菜菜的机器学习(一)----决策树
案例:(1)红酒数据集的分类 (2)一维回归图像的绘制
涉及的模块和库:sklearn.tree
准备工作:(1)开发环境:Jupyter Lab
(2)python最少3.4版本以上
(3)sklearn最少0.19版本以上
(4)Numpy1.15.3,Pandas0.23.4,Matplotlib3.0.1,SciPy1.1.0(在学习之前我们要确保都有这些库,没有的话需手动导入)
(5)Graphviz0.8.4(这个必须安装,不然画不出决策树,在安装之后要导入Anaconda中,否则会显示模块不存在)
目录
1 概述
1.1决策树初识
1.2 决策数算法的核心是要解决两个问题
1.3 sklearn中的决策树
2 分类树与红酒数据集
2.1 参数
2.1.1 Criterion
2.1.2 random_state、splitter
2.1.3 剪枝参数
2.1.4 目标权重参数
2.2 重要属性和接口
3 回归树和一维回归的图像绘制
3.1 重要参数、属性、接口
3.2 一维回归的图像绘制
1 概述
sklearn全称是scikit-learn,是一个基于Python的机器学习的工具包。通过NumPy、SciPy和Matplotlib等Python数值计算的库实现高效的算法应用。
1.1决策树初识
决策树:一种非参数的有监督学习方法,能够从一系列有特征和标签的数据中总结出决策规则,并用树状图才呈现这些规则,以解决分类和回归问题。
决策时的本质是一种图结构,我们只需要对记录的特征提问一系列问题就可以对数据进行分类了。
节点分类:根节点(最初的问题所在的地方)、中间节点(在得到结论前的每一个问题都可以称之为中间节点)、叶子节点(每一个结论)
1.2 决策数算法的核心是要解决两个问题
(1)如何从数据表中找到最佳节点和最佳分枝
(2)如何让决策时停止生长,防止过拟合
1.3 sklearn中的决策树
tree模块共包含五个类:
(1)tree.DecisionTreeClassifier:分类树
(2)tree.DecisionTreeRegressor:回归树
(3)tree.export_graphviz:将生成的决策树导出成DOT格式
(4)tree.ExtraTreeClassifier:高随机版本的分类树
(5)tree.ExtraTreeRegressor:高随机版本的回归树
sklearn的基本建模流程:
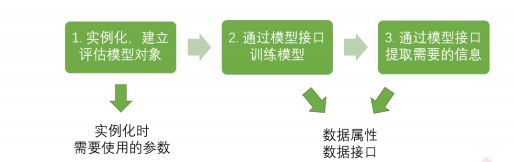
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息2 分类树与红酒数据集
学习目标:
(1)8个参数:Criterion、两个随机性相关的参数(random_state,splitter)、五个剪枝参数(max_depth,min_samples_split,min_samples_leaf,max_feature,min_impurity_decrease)
2.1 参数
2.1.1 Criterion
不纯度:为了把一个表格转化为一棵树,我们需要找到最佳节点和最佳分枝方法,对于分类树来说,衡量最佳的指标就叫做不纯度。
不纯度越低说明决策树对训练集的拟合度越好。
决策树算法在分枝方法上的核心大多是围绕在不纯度相关指标的优化上。
不纯度基于节点来计算,每个节点都有不纯度,叶子节点的不纯度最低。
Criterion是决定计算不纯度的方法的。方法有二如下:
(1)输入"entropy",使用信息熵
(2)输入"gini",使用基尼系数
注意:信息熵对于不纯度较敏感一些;在实际使用中,信息熵和基尼系数的的效果基本一致;,对于高纬度数据或者噪声很多的数据,使用信息熵很容易过拟合;当模型拟合程度不足时,即当模型在训练集和测试集上都表现不好时,使用信息熵。
决策树基本流程:计算所有特征的不纯度,找最优的特征来分枝,在第一个特征的分枝下计算特征的不纯度指标最优的一直计算。
#导入需要的算法库和模块
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split#探索数据
wine = load_wine()#将数据集生成表格
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)#分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3)#建立模型
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)#返回预测的准确度accuracy
score
此时每执行一次score输出的值都不一样,生成的图也不一样,所以之后需要加入参数来确保score不变。
#画出一棵树
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True)
graph = graphviz.Source(dot_data)
graphclf.feature_importances_#查看特征值的重要性#探索决策树
[*zip(feature_name,clf.feature_importances_)]#形成一个元祖建立模型之后,score会在某个值附近波动,画出的树都不同。
注意:决策树在建树时,是靠优化节点来追求一棵优化的树。但是最优的节点并不能保证最优的树,所以我们需要建立更多的树,从中挑出最优的树。所以方法是每次不使用全部的全部特征,而是随机选取一部分特征,从中选取不纯度指标最优的特征作为分枝。
2.1.2 random_state、splitter
random_state:用来设置分枝中随机模式的参数,高纬度的随机性显示的比较明显。
splitter:有两个输入值,best、random。
输入best,决策树在选择时会优先选择最重要的特征进行分枝。
输入random,决策树在分枝时会更加的随机,所以当用这两个参数可以防止过拟合。需要注意的是当树建成之后,我们还需要使用剪枝参数来防止过拟合。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30,splitter="random")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)#返回预测的准确度accuracy
score#此时的score不会变2.1.3 剪枝参数
为什么要使用剪枝参数?
