计算机系统基础知识_体系结构及指令
文章目录
- 概述
- 计算机体系结构分类
- 指令系统
- 指令集体系结构的分类
- CISC和RISC
- 复杂指令集计算机(Complex Instruction Set Computer)
- 精简指令集计算机(Reduced Instruction Set Computer)
- 指令优化
- 指令的流水线
- 流水(Pipelining)
- 流水的分类
- 流水相关的处理方式
- 流水技术
- 流水吞吐率与建立时间
概述
1964年,阿姆达尔(G.M.Amdahl)指出计算机体系结构是程序员角度所看到的的计算机属性,即要编写出正确运行的程序必须了解的概念性结构和功能特性。
1982年,梅尔斯(G.J.Myers)在其所著的《计算机体系结构的进展》一书中定义了组成计算机系统的若干层次,每一层都提供一定功能支持它上面的一层,并把不同层之间的界面定义为体系结构。Myers发展了Amdahl的概念性结构性思想,明确了传统体系结构就是硬件与软件间的界面,即指令集体系结构。
1984年,拜尔(J.L.Baer)在题为”计算机体系结构“的文章中定义:体系结构由结构、组织、实现、性能4个基本方面组成。其中,结构指计算机系统硬件的互联;组织指各种部件的动态联系与管理;实现指模块设计的组装完成;性能指计算机系统的行为表现。这个定义发展了Amdahl的功能特性思想。显然,计算机系统组织又成为体系结构的子集。
计算机体系结构、组织、实现三者关系如下:
- 计算机体系结构(Computer Architecture) 指计算机的概念性结构和功能属性。
- 计算机组织(Computer Organization) 指计算机体系结构的逻辑实现,包括数据流和控制流的组成及逻辑设计等,又被称为计算机组成原理。
- 计算机实现(Computer Implementation) 指计算机组织的物理实现。
计算机体系结构分类
宏观的来说,可以按处理机的数量分类,分为:
-
单处理系统(Uni-processing System)
利用单一处理单元与外部设备结合,实现存储、计算、通信、输入输出等功能的系统。
-
并行处理与多任务处理系统(Parallel Processing and Multiprocessing System)
将两个以上的处理机互联,彼此进行通信协调,共同求解一个大问题的计算机系统。
-
分布式处理系统(Distributed Processing System)
物理上远距离又低耦合的多计算机系统。其中物理远距离意味着通信时间与处理时间相比已经无法忽略,这也是为什么需要低耦合的主要原因。
微观的来说,可以按并行程度分类,有如下几种分类法:
-
Flynn分类法
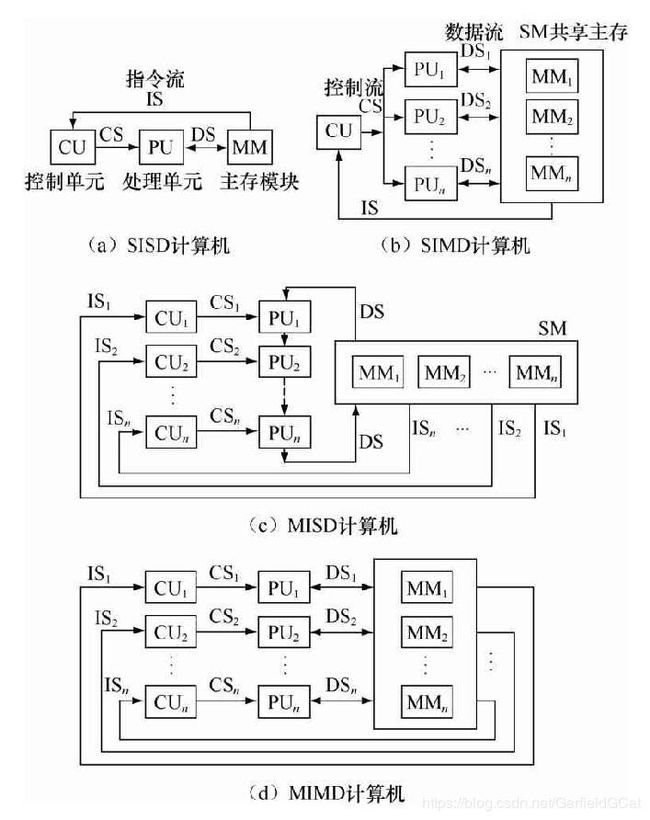
由M.J.Flynn于1966年提出,按指令流和数据流的数量进行分类。指令流为指令序列,数据流为指令所使用的数据序列。主要分为如下4类:
- 单指令流、单数据流(SISD, Single Instruction stream Single Data stream)
- 单指令流、多数据流(SIMD, Single Instruction stream Multiple Data stream)
- 多指令流、单数据流(MISD, Multiple Instruction stream Single Data stream)
- 多指令流、多数据流(MIMD, Multiple Instruction stream Multiple Data stream)
