清楚如何建模?用什么语言建模?其实,购物性别的区分使用的是spark,但是机器学习算法也有很多分类,包含逻辑回归,线性支持向量机,朴素贝叶斯模型和决策树。那么,又该如何选择呢?其中,决策树的优点较多,主要是其变量处理灵活,不要求相互独立。可处理大维度的数据,不用预先对模型的特征有所了解。对于表达复杂的非线性模式和特征的相互关系,模型相对容易理解和解释。看起来决策树的方法最适合区分性别特征了,所以决定用决策树进行尝试。
什么是决策树?简单来讲,是通过训练数据来构建一棵用于分类的树,从而对未知数据进行高效分类。可以从下面的图了解决策树的工作原理。
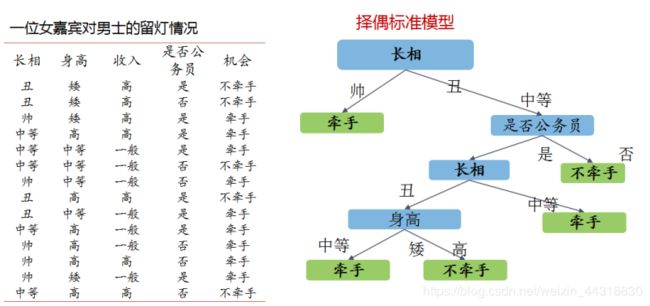
构造决策树的步骤为:
通过训练数据来构建一棵用于分类的树,从而对未知数据进行高效分类。
以上步骤中,能够得出一个结论,在构建决策树的过程中,最重要的是如何找到最好的分割点。决策树值得注意的问题是过拟合问题,整个算法必须解决「如何停止分割」和「如何选择分割」两个关键问题。
最简单的做法就是设定树的深度或枝叶的最少样本量。但是,过少的样本量又不具有代表性,所以一般情况,可以使用交叉验证的方法。交叉验证就是可以使用一部分数据用于模型的训练,另一部分数据可以用来评估模型的性能。业内常用的划分方法是讲样本进行50/50分,60/40分或者80/20分。
1.1.3 模型确立过程
在建模前期,首要考虑的事情就是先确定指标,以及对样本的定义。购物性别指的是什么?通过哪些数据来确定购物性别,样本的准确性,如何验证数据的可信度等。
1.1.4 购物性别的定义
先看下图,具体的逻辑可从图中查看。一般来讲,用户填写的资料不一定真实,我们对他/她的性别数据持怀疑态度,所以,就需要其他数据进行辅助证明其性别。
订单数据能够真实反映用户的购买心态,预测购买行为,并且能够通过购买商品的所属类别,判断用户的购买倾向,最后得到性别特征类目。不过本文就不展开探讨甄别特征类目的区分方法了。

根据数据结果,最终,确认了购物性别的定义。分为:
购物性别男:N月购买的男性特征类目子下单数> N月购买的女性特征类目子下单数
购物性别女:N月购买的男性特征类目子下单数> N月购买的女性特征类目子下单数
购物性别中性:未下单男女特征类目
N需要具体根据业务场景来定。
1.1.5 建模数据准备过程
本节是具体的操作过程,模型的实操阶段。一般来讲,不同模型的训练其实大体雷同。从技术上来讲,各家算法大多使用sparkmllib,不同点是所运算的模型都是针对于场景来定的。

在全部样本中,取80%的数据用于训练模型
在全部样本中,取20%的数据用户数据测试
这种方式可以更好的根据数据的规模,提高模型的准确性
1.1.6 模型效果分析
行业内当前采用数据挖掘、机器学习和推荐系统中的评测指标—准确率(Precision)、召回率(Recall),准确率是应用最广的数据指标,也很清晰易懂,以男性为例。

准确率=命中的男性用户数量/所有预测男性数量,一般来讲,准确率可以评估模型的质量,他是很直观的数据评价,但并不是说准确度越高,算法越好。
召回率=命中的男性用户数量/所有男性数量,反映了被正确判定的正例占总的正例的比重。模型建立完后,需根据模型的结果与预期的对比,进行调优。
1.1.7 回顾总结
购物性别定义对于用户精准营销十分重要,疑难杂症,对症下药,才能出现更好的疗效。
对于新手来说,初期一定是对模型性能及效果分析不是很熟练,可先用小数据量进行测试, 走通全流程建表要规范,方便后期批量删除,因为建模是个反复的过程。
根据各类参数的评估结果,以及人工经验选定的模型参数,建立模型。值得注意的是,决策树的深度不要过深,以防止过拟合的问题。
决策树分类算法详解
2.1 概念入门
在讲解其算法之前,我们需要掌握其常见的几个概念。
- 数据
“承载了信息的东西”才是数据。
- 信息
信息是用来消除随机不定性的东西。
- 信息量
这里涉及到两个计算公式,可以分别通过事件发生的数量和概率来获得信息量。计算出的信息量单位都是bit,也就是比特。
![]()
m 指的是可能的数量(几种可能性), I就是信息量。

另一个公式
![]()
P指的是事件的概率

- 信息熵
信息的不确定性可以用熵来表示,即信息熵是信息杂乱程度的描述。
越不确定,信息熵越大,越确定,信息熵越小
计算信息熵的公式也有两个

其中pi概率,Logpi 是信息量。
另外一个公式是:

信息熵的计算公式为:所有的事件发生的概率 * 事件的信息量的总和

2个球队比赛的信息熵

32个球队比赛的信息熵

- 小结

- 什么是信息增益??

