PTA 乙级难点(全部)
PTA 乙级难点题目列表
- 1002 写出这个数(字符串)
- 1003 我要通过!
- 1004 成绩排名
- 1005 继续(3n+1)猜想
- 1008 数组元素循环右移问题
- 1009 说反话
- 1010 一元多项式求导
- 1012 数字分类
- 1015 德才论
- 1017 A除以B
- 1023 组个最小数
- 1024 科学计数法
- 1025 反转链表
- 1026 程序运行时间
- 1027 打印沙漏
- 1028 人口普查
- 1029 旧键盘
- 1030 完美数列
- 1033 旧键盘打字
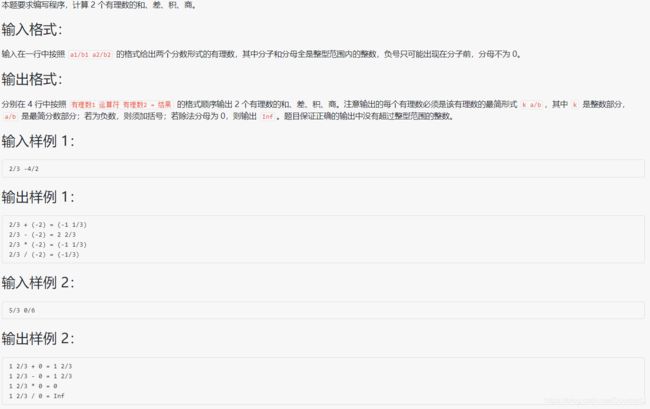
- 1034 有理数四则运算
- 1035 插入与归并
- 1039 到底买不买
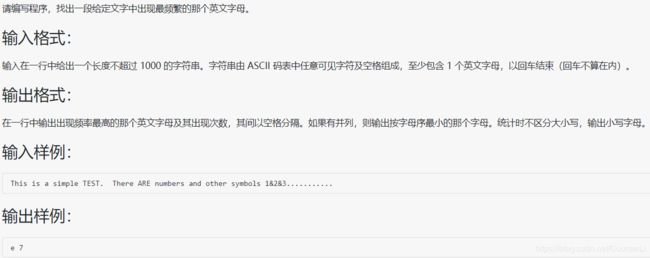
- 1042 字符统计
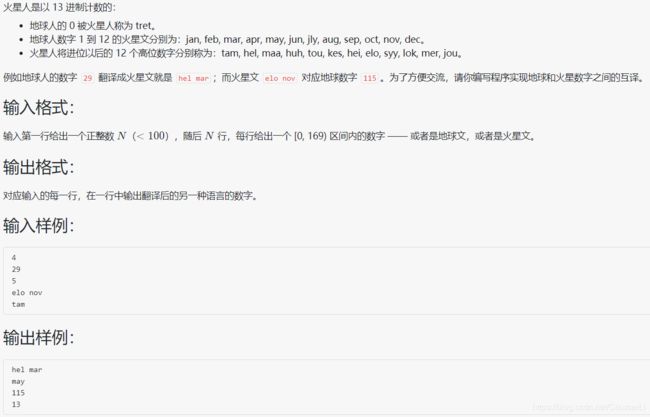
- 1044 火星数字
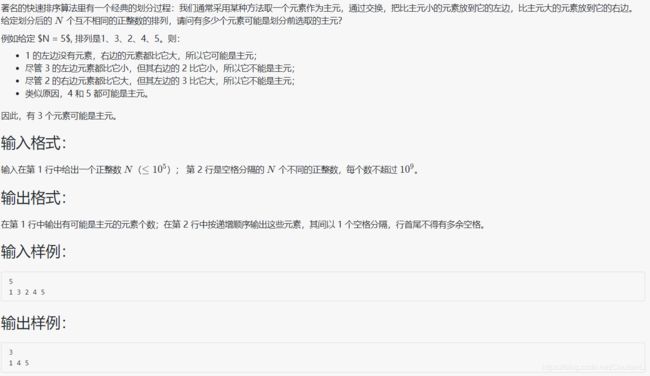
- 1045 快速排序
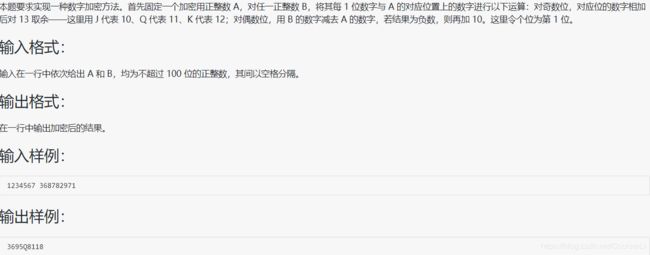
- 1048 数字加密
- 1049 数列的片段和
- 1050 螺旋矩阵
- 1051 复数乘法
- 1052 卖个萌
- 1054 求平均值
- 1055 集体照
- 1056 组合数的和
- 1058 选择题
- 1059 C语言竞赛
- 1060 爱丁顿数
- 1064 朋友数
- 1067 试密码
- 1068 万绿丛中一点红
- 1069 微博转发抽奖
- 1070 结绳
- 1073 多选题常见计分法
- 1074 宇宙无敌加法器
- 1075 链表元素分类
- 1076 Wifi密码
- 1080 MOOC期终成绩
- 1084 外观数列
- 1085 PAT单位排行
- 1086 就不告诉你
- 1089 狼人杀-简单版
- 1090 危险品装箱
- 1091 N-自守数
- 1093 字符串A+B
- 1095 解码PAT准考证
1002 写出这个数(字符串)
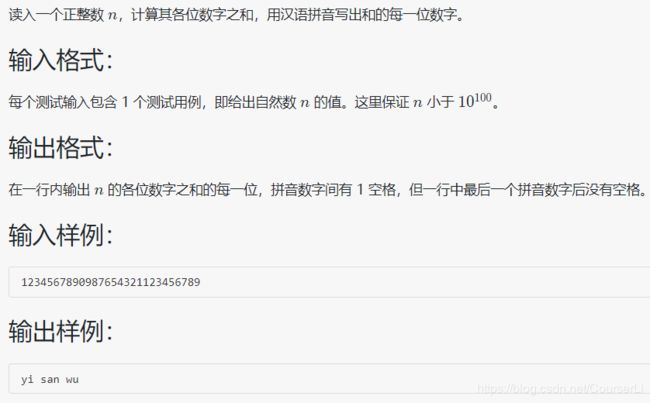
#include1003 我要通过!
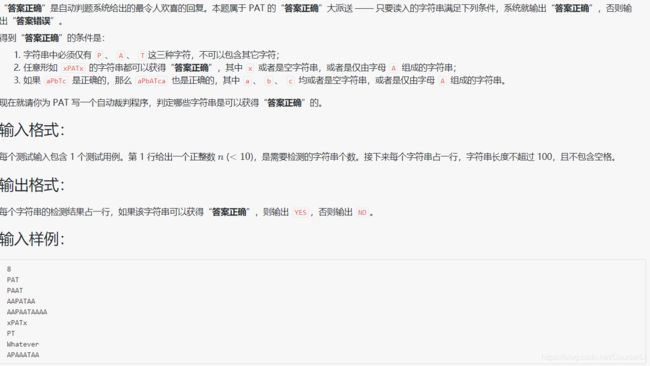

