如何更好的写作一篇论文(简单的方法,不简单的论文):A Simple Framework for Contrastive Learning of Visual Representations
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen1 Simon Kornblith1 Mohammad Norouzi1 Geoffrey Hinton1
发布于2020.02.13
地址:https://arxiv.org/abs/2002.05709
这篇论文其实早就想分享一下了,只是一直耽搁到了现在。虽然论文目前应该是还没有被接受,但是大佬Geoffrey Hinton的工作及最终优越的实验效果,还是引起了相关领域研究者非常大的关注的。
当然,这不是关于对抗样本的一篇文章(所以标题也没有加对抗样本),关于本文章更多的领域知识及文章细节,网上已经有了不少的讨论及解析。在这里,我所关注的是从另一个视角来学习本篇文章。
本专栏的目的不仅仅是局限于对抗样本本身的学习,同样对于相关创新的idea、有启发的工作及好的文章写作,进行学习分享。而本篇博客的目的,就是来学习如何以更好的角度或者方式方法,来表明你文章的价值。
抛开这篇论文的方法本身,有什么值得我们学习的地方?
正如论文题目所说,这是一个简单的框架,简单到可以说是,现有技术的简单利用和组合。那么这样一篇简单的论文,如何做到让他不简单呢?(或者说,如何让读者或论文审稿者判定这篇论文是不简单的、有价值的呢?)
首先,这篇文章的附录确实有很多值得学习得地方。
1.实验的细节,够细够清晰。
2.实验过程当中,所做过的所有有用的实验数据,包括对比、启发,等等,全部列了出来。可以启动一个:虽然文章方法看起来简单,但是简单的背后确实大量的实验支撑。
3.与已有方法的对比。这个问题是没法回避的,既然没法回避,就一一具体对比分析。对比的过程,也是一个自己方法优点不断重复、强调及扩大的过程。(其实这些问题,在review的时候都有可能碰到,等到rebuttal再补充就晚了。)
下面我们来具体看一下文章的细节,这些细节是如何来突出表现本文章的novelty的。
一个简单的框架用于视觉表现的对比学习
Abstract
This paper presents SimCLR: a simple framework for contrastive learning of visual representations. 简称介绍。
我们简化了最近提出的对比型自监督学习算法,其不需要专门的架构或存储库。为了(理解什么操作可以学习更有用的表征),我们做了(系统的研究了我们框架的主要组件)。We show that
(1) 数据扩充组件在任务中的重要性,
(2)介绍了一个在表征与对比损失之间可学习的非线性变换,and
(3) 更大的batch sizes及更多的训练步骤对于表征学习更有用。
By combining these findings, 性能及实验数据展示。
(1跟3看起来就是废话,试问谁不知道,哈哈。你能做的了实验,你敢发表论文吗?你发表了论文,你不怕被喷吗?哈哈)
1. Introduction
学习没有人类监督的有效的视觉表现是一个长期存在的问题。大多数主流方法可分为两类:生成式和区别式。在这里提到了一个像素级别的生成计算量大及对于表征学习没有必要。(像素级别的操作在各任务当中应用的还是比较多的,可以作为自己实验类别方法)。
In this work, 我们介绍了,which we call SimCLR. Not only does SimCLR outperform previous work (Figure 1), but it is also simpler, requiring neither specialized architectures (Bachmanetal.,2019;Hénaffetal.,2019) nor a memory bank (Wu et al., 2018; Tian et al., 2019; He et al., 2019a; Misra & van der Maaten, 2019).
这一句话的表示形式(对比文献,突出贡献)及句式,都是值得学习的。
(对应摘要)为了,我们,and show that:
-
多个数据扩充操作的组合在定义产生有效表示的对比预测任务时是至关重要的。In addition, 无监督对比相比有监督学习受益更大(添加了新的实验对比)
-
介绍了一个在表征和对比损失之间的可学习非线性变换,极大地提高了学习表征的质量。
-
具有对比交叉熵损失的表示法学习得益于归一化嵌入和适当调整的温度参数。
-
与监督学习相比,对比学习受益于更大的批量和更长的训练。与监督学习一样,对比学习也受益于更深更广的网络。
We combine these findings to achieve 实验结果提升对比。
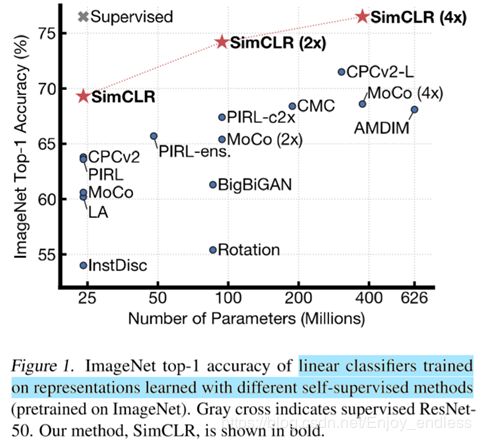
这个图,包括yolo实验结果对比图,efficientnet实验结果对比图等,都是够学一壶的。
2 Method
2.1 对比学习框架
SimCLR通过潜在空间中的对比损失,最大限度地提高相同数据示例的不同扩充视图之间的一致性,从而学习表示。As illustrated in Figure 2, 框架有以下4个主要组件。
- 随机数据扩充模块,3个简单的扩充:随机裁剪,然后将大小调整回原来的大小,随机颜色扰动及随机高斯扰动。
- 基于神经网络的编码器f(.),从扩充的数据样本中提取表征向量。没有任何限制实现不同网络的应用。简单的使用了ResNet。
- 一个小的神经网络映射头g(.),将表征映射到对比损失的同一空间。使用了含有一个隐藏层的MLP,第4部分展示了经MLP转换后的对比损失更好。
- 定义了一个对比损失函数应用于对比预测任务。
损失函数:
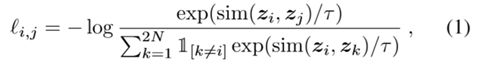
其中 ![]() 为向量间的cosine相似度。Zi和zj为如下图2的最终输出。N表示一个batch内样本的个数,一个样本x经扩充变为两个xi和xj,总共2N个样本。 This loss has been used in previous work (Sohn, 2016; Wu et al., 2018; Oord et al., 2018) (损失也不是自己提出来的,,,)
为向量间的cosine相似度。Zi和zj为如下图2的最终输出。N表示一个batch内样本的个数,一个样本x经扩充变为两个xi和xj,总共2N个样本。 This loss has been used in previous work (Sohn, 2016; Wu et al., 2018; Oord et al., 2018) (损失也不是自己提出来的,,,)
算法1总结了提出的方法。(里面还加上了注解,,,,)