我们计算信息增益的大致过程如下:

上图中已经透露出,某个固定值与信息熵的差值便是这个位置的信息增益。
但是这个固定值是怎么计算出来的呢?
原来这个固定值指的是不参考任何特征,直接根据结果计算信息熵(整体的信息熵)。在下边有一个决策树的实例中会体现出计算的过程,大家可以留意下。
再用这个固定值值 - 某一特征信息熵便得到了信息增益。

信息增益越大,数据越纯粹,这个判断,特征的位置越靠前。
2.2 算法原理
先让我们来看这样几篇报道,对于决策树有一个大概的认知。


决策树是最经典的机器学习模型之一。它的预测结果容易理解, 易于向业务部门解释。预测速度快,可以处理类别型数据和连续型数据。在机器学习的数据挖掘类求职面试中,决策树是面试官最喜欢的面试题之一。


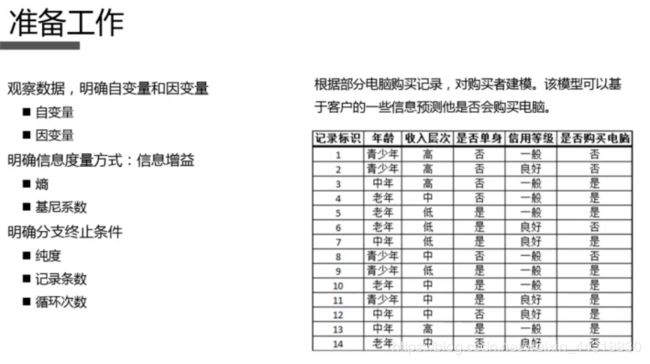







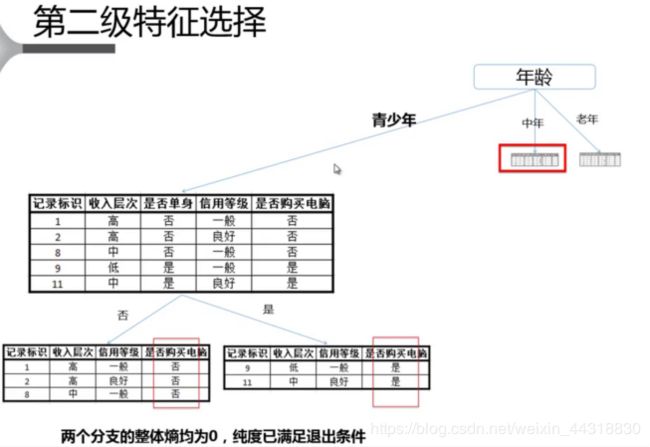





2.3 快速体验
之前我们在初次介绍KMeans聚类算法的时候,在最后利用该算法对鸢尾花数据集进行了聚类分析。看了本篇博客,学习了决策树分类算法,那我们也重拾起曾经的数据集,用Java来体验一波“决策树”的快感。
需要注意的是,我们本次读取的数据集iris_tree.csv如下所示,想要数据集的朋友可以私信获取。

