注:本文所用时间为14量车的总时间单位为秒。
表结构及名称

image.png
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
val warehouseLocation = "spark-warehouse"
val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
import spark.implicits._
import spark.sql
一、对数据的简单分析
1.总数据量的统计
sql("use dbtac")
sql("select count(*) as trajectory_number from trajectory").show

image.png
2.查询有多少量车
sql("select count(distinct vme_id) as car_number from trajectory").show

image.png
二、停歇点识别算法实现
1.统计每辆车平均每天停车点数
根据大部分文献停车的上限速度可以设置为人步行的速度约为1m/s。
//统计每辆车平均每天停车点数
val evey_car_stop_time=sql("select vme_id, count(*)*2/3600/count(distinct to_date(gps_time) ) as stop_time from trajectory where speed<1 group by vme_id order by vme_id " )
//保存数据到本地
evey_car_stop_time.repartition(1).write.format("csv").save("file:/home/hadoop/mydata/evey_car_stop_time")

image.png
2.具体分析车辆编号为s90110009的车辆停息点分布
val s9_every_day_stop_time=sql("select to_date(gps_time) as gps_t, count(*)*2/3600 as num_trajectory from trajectory where vme_id='S901100009' and speed<1 group by to_date(gps_time) order by to_date(gps_time) ")
//保存数据到本地
s9_every_day_stop_time.repartition(1).write.format("csv").save("file:/home/hadoop/mydata/s9_every_day_stop_time")
3.计算疑似停车点与上一个点之间的距离
假定第一个速度小于1的轨迹点为停留点p,计算p与第二个点的距离,如果距离小于距离阈值则判定为停留点,并赋值给p,依次计算点p与下一个点的距离,直到遍历完所有点
三、农机运营分析
这里的运营是指除了停运和停车熄火之外的其他状态,包括行驶、停车检查、田间作业等状态。运营时间和运营里程反映农机的使用率以及农机手的工作强度。
5个月农机作业轨迹数量的部分展示(统计10月份每天的作业车辆和轨迹个数)
val oct_stat = sql(" select distinct to_date(gps_time) as gps_t, count(gps_time) as num_trajectory ,count(distinct vme_id) as num_car, avg(speed) avg_speed from trajectory where month(gps_time)=10 group by to_date(gps_time) order by gps_t")
//保存数据到本地
oct_stat.repartition(1).write.mode("overwrite").format("csv").save("file:/home/hadoop/mydata/oct_stat")
1.运营时间与距离分析
以为单位进行分析日均运营时间分析(月均运营时间是指该月运营农机的运营时间总和与当日运营出租车的总和之比)
val all_operation= sql(" select a.gps_t, day(a.gps_t) as day,a.num_trajectory, a.num_car, a.avg_speed, a.num_trajectory*2/a.num_car/3600 as avg_day_operation_time, a.avg_speed* a.num_trajectory*2/a.num_car/1000 as avg_day_operation_distance from (select distinct to_date(gps_time) as gps_t, count(gps_time) as num_trajectory ,count(distinct vme_id) as num_car, avg(speed) avg_speed from trajectory where group by to_date(gps_time) order by gps_t) as a")
//保存数据到本地
oct_operation.repartition(1).write.format("csv").save("file:/home/hadoop/mydata/all_operation")

image.png
2.农机作业分析
农机作业分析是指农机作业深度达到标准深度为300mm
val all_work = sql("select a.gps_t, day(a.gps_t) as day, a.num_trajectory, a.num_car, a.avg_speed, a.num_trajectory*2/a.num_car/3600 as avg_day_work_time, a.avg_speed* a.num_trajectory*2/a.num_car/1000 as avg_day_work_distance from (select distinct to_date(gps_time) as gps_t, count(gps_time) as num_trajectory ,count(distinct vme_id) as num_car, avg(speed) avg_speed from trajectory where work_deep>300 group by to_date(gps_time) order by gps_t) as a")
//保存数据到本地
all_work.repartition(1).write.format("csv").save("file:/home/hadoop/mydata/all_work")

image.png
3.单个农机每日作业分析
每天有多少车辆作业
val every_work = sql("select a.car_id, a.gps_t, month(a.gps_t) as month, a.num_trajectory, a.num_car, a.avg_speed, a.num_trajectory*2/a.num_car/3600 as avg_day_work_time, a.avg_speed* a.num_trajectory*2/a.num_car/1000 as avg_day_work_distance from (select distinct to_date(gps_time) as gps_t, count(gps_time) as num_trajectory ,count(distinct vme_id) as num_car, vme_id as car_id,avg(speed) avg_speed from trajectory where work_deep>300 and speed>1 group by to_date(gps_time), vme_id order by gps_t) as a")
//保存数据到本地
every_work.repartition(1).write.format("csv").save("file:/home/hadoop/mydata/every_work")
4.单个农机每日运营分析
每天有多少车辆作业
val every_operation = sql("select a.car_id, a.gps_t, month(a.gps_t) as month, a.num_trajectory, a.num_car, a.avg_speed, a.num_trajectory*2/a.num_car/3600 as avg_day_work_time, a.avg_speed* a.num_trajectory*2/a.num_car/1000 as avg_day_work_distance from (select distinct to_date(gps_time) as gps_t, count(gps_time) as num_trajectory ,count(distinct vme_id) as num_car, vme_id as car_id,avg(speed) avg_speed from trajectory where speed>1 group by to_date(gps_time), vme_id order by gps_t) as a")
//保存数据到本地
every_operation.repartition(1).write.format("csv").save("file:/home/hadoop/mydata/every_operation")
4.查询速度
横坐标为速度, 纵坐标为轨迹点数目,速度为车辆的瞬时速度。
5.查询作业深度
select work_deep, count(*) from trajectory group by work_deep;

image.png
6.其他

image.png
1表示速度为0(蓝色)和速度非零的作业时间
2表示作业深度小于50(蓝色)和作业深度大于50的作业时间
从途中可以看出非作业中很大一部分时间中农机处于停息状态约占22%.
深度为300mm的轨迹点出现剧增,原因分析
sql("select vme_id, count(work_deep) ,avg(speed) from trajectory where work_deep = 300 group by vme_id order by count(work_deep) ").show
三、基于时间的农机轨迹分析
1.作业月份分析
select month(gps_time, count(*)) from trajectory group by month(gps_time);```

2.不同农机运营时间分析
select vme_id ,count(*) from trajectory group by vme_id ; ```
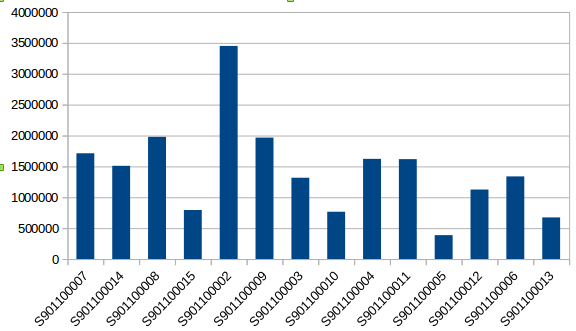
image.png
3.不同农机作业时间分析
select vme_id ,count(*) from trajectory where work_deep>50 group by vme_id ;

image.png
4.不同时间段作业分析

image.png