2.2 Training with Large Batch Size
我们训练模型不使用存储模块,而是将训练的batch size从256到8192变换。使用大的batch size基于标准的SGD/Momentum优化会使训练不稳定,于是我们使用了LARS优化器。
全局BN.并行训练时计算所有设备的BN均值和方差。其他方法包括shuffling数据或通过layer norm来替换BN。
2.3 Evaluation Protocol
Most of our study for unsupervised pretraining (learning encoder network f without labels) is done using the ImageNet ILSVRC-2012 dataset (Russakovsky et al., 2015).
(无监督预训练,很有意思哈)
具体的使用设置细节:维度、优化器、epoch、batch size, LearningRate = 0.3×BatchSize/256。
3.Data Augmentation for Contrastive Representation Learning
Data augmentation defines predictive tasks. 尽管数据扩充已广泛应用于监督及无监督表征学习,然而它还没有被认为是一种系统的方法来定义对比预测任务。 Many existing approaches define contrastive prediction tasks by changing the architecture. For example, ,.我们证明,通过对目标图像执行简单的随机裁剪(调整大小),可以避免这种复杂性,从而创建包含上述两个任务的一系列预测任务,如图3所示。
(这一段引子非常重要!!数据扩充一个任务/方向的转变,之前方法面对相同问题是如何操作的,而我这里的优点是什么。既简单又可以取得很好的性能)
3.1 Composition of data augmentation operations is crucial for learning good representations
数据的空间和几何变换:
3.2
网络架构变换:
Vgg–xrnet—enfficennet
一半数据----全量数据
采样方式,---- 均衡采样
损失函数:交叉熵、focal loss、
加Mask、分割、数据增强/广、
附录的引用:

附录的格式:

不仅放上了代码,还同时包括tensorflow和pytorch的。。。

额外的实验,这些可能跟本文方法没有直接关系,但是任何方法都是实践对比出来的,在我们实验对比过程当中,任何有启发性的实验,都可以表明我们的工作进程及迭代。

最后这一个与现有方法的逐一对比,这是一个不可回避的问题,如何更好的对比出自己方法的优点。
具体的细节有很多,这里不再一一列举了。
方法很简单,实验很详尽,这样的论文还是有不少的,如何将这样的论文写好,并得到各大顶会reviewer的认可,是非常值得借鉴和学习的。
后续关于这一块的文章学习与分享,也将会持续更新。