Spark-2.0.1 安装 及 WordCount (详细图文)
开”怼“…
1 安装 scala
这次我是安装到了 /usr/local/share 目录下:
1.1 解压
[root@master share]# pwd
/usr/local/share
[root@master share]# tar -zxvf scala-2.11.8.tgz
...
[root@master share]# ll
total 28028
drwxr-xr-x. 2 root root 4096 Sep 20 04:54 applications
drwxr-xr-x. 2 root root 4096 Sep 23 2011 info
drwxr-xr-x. 21 root root 4096 Sep 20 04:49 man
drwxrwxr-x 6 1001 1001 4096 Mar 4 2016 scala-2.11.8
-rw-r--r-- 1 root root 28678231 Nov 18 09:14 scala-2.11.8.tgz
[root@master share]# mv scala-2.11.8 scala
[root@master share]#1.2 配置环境变量
[root@master share]# vi /etc/profile
[root@master share]# source /etc/profile
1.3 使用 scala -version 验证
[root@master share]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
[root@master share]# 当出现这样的信息的时候就表示我们的 scala 安装成功了。
发送到其他节点上就可以了…
2 安装 spark
2.1 解压,配置环境变量…
快速飘过…
[root@master hadoop]# pwd
/usr/hadoop
[root@master hadoop]# tar -zxvf spark-2.0.1-bin-hadoop2.6.tgz
...
[root@master hadoop]# mv spark-2.0.1-bin-hadoop2.6.tgz spark-2.0.1
[root@master hadoop]# vi /etc/profile
[root@master hadoop]# source /etc/profile
2.2 修改 spark 配置
进入到 conf 目录
2.2.1 修改 spark-env.sh
[root@master conf]# pwd
/usr/hadoop/spark-2.0.1/conf
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
在 spark-env.sh 中添加
# scala的安装目录
export SCALA_HOME=/usr/local/share/scala
# java的安装目录
export JAVA_HOME=/usr/java/jdk1.8.0_91
# 每个worker默认分配的 内存.
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
export SPARK_WORKER_MEMORY=1G
# hadoop的配置文件目录
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.6.4/etc/hadoop2.2.1 修改 slaves
[root@master conf]# pwd
/usr/hadoop/spark-2.0.1/conf
[root@master conf]# cp slaves.template slaves
[root@master conf]# vi slaves
在 slaves 中如下修改:

2.2.3 修改 log4j.properties
[root@master conf]# pwd
/usr/hadoop/spark-2.0.1/conf
[root@master conf]# cp log4j.properties.template log4j.properties
2.2.4 发送到集群中其他节点
我就三台虚拟机,一直以来都是…
[root@master hadoop]# scp -r spark-2.0.1 root@slave1:/usr/hadoop/
...
[root@master hadoop]# scp -r spark-2.0.1 root@slave2:/usr/hadoop/
...
[root@master hadoop]# scp /etc/profile root@slave1:/etc/
...
[root@master hadoop]# scp /etc/profile root@slave2:/etc/
...