-
冯式分类法
由冯泽云于1972年提出,按最大并行度进行分类,所谓最大并行度(Pm)即计算机系统在单位时间内能处理的最大二进制位数。主要分为如下4类:
- 字串行、位串行(WSBS, Word Serial and Bit Serial)
- 字并行、位串行(WPBS, Word Parallel and Bit Serial)
- 字串行、位并行(WSBP, Word Serial and Bit Parallel)
- 字并行、位并行(WPBP, Word Parallel and Bit Parallel)
-
Handler分类法
由Wolfgang Handler(汉德勒)于1977年提出,按硬件并行程度计算并行度的方法,将结构分为3个层次:处理机级、每个处理机中算数逻辑单元、每个算数逻辑单元中逻辑门电路级。然后分别计算每一级可以并行或流水处理的程序,以此求出系统并行度。
-
Kuck分类法
由David J.Kuck于1978年提出的与Flynn分类法类似的分类,但用的是指令流和执行流,也分为如下4类:
- 单指令流、单执行流(SISE, Single Instruction stream Single Execution stream)
- 单指令流、多执行流(SIME, Single Instruction stream Multiple Execution stream)
- 多指令流、单执行流(MISE, Multiple Instruction stream Single Execution stream)
- 多指令流、多执行流(MIME, Multiple Instruction stream Multiple Execution stream)
下图是按照Flynn分类的计算机结构示例:
指令系统
一个处理器支持的指令和指令的字节级编码就称为指令体系结构(ISA, Instruction Set Architecture),不同的处理器支持不同的指令集体系结构。因此程序有时候能在一种处理器上运行但无法在另外一种处理器上运行。
指令集体系结构的分类
按体系结构的观点来对指令集分类,可以根据以下5个方面分类:
- 操作数在CPU中存储方式,即从主存取出后放在什么位置
- 显式操作数的数量,即典型指令中能包含的操作数个数
- 操作数的位置,即任一ALU指令的操作数能否位于主存中
- 指令的操作,即指令集提供的操作
- 操作数的类型和大小
按暂存机制分类,可以根据以下3个方面分类:
- 栈(Stack)
- 累加器(Accumulator)
- 寄存器组(a set of Registers)
CISC和RISC
指令集的发展历史中,曾出现过两种流派,一种是让单个指令能干更复杂的工作,另一种则反之,下面来简单了解一下。
复杂指令集计算机(Complex Instruction Set Computer)
因曾经计算机硬件非常昂贵,因此其基本思想是增强指令功能,用更复杂的新指令来取代子指令的功能来提升工作效率,但随着发展其已经越来越臃肿,反而在某种程度上影响效率。
Intel x86就是典型的CISC结构体系,Intel经常推出新的指令,但又不得不考虑兼容性保留以前的指令,其结果就是导致解码系统设计及其复杂。
但这种结构由于指令比较丰富,可以减少程序语言编译器的设计难度,但其仍有无法忽视的弊端:
- 指令集过于庞杂。
- 微程序技术是CISC的核心,每条复杂指令都经过一段解释性微程序来实现,这就导致需要多个CPU周期,降低处理效率。