#include分析题目三个通过条件可知:字符串中不能出现P、A、T之外的字符;PT之间只有一个A时(PAT),前后可以加上相同个数的A;PT中每多一个A(>2),后面加上前面个数个A,
统计字符串中P、T前中后A的个数判断即可
1004 成绩排名
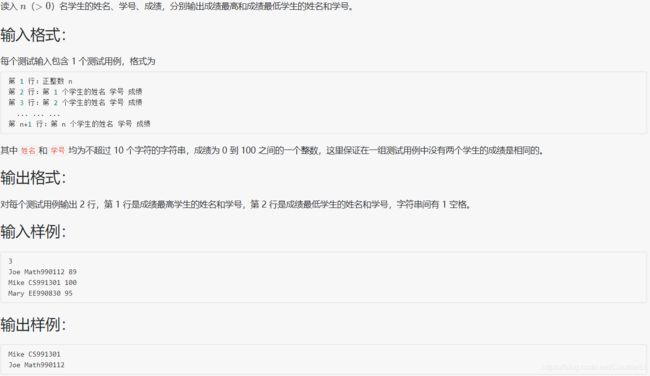
#include注意 typedef 的用法,还有 max min new 不可以作为变量名使用,再提醒一下:结构体之间是可以赋值的
1005 继续(3n+1)猜想
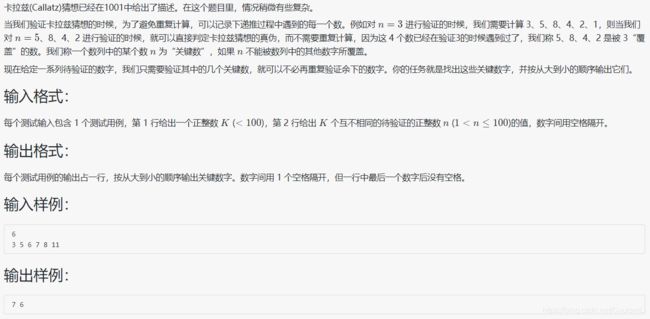
#include题目意思是第一个直接执行3n+1猜想,并记录过程中的每个数,注意是过程数;后面的每个数先判断是否已经记录过,记录过就直接跳过(记录过后面算就没意义了),没记录过就执行3n+1猜想并记录过程数
1008 数组元素循环右移问题
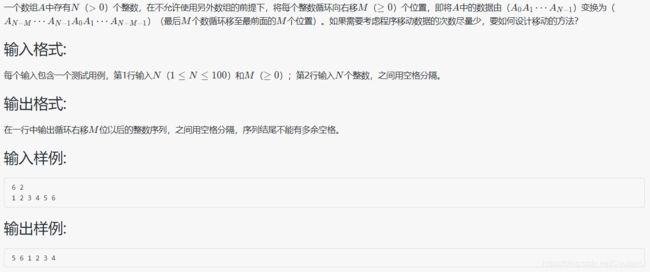
#include题目本身不难,但要关注本代码的小技巧
1009 说反话
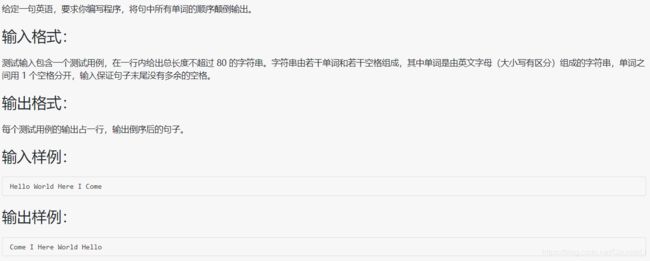
#include特别注意:输出字符串时,程序读取到 '\0' 后面都不会输出,如 "123\0456",只打印 123
1010 一元多项式求导
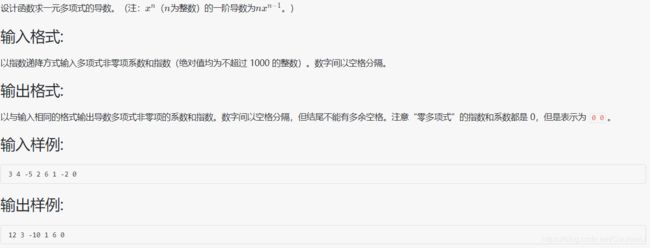
#include可以利用规律来相乘和减 1,比如例题中 3 * 4 = 12 ,- 5 * 2 = -10 ,6 * 1 = 6 ,- 2 * 0 = 0,这是对应的系数,4 - 1 = 3 ,2 - 1 = 1 ,1 - 1 = 0,这是指数,最后一个是常数 -2,指数不做运算,这是要注意的
另外本代码的 flag 有两个用处,一是解决题目要求的:结尾不能有多余空格,二是满足题目:“零多项式” 的指数和系数都是 0,但是表示为 0 0
1012 数字分类
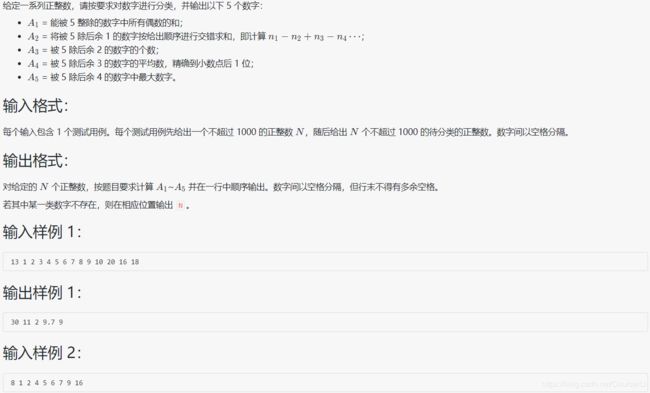

#include本代码是每输入一个数就判断一个数,会比较方便和省时
补充关于浮点数精度的知识点
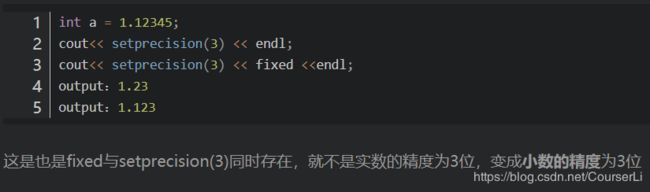
1015 德才论

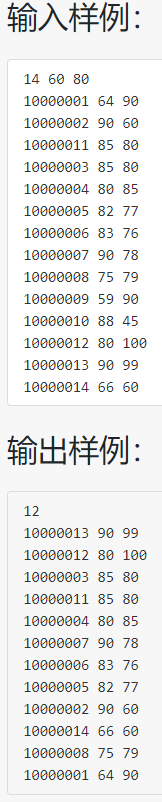
#include 本代码总体是:先分类,再排序
题目要求:考生按输入中说明的规则从高到低排序,当某类考生中有多人总分相同时,按其德分降序排列,若德分也并列,则按准考证号的升序输出
补充一点:strcmp 的用处如下
基本形式为 strcmp(str1,str2)
若str1=str2,则返回零
若str1<str2,则返回负数
若str1>str2,则返回正数
(即:两个字符串自左向右逐个字符相比(按ASCII值大小相比较),直到出现不同的字符或遇'\0'为止)
故代码中的 strcmp(a.id, b.id) < 0 代表升序(从小到大),记住这种表达方式~
1017 A除以B
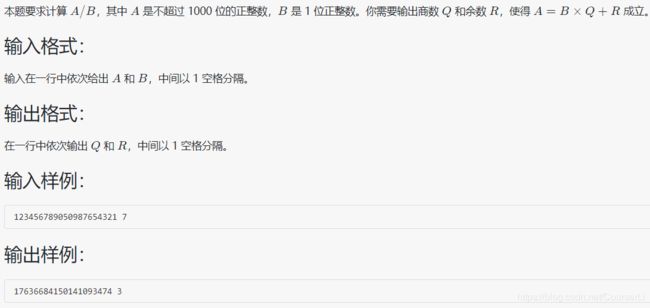
#include 代码内容是:模拟手动除法的过程,每次用第一位去除以B,如果得到的商不是0就输出,否则就 * 10 + 下一位,直到最后的数为余数
注意:存在除数为 0 的情况
1023 组个最小数
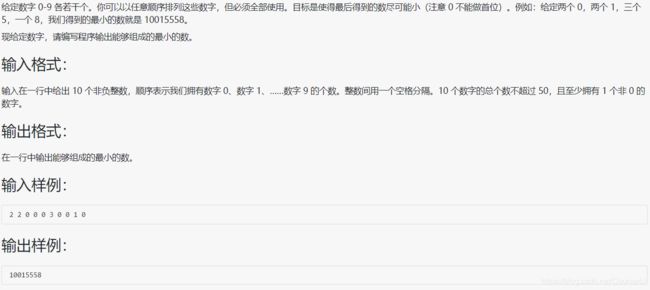
#include也是用到了小技巧:先确定开头,再往后从小到大添加数字
1024 科学计数法
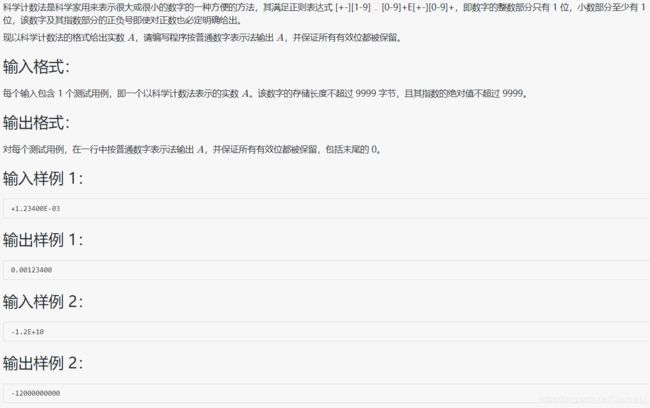
#include本题难点就在于条件
代码顺序是:先打出指数是0的特例(省去后面麻烦),再判断指数为正与负并写出各个结果
当指数为正数时,可以直接略过原来的 .号只考虑如何加新的 . 号,其中 (i==exp+2) && (pos-3 != exp) 可以打个草稿分析(前者+2是加上了符号和 . 号)(后者-3是减去了符号和 . 号和 E 号)
(注意题目要求:正数不用输出+号、并保证所有有效位都被保留,包括末尾的 0)
1025 反转链表
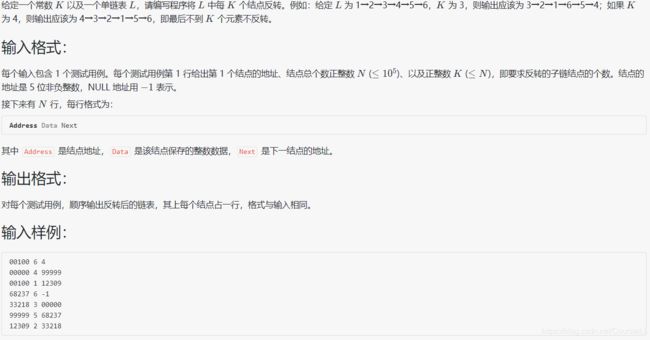

