对抗样本(论文解读二): Transferable Adversarial Attacks for Image and Video Object Detection
准备写一个论文学习专栏,先以对抗样本相关为主,后期可能会涉及到目标检测相关领域。
内容不是纯翻译,包括自己的一些注解和总结,论文的结构、组织及相关描述,以及一些英语句子和相关工作的摘抄(可以用于相关领域论文的写作及扩展)。
平时只是阅读论文,有很多知识意识不到,当你真正去着手写的时候,发现写完之后可能只有自己明白做了个啥。包括从组织、结构、描述上等等很多方面都具有很多问题。另一个是对于专业术语、修饰、语言等相关的使用,也有很多需要注意和借鉴的地方。
本专栏希望在学习总结论文核心方法、思想的同时,期望也可以学习和掌握到更多论文本身上的内容,不论是为自己还有大家,尽可能提供更多可以学习的东西。
当然,对于只是关心论文核心思想、方法的,可以只关注摘要、方法及加粗部分内容,或者留言共同学习。
Transferable Adversarial Attacks for Image and Video Object Detection
XingxingWei1,SiyuanLiang2,NingChen1,XiaochunCao2 1DepartmentofComputerScienceandTechnology,TsinghuaUniversity 2InstituteofInformationEngineering,ChineseAcademyofSciences {xwei11,ningchen}@mail.tsinghua.edu.cn,{liangsiyuan,caoxiaochun}@iie.ac.cn
发表于IJCAI 2019
针对图像和视频检测可转移的对抗攻击
1 Abstract
Existing attacking methods for image object detection have two limitations: weak transferability—the generated adversarial examples often have a low success rate to attack other kinds of detection methods, and high computation cost—they need much time to deal with video data, where many frames need polluting.
根据自己的贡献,引出To address these issues,
方法基于 Generative Adversarial Network (GAN),结合高层的类别损失和低层的特征损失来联合训练对抗样本生成器,可有效生成图像和视频对抗样本,并且可同时攻击两种有代表性的目标检测模型:基于提议的Faster R-CNN和基于回归的SSD。

对比效果图,原图及分别基于原有DAG攻击方法和自己的攻击方法UEA产生的对抗样本,分别在Faster R-CNN和SSD300下的目标检测结果。
2 Introduction
背景、图像分类攻击
现有目标检测攻击及其不足点:1 基于提议区域的攻击无法攻击基于回归的攻击;2基于迭代优化,耗时无法处理视频。
To address these issues, in this paper, we propose the Unified and Efficient Adversary (UEA) for image and video object detection. 利用生成机制而非优化程序。
We observe that both the proposal and regression based detectors utilize feature networks as their backends. For examples,Faster-RCNN and SSD use the same VGG16. 找到两者的共同点,底层都是基于VGG16来提取特征的。通过多尺度的注意特征loss来利用这一点。
贡献:
1.提出的UEA即可有效的攻击图像和视频,也可以同时攻击两类检测器;
2.提出了多尺度的注意特征损失 multi-scale attention feature loss ,利用高层类别损失和底层特征损失来联合训练对抗样本生成器。
3 Related Work
3.1 Image and Video Object Detection
Currently, the dominant image object detection models can be roughly categorized into two classes: proposal based models and regression based models.
R-CNN系列:They firstly detect proposal regions, and then classify them to output the final detected results.
YOLO/SSD: directly predict the coordinates of bounding boxes.
video object detection : They usually apply the existing image detector on the selected key frames, and then propagate the bounding boxes via temporal interactions。选定关键帧,利用图像目标检测,通过时间交互传播边界框。(这一块有待实践、理解)
3.2 Adversarial Attack for Object Detection
现有的针对目标检测的物理攻击都是基于提议的,且都是基于优化过程的。

4 Methodology
4.1 UEA
1.首先将问题定义为条件GAN框架,其目标函数为:
![]()
其中G和D分别为对抗样本生成器和判别器。
为了使生成图像更接近于原始图像,于是引入如下L2损失:

4.2 损失函数
为了能够同时攻击两种类型的目标检测器,除了如上两个损失之外,又引入了DAG的类别损失函数:

其中X是提取的特征图,tn是X上所有的提议区域,ln是tn的ground-truth,l^n为随机指定类别的错误标签。f()表示分类得分向量。
如上式可以攻击Faster R-CNN,为了使其能够具有转移性,我们又引入了低层多尺度注意特征损失:
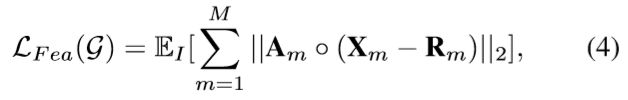
其中Xm为提取的m层的特征图,Rm为随机预定义的特征图且在训练中是固定的。
为了愚弄检测器,仅仅区域的前景目标需要扰动,于是使用注意力权重Am去测量Xm中的目标。
未完!!
4 Experiments
4.1 Datasets
Image Detection In order to train the adversarial generator in UEA, we use the training dataset of PASCALVOC 2007 with totally 5011 images. They are categorized into 20 classes. In testing phase, we use the PASCAL VOC 2007 testing set [Everingham et al., ] with 4952 images. 描述形式
4.2 Metrics
Fooling Rate: mAP
Time:
(组织形式)
4.3 Threat Models
Faster-RCNN and SSD300
4.4 Results on Image Detection
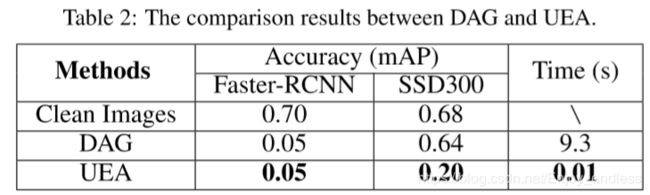
检测结果如下,分别包括在干净图像、DAG攻击方法下及UEA攻击下的样本,在两个模型下的检测结果,及其时间。
样本图:

From the table, we see: (1): . (2): . (3):
Ablation Study of UEA
Now we look into the ablation study of UEA. 针对提出的类别及类别+特征损失,其对于图像当中每一类的影响结果如下图:

Qualitative Comparisons
We give some qualitative comparisons between DAG and UEA 如下图:

To better show the intrinsic mechanism of UEA, we visualize the feature maps extracted from adversarial examples via DAG and UEA, respectively. Because Faster-RCNN and SSD300 utilize the same VGG16 as their feature network,we select the feature maps extracted on conv4 layer and visualize them using the method in [Zeiler and Fergus,2014].
特征可视化,这一块也挺有意思的,其实各种论文当中用到的各种小技术,还是很有意思的,同样也是具有一定学习价值的。

在这里我没有放置关于视频检测相关的内容,一个是技术基本是一样的,一个是相关知识不太了解,后期有可能会学习添加。
这篇文章涉及到的一些知识、思路,还是具有不少借用价值的,同时还包括一些小技术也挺有用,所以关于其代码的研究还是要跟进的,希望与感兴趣的小伙伴一起研究学习。
源码git地址:
https://github.com/LiangSiyuan21/Adversarial-Attacks-for-Image-and-Video-Object-Detection