对抗样本(论文解读九):Making an Invisibility Cloak Real World Adversarial Attacks on Object
Making an Invisibility Cloak Real World Adversarial Attacks on Object
Zuxuan Wu Facebook AI University of Maryland
Ser-Nam Lim Facebook AI
Larry Davis University of Maryland
Tom Goldstein Facebook AI University of Maryland
论文公开于2019.10.31

Abstract
攻击通用的检测器及集成检测器。测试了对抗块在白盒和黑盒设置下的有效性,以及在不同数据集、目标类别和检测器模型之间的可转移性。最后,我们使用打印的海报和可穿戴的衣服对物理世界攻击进行了详细的研究,并使用不同的度量标准严格地量化了这些攻击的性能。(表较笼统)
1.Introduction
对抗样本—数字世界—物理世界(不同镜头、分辨率、光照、距离及角度)
一系列的物理攻击通常局限于数字空间。进一步的,许多物理攻击的研究虽然取得了成功,但是没有量化攻击的成功率,以及训练过程及环境是如何影响其有效性的。最后,物理攻击通常定义于固定打印板、并无考虑复杂扭曲等:如3d的人、飞机和车等。
在本文中,我们研究艺术和科学的物理攻击探测器,最终目标是生产可穿戴纺织品。我们的研究目标如下:
我们聚焦于强有力的检测器,不同于分类器,其一张图象输出一个特征向量。检测器输出一个特征图,包含不同先验对应不同目标。attacks must simultaneously manipulate hundreds or thousands of priors operating at different positions, scales, and aspect ratios。
我们打破了从数字化模拟再到现实世界来实现攻击的渐进过程。我们探讨了现实世界中的扰动变量是如何造成数字和物理攻击的差异的,以及通过实验量化和识别这些差异。
我们量化了不同条件下的攻击成功率,并测量了算法和模型对于其的影响。我们研究了攻击如何降低标准度量(AP),以及更多可解释的成功/失败度量。
我们通过制造可穿的对抗服装,以及量化在复杂的织物变形情况下攻击的成功率,将物理攻击推到其极限。
2.Related Work
Attacks on object detection and semantic segmentation. a plethora of work 于图像分类,较少的工作位于目标检测及语义分割。对于数字攻击工作的罗列。 Note that all of these studies focus on digital (as opposed to physical) attacks with a specific detector. In this paper, we systematically evaluate a wide range of popular detectors in both the digital and physical world. 对比、引
Physical attacks in the real world. 工作罗列
2.1.Object detector basics
We briefly review the inner workings of object detectors, most of which can be described as either two-stage frameworks 引
Two-stage detectors These detectors use a region proposal network (RPN) to简介
One-stage detectors These networks generate object proposals and at the same time predict their class labels.
Why are detectors hard to fool? 他这里是说每一个目标都会产生成百上千个先验框,然后这些先验框是通过NMS来过滤掉概率较小的,当你试图攻击最大概率框以后,网络还可以选择其他先验框进行再次输出检测结果。所以,这种攻击必须同时欺骗所有与目标重叠的先验集合,这比欺骗单个分类器的输出要困难得多。
3.Approach
Our goal is to generate an adversarial pattern that, 不论是数字还是物理空间,其攻击都可以通用。Furthermore, we expect the pattern to be
(1) 通用----图像无关,对于多类别、不同场景都有效;
(2) 可转移----对于不同网络的检测器都有效;
(3)数据集无关----可以攻击基于不同数据集训练的检测器;
(4)鲁棒----对于不同视角和距离有效;
(5)可实现----可打印
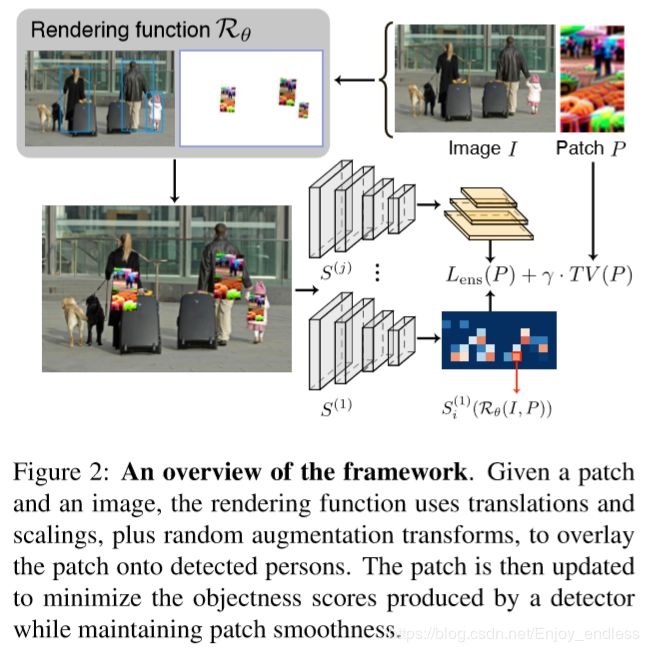
3.1.Creating a universal adversarial patch
Our strategy is to “train” a patch using a large set of images containing people. On each training iteration,引 We then place a randomly transformed patch over each detected person, and update the patch pixels to minimize the objectness scores in the output feature map. 表述
目标损失函数如下:

i表示检测器获得的先验框,R表示贴附块后的图像,Si表示每个先验框的目标分数。损失函数惩罚任何一个目标分数大于-1的先验框(是否非常耗时??)。同时最小化变换期望,提高其鲁棒性,以及最小化对于训练集随机的期望。最后最小化块内总体像素差值。最终优化问题为:

Ensemble training 为了使对抗样本具有黑盒攻击能力,我们将原目标损失替换为集成损失:

S^j表示集成中的第j个检测器。
4.Crafting attacks in the digital world
Datasets and metrics We craft attack patches using … the dataset that do not contain people,when then chose a random subset of 10,000 images for training. … compute average precision (AP) …further compute success rates to quantify the performance of patches. 语言表述
Object detectors attacked We experiment with both one-stage detectors, i.e., YOLOv2 and YOLOv3, and two-stage detectors, i.e., R50-C4 and R50-FPN, both of which are based on Faster RCNN with a ResNet-50 [10] backbone. We consider parches crafted using three different ensembles of detectors—ENS2: YOLOv2 + R50-FPN, ENS2-r: YOLOv2 + R50-FPN-r, and ENS3-r: YOLOv2 + YOLOv3 + R50-FPN-r.(他这里是多个集成训练,算是可转移性吗,具体是怎么集成的,有待进一步学习)
Implementation details We use PyTorch for implementation,and在前向传递过程中,由rendering function 动态调整块的大小(有待进一步学习)。Adam、decay the rate,resized to。
4.1.Evaluation of digital attacks
We begin by evaluating patches in digital simulated settings:白/黑盒

Effectiveness of learned patches for white-box attack We compare with the following alternative patches: (1) FTED, a learned YOLOV2 patch that is further fine-tuned on a R50-FPN model; (2) SEURAT,实验设置
Patches are shown in Fig 3, and results are summarized in Table 1. We can observe that all adversarially learned patches are highly effective in digital simulations, where…表述

(他这个表里面还有一个颜色变换。。设置)
Interestingly, In addition, It is also interesting to see that ,表述
We visualize the impact of the patch in Figure 4, which shows

Transferability across backbones We also investigate whether the learned patches transfer to detectors with a range of backbones. We evaluate the patches on the following detectors: (1) R101-FPN, ; (2) X101-FPN,…The results are shown in Figure 5. We observe that

Transferability across datasets We further demonstrate the transferability of patches learned on COCO to other datasets including Pascal VOC 2007[5] and the Inria person dataset [4]. the results are presented in Figure6. The left two panels correspond to results of…the rightmost panel shows the APs of… From the right two panels, we can see that weights learned on COCO are more robust than on VOC. 表述,及实验设置,图表设计,都是值得借鉴

Transferability across classes 我们发现即使用于训练抑制一个类别的块,其也可以同时抑制其他的类别。除了训练‘人’类别块,我们同时训练了‘bus’、‘horse’基于coco,并在voc上评估。表2总结了结果。我们可以看到,,,同时我们还比较了灰色补丁,以得出性能下降是由于遮挡的可能性。(实验做的很严谨)。
5.Physical world attacks
We now move on to discuss the results of physical world attacks with printed posters. 我们同时量化攻击性能 “success rates,” which we define as (1) a SUCCESS attack: …; (2) a PARTIAL SUCCESS attack: when there is a bounding box covering less than 50% of a person; (3) a FAILURE attack: …检测样例如图7所示

5.1.Printed posters
我们用10个不同的块在15个不同的地方打印海报和拍照。在每个地方,我们都拍了四张照片,这四张照片是用打印出来的块拼成的,离相机有两段距离,贴在块的地方有两处高度。我们也拍摄了没有打印海报的照片作为对照(对照)。我们总共收集了630张照片(参见图7底部的一行作为示例)。我们使用四个块,性能良好的数字(即YOLOV2, ENS2, ENS3,),和三个基线块(SEURAT patch, FLIP patch,白色)。
Poster results 图8a及8c总结了结果。We can see that FCOS网络在对抗块下是最脆弱的网络,尽管我们从未训练过无锚探测器,更不用说FCOS了,它还是落入了YOLOV2补丁。这可能是因为无锚模型预测了包围盒像素的“中心度”,当人的中心像素被印刷的海报遮挡时,性能下降。然而有趣的是,简单地使用基线块并不能欺骗FCOS。(关于原因也只是猜测或避而不谈)
Beyond the choice of detector, several other training factors impact performance. Surprisingly, TPS块不如YOLOV2,我们认为如此复杂的变换使得优化非常困难。It is also surprising to see that YOLOV2-Inria块优于YOLOV2,但是可转移性不好(未解释原因)。 Not surprisingly,
5.2.Paper dolls
我们发现,制造物理攻击的一种非常有用的技术是制作“纸娃娃”——打印出测试图像,我们可以用不同大小的不同补丁加以修饰。在本节中,我们将使用纸娃娃来深入了解为什么物理攻击不如数字攻击有效。原因可能有三:(1)探测器像素化和压缩算法;(2)补丁边界周围的渲染工件有助于数字攻击;(3)表征和纹理的不同。