#include主要步骤:先对原列表排序,再反转
注意:应该考虑输入样例中有不在链表中的结点的情况,所以用个sum计数
补充:new和delete的用法回顾 、reverse()函数的第二个参数是数组最后一个元素的下一个地址
1026 程序运行时间
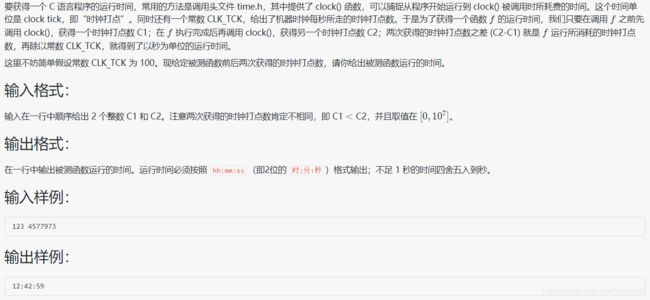
#include题目本身不难,但注意代码的技巧性,本题运用了四舍五入的简易版
1027 打印沙漏
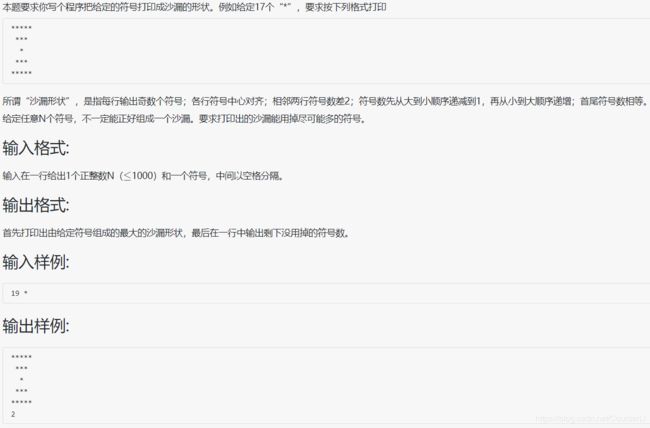
#include分析:
明确了 整个沙漏的字符数(2k*k-1)与 半个的完整的沙漏层数(k)与 每一层沙漏个数(2k-1) 的关系即可
整个沙漏的形状为: 2k-1 , 2k-3 , … ,5 ,3, 1 , 3, 5, … ,2k-3 , 2k-1 ( k 代表半个的完整的沙漏层数)
整个沙漏的字符数为 2k*k -1 (用到了等差数列求和)
补充:对于输入的 n ,其实也只需要判断(n+1)/2是不是开方数,但是不管它是不是开方数,开方的结果都是 k
等差数列求和回顾
1028 人口普查
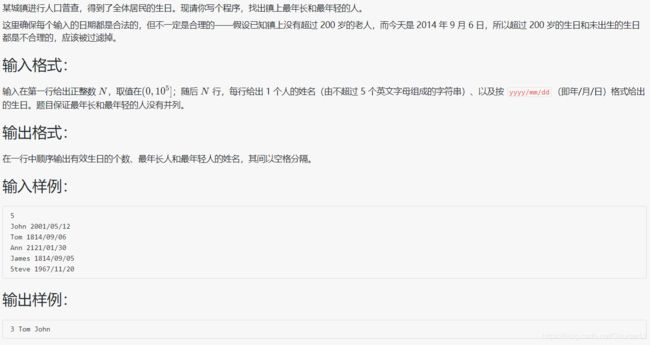
#include注意题目:这里确保每个输入的日期都是合法的,但不一定是合理的
分析:利用 string 的特性,使字符串间可以直接比较大小,然后求最值即最年轻的和最年长的,最后注意一个坑点,可能会有0个符合的年份,则只输出0
1029 旧键盘
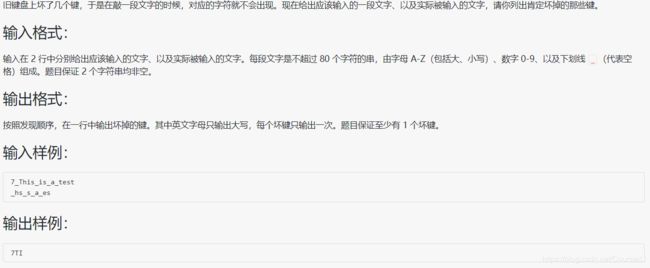
#include 题目和代码本身不难,但要记住这种判断输出并记录 的方法
1030 完美数列
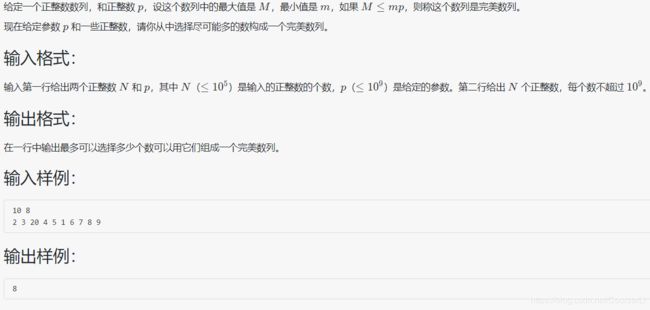
#include 有点阅读理解的味道,题目的意思:最大与最小相除小于p,求如何使数列中间的元素更多
分析:从最小数开始,不断增大,找出 与 最大数开始往后减小(用二分法)的最下标大差值
补充:就当回顾二分法的适用题目与方法
1033 旧键盘打字
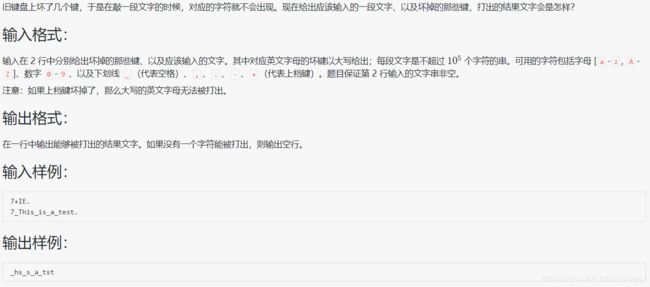
#include题目和代码本身简单,但需要掌握两个函数:isupper() 和 toupper()
isupper(c): 当参数c为大写英文字母(A-Z)时,返回 非0 值,否则返回 0
toupper(c): 能将字符c转换为大写英文字母
两者都包含于头文件
1034 有理数四则运算
#include 分析:func(m, n)的作用是对 m / n 的分数进行化简
在 func()函数中,先看 m 和 n 里面是否有0(m * n 是否等于0),再看 flag,flag=true表示 m 和 n 异号,那么后面要添加”(-“和”)”,再将 m和 n 取绝对值,然后计算 x = m/n,x 表示可提取的整数部分(带分数),接着根据 m % n 是否等于 0 的结果判断后面还有没有小分数,若有小分数,然后求 m 和 n 的最大公约数 t ,让 m 和 n 都除以 t 进行化简,最后输出即可
补充:判断 m 和 n 是否异号千万不要写成判断 m * n 是否小于 0,因为 m * n 的结果可能超过了 long long int 的长度,导致溢出大于 0,如果这样写的话会有一个测试点无法通过
1035 插入与归并
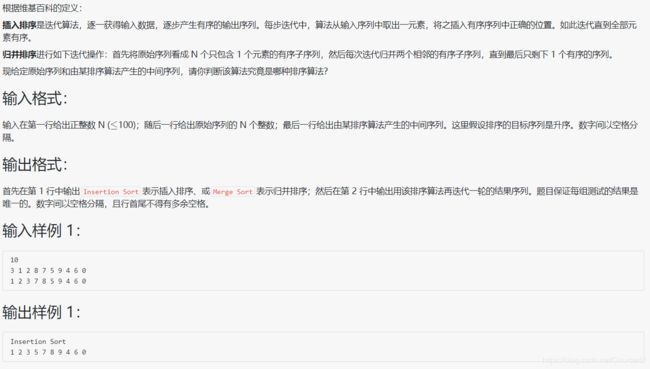