- 指令集庞大虽然便于程序语言编译器的设计,但过多可选择的指令也会导致编译器本身冗长复杂,难以优化。
- CISC强调完善的中断控制会导致设计复杂、研制周期长。
- CISC芯片设计困难,出错几率大,导致其芯片种类繁多。
精简指令集计算机(Reduced Instruction Set Computer)
它的基本思想和CISC相反,通过减少指令的数量和功能,使硬件设计更为容易,指令尽量在单周期运行。通过优化编译来提高执行速度。其部分关键技术如下:
-
重叠寄存器窗口(Overlapping Register Windows)
在处理机中设置大量的寄存器,并划分成一个一个“窗口”,每个过程都可以使用相邻的3个窗口和1个公共窗口。这些窗口中有一个来自上个过程,有一个与下个过程公用。这样一来过程间的结果传递就轻松许多。
-
优化编译技术
前面提到,RISC设置大量的寄存器,因此优化编译使得尽可能的利用寄存器就是提高效率的最好方式。
-
超流水及超标量技术
-
硬布线逻辑与微程序结合
指令优化
面向目标程序的优化思路就是对程序中的出现的各种指令进行统计分析,得出静态和动态的使用频度。按使用频度来针对性的改进目标代码。大量统计表明,动态和静态使用频度之间非常接近。这种方式是CISC的主要优化方式。
面向高级程序语言的优化思路就是尽可能缩小高级语言和机器语言之间的语义差距,利于缩短编译的过程和编译后程序长度。
面向操作系统的优化思路则要着重于缩小操作系统与体积结构间的语义差距,利于减少操作系统运行所需的辅助时间,实际上,有很多指令都是专门为了实现操作系统而设计的。
指令的流水线
指令的执行有多个控制方式,有以按指令顺序串行执行的顺序方式;有在一条指令完成前就开始解释下一条的重叠方式;还有模仿工业生产的流水方式,将重复的处理过程分成一个一个模块单独处理;
顺序方式的缺点即是效率过低,机器可能会出现部分部件长期处于等待的状态。而重叠在顺序之上稍作优化,但通常采用的是一次重叠,即最多只会解释下一条,这样一来速度确实有所提高,但需要考虑潜在的指令冲突、转移的相关问题。
而现在最主要的是流水方式,下面将详细介绍一下。
流水(Pipelining)
该技术是将并行性或并发性嵌入计算系统的形式,通过将重复的过程拆解成一个个子任务,这些子任务都可以在专用又独立的模块上有效并发工作。
如下图:
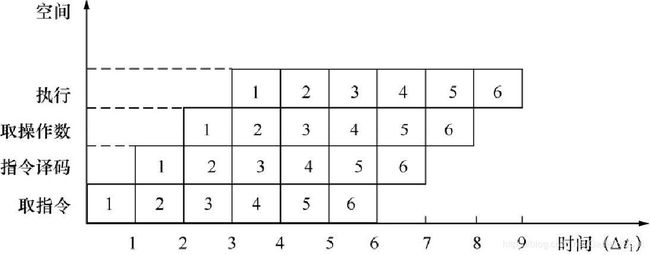
可以看到这种方式把一条指令拆解成几个不同的子过程来执行,这样一来机器的整体吞吐率就会上升。流水线的方式和重叠有一点类似,可以将流水看做是重叠的延伸。
流水的分类
根据不同的分类标准,流水又可分为多种不同的类型:
-
按级别分类:
- 部件级流水,又叫做运算操作流水线(Arithmetic Pipelines)
- 处理机级流水,又叫做指令流水线(Instruction Pipelines),即本文主要讲的,将一条指令分解为多个子过程同时执行。
- 系统级流水,又叫做宏流水线(Macro Pipelines)
-
按功能分类:
-
单功能流水线,单条流水线只能完成一种固定任务的流水线
-
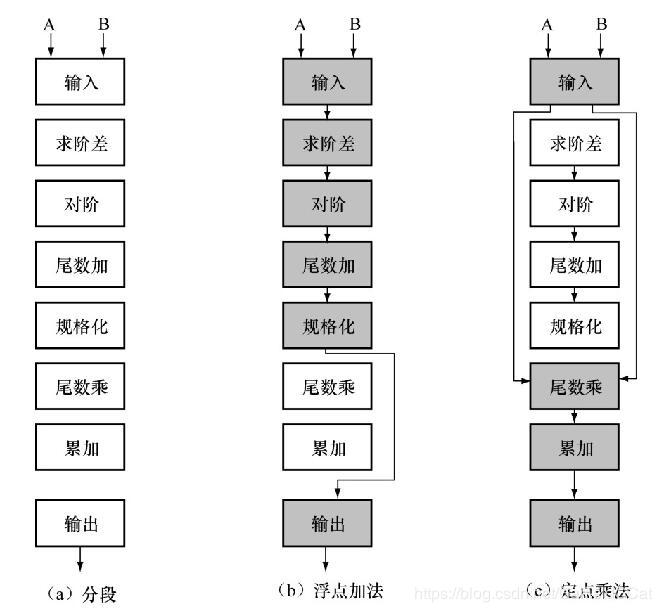
多功能流水线,通过不同的连接方式就能实现不同功能的流水线,Texas公司的ASC处理机就是一个典型,如下图:
-
-
按连接分类:
- 静态流水线,同一时间段只能按照一种固定的方式连接,实现固定的功能的流水线,前面提到的TI-ASC处理机就是静态流水线。