具体代码:
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorAssembler}
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/*
* @Author: Alice菌
* @Date: 2020/7/2 15:03
* @Description:
用决策树对鸢尾花数据进行分类
*/
object IrisTree {
def main(args: Array[String]): Unit = {
// 监督学习如何实现
// 训练集,测试集如何使用
// 成功率(准确率)
// 1、初始化SparkSession
val spark: SparkSession = SparkSession.builder().appName("IrisTree").master("local[*]").getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
// 导入隐式转换
import spark.implicits._
// 2、读取数据
val dataSource: DataFrame = spark.read
.csv("file:///E:\\iris_tree.csv")
.toDF("Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width", "Species")
.select('Sepal_Length cast DoubleType, //字符串类型无法直接计算,需要将其传为doubleType
'Sepal_Width cast DoubleType,
'Petal_Length cast DoubleType,
'Petal_Width cast DoubleType,
'Species
)
//展示一些数据
dataSource.show()
//+------------+-----------+------------+-----------+-----------+
//|Sepal_Length|Sepal_Width|Petal_Length|Petal_Width| Species|
//+------------+-----------+------------+-----------+-----------+
//| 5.1| 3.5| 1.4| 0.2|Iris-setosa|
//| 4.9| 3.0| 1.4| 0.2|Iris-setosa|
//| 4.7| 3.2| 1.3| 0.2|Iris-setosa|
//| 4.6| 3.1| 1.5| 0.2|Iris-setosa|
//| 5.0| 3.6| 1.4| 0.2|Iris-setosa|
//| 5.4| 3.9| 1.7| 0.4|Iris-setosa|
//| 4.6| 3.4| 1.4| 0.3|Iris-setosa|
// 3、标签处理(数据不能直接使用,需要将最终的标签处理成数字。)
val SpeciesToLabel: StringIndexerModel = new StringIndexer()
.setInputCol("Species")
.setOutputCol("label")
.fit(dataSource)
//4、将特征数据处理成向量
val features: VectorAssembler = new VectorAssembler()
.setInputCols(Array("Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width"))
.setOutputCol("features")
//5、初始化决策树,进行分类
val decisionTree: DecisionTreeClassifier = new DecisionTreeClassifier() //创建决策树对象
.setFeaturesCol("features") //设置特征列
.setPredictionCol("prediction") //设置预测后的列名
.setMaxDepth(4) //设置深度
//------查看----------
//6、构建一个 PipeLine 将 第3 4 5 步骤连起来
val pipeline: Pipeline = new Pipeline().setStages(Array(SpeciesToLabel,features,decisionTree))
//7、将原始数据拆分成训练集和测试集
//将数据切分成80%的训练集和20%的测试集
val Array(trainDatas,testDatas): Array[Dataset[Row]] = dataSource.randomSplit(Array(0.8,0.2))
//8、使用 PipLine 对训练集进行训练,使用测试集进行测试
//使用训练数据进行训练,得到一个模型
val model: PipelineModel = pipeline.fit(trainDatas)
//使用测试集进行测试
val testDF: DataFrame = model.transform(testDatas)
testDF.show()
//+------------+-----------+------------+-----------+---------------+-----+-----------------+--------------+-------------+----------+
//|Sepal_Length|Sepal_Width|Petal_Length|Petal_Width| Species|label| features| rawPrediction| probability|prediction|
//+------------+-----------+------------+-----------+---------------+-----+-----------------+--------------+-------------+----------+
//| 4.3| 3.0| 1.1| 0.1| Iris-setosa| 0.0|[4.3,3.0,1.1,0.1]|[38.0,0.0,0.0]|[1.0,0.0,0.0]| 0.0|
//| 4.4| 3.2| 1.3| 0.2| Iris-setosa| 0.0|[4.4,3.2,1.3,0.2]|[38.0,0.0,0.0]|[1.0,0.0,0.0]| 0.0|
//| 4.7| 3.2| 1.3| 0.2| Iris-setosa| 0.0|[4.7,3.2,1.3,0.2]|[38.0,0.0,0.0]|[1.0,0.0,0.0]| 0.0|
//| 4.9| 3.0| 1.4| 0.2| Iris-setosa| 0.0|[4.9,3.0,1.4,0.2]|[38.0,0.0,0.0]|[1.0,0.0,0.0]| 0.0|
//| 5.0| 2.0| 3.5| 1.0|Iris-versicolor| 1.0|[5.0,2.0,3.5,1.0]|[0.0,35.0,0.0]|[0.0,1.0,0.0]| 1.0|
//| 5.0| 3.2| 1.2| 0.2| Iris-setosa| 0.0|[5.0,3.2,1.2,0.2]|[38.0,0.0,0.0]|[1.0,0.0,0.0]| 0.0|
//| 5.1| 3.4| 1.5| 0.2| Iris-setosa| 0.0|[5.1,3.4,1.5,0.2]|[38.0,0.0,0.0]|[1.0,0.0,0.0]| 0.0|
//9、查看分类的成功的百分比
val evaluator: MulticlassClassificationEvaluator = new MulticlassClassificationEvaluator() //多类别评估器
.setLabelCol("label") //设置原始数据中自带的label
.setPredictionCol("prediction") //设置根据数据计算出来的结果“prediction”
val Score: Double = evaluator.evaluate(testDF) //将测试的数据集DF中自带的结果与计算出来的结果进行对比得到最终分数
println(">>>>>>>>>>>>>>>>>>>>>>> "+Score)
//>>>>>>>>>>>>>>>>>>>>>>> 0.9669208211143695
val decisionTreeClassificationModel: DecisionTreeClassificationModel = model.stages(2).asInstanceOf[DecisionTreeClassificationModel]
// 输出决策树
println(decisionTreeClassificationModel.toDebugString)
//DecisionTreeClassificationModel (uid=dtc_d936bd9c91b5) of depth 4 with 13 nodes
// If (feature 2 <= 1.9)
// Predict: 0.0
// Else (feature 2 > 1.9)
// If (feature 2 <= 4.7)
// If (feature 3 <= 1.6)
// Predict: 1.0
// Else (feature 3 > 1.6)
// Predict: 2.0
// Else (feature 2 > 4.7)
// If (feature 2 <= 4.9)
// If (feature 3 <= 1.5)
// Predict: 1.0
// Else (feature 3 > 1.5)
// Predict: 2.0
// Else (feature 2 > 4.9)
// If (feature 3 <= 1.6)
// Predict: 2.0
// Else (feature 3 > 1.6)
// Predict: 2.0
}
}
结语
本篇博客博主地简单为大家介绍了一下用户画像项目中的USG模型和机器学习中的决策树算法。后续会借助决策树,为大家带来如何在用户画像中开发用户购物性别的标签,敬请期待
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