#include 先简单回顾一下插入排序(图1)和归并排序(图2)
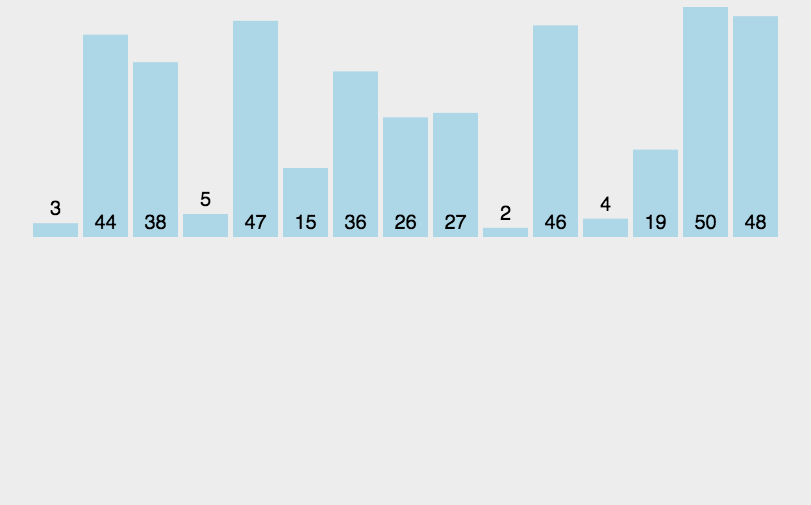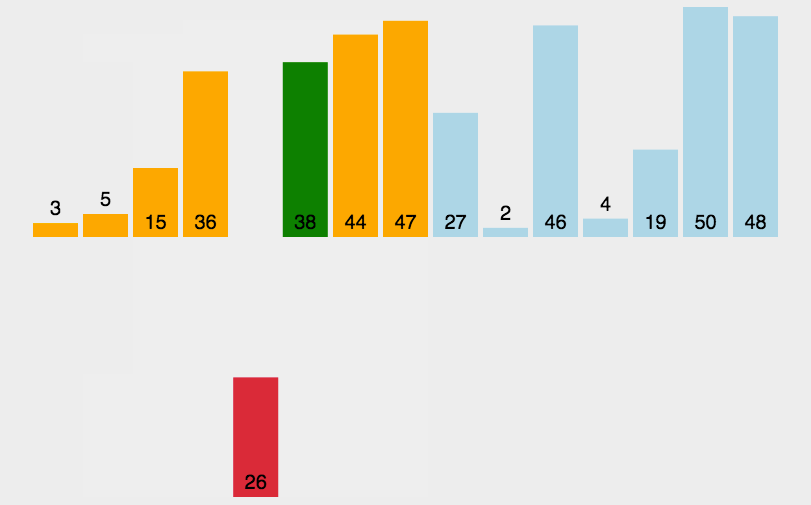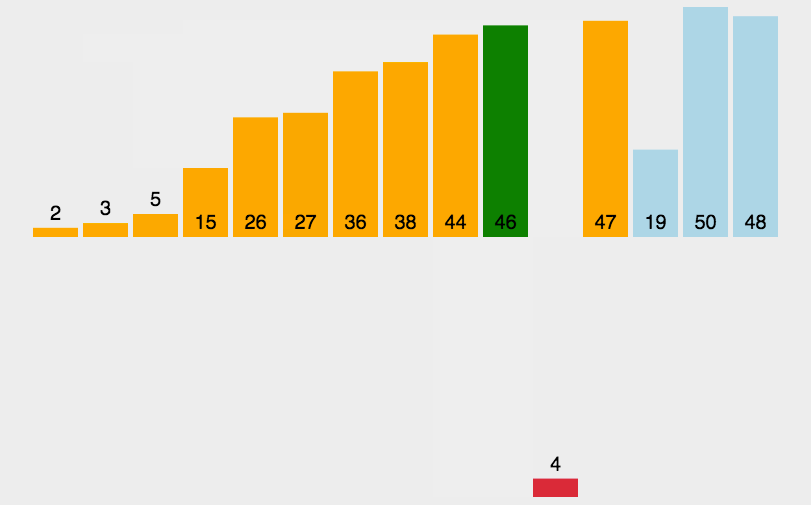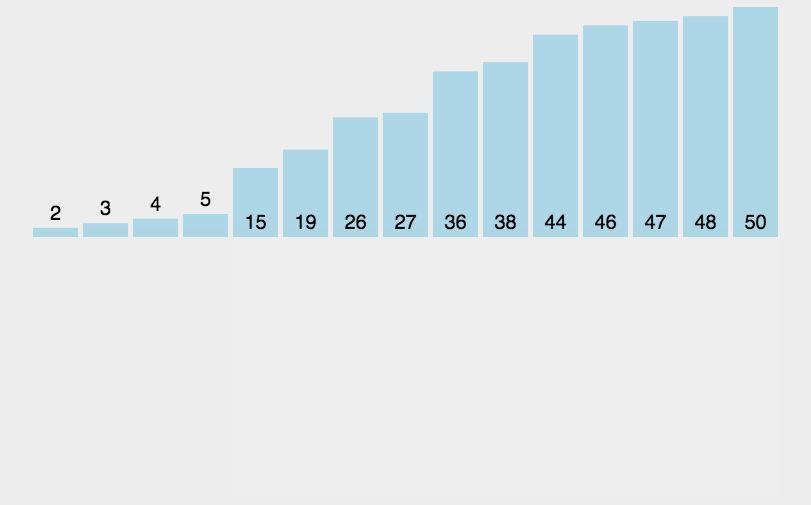
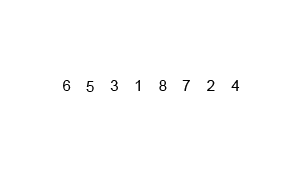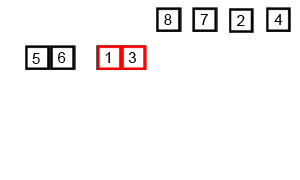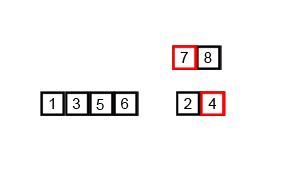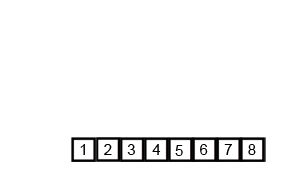
分析:先将 i 指向序列中满足从左到右是从小到大顺序的最后一个下标,再将 j 指向从 i + 1 开始,第一个不满足a[j] == b[j]的下标,如果 j 顺利到达了下标 n,说明是插入排序,否则说明是归并排序
过程:如果是插入排序,再下一次的序列是sort(a, a+i+2)(这里别忘了 sort 函数第二个参数 + 的是数量),而如果是归并排序,直接对原来的序列进行模拟归并过程
补充:插入排序是由前之后排序,归并排序是整体排序,一次排一列
1039 到底买不买
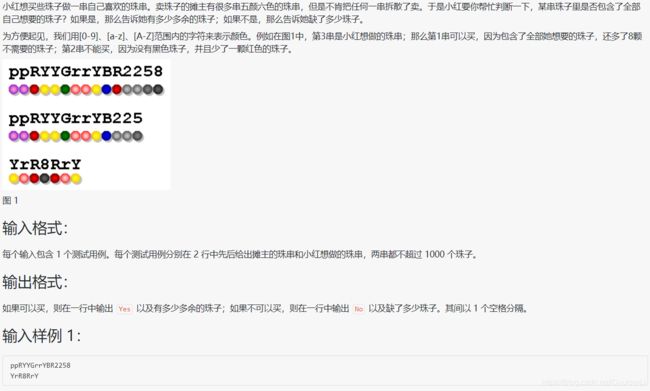
#include比较奇特的一点是:由 一个数组 和 数组的各个值的正负 判断 Yes or No
分析:想要记作 - - ,买了的记作++ ,那么最后 正数即为多余的,负数即为缺少的
1042 字符统计
#include题目和代码本身简单,但需要掌握两个函数:isalpha() 和 tolower()
isalpha(c): 当参数c为英文字母 (A-Z) 或 (a-z) 时,返回 非0 值,否则返回 0
isalnum(c):当字符变量c为字母或数字,返回 非0 值,否则返回 0
tolower(c): 能将字符c转换为小写英文字母
两者都包含于头文件
1044 火星数字
#include 分析:本代码用到了 string 数组,和各种各样的函数
substr ( 开始,长度),相当于复制,举例如下:
string s1 = s2.substr(0, 3);
atoi(c) 将字符 c 转换成数字,举例如下:
str[100]="00100" ; cout<<atoi(str)<<endl; output:100
//头文件 strcmp(str1,str2),若str1=str2,则返回零;若str1str1>str2,则返回正数
strcpy(str1,str2),将str2中的字符复制到str1中
补充:
string s;
getline(cin,s);
cout<<s.size();
//下面实例说明了空格在 getline中也算一个字符
input:a b
output:3
1045 快速排序
#include 由主元的定义:比前面的数都大,比后面的数都小,而相当于主元本身已经排好序了,那么将原数组排好序,对应位置相同的有可能是主元,再加上当前最大值的验证方法,一重循环即可
然后我似乎也找到有些人热衷于在末尾加换行符的原因了:不加就可能过不了测试点
1048 数字加密
#include 题目和代码本身简单,但需要注意:题目并没有说明白数字A可能比数字B长,这时需要短的数字补零(反转字符串即可)
补充:关于 string类 中 append 的用法,举例如下:
string a, b;
cin >> a >> b;
int lena = a.length(), lenb = b.length();
if (lena > lenb) //若 a 比 b 长,就补齐 b
b.append(lena - lenb, '0'); //第一个参数是个数,第二个参数是补充的字符
cout << b;
input:12345 123
output:12300
1049 数列的片段和
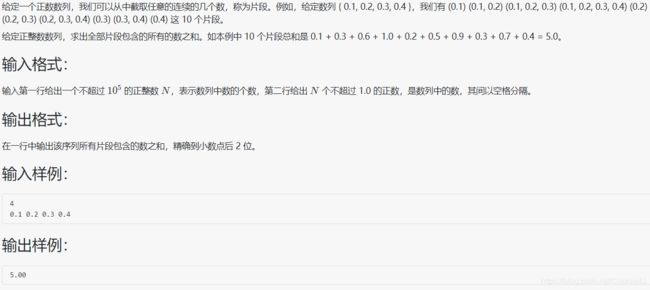
#include 单纯就是数学题,每个数出现的个数是(左边数的个数+1)*(右边数的个数+1)
1050 螺旋矩阵
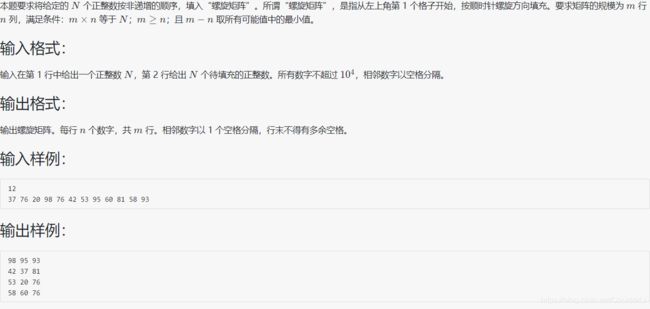
#include 解析:首先计算行数m和列数n的值,题目要求(m >= n),n 等于根号N的整数部分一直往 1 减,直到 N % n == 0,m 等于 N / n,再算 层数level(尽量多),等于 m / 2 + m % 2(所以用 m),最后矩阵排序,按顺时针螺旋方向,数字从大到小,输入数组元素,最后正常输出数组即可
补充:输入数组元素时,按照 4 个 for 循环输入,注意第二个和第四个 for 循环的起始位置和结束位置(输入元素总量少一个)
当不想占用栈太多内存时,可以用 vector 充当动态数组,因为其数据存储在堆中,用法如下:
//建立一维动态数组
vector<int> a(10);
//建立二维动态数组
vector<vector<int> > b(10, vector<int>(10));
//输入
cin>>a[0]>>b[0][0];
//输出
cout<<a[0]<<' '<<b[0][0];
input:5 5
output:5 5
1051 复数乘法
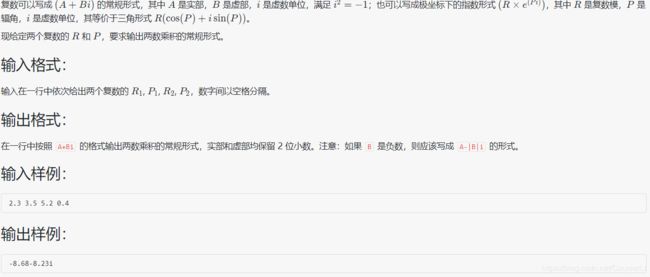
#include 题目可能有问题,没有说清楚要不要四舍五入,顺便补充一个关于四舍五入小知识点
double a=0.004;
double b=0.005;
printf("%.2lf\n",a);
printf("%.2lf",b);
//从结果来看,对于格式化,程序会自动四舍五入
output:0.00
0.01
1052 卖个萌
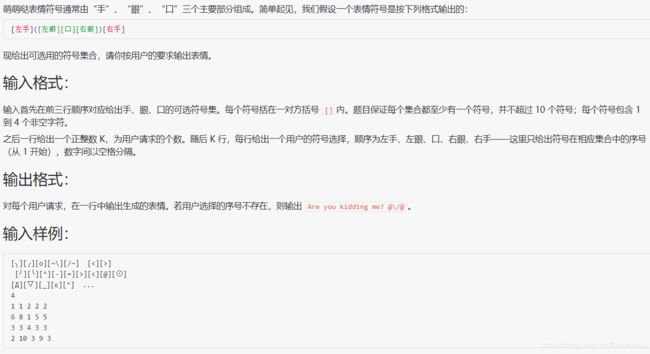