在不加限制的情况下,一棵决策树会生长到衡量不纯度的指标最优,或者当没有更多特征可用时,但是当这种情况发生时,往往会过拟合。即可以理解为在训练集上表现很好,但是在测试集上却表现糟糕。
为了让决策树有更好的泛化性,我们要对决策树进行剪枝。
#我们的树对训练集的拟合程度如何?
score_train = clf.score(Xtrain, Ytrain)
score_train(1)max_depth:限制树的最大深度,一般从3开始,查看拟合效果之后,再决定是不是要增加深度。
(2)min_samples_leaf:当一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生。
min_samples_split:一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。这个参数的数量设置得太小会引起过拟合,设置得太大就会阻止模型学习数据。一般来说,建议从=5开始使用。如果叶节点中含有的样本量变化很 大,建议输入浮点数作为样本量的百分比来使用。同时,这个参数可以保证每个叶子的最小尺寸,可以在回归问题 中避免低方差,过拟合的叶子节点出现。对于类别不多的分类问题,=1通常就是最佳选择。
(3)max_features:限制分枝时考虑的特征个数,超过限制个数的特征就会被舍弃。
max_impurity_decrease:用来限制高纬度数据过拟合的。
确定最优的剪枝参数:使用确定超参数的曲线。
当数据集很巨大时,我们预测到之后要进行剪枝时,我们可以提前设定这些参数来控制树的大小和复杂性。
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1,criterion="entropy",random_state=30,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()2.1.4 目标权重参数
(1)class_weight:默认为None,指的是给少量的标签更多的权重,让模型更偏向于少数类,向捕获少数类的方向建模。此参数表示让数据集的所有标签都有相同的权重。
(2)min_weight_fraction_leaf:它是基于权重的剪枝参数。和(1)搭配使用。
2.2 重要属性和接口
(1)feature_importances_:可以查看各个特征对模型的重要性。
(2)fit
(3)score
(4)apply:输入测试集返回每个测试样本所在叶子节点的索引。
(5)predict:输入测试集返回每个测试样本的标签。
3 回归树和一维回归的图像绘制
注意:在回归树中没有标签是否分布均衡的问题,因为没有class_weight参数。
3.1 重要参数、属性、接口
在回归树中,MSE不仅是分枝质量衡量指标,也是衡量回归树回归质量的指标。
MSE越小越好。
注意:回归树中返回的是R平方,并不是MSE。
#R平方越小越好
boston = load_boston()
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, boston.data, boston.target,cv=10,scoring = "neg_mean_squared_error")
#交叉验证cross_val_score的用法3.2 一维回归的图像绘制
#回归树的实例(一维回归的图像绘制)
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as pltrng = np.random.RandomState(1)#生成随机数种子
X = np.sort(5 * rng.rand(80,1), axis=0) #生成0-5之间的随机的X的取值
y = np.sin(X).ravel() #生成正弦曲线
plt.figure()
plt.scatter(X,y,s=20,edgecolor="black",c="darkorange",label="data")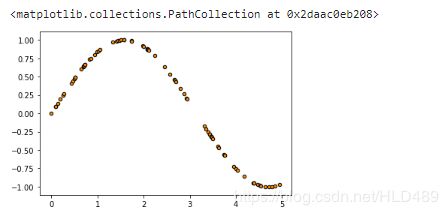
#在正弦曲线上加噪声
#np.random.rand(数组结构),生成随机数组的函数
y[::5] += 3 * (0.5 - rng.rand(16))#0.5是一个中位数,会使得有些数为正,有的数为负
plt.figure()
plt.scatter(X,y,s=20,edgecolor="black",c="darkorange",label="data")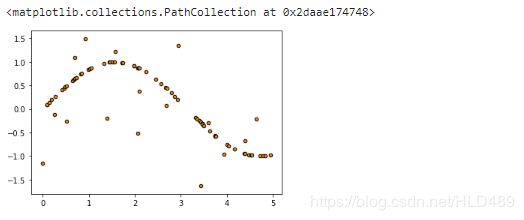
#实例化和训练模型
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)#测试集导入模型,预测结果
#np.arrange(开始点,结束点,步长) 生成有序数组的函数
#了解增维切片np.newaxis的用法
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)#绘制图像
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()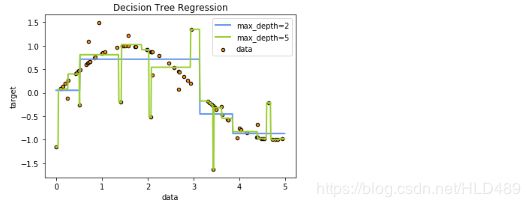
得出结论:max_depth设置的过高,决策树会从训练数据中学到很多细节,包括噪声,从而模型偏离正弦曲线,形成过拟合。
(以上内容来自菜菜的机器学习资料整理)