[root@master hadoop]# ssh slave1 'source /etc/profile'
[root@master hadoop]# ssh slave2 'source /etc/profile'3 启动 spark
进入到 spark 的 sbin 目录:
[root@master sbin]# pwd
/usr/hadoop/spark-2.0.1/sbin
[root@master sbin]# ll
total 92
-rwxr-xr-x 1 root root 2803 Sep 29 08:04 slaves.sh
-rwxr-xr-x 1 root root 1429 Sep 29 08:04 spark-config.sh
-rwxr-xr-x 1 root root 5427 Sep 29 08:04 spark-daemon.sh
-rwxr-xr-x 1 root root 1262 Sep 29 08:04 spark-daemons.sh
-rwxr-xr-x 1 root root 1190 Sep 29 08:04 start-all.sh
-rwxr-xr-x 1 root root 1272 Sep 29 08:04 start-history-server.sh
-rwxr-xr-x 1 root root 1916 Sep 29 08:04 start-master.sh
-rwxr-xr-x 1 root root 1733 Sep 29 08:04 start-mesos-dispatcher.sh
-rwxr-xr-x 1 root root 1423 Sep 29 08:04 start-mesos-shuffle-service.sh
-rwxr-xr-x 1 root root 1279 Sep 29 08:04 start-shuffle-service.sh
-rwxr-xr-x 1 root root 3151 Sep 29 08:04 start-slave.sh
-rwxr-xr-x 1 root root 1395 Sep 29 08:04 start-slaves.sh
-rwxr-xr-x 1 root root 1824 Sep 29 08:04 start-thriftserver.sh
-rwxr-xr-x 1 root root 1478 Sep 29 08:04 stop-all.sh
-rwxr-xr-x 1 root root 1056 Sep 29 08:04 stop-history-server.sh
-rwxr-xr-x 1 root root 1080 Sep 29 08:04 stop-master.sh
-rwxr-xr-x 1 root root 1227 Sep 29 08:04 stop-mesos-dispatcher.sh
-rwxr-xr-x 1 root root 1084 Sep 29 08:04 stop-mesos-shuffle-service.sh
-rwxr-xr-x 1 root root 1067 Sep 29 08:04 stop-shuffle-service.sh
-rwxr-xr-x 1 root root 1557 Sep 29 08:04 stop-slave.sh
-rwxr-xr-x 1 root root 1064 Sep 29 08:04 stop-slaves.sh
-rwxr-xr-x 1 root root 1066 Sep 29 08:04 stop-thriftserver.sh
[root@master sbin]# 使用 start-all.sh 脚本来启动,等一下,有没有觉得很熟悉。这个脚本跟启动 hadoop 集群的脚本重名了。所以我们启动的时候,最好还是指定一下:
[root@master sbin]# ./start-all.sh
...然后我们使用 jps 命令查看一下 java 进程:
[root@master sbin]# jps
2496 Worker
2593 Master
3798 Jps
[root@master sbin]# 这节点上有一个 master 一个 worker 进程,在集群中的两个子节点会有一个 worker 进程。
当然,这还没有实现 HA 机制,其实实现 HA 也是借助 zookeeper 集群,原理我就不说了,我也不是什么理论派,怕讲不清楚耽误了大家。
我们只需要在 spark-env.sh 文件中添加一行内容就可以了:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zook
eeper.dir=/usr/hadoop/spark-2.0.1/zookeeperDir"这样看着有点不清不楚的,我给换个格式:
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181
-Dspark.deploy.zookeeper.dir=/usr/hadoop/spark-2.0.1/zookeeperDir就是这三个参数,只要修改为你们自己安装的 zookeeper 集群的位置就行,zookeeper.dir 是在 zookeeper 集群中的目录…呃,解释不清楚了。等下我们启动了 zk 集群看一下。
然后就是把 spark-env.sh 文件发送到集群中其他节点上的相应位置,重新启动即可。不过,需要先启动 zookeeper 集群。
这个时候我们到 slave1 节点上,手动启动一个 master ,还是进入到 spark 的 sbin 目录,使用 start-master.sh 脚本:
[root@slave1 sbin]# pwd
/usr/hadoop/spark-2.0.1/sbin
[root@slave1 sbin]# ./start-master.sh哦,对了,我们启动 spark 之后可以通过 webUI 来查看一些状态信息:
通过浏览器访问:”http://master:8080”