#include 问题和代码本身不难,但用到了二重动态规划(string类型),举例如下:
vector<vector<string> > v; //注意对于 string 类型不用设置长度
vector<string> row;
string a;
cin>>a;
row.push_back(a);
v.push_back(row);
cout<<v[0][0];
input:12345
output:12345
1054 求平均值
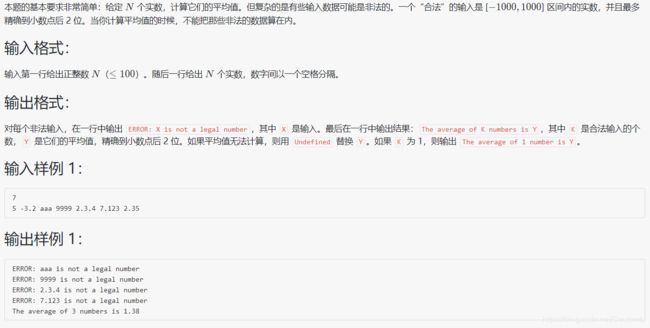

#include 先讲解 sscanf 和 sprintf 的作用:
sscanf(a,"%lf",&temp):从 a(字符串)中读进与指定格式相符的数据输入到 temp 中
sprintf(b,"%.2f",temp):将 temp 格式化输入到 b(字符串)中 (注意没有&号)
下面以部分本代码举例:
char a[50], b[50];
double temp;
scanf("%s", a);
sscanf(a, "%lf", &temp);
sprintf(b, "%.2f",temp);
cout<<a<<endl<<temp<<' '<<b;
//从下列实例看出排除了多种不合法数据
input:1.23.4
ouput:1.23 1.23
input:45.678
ouput:45.678 45.68
input:aaa
ouput:4.94066e-324 0.00
以其他例子举例:
char str[100]="1234:3.14,hello",arr[10];
int n;
double db;
sscanf(str,"%d:%lf,%s",&n,&db,arr); //注意这里不能用 %.2lf(似乎是规定)
cout<<n<<' '<<db<<' '<<arr<<endl;
char str2[100],arr2[]="hello";
int n2=1234;
double db2=3.14;
sprintf(str2,"%d:%.2lf,%s",n2,db2,arr2);
cout<<str2;
//下面实例说明此函数可以转换多个参数
output:
1234 3.14 hello
1234:3.14,hello
1055 集体照

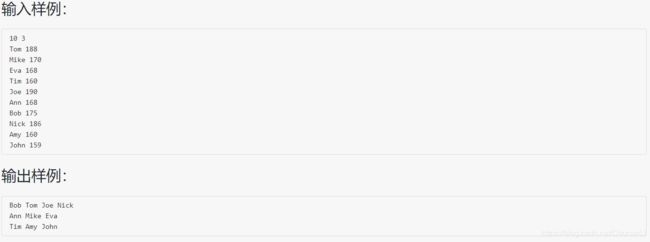
#include 分析:因为是面对拍照者,后排的人输出在上方,前排输出在下方,每排人数为 N / K,多出来的人全部站在最后一排,最中间一个学生应该排在 m / 2 的下标位置(题目的要求有歧义),即ans[m / 2] = stu[t].name,然后排左边一列,ans 数组的下标 j 从 m / 2 - 1 开始,一直往左 j - -,而对于 stu 的下标 i 从 t + 1 开始,每次隔一个人选取,排右边的队伍同理,最后输出当前已经排好的 ans 数组
1056 组合数的和
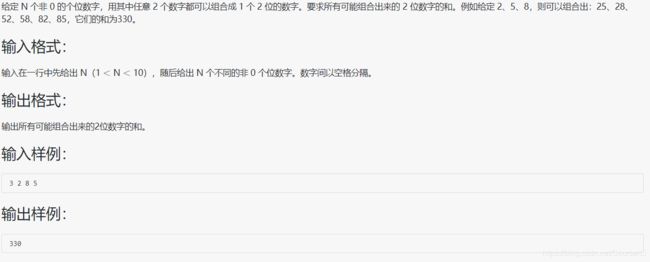
#include 技巧性题目,在 sum 累加的过程中,对于每一个输入的数字 temp,能够放在个位也能够放在十位,所以每个数字 temp 都能在个位出现 (N-1) 次,十位出现 (N-1) 次,在个位产生的累加效果为 temp * (N-1) ,而在十位产生的累加效果为 temp * (N-1) * 10,所以 sum 即是答案
1058 选择题
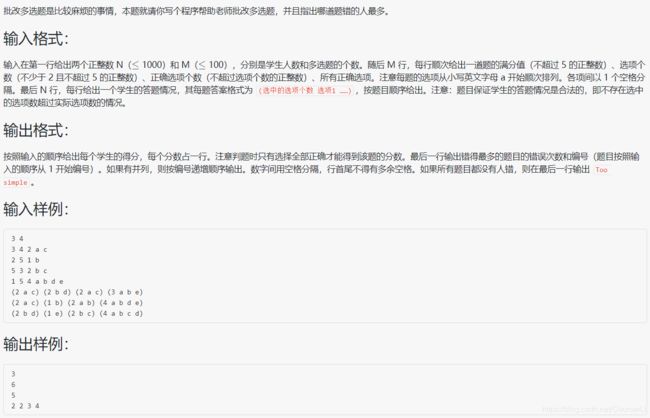
#include 分析:本题只要思路明确就可以很容易写出代码,要求输出 每个人的分数 和 错误人数最多的题和编号,那么肯定要设置 wrongCnt[i] 作为每题错误人数,maxWrongCnt作为错误最多的人数,再根据题目要求设置相应的变量进行推导即可
解析:set 是一种特别好的容器,它能存储元素各不同元素作为集合,举例如下:
set<int> st,sp;
//判断两种集合包含元素是否相同 (直接用等号判断)
st==sp;
//插入 (括号内是元素值)
st.insert(5)
//查找 (括号内是元素值;若找不到则返回 st.end())
st.find(5)!=st.end()
//是否存在 (括号内是元素值;若找到返回非 0值;若找不到则返回 0)
st.count(5)
小知识:vector 封装数组,set 封装集合,queue 封装队列,list 封装链表,map 封装关联数
补充:关于 scanf()另类的用法,举例如下:
int d;
scanf("("); //表示忽略左括号
scanf("%d",&d);
scanf(")"); //表示忽略右括号
cout<<d;
//下面实例论证上述说明是正确的
input: (45)
output: 45
input: 45
output: 45
input: )45(
output: 0
1059 C语言竞赛
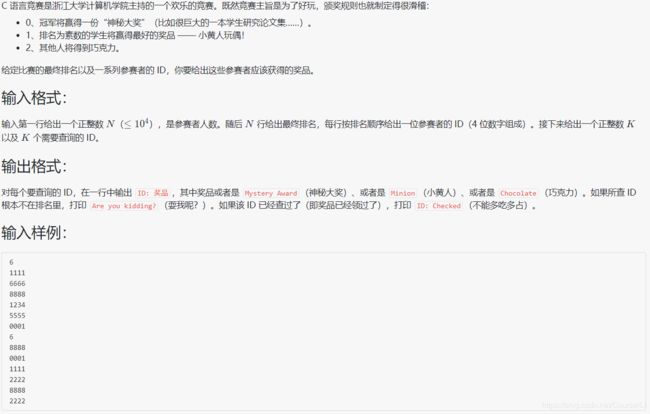