- 动态流水线,同一时间段流水线能以不同方式连接,实现不同功能的流水线,但这种流水线是有限制的,流水线中的各个部件不能冲突的同时使用。
下图展示了它们之间的区别,静态流水线中只有浮点加法全部流水后才能使用定点乘法,而动态则不然。

-
按反馈回路分类:
-
线性流水线,模块只能经过一次的流水线
-
非线性流水线,存在反馈回路,某功能能多次通过的流水线,如下图:

-
除了上面这些常见的,还有按流动顺序分类的同步流水线和异步流水线;按处理数据分类的向量流水线和标量流水线等。
流水相关的处理方式
由于流水存在多条指令被同时解释执行的过程,就有可能对同一寄存器或同一主存进行先写后读的可能,这时就出现了相关。相关又分为两类:
-
局部性相关
这种相关包括指令相关、内存访问相关、通用寄存器相关等。这种相关一般不会造成大范围的影响,它只影响相关的两条或数条指令,而且最多影响部分流水线推后,不影响指令缓冲中预取出的指令,因此也称为局部性相关。
解决这种相关有推后法和通路法,前者推后相关单元读取,直至写入完成。后者则设计特殊通路,直接取得运算结果,无需等待写入完成。
-
全局性相关
这种相关则较为严重,主要是条件转移指令,它可能会使得指令缓冲中预读的指令无效,需要被修改。从而造成流水线效率下降,所以称为全局性相关。
解决这种相关主要使用转移分支猜测技术、提前形成条件码技术、加快短循环等方式。一般来说,条件转移存在两个分支,通过猜测其中一种分支来加快流水线的处理效率,这也是现代计算机最常使用的手段。而提前形成条件码主要是通过某些数学特性,如乘法运算很容易就可以得知结果的正负等,这样一来就可以帮助进行猜测或提前转移。最后的加快段循环则是将小的循环指令整体放入指令缓冲中,大大提升循环的执行效率。
流水技术
-
超流水线(Super Pipeline)
通过细化流水,增加级数,提高主频,使单个时间周期内能完成一个甚至两个浮点操作,其实质是用时间换空间。
超流水机器的特征是所有的功能单元都采用流水线,并且有更深的流水深度,比流水线机器具备更多的级数。但由于它仅限于指令级并行,所以这种机器的**每指令周期(CPI, Clock Cycles Per Instruction)**都会稍高。
-
超标量(Super Scalar)
与超流水相比是通过内装多条流水线来同时执行,以此来换取更高的CPI,其实质是用空间换时间。
-
超长指令字(VLIW, Very Long Instruction Word)
这个技术较为特殊,虽然和超标量一样目的都是共同执行多条指令,但它不同于超标量通过增加流水线来实现高效的并行处理,而是通过软件将若干个无关联的指令压缩成一个执行来实现。理论上它与超标量是等价的。
流水吞吐率与建立时间
吞吐率即单位时间内流出的结果率,对指令而言即单位时间内执行的指令数量。如果流水线的子过程所用时间不一,那么吞吐率p应为最长子过程的倒数: p = 1 / m a x { Δ t 1 , Δ t 2 , … , Δ t m } p = 1 / max \{ \Delta t_1, \Delta t_2, \dots , \Delta t_m \} p=1/max{Δt1,Δt2,…,Δtm}
从其原理可以看出来,流水线要达到最大效率是需要时间的,需要各级都满载,那么需要的时间就叫做建立时间。若m个子过程的所用时间一致均为 Δ t 0 \Delta t_0 Δt0,则建立时间为 T 0 = m Δ t 0 T_0 = m \Delta t_0 T0=mΔt0。