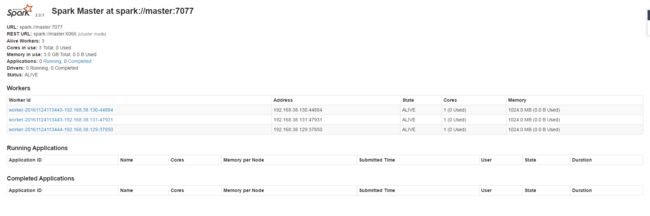
我们此时集群中是有两个 master 进程的,我们可以 kill 掉主节点上的 master 进程,然后访问:”http://slave1:8080” ,我们会发现这个时候:
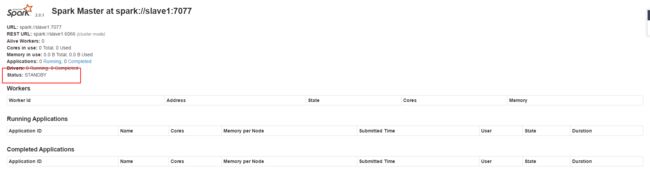
spark master 任然是 standby 状态,但是”http://master:8080“是已经不能访问。稍等一会儿,让zookeeper 选举一会儿(其实是让子弹飞一会儿…),然后我们再刷新”http://slave1:8080“就会发现,状态已经切换成 running 了。
4.运行 wordcount
既然我们的 spark 集群已经安装成功,并且正常启动了。那么我们就来体验一下它是怎么”Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.“
这个是官网上写的,可不是我说的。
4.1 准备工作
我们在Linux上任意一个目录下准备一个文件,写上一部分测试用的单词即可:
[root@master ~]# pwd
/root
[root@master ~]# vi WordCount.txt
Hello World Hello Scala Spark
Hello World Hello Scala Spark
Slave master zookeeper
Slave master zookeeper
Hello World Hello Scala Spark
Slave master zookeeper
Hello World Hello Scala Spark
Slave master zookeeper
"WordCount.txt" 8L, 212C written
[root@master ~] #4.2 启动 spark 客户端
我们暂时可以通过 spark-shell 来访问 spark集群。
[root@master spark-2.0.1]# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/11/24 15:59:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/24 15:59:15 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.38.129:4040
Spark context available as 'sc' (master = local[*], app id = local-1479974354326).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 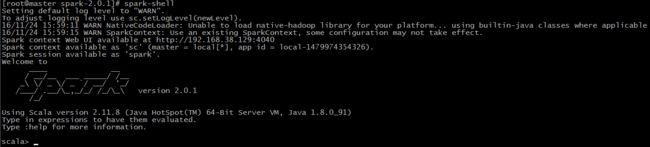
第一感觉就是:好”帅“呀… * o *
好了,被帅过去之后…
4.3 WordCount 走起
...
# 加载本地的WordCount.txt文件
scala> val file = sc.textFile("file:///root/WordCount.txt")
file: org.apache.spark.rdd.RDD[String] = file:///root/WordCount.txt MapPartitionsRDD[1] at textFile at :24
# 按照空格划分
scala> val words = file.flatMap(_.split(" "))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at :26
# 将划分出来的 words 映射成为 (word,1) 即 MapReduce 的 map 部分
scala> val kv = words.map((_,1))
kv: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at :28
# 按照 key 累加 value 即 MapReduce 的 reduce 部分
scala> val result = kv.reduceByKey(_+_)
result: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at :30
# 输出结果
scala> result.foreach(println _)
(Spark,4)
(Hello,8)
(Slave,4)
(master,4)
(zookeeper,4)
(World,4)
(Scala,4)
# 保存为本地文件
scala> result.saveAsTextFile("file:///root/Spark.wordcount.out")
scala>
经过上面一部分你可能不怎么清楚的过程之后,我们的 wordcount 程序就跑完了。我们还将结果输出到了本地,我们可以按照那个路径去看一下:
[root@master ~]# pwd
/root
[root@master ~]# ll Spark.wordcount.out
total 4
-rw-r--r-- 1 root root 75 Nov 24 18:58 part-00000
-rw-r--r-- 1 root root 0 Nov 24 18:58 _SUCCESS
[root@master ~]#
是不是感觉这样的目录结构好熟悉,跟 mapreduce 的输出目录是一样。我们可以看一下 part-00000 这个文件到底有没有保存我们的结果:
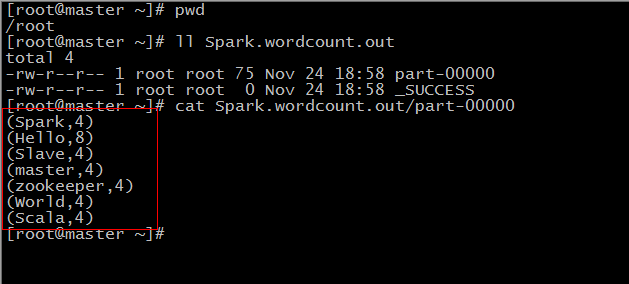
跟我们在 spark-shell 中看到一样,而且你在这个过程中你会明显发现,这个运行起来要比我们的 mapreduce 程序确实快很多,而且最重要的是,只需要几行就完成了。其实这个还可以再简单一点:

这个是我之前写的,要比这个更加简略一些。
文章到此就结束了,看官方文档去吧!