#include 题目和代码本身不难,就是想提醒一下以后遇到素数不要老想着用欧拉线性筛法,记一下普通模板
bool isprime(int a)
{
if(a <= 1) return false;
for(int i = 2; i <= sqrt((double)a); i++)
if(a % i == 0)
return false;
return true;
}
1060 爱丁顿数
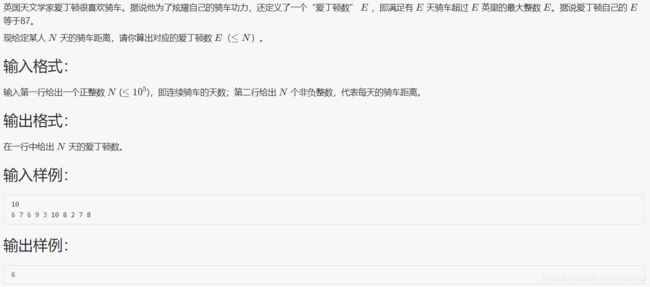
#include 单纯就是考数学,从下标 1 开始存储 n 天的公里数在数组 a 中,对 n 个数据从大到小排序,i 表示了骑车的天数,那么满足a[i] > i的最大值即答案
1064 朋友数
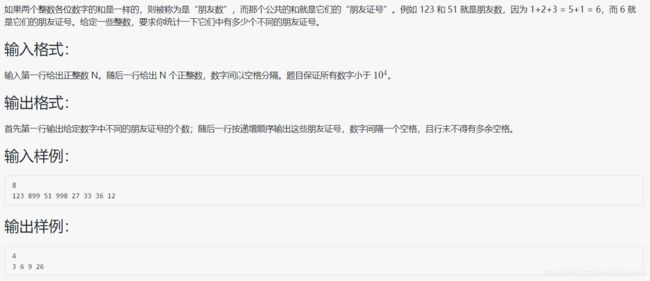
#include 题目和代码本身不难,但补充几个有关 set 的小知识点:
//1 定义时不用写集合个数,因为不常用到下标
set<int> s;
//2 关于 int型的元素会自动排序,不用手动 sort
//3 输出 set元素不用下标法,用如下方法
for(auto it = s.begin(); it != s.end(); it++) //auto 非常好用,但只适用于 PAT
set<int>::iterator it; //迭代器
for(it = s.begin(); it != s.end(); it++) //蓝桥杯和 PAT都适用
//也是关于蓝桥杯和 PAT的
stoi()
//此函数仅适用于 PAT
string str = "010";
int a = stoi(str, 0, 2); //将 2进制转换成 10进制
int b = stoi(str, 0, 3); //将 3进制转换成 10进制
cout << a << endl;
cout << b << endl;
//中间的参数是起始位置,但最好别改(改了会报错,我也不知道怎么回事)
output:
2
3
1067 试密码
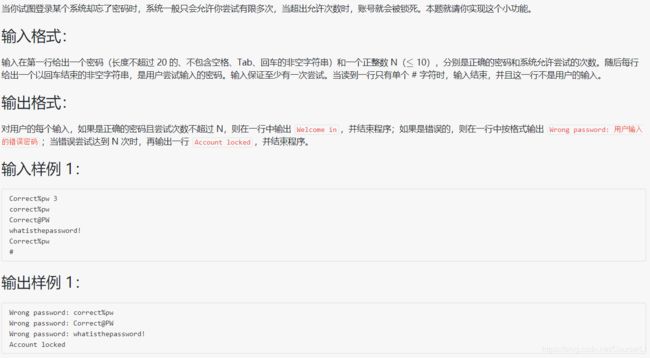

#include 题目和代码本身简单,但想回顾一下字符串的边界与 getchar()的必要性
1068 万绿丛中一点红
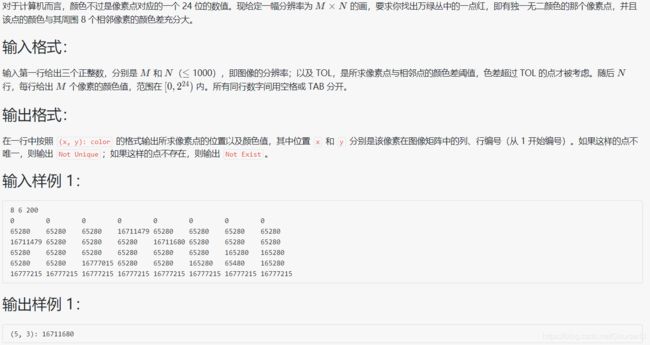
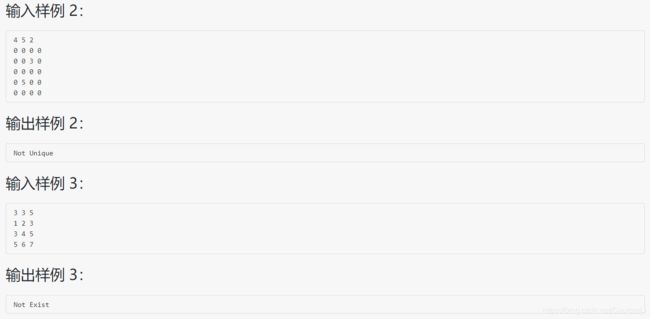
#include 分析:思路大致和迷宫问题类似,但此题有个额外注意的地方,即判定条件,仅当满足在 m坐标 与 n坐标内 和 差值在200之间才判定为否,其他均为正确,这样做的好处就是判断越界的元素也是对的(相当于在边界的元素只用判定相邻的元素即可)
补充:vector 二维数组的两种表达方式,举例如下:
int n=5,m=5;
//第一种
vector<vector<int> > v(n, vector<int>(m));
//第二种 (安全些,不容易发生段错误)
vector<vector<int> > v;
v.resize(n, vector<int>(m));
额外:vector 的 resize 另一种用法
补充:有关 map 的用法,举例如下:
map<int,int> m;
m[1000]++;
m[100]++;
map<int,int>::iterator it;
for(it=m.begin();it!=m.end();it++)
cout << (*it).first << " " << (*it).second << endl;
//说明 map可直接用来存储关联数,并可以有效提取
output:
100 1
1000 1
m[1]=5,m[2]=4,m[3]=3,m[4]=2,m[5]=1;
map<int,int>::iterator it;
for(it=m.begin();it!=m.end();it++){
cout << (*it).first << " " << (*it).second << endl;
//再一次论证
output:
1 5
2 4
3 3
4 2
5 1
1069 微博转发抽奖
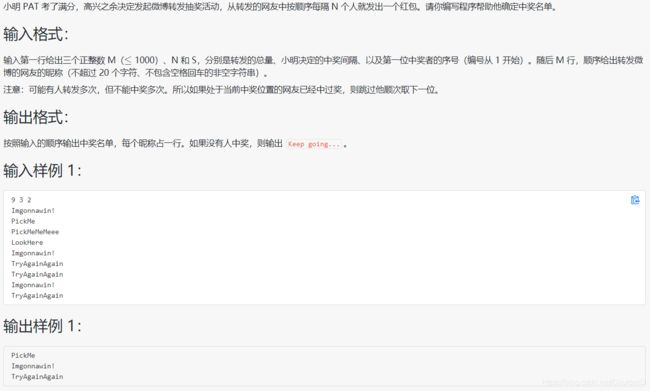

#include 这个代码很机智的将复杂简化了,若是一般写容易i+n,但本代码将全部循环写出来,并用另一个变量 s 代替 + n,这样就避免代码复杂化
1070 结绳
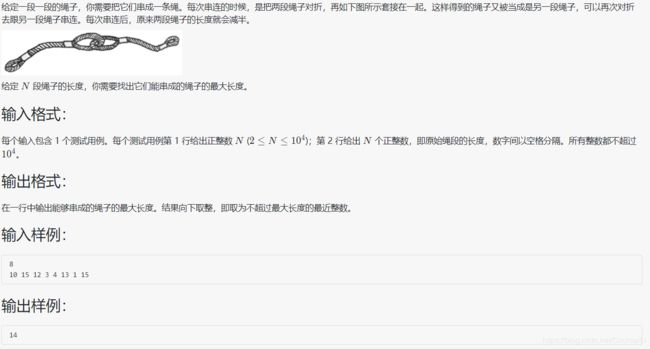
#include 数学题,因为所有长度都要串在一起,所以越早串绳子,越要对折的次数多,所以既然希望绳子长度是最长的,就必须让长的段对折次数尽可能的短
1073 多选题常见计分法

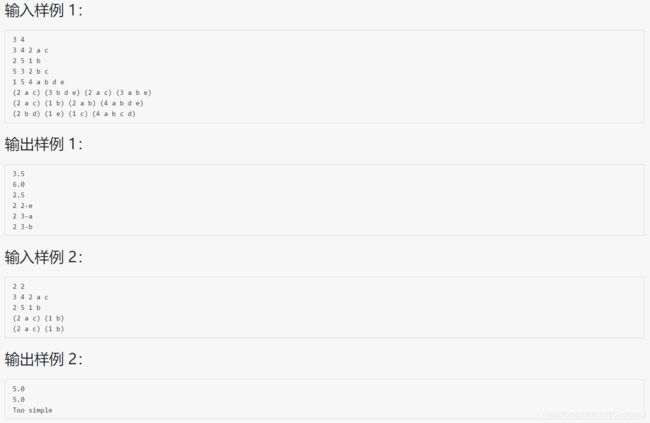
#include 分析:用异或运算来判断一个选项和正确选项是否匹配,如果是匹配的,那么异或的结果应当是0,如果不匹配,那么这个选项就是存在错选或者漏选的情况,例如:设 a 为 00001,b 为 00010,c 为 00100,d 为 01000,e 为 10000,如果给定的正确答案是 ac,即 10001,那么如果给出的选项也是 10001,异或的结果就是 0,如果给出的选项是 a(漏选)或者 ab(选错),即 00001 或 00011,异或之后皆不为 0,通过 异或操作的结果 用 与运算符 就可以把错选和漏选的选项找出来,本代码 存储选项的变量 存储的是二进制值,二进制由 hash 给出分别是1 2 4 8 16,即二进制各位置的 1(本题需要设置的变量特别多)
补充:
| 运算符 | 描述 |
|---|---|
| & | 按位与运算符: 参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 |
| | | 按位或运算符: 只要对应的二个二进位有一个为1时,结果位就为1。 |
| ^ | 按位异或运算符: 当两对应的二进位相异时,结果为1 |
| ~ | 按位取反运算符: 对数据的每个二进制位取反,即把1变为0,把0变为1 ;~x 类似于 -x-1 |
| << | 左移动运算符: 运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 |
| >> | 右移动运算符: 把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 |
下面以变量 a 为 60,b 为 13 举例,二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a & b = 0000 1100
a | b = 0011 1101
a ^ b = 0011 0001
~a = 1100 0011
a << 2 = 1111 0000
a >> 2 = 0000 1111
1074 宇宙无敌加法器
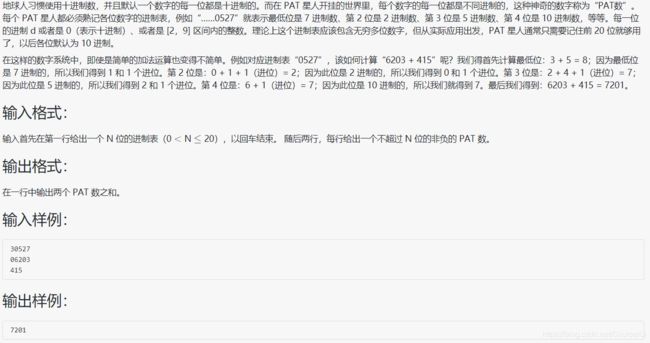
#include 代码非常简洁,但没什么好讲的,回顾一下 string 类进制
1075 链表元素分类
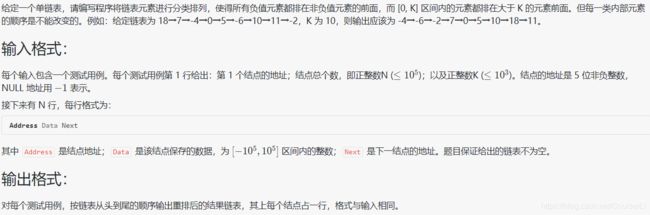
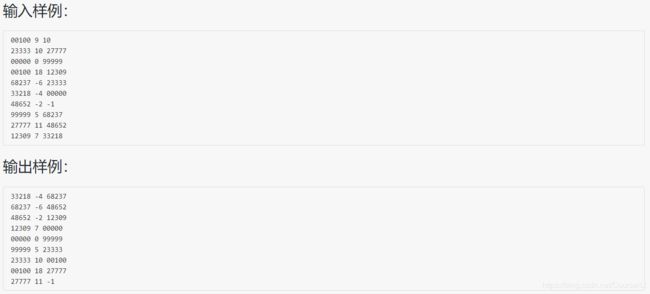
#include 此题与1025类似,但那题用的是堆数组,而此题用的是 vector 数组,作用就是可以根据题目要求分三类,而要插入直接 push_back,非常的简洁(那题只用分一类,不用多此一举)
1076 Wifi密码

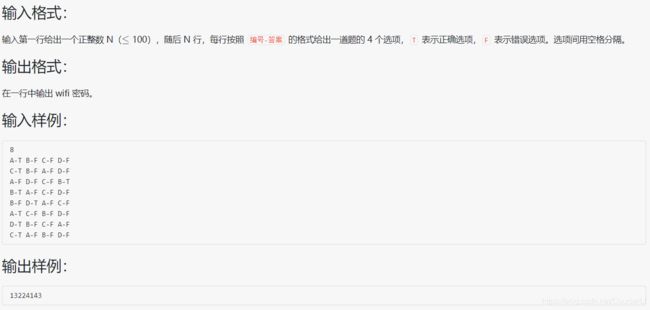
#include 分析:超精简代码,n 没什么作用,以字符串方式接收输入,只要遇到任何一个字符串 s 满足大小为 3 且 s[2] 为 ‘T’,就将 s[0] 字母对应的 wifi 密码输出
1080 MOOC期终成绩

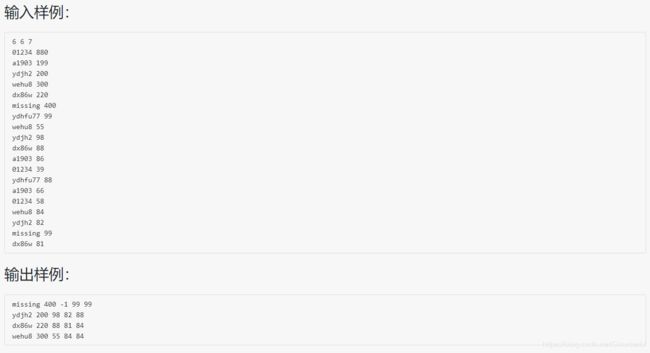
#include 分析:
1、因为所有人必须要G编程>=200分,所以用v数组保存所有G编程>=200的人,(一开始gm和gf都为-1),用map映射保存名字所对应v中的下标(为了避免与“不存在”混淆,保存下标+1,当为0时表示该学生的姓名在v中不存在)
2、G期中中出现的名字,如果对应的map并不存在(==0),说明该学生编程成绩不满足条件,则无须保存该学生信息。将存在的人的期中考试成绩更新
3、G期末中出现的名字,也必须保证在map中存在,先更新G期末和G总为新的成绩,当G期末
1084 外观数列
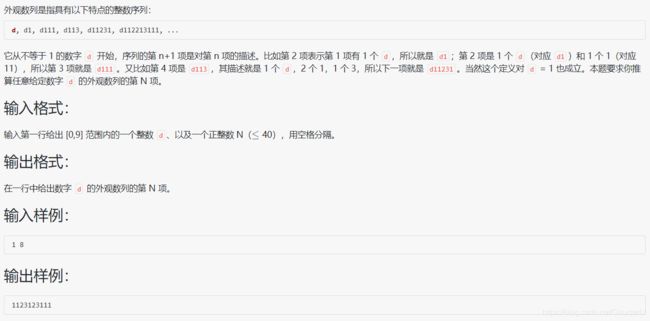
#include 分析:题目的意思是 d 代表某个数字来进行数列演示,而关于代码的关键部分,可以自行想象数字(字符串)迭代的过程
补充:
to_string()函数作用:将数字常量转换成 string 类
注意:此函数在 PTA 可以使用,而蓝桥杯不允许
若要用可以使用代替的函数表示,举例如下:
string to_string(int a)
{
string b="";
char c[1000]={0}; //存储空间根据题目调整
sprintf(c,"%d",a);
for(int i=0;i<strlen(c);i++)
b+=c[i];
return b;
}
//注意还有头文件 和
1085 PAT单位排行
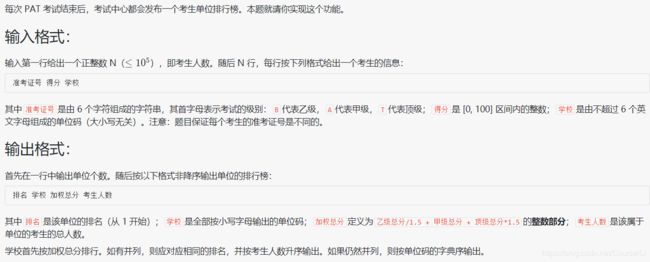
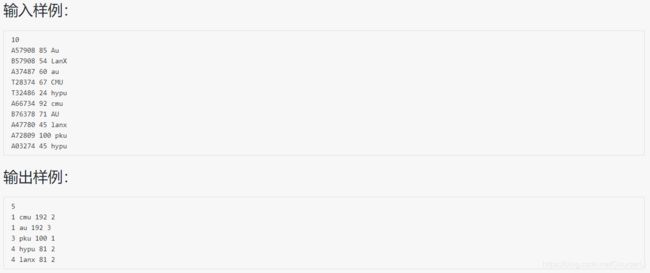
#include 分析:两个 map,一个 cnt 用来存储某学校名称对应的参赛人数,另一个 sum 计算某学校名称对应的总加权成绩,每次学校名称 string school 都要转化为全小写,将 map 中所有学校都保存在 vector ans 中,类型为 node,node 中包括学校姓名、加权总分、参赛人数,对 ans 数组排序,根据题目要求写好 cmp 函数,最后按要求输出,对于排名的处理:设立 pres 表示前一个学校的加权总分,如果 pres 和当前学校的加权总分不同,说明 rank 等于数组下标 + 1,否则 rank不变
补充:
本代码用的头文件 <unordered_map> 仅适用于 PTA
而蓝桥杯只用用 <map>
同理,蓝桥杯不能用 auto ,要转为迭代器类型
1086 就不告诉你

#include 单纯回顾一下 string 类 既有 to_string 又有 stoi 还可以 reverse
1089 狼人杀-简单版
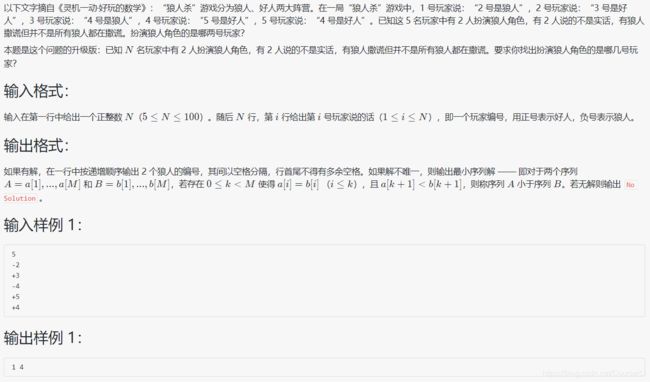

#include 分析:题目:已知 N 名玩家中有 2 人扮演狼人角色,有 2 人说的不是实话,有狼人撒谎但并不是所有狼人都在撒谎,说明这两个说谎的人一个是好人一个是狼人,每个人说的数字保存在 v 数组中,i 从 1~n - 1 、j 从 i + 1~n 遍历,分别假设 i 和 j 是狼人,a 数组表示真实情况(该人是狼人还是好人),等于 1 表示是好人,等于 -1 表示是狼人。k 从 1~n 分别判断 k 所说的话是真是假,k 说的话和真实情况不同(即v[k] * a[abs(v[k])] < 0)则表示 k 在说谎,则将 k 放在 lie 数组中,遍历完成后判断 lie 数组,如果说谎人数等于 2 并且这两个说谎的人一个是好人一个是狼人(即a[lie[0]] + a[lie[1]] == 0)表示满足题意,此时输出 i 和 j 并 return,否则最后的时候输出 No Solution
1090 危险品装箱

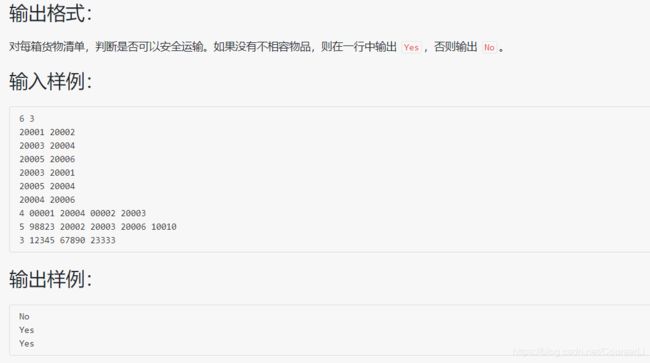
#include 分析:用 map 存储每一个货物的所有不兼容货物(用到了 map 的新用法),在判断给出的一堆货物是否是相容的时候,判断任一货物的不兼容货物是否在这堆货物中,如果存在不兼容的货物,则这堆货物不能相容,如果遍历完所有的货物,都找不到不兼容的两个货物,则这堆货物就是兼容的
1091 N-自守数
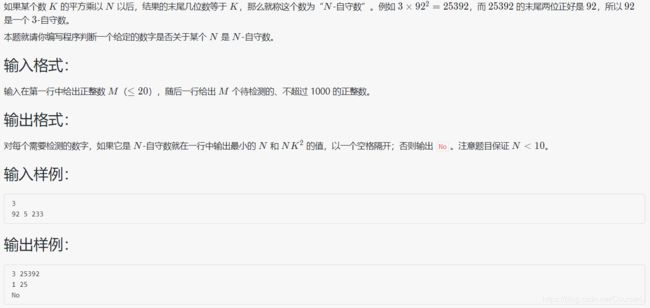
#include 题目和代码简单,解析一下 string 类的新用法:substr()函数
string temp;
temp = suf.substr(Off, Count)
off 参数: 复制子字符串的起始位置
Count 参数: 复制的字符数目
下面再举例说明:
string suf = "abcde";
string temp,temp2;
temp = suf.substr(2,1);
temp2 = suf.substr(2); //若没有第二个参数则代表一直复制到结尾
//下面实例看出是从 0开始计数
output:
c
cde
1093 字符串A+B
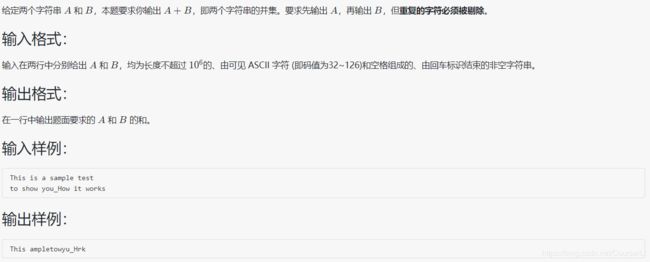
#include 分析:因为题目要求若有重复字符先出现 A 的,故做法为:A + B 在剔除重复字符
1095 解码PAT准考证

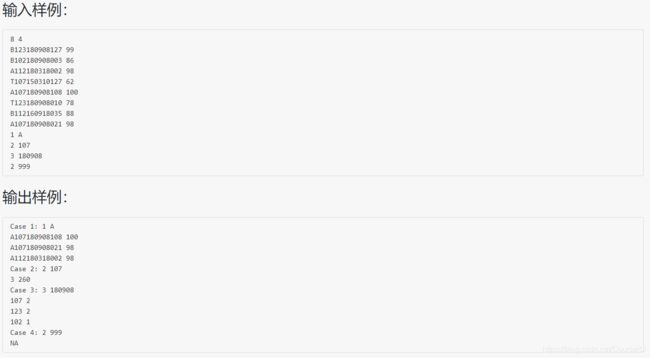
#include 分析:非常有参考价值的分类题
题目大意:给出一组学生的准考证号和成绩,准考证号包含了等级(乙甲顶),考场号,日期,和个人编号信息,并有三种查询方式
查询一:给出考试等级,找出该等级的考生,按照成绩降序,准考证升序排序
查询二:给出考场号,统计该考场的考生数量和总得分
查询三:给出考试日期,查询改日期下所有考场的考试人数,按照人数降序,考场号升序排序
代码:先把所有考生的准考证和分数记录下来
1、按照等级查询,枚举选取匹配的学生,然后排序即可
2、按照考场查询,枚举选取匹配的学生,然后计数、求和
3、按日期查询每个考场人数,用 unordered_map 存储,最后排序汇总
注意:1、第三个用 map 存储会超时,用unordered_map就不会超时啦
2、排序传参建议用引用传参,这样更快,虽然有时候不用引用传参也能通过,但还是尽量用,养成好习惯
解析:c_str() 函数的用法
作用:将 C++ 的 string 转化为 C 的字符串数组输出
string temp = "123";
printf("%s",temp.c_str());
//这样就可以将 temp 以 c语言 的形式输出(目的是为了快)
output:123
补充:for (auto it : m) 函数的用法
c++11的新特性,范围 for
m 是一个可遍历的容器或流,比如 vector 类型
it 就用来在遍历过程中获得容器里的每一个元素
vector<int> m={1,2,3,4};
for(auto it : v)
cout<<it;
output: 1234
//注意仅 PTA 适用,蓝桥